 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Facial Expression Recognition to Interpersonal Relation Prediction
Nov 06, 2017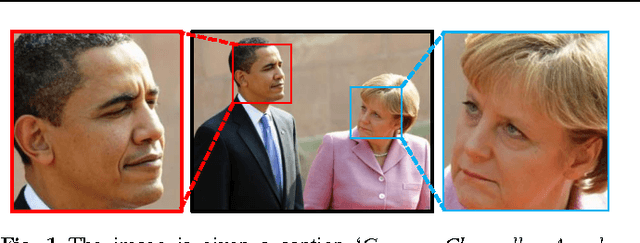
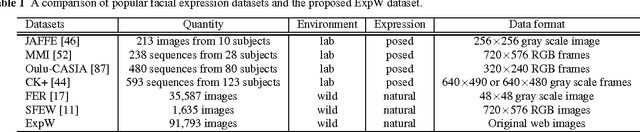

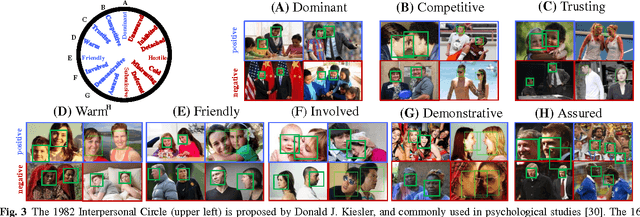
Interpersonal relation defines the association, e.g., warm, friendliness, and dominance, between two or more people. Motivated by psychological studies, we investigate if such fine-grained and high-level relation traits can be characterized and quantified from face images in the wild. We address this challenging problem by first studying a deep network architecture for robust recognition of facial expressions. Unlike existing models that typically learn from facial expression labels alone, we devise an effective multitask network that is capable of learning from rich auxiliary attributes such as gender, age, and head pose, beyond just facial expression data. While conventional supervised training requires datasets with complete labels (e.g., all samples must be labeled with gender, age, and expression), we show that this requirement can be relaxed via a novel attribute propagation method. The approach further allows us to leverage the inherent correspondences between heterogeneous attribute sources despite the disparate distributions of different datasets. With the network we demonstrate state-of-the-art results on existing facial expression recognition benchmarks. To predict inter-personal relation, we use the expression recognition network as branches for a Siamese model. Extensive experiments show that our model is capable of mining mutual context of faces for accurate fine-grained interpersonal prediction.
Temporal Action Detection with Structured Segment Networks
Sep 18, 2017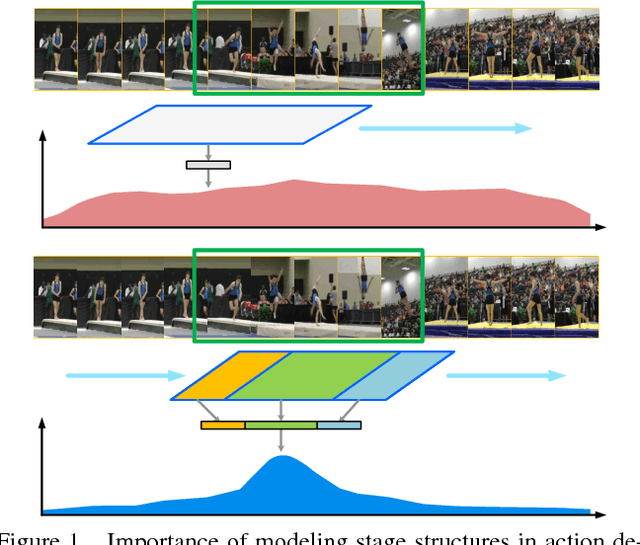
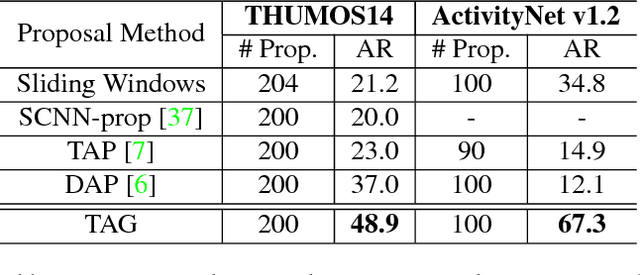
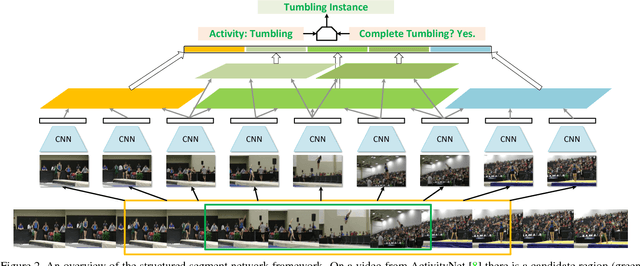
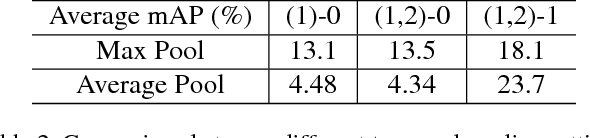
