 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUPareto: Bridging the Forgetting-Utility Gap in Federated Unlearning via Pareto Augmented Optimization
Feb 02, 2026Federated Unlearning (FU) aims to efficiently remove the influence of specific client data from a federated model while preserving utility for the remaining clients. However, three key challenges remain: (1) existing unlearning objectives often compromise model utility or increase vulnerability to Membership Inference Attacks (MIA); (2) there is a persistent conflict between forgetting and utility, where further unlearning inevitably harms retained performance; and (3) support for concurrent multi-client unlearning is poor, as gradient conflicts among clients degrade the quality of forgetting. To address these issues, we propose FUPareto, an efficient unlearning framework via Pareto-augmented optimization. We first introduce the Minimum Boundary Shift (MBS) Loss, which enforces unlearning by suppressing the target class logit below the highest non-target class logit; this can improve the unlearning efficiency and mitigate MIA risks. During the unlearning process, FUPareto performs Pareto improvement steps to preserve model utility and executes Pareto expansion to guarantee forgetting. Specifically, during Pareto expansion, the framework integrates a Null-Space Projected Multiple Gradient Descent Algorithm (MGDA) to decouple gradient conflicts. This enables effective, fair, and concurrent unlearning for multiple clients while minimizing utility degradation. Extensive experiments across diverse scenarios demonstrate that FUPareto consistently outperforms state-of-the-art FU methods in both unlearning efficacy and retained utility.
FlowSteer: Interactive Agentic Workflow Orchestration via End-to-End Reinforcement Learning
Feb 02, 2026In recent years, a variety of powerful agentic workflows have been applied to solve a wide range of human problems. However, existing workflow orchestration still faces key challenges, including high manual cost, reliance on specific operators/large language models (LLMs), and sparse reward signals. To address these challenges, we propose FlowSteer, an end-to-end reinforcement learning framework that takes a lightweight policy model as the agent and an executable canvas environment, automating workflow orchestration through multi-turn interaction. In this process, the policy model analyzes execution states and selects editing actions, while the canvas executes operators and returns feedback for iterative refinement. Moreover, FlowSteer provides a plug-and-play framework that supports diverse operator libraries and interchangeable LLM backends. To effectively train this interaction paradigm, we propose Canvas Workflow Relative Policy Optimization (CWRPO), which introduces diversity-constrained rewards with conditional release to stabilize learning and suppress shortcut behaviors. Experimental results on twelve datasets show that FlowSteer significantly outperforms baselines across various tasks.
A General Model for Retinal Segmentation and Quantification
Jan 31, 2026Retinal imaging is fast, non-invasive, and widely available, offering quantifiable structural and vascular signals for ophthalmic and systemic health assessment. This accessibility creates an opportunity to study how quantitative retinal phenotypes relate to ocular and systemic diseases. However, such analyses remain difficult at scale due to the limited availability of public multi-label datasets and the lack of a unified segmentation-to-quantification pipeline. We present RetSAM, a general retinal segmentation and quantification framework for fundus imaging. It delivers robust multi-target segmentation and standardized biomarker extraction, supporting downstream ophthalmologic studies and oculomics correlation analyses. Trained on over 200,000 fundus images, RetSAM supports three task categories and segments five anatomical structures, four retinal phenotypic patterns, and more than 20 distinct lesion types. It converts these segmentation results into over 30 standardized biomarkers that capture structural morphology, vascular geometry, and degenerative changes. Trained with a multi-stage strategy using both private and public fundus data, RetSAM achieves superior segmentation performance on 17 public datasets. It improves on prior best methods by 3.9 percentage points in DSC on average, with up to 15 percentage points on challenging multi-task benchmarks, and generalizes well across diverse populations, imaging devices, and clinical settings. The resulting biomarkers enable systematic correlation analyses across major ophthalmic diseases, including diabetic retinopathy, age-related macular degeneration, glaucoma, and pathologic myopia. Together, RetSAM transforms fundus images into standardized, interpretable quantitative phenotypes, enabling large-scale ophthalmic research and translation.
