 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBradley-Terry and Multi-Objective Reward Modeling Are Complementary
Jul 10, 2025Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley--Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function's ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.
CCL-LGS: Contrastive Codebook Learning for 3D Language Gaussian Splatting
May 26, 2025



Recent advances in 3D reconstruction techniques and vision-language models have fueled significant progress in 3D semantic understanding, a capability critical to robotics, autonomous driving, and virtual/augmented reality. However, methods that rely on 2D priors are prone to a critical challenge: cross-view semantic inconsistencies induced by occlusion, image blur, and view-dependent variations. These inconsistencies, when propagated via projection supervision, deteriorate the quality of 3D Gaussian semantic fields and introduce artifacts in the rendered outputs. To mitigate this limitation, we propose CCL-LGS, a novel framework that enforces view-consistent semantic supervision by integrating multi-view semantic cues. Specifically, our approach first employs a zero-shot tracker to align a set of SAM-generated 2D masks and reliably identify their corresponding categories. Next, we utilize CLIP to extract robust semantic encodings across views. Finally, our Contrastive Codebook Learning (CCL) module distills discriminative semantic features by enforcing intra-class compactness and inter-class distinctiveness. In contrast to previous methods that directly apply CLIP to imperfect masks, our framework explicitly resolves semantic conflicts while preserving category discriminability. Extensive experiments demonstrate that CCL-LGS outperforms previous state-of-the-art methods. Our project page is available at https://epsilontl.github.io/CCL-LGS/.
Learning to Rank Chain-of-Thought: An Energy-Based Approach with Outcome Supervision
May 21, 2025Mathematical reasoning presents a significant challenge for Large Language Models (LLMs), often requiring robust multi step logical consistency. While Chain of Thought (CoT) prompting elicits reasoning steps, it doesn't guarantee correctness, and improving reliability via extensive sampling is computationally costly. This paper introduces the Energy Outcome Reward Model (EORM), an effective, lightweight, post hoc verifier. EORM leverages Energy Based Models (EBMs) to simplify the training of reward models by learning to assign a scalar energy score to CoT solutions using only outcome labels, thereby avoiding detailed annotations. It achieves this by interpreting discriminator output logits as negative energies, effectively ranking candidates where lower energy is assigned to solutions leading to correct final outcomes implicitly favoring coherent reasoning. On mathematical benchmarks (GSM8k, MATH), EORM significantly improves final answer accuracy (e.g., with Llama 3 8B, achieving 90.7% on GSM8k and 63.7% on MATH). EORM effectively leverages a given pool of candidate solutions to match or exceed the performance of brute force sampling, thereby enhancing LLM reasoning outcome reliability through its streamlined post hoc verification process.
CARES: Comprehensive Evaluation of Safety and Adversarial Robustness in Medical LLMs
May 16, 2025Large language models (LLMs) are increasingly deployed in medical contexts, raising critical concerns about safety, alignment, and susceptibility to adversarial manipulation. While prior benchmarks assess model refusal capabilities for harmful prompts, they often lack clinical specificity, graded harmfulness levels, and coverage of jailbreak-style attacks. We introduce CARES (Clinical Adversarial Robustness and Evaluation of Safety), a benchmark for evaluating LLM safety in healthcare. CARES includes over 18,000 prompts spanning eight medical safety principles, four harm levels, and four prompting styles: direct, indirect, obfuscated, and role-play, to simulate both malicious and benign use cases. We propose a three-way response evaluation protocol (Accept, Caution, Refuse) and a fine-grained Safety Score metric to assess model behavior. Our analysis reveals that many state-of-the-art LLMs remain vulnerable to jailbreaks that subtly rephrase harmful prompts, while also over-refusing safe but atypically phrased queries. Finally, we propose a mitigation strategy using a lightweight classifier to detect jailbreak attempts and steer models toward safer behavior via reminder-based conditioning. CARES provides a rigorous framework for testing and improving medical LLM safety under adversarial and ambiguous conditions.