Detecting actions in untrimmed videos is an important yet challenging task. In this paper, we present the structured segment network (SSN), a novel framework which models the temporal structure of each action instance via a structured temporal pyramid. On top of the pyramid, we further introduce a decomposed discriminative model comprising two classifiers, respectively for classifying actions and determining completeness. This allows the framework to effectively distinguish positive proposals from background or incomplete ones, thus leading to both accurate recognition and localization. These components are integrated into a unified network that can be efficiently trained in an end-to-end fashion. Additionally, a simple yet effective temporal action proposal scheme, dubbed temporal actionness grouping (TAG) is devised to generate high quality action proposals. On two challenging benchmarks, THUMOS14 and ActivityNet, our method remarkably outperforms previous state-of-the-art methods, demonstrating superior accuracy and strong adaptivity in handling actions with various temporal structures.
Faceness-Net: Face Detection through Deep Facial Part Responses
Aug 25, 2017
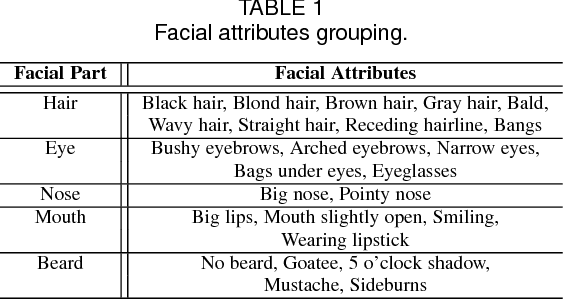
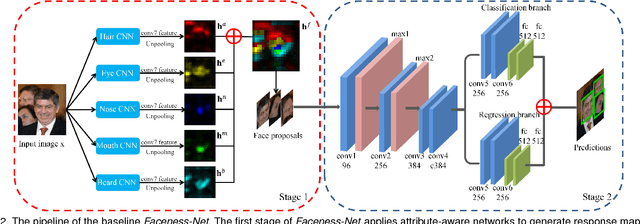
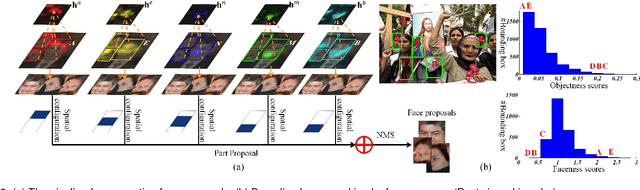
We propose a deep convolutional neural network (CNN) for face detection leveraging on facial attributes based supervision. We observe a phenomenon that part detectors emerge within CNN trained to classify attributes from uncropped face images, without any explicit part supervision. The observation motivates a new method for finding faces through scoring facial parts responses by their spatial structure and arrangement. The scoring mechanism is data-driven, and carefully formulated considering challenging cases where faces are only partially visible. This consideration allows our network to detect faces under severe occlusion and unconstrained pose variations. Our method achieves promising performance on popular benchmarks including FDDB, PASCAL Faces, AFW, and WIDER FACE.