Shape of Thought: Progressive Object Assembly via Visual Chain-of-Thought
Jan 28, 2026Multimodal models for text-to-image generation have achieved strong visual fidelity, yet they remain brittle under compositional structural constraints-notably generative numeracy, attribute binding, and part-level relations. To address these challenges, we propose Shape-of-Thought (SoT), a visual CoT framework that enables progressive shape assembly via coherent 2D projections without external engines at inference time. SoT trains a unified multimodal autoregressive model to generate interleaved textual plans and rendered intermediate states, helping the model capture shape-assembly logic without producing explicit geometric representations. To support this paradigm, we introduce SoT-26K, a large-scale dataset of grounded assembly traces derived from part-based CAD hierarchies, and T2S-CompBench, a benchmark for evaluating structural integrity and trace faithfulness. Fine-tuning on SoT-26K achieves 88.4% on component numeracy and 84.8% on structural topology, outperforming text-only baselines by around 20%. SoT establishes a new paradigm for transparent, process-supervised compositional generation. The code is available at https://anonymous.4open.science/r/16FE/. The SoT-26K dataset will be released upon acceptance.
The End of Manual Decoding: Towards Truly End-to-End Language Models
Oct 30, 2025



The "end-to-end" label for LLMs is a misnomer. In practice, they depend on a non-differentiable decoding process that requires laborious, hand-tuning of hyperparameters like temperature and top-p. This paper introduces AutoDeco, a novel architecture that enables truly "end-to-end" generation by learning to control its own decoding strategy. We augment the standard transformer with lightweight heads that, at each step, dynamically predict context-specific temperature and top-p values alongside the next-token logits. This approach transforms decoding into a parametric, token-level process, allowing the model to self-regulate its sampling strategy within a single forward pass. Through extensive experiments on eight benchmarks, we demonstrate that AutoDeco not only significantly outperforms default decoding strategies but also achieves performance comparable to an oracle-tuned baseline derived from "hacking the test set"-a practical upper bound for any static method. Crucially, we uncover an emergent capability for instruction-based decoding control: the model learns to interpret natural language commands (e.g., "generate with low randomness") and adjusts its predicted temperature and top-p on a token-by-token basis, opening a new paradigm for steerable and interactive LLM decoding.
CLEANet: Robust and Efficient Anomaly Detection in Contaminated Multivariate Time Series
Oct 26, 2025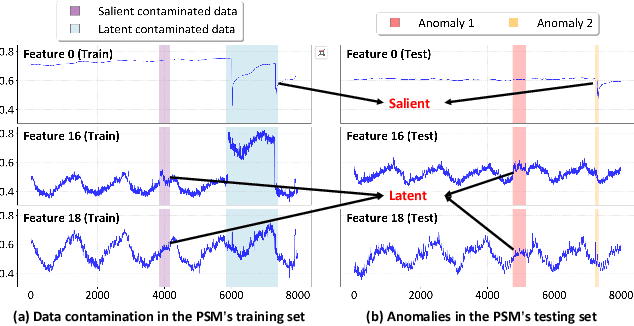
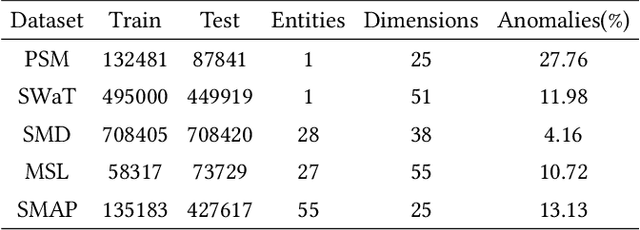
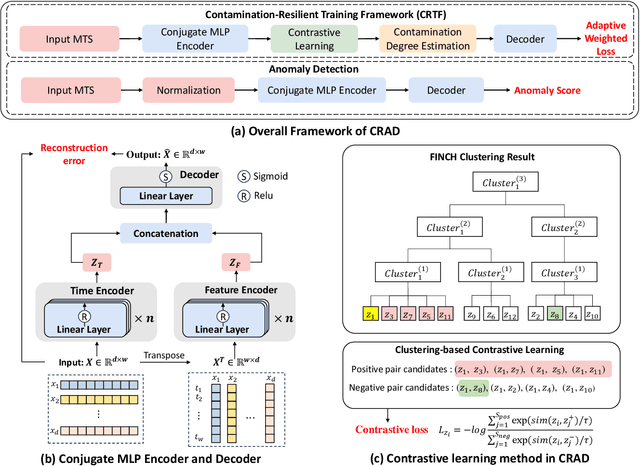
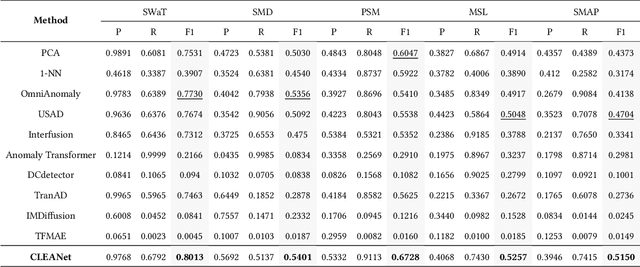
