 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkilled AI Agents for Embedded and IoT Systems Development
Mar 20, 2026Large language models (LLMs) and agentic systems have shown promise for automated software development, but applying them to hardware-in-the-loop (HIL) embedded and Internet-of-Things (IoT) systems remains challenging due to the tight coupling between software logic and physical hardware behavior. Code that compiles successfully may still fail when deployed on real devices because of timing constraints, peripheral initialization requirements, or hardware-specific behaviors. To address this challenge, we introduce a skills-based agentic framework for HIL embedded development together with IoT-SkillsBench, a benchmark designed to systematically evaluate AI agents in real embedded programming environments. IoT-SkillsBench spans three representative embedded platforms, 23 peripherals, and 42 tasks across three difficulty levels, where each task is evaluated under three agent configurations (no-skills, LLM-generated skills, and human-expert skills) and validated through real hardware execution. Across 378 hardware validated experiments, we show that concise human-expert skills with structured expert knowledge enable near-perfect success rates across platforms.
CoCo: Code as CoT for Text-to-Image Preview and Rare Concept Generation
Mar 09, 2026Recent advancements in Unified Multimodal Models (UMMs) have significantly advanced text-to-image (T2I) generation, particularly through the integration of Chain-of-Thought (CoT) reasoning. However, existing CoT-based T2I methods largely rely on abstract natural-language planning, which lacks the precision required for complex spatial layouts, structured visual elements, and dense textual content. In this work, we propose CoCo (Code-as-CoT), a code-driven reasoning framework that represents the reasoning process as executable code, enabling explicit and verifiable intermediate planning for image generation. Given a text prompt, CoCo first generates executable code that specifies the structural layout of the scene, which is then executed in a sandboxed environment to render a deterministic draft image. The model subsequently refines this draft through fine-grained image editing to produce the final high-fidelity result. To support this training paradigm, we construct CoCo-10K, a curated dataset containing structured draft-final image pairs designed to teach both structured draft construction and corrective visual refinement. Empirical evaluations on StructT2IBench, OneIG-Bench, and LongText-Bench show that CoCo achieves improvements of +68.83%, +54.8%, and +41.23% over direct generation, while also outperforming other generation methods empowered by CoT. These results demonstrate that executable code is an effective and reliable reasoning paradigm for precise, controllable, and structured text-to-image generation. The code is available at: https://github.com/micky-li-hd/CoCo
Enhancing Low-resolution Image Representation Through Normalizing Flows
Jan 11, 2026Low-resolution image representation is a special form of sparse representation that retains only low-frequency information while discarding high-frequency components. This property reduces storage and transmission costs and benefits various image processing tasks. However, a key challenge is to preserve essential visual content while maintaining the ability to accurately reconstruct the original images. This work proposes LR2Flow, a nonlinear framework that learns low-resolution image representations by integrating wavelet tight frame blocks with normalizing flows. We conduct a reconstruction error analysis of the proposed network, which demonstrates the necessity of designing invertible neural networks in the wavelet tight frame domain. Experimental results on various tasks, including image rescaling, compression, and denoising, demonstrate the effectiveness of the learned representations and the robustness of the proposed framework.
SeNM-VAE: Semi-Supervised Noise Modeling with Hierarchical Variational Autoencoder
Mar 26, 2024

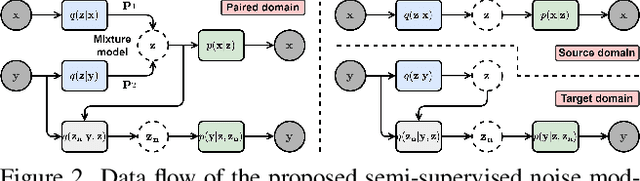

The data bottleneck has emerged as a fundamental challenge in learning based image restoration methods. Researchers have attempted to generate synthesized training data using paired or unpaired samples to address this challenge. This study proposes SeNM-VAE, a semi-supervised noise modeling method that leverages both paired and unpaired datasets to generate realistic degraded data. Our approach is based on modeling the conditional distribution of degraded and clean images with a specially designed graphical model. Under the variational inference framework, we develop an objective function for handling both paired and unpaired data. We employ our method to generate paired training samples for real-world image denoising and super-resolution tasks. Our approach excels in the quality of synthetic degraded images compared to other unpaired and paired noise modeling methods. Furthermore, our approach demonstrates remarkable performance in downstream image restoration tasks, even with limited paired data. With more paired data, our method achieves the best performance on the SIDD dataset.