Learning to Disambiguate by Asking Discriminative Questions
Aug 09, 2017


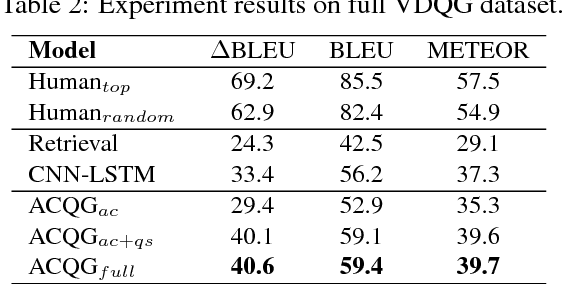
The ability to ask questions is a powerful tool to gather information in order to learn about the world and resolve ambiguities. In this paper, we explore a novel problem of generating discriminative questions to help disambiguate visual instances. Our work can be seen as a complement and new extension to the rich research studies on image captioning and question answering. We introduce the first large-scale dataset with over 10,000 carefully annotated images-question tuples to facilitate benchmarking. In particular, each tuple consists of a pair of images and 4.6 discriminative questions (as positive samples) and 5.9 non-discriminative questions (as negative samples) on average. In addition, we present an effective method for visual discriminative question generation. The method can be trained in a weakly supervised manner without discriminative images-question tuples but just existing visual question answering datasets. Promising results are shown against representative baselines through quantitative evaluations and user studies.
Deep Learning Markov Random Field for Semantic Segmentation
Aug 08, 2017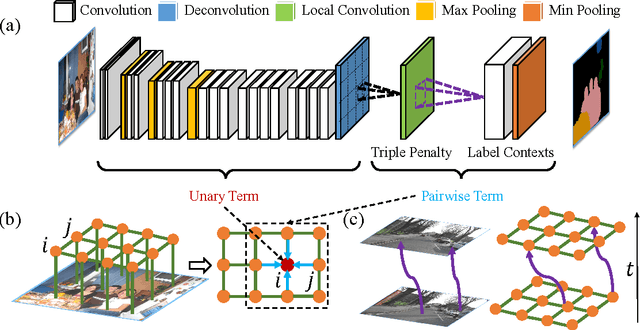
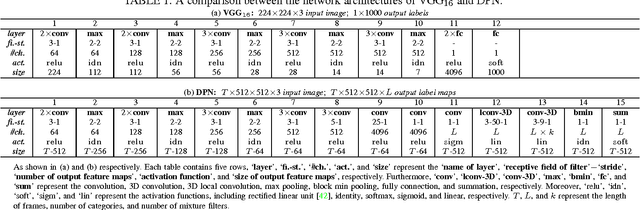
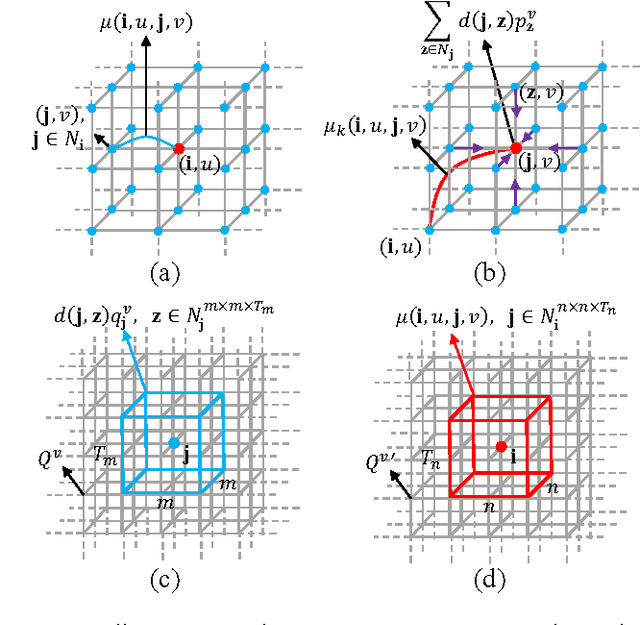

Semantic segmentation tasks can be well modeled by Markov Random Field (MRF). This paper addresses semantic segmentation by incorporating high-order relations and mixture of label contexts into MRF. Unlike previous works that optimized MRFs using iterative algorithm, we solve MRF by proposing a Convolutional Neural Network (CNN), namely Deep Parsing Network (DPN), which enables deterministic end-to-end computation in a single forward pass. Specifically, DPN extends a contemporary CNN to model unary terms and additional layers are devised to approximate the mean field (MF) algorithm for pairwise terms. It has several appealing properties. First, different from the recent works that required many iterations of MF during back-propagation, DPN is able to achieve high performance by approximating one iteration of MF. Second, DPN represents various types of pairwise terms, making many existing models as its special cases. Furthermore, pairwise terms in DPN provide a unified framework to encode rich contextual information in high-dimensional data, such as images and videos. Third, DPN makes MF easier to be parallelized and speeded up, thus enabling efficient inference. DPN is thoroughly evaluated on standard semantic image/video segmentation benchmarks, where a single DPN model yields state-of-the-art segmentation accuracies on PASCAL VOC 2012, Cityscapes dataset and CamVid dataset.