Multivariate time series (MTS) anomaly detection is essential for maintaining the reliability of industrial systems, yet real-world deployment is hindered by two critical challenges: training data contamination (noises and hidden anomalies) and inefficient model inference. Existing unsupervised methods assume clean training data, but contamination distorts learned patterns and degrades detection accuracy. Meanwhile, complex deep models often overfit to contamination and suffer from high latency, limiting practical use. To address these challenges, we propose CLEANet, a robust and efficient anomaly detection framework in contaminated multivariate time series. CLEANet introduces a Contamination-Resilient Training Framework (CRTF) that mitigates the impact of corrupted samples through an adaptive reconstruction weighting strategy combined with clustering-guided contrastive learning, thereby enhancing robustness. To further avoid overfitting on contaminated data and improve computational efficiency, we design a lightweight conjugate MLP that disentangles temporal and cross-feature dependencies. Across five public datasets, CLEANet achieves up to 73.04% higher F1 and 81.28% lower runtime compared with ten state-of-the-art baselines. Furthermore, integrating CRTF into three advanced models yields an average 5.35% F1 gain, confirming its strong generalizability.
LMM-Incentive: Large Multimodal Model-based Incentive Design for User-Generated Content in Web 3.0
Oct 06, 2025Web 3.0 represents the next generation of the Internet, which is widely recognized as a decentralized ecosystem that focuses on value expression and data ownership. By leveraging blockchain and artificial intelligence technologies, Web 3.0 offers unprecedented opportunities for users to create, own, and monetize their content, thereby enabling User-Generated Content (UGC) to an entirely new level. However, some self-interested users may exploit the limitations of content curation mechanisms and generate low-quality content with less effort, obtaining platform rewards under information asymmetry. Such behavior can undermine Web 3.0 performance. To this end, we propose \textit{LMM-Incentive}, a novel Large Multimodal Model (LMM)-based incentive mechanism for UGC in Web 3.0. Specifically, we propose an LMM-based contract-theoretic model to motivate users to generate high-quality UGC, thereby mitigating the adverse selection problem from information asymmetry. To alleviate potential moral hazards after contract selection, we leverage LMM agents to evaluate UGC quality, which is the primary component of the contract, utilizing prompt engineering techniques to improve the evaluation performance of LMM agents. Recognizing that traditional contract design methods cannot effectively adapt to the dynamic environment of Web 3.0, we develop an improved Mixture of Experts (MoE)-based Proximal Policy Optimization (PPO) algorithm for optimal contract design. Simulation results demonstrate the superiority of the proposed MoE-based PPO algorithm over representative benchmarks in the context of contract design. Finally, we deploy the designed contract within an Ethereum smart contract framework, further validating the effectiveness of the proposed scheme.