Unconstrained Fashion Landmark Detection via Hierarchical Recurrent Transformer Networks
Aug 07, 2017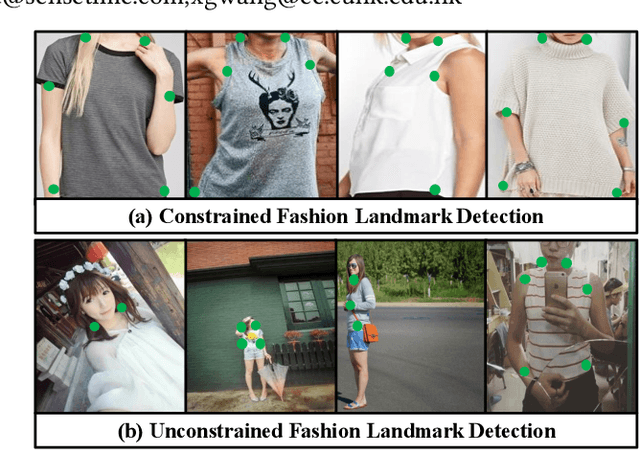

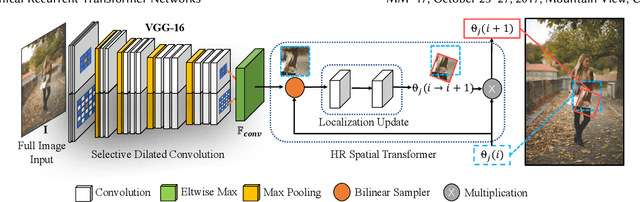

Fashion landmarks are functional key points defined on clothes, such as corners of neckline, hemline, and cuff. They have been recently introduced as an effective visual representation for fashion image understanding. However, detecting fashion landmarks are challenging due to background clutters, human poses, and scales. To remove the above variations, previous works usually assumed bounding boxes of clothes are provided in training and test as additional annotations, which are expensive to obtain and inapplicable in practice. This work addresses unconstrained fashion landmark detection, where clothing bounding boxes are not provided in both training and test. To this end, we present a novel Deep LAndmark Network (DLAN), where bounding boxes and landmarks are jointly estimated and trained iteratively in an end-to-end manner. DLAN contains two dedicated modules, including a Selective Dilated Convolution for handling scale discrepancies, and a Hierarchical Recurrent Spatial Transformer for handling background clutters. To evaluate DLAN, we present a large-scale fashion landmark dataset, namely Unconstrained Landmark Database (ULD), consisting of 30K images. Statistics show that ULD is more challenging than existing datasets in terms of image scales, background clutters, and human poses. Extensive experiments demonstrate the effectiveness of DLAN over the state-of-the-art methods. DLAN also exhibits excellent generalization across different clothing categories and modalities, making it extremely suitable for real-world fashion analysis.
Video Frame Synthesis using Deep Voxel Flow
Aug 05, 2017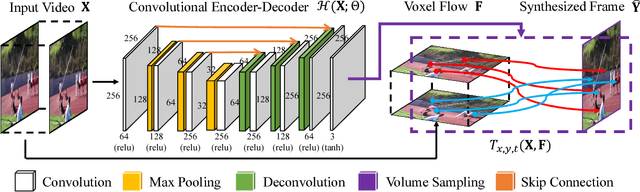
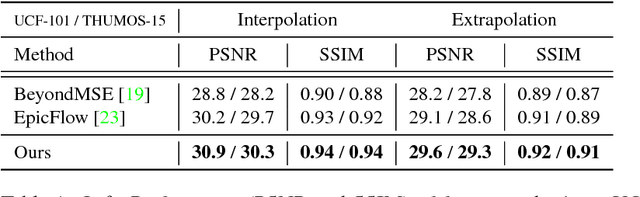
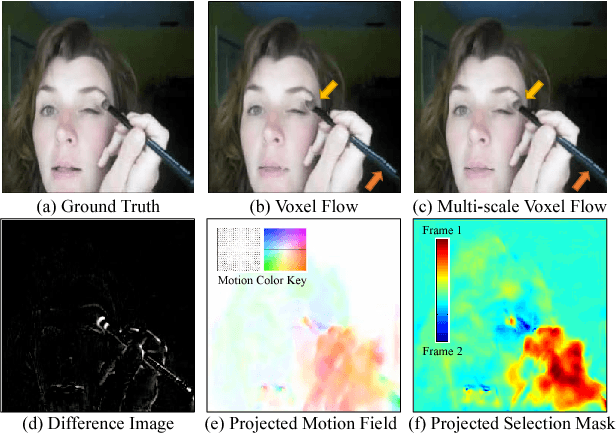
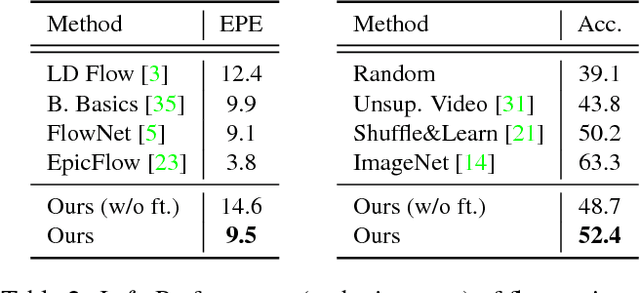
We address the problem of synthesizing new video frames in an existing video, either in-between existing frames (interpolation), or subsequent to them (extrapolation). This problem is challenging because video appearance and motion can be highly complex. Traditional optical-flow-based solutions often fail where flow estimation is challenging, while newer neural-network-based methods that hallucinate pixel values directly often produce blurry results. We combine the advantages of these two methods by training a deep network that learns to synthesize video frames by flowing pixel values from existing ones, which we call deep voxel flow. Our method requires no human supervision, and any video can be used as training data by dropping, and then learning to predict, existing frames. The technique is efficient, and can be applied at any video resolution. We demonstrate that our method produces results that both quantitatively and qualitatively improve upon the state-of-the-art.
Video Object Segmentation with Re-identification
Aug 01, 2017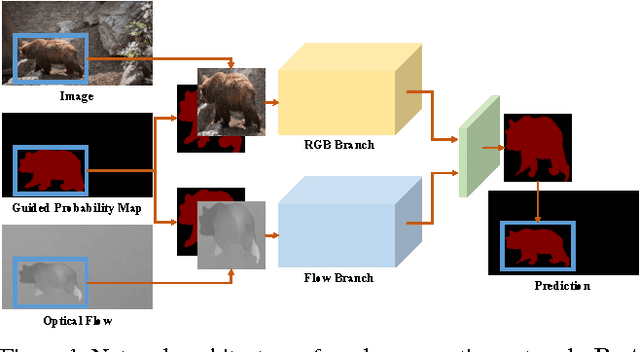
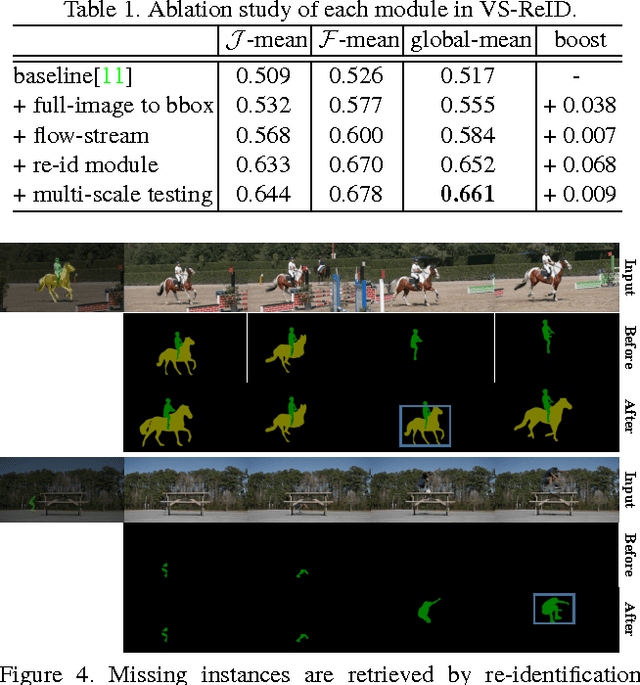
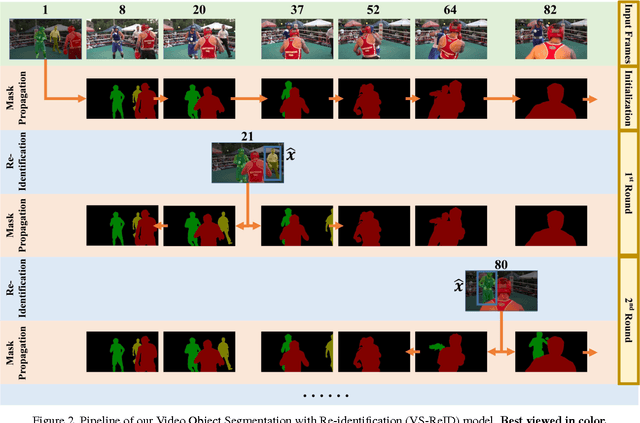
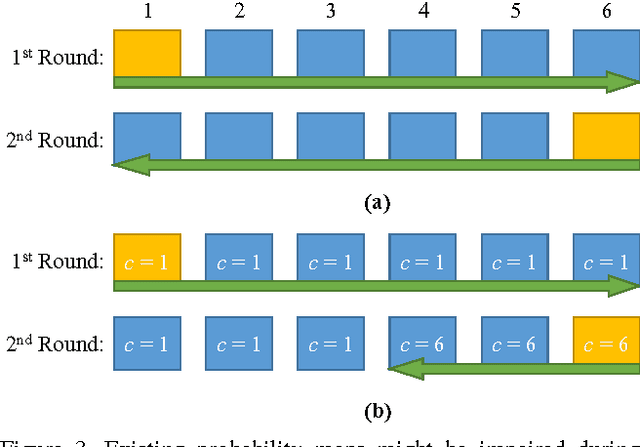