Multi-Physics: A Comprehensive Benchmark for Multimodal LLMs Reasoning on Chinese Multi-Subject Physics Problems
Sep 19, 2025



While multimodal LLMs (MLLMs) demonstrate remarkable reasoning progress, their application in specialized scientific domains like physics reveals significant gaps in current evaluation benchmarks. Specifically, existing benchmarks often lack fine-grained subject coverage, neglect the step-by-step reasoning process, and are predominantly English-centric, failing to systematically evaluate the role of visual information. Therefore, we introduce \textbf {Multi-Physics} for Chinese physics reasoning, a comprehensive benchmark that includes 5 difficulty levels, featuring 1,412 image-associated, multiple-choice questions spanning 11 high-school physics subjects. We employ a dual evaluation framework to evaluate 20 different MLLMs, analyzing both final answer accuracy and the step-by-step integrity of their chain-of-thought. Furthermore, we systematically study the impact of difficulty level and visual information by comparing the model performance before and after changing the input mode. Our work provides not only a fine-grained resource for the community but also offers a robust methodology for dissecting the multimodal reasoning process of state-of-the-art MLLMs, and our dataset and code have been open-sourced: https://github.com/luozhongze/Multi-Physics.
AniMer+: Unified Pose and Shape Estimation Across Mammalia and Aves via Family-Aware Transformer
Aug 01, 2025In the era of foundation models, achieving a unified understanding of different dynamic objects through a single network has the potential to empower stronger spatial intelligence. Moreover, accurate estimation of animal pose and shape across diverse species is essential for quantitative analysis in biological research. However, this topic remains underexplored due to the limited network capacity of previous methods and the scarcity of comprehensive multi-species datasets. To address these limitations, we introduce AniMer+, an extended version of our scalable AniMer framework. In this paper, we focus on a unified approach for reconstructing mammals (mammalia) and birds (aves). A key innovation of AniMer+ is its high-capacity, family-aware Vision Transformer (ViT) incorporating a Mixture-of-Experts (MoE) design. Its architecture partitions network layers into taxa-specific components (for mammalia and aves) and taxa-shared components, enabling efficient learning of both distinct and common anatomical features within a single model. To overcome the critical shortage of 3D training data, especially for birds, we introduce a diffusion-based conditional image generation pipeline. This pipeline produces two large-scale synthetic datasets: CtrlAni3D for quadrupeds and CtrlAVES3D for birds. To note, CtrlAVES3D is the first large-scale, 3D-annotated dataset for birds, which is crucial for resolving single-view depth ambiguities. Trained on an aggregated collection of 41.3k mammalian and 12.4k avian images (combining real and synthetic data), our method demonstrates superior performance over existing approaches across a wide range of benchmarks, including the challenging out-of-domain Animal Kingdom dataset. Ablation studies confirm the effectiveness of both our novel network architecture and the generated synthetic datasets in enhancing real-world application performance.
Fairness-aware Anomaly Detection via Fair Projection
May 16, 2025



Unsupervised anomaly detection is a critical task in many high-social-impact applications such as finance, healthcare, social media, and cybersecurity, where demographics involving age, gender, race, disease, etc, are used frequently. In these scenarios, possible bias from anomaly detection systems can lead to unfair treatment for different groups and even exacerbate social bias. In this work, first, we thoroughly analyze the feasibility and necessary assumptions for ensuring group fairness in unsupervised anomaly detection. Second, we propose a novel fairness-aware anomaly detection method FairAD. From the normal training data, FairAD learns a projection to map data of different demographic groups to a common target distribution that is simple and compact, and hence provides a reliable base to estimate the density of the data. The density can be directly used to identify anomalies while the common target distribution ensures fairness between different groups. Furthermore, we propose a threshold-free fairness metric that provides a global view for model's fairness, eliminating dependence on manual threshold selection. Experiments on real-world benchmarks demonstrate that our method achieves an improved trade-off between detection accuracy and fairness under both balanced and skewed data across different groups.