Conventional video segmentation methods often rely on temporal continuity to propagate masks. Such an assumption suffers from issues like drifting and inability to handle large displacement. To overcome these issues, we formulate an effective mechanism to prevent the target from being lost via adaptive object re-identification. Specifically, our Video Object Segmentation with Re-identification (VS-ReID) model includes a mask propagation module and a ReID module. The former module produces an initial probability map by flow warping while the latter module retrieves missing instances by adaptive matching. With these two modules iteratively applied, our VS-ReID records a global mean (Region Jaccard and Boundary F measure) of 0.699, the best performance in 2017 DAVIS Challenge.
Face Detection through Scale-Friendly Deep Convolutional Networks
Jun 09, 2017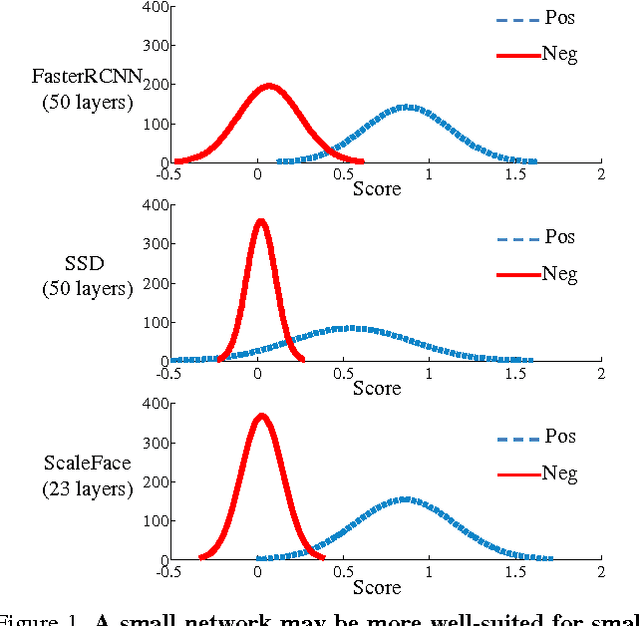
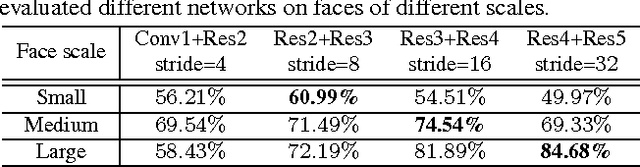
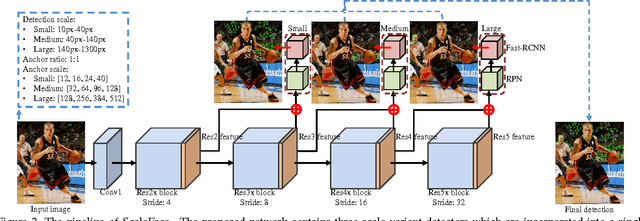
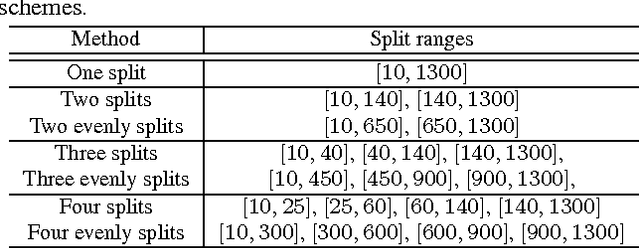
In this paper, we share our experience in designing a convolutional network-based face detector that could handle faces of an extremely wide range of scales. We show that faces with different scales can be modeled through a specialized set of deep convolutional networks with different structures. These detectors can be seamlessly integrated into a single unified network that can be trained end-to-end. In contrast to existing deep models that are designed for wide scale range, our network does not require an image pyramid input and the model is of modest complexity. Our network, dubbed ScaleFace, achieves promising performance on WIDER FACE and FDDB datasets with practical runtime speed. Specifically, our method achieves 76.4 average precision on the challenging WIDER FACE dataset and 96% recall rate on the FDDB dataset with 7 frames per second (fps) for 900 * 1300 input image.
Temporal Segment Networks for Action Recognition in Videos
May 08, 2017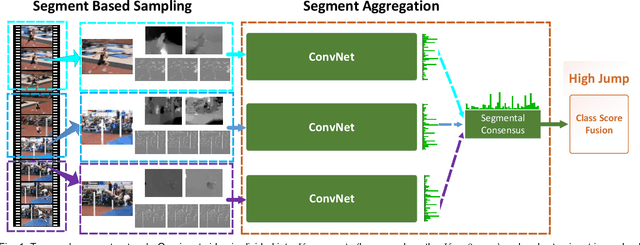
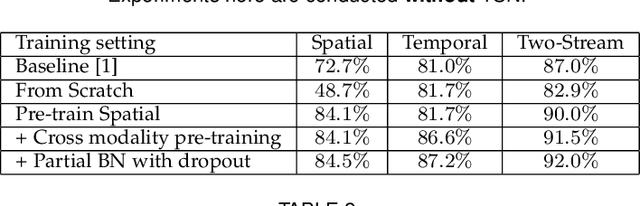

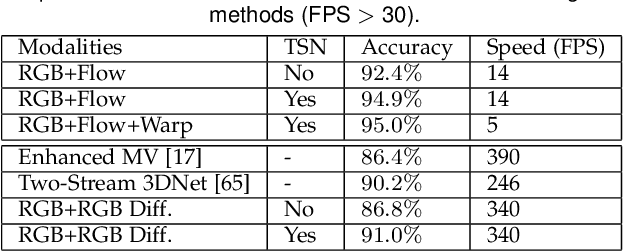
Deep convolutional networks have achieved great success for image recognition. However, for action recognition in videos, their advantage over traditional methods is not so evident. We present a general and flexible video-level framework for learning action models in videos. This method, called temporal segment network (TSN), aims to model long-range temporal structures with a new segment-based sampling and aggregation module. This unique design enables our TSN to efficiently learn action models by using the whole action videos. The learned models could be easily adapted for action recognition in both trimmed and untrimmed videos with simple average pooling and multi-scale temporal window integration, respectively. We also study a series of good practices for the instantiation of TSN framework given limited training samples. Our approach obtains the state-the-of-art performance on four challenging action recognition benchmarks: HMDB51 (71.0%), UCF101 (94.9%), THUMOS14 (80.1%), and ActivityNet v1.2 (89.6%). Using the proposed RGB difference for motion models, our method can still achieve competitive accuracy on UCF101 (91.0%) while running at 340 FPS. Furthermore, based on the temporal segment networks, we won the video classification track at the ActivityNet challenge 2016 among 24 teams, which demonstrates the effectiveness of TSN and the proposed good practices.