MedGUIDE: Benchmarking Clinical Decision-Making in Large Language Models
May 16, 2025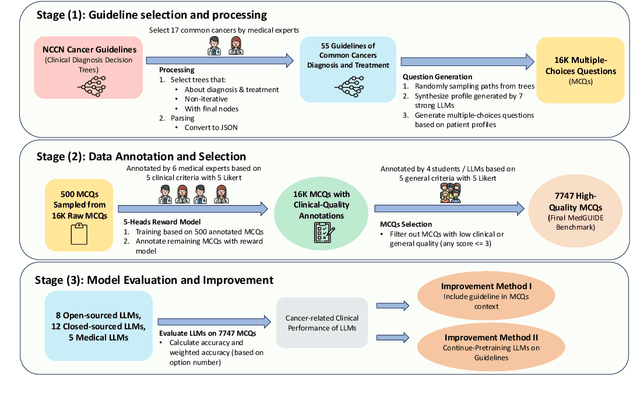
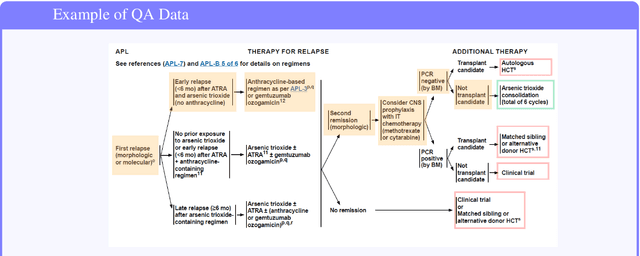
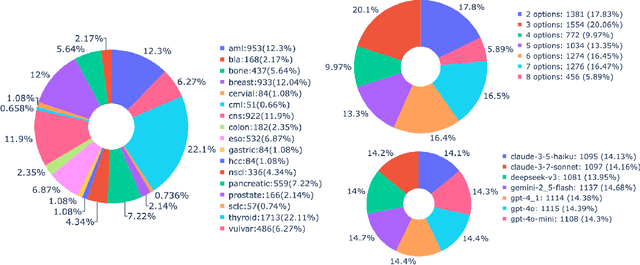
Clinical guidelines, typically structured as decision trees, are central to evidence-based medical practice and critical for ensuring safe and accurate diagnostic decision-making. However, it remains unclear whether Large Language Models (LLMs) can reliably follow such structured protocols. In this work, we introduce MedGUIDE, a new benchmark for evaluating LLMs on their ability to make guideline-consistent clinical decisions. MedGUIDE is constructed from 55 curated NCCN decision trees across 17 cancer types and uses clinical scenarios generated by LLMs to create a large pool of multiple-choice diagnostic questions. We apply a two-stage quality selection process, combining expert-labeled reward models and LLM-as-a-judge ensembles across ten clinical and linguistic criteria, to select 7,747 high-quality samples. We evaluate 25 LLMs spanning general-purpose, open-source, and medically specialized models, and find that even domain-specific LLMs often underperform on tasks requiring structured guideline adherence. We also test whether performance can be improved via in-context guideline inclusion or continued pretraining. Our findings underscore the importance of MedGUIDE in assessing whether LLMs can operate safely within the procedural frameworks expected in real-world clinical settings.
When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs
May 16, 2025Reasoning-enhanced large language models (RLLMs), whether explicitly trained for reasoning or prompted via chain-of-thought (CoT), have achieved state-of-the-art performance on many complex reasoning tasks. However, we uncover a surprising and previously overlooked phenomenon: explicit CoT reasoning can significantly degrade instruction-following accuracy. Evaluating 15 models on two benchmarks: IFEval (with simple, rule-verifiable constraints) and ComplexBench (with complex, compositional constraints), we consistently observe performance drops when CoT prompting is applied. Through large-scale case studies and an attention-based analysis, we identify common patterns where reasoning either helps (e.g., with formatting or lexical precision) or hurts (e.g., by neglecting simple constraints or introducing unnecessary content). We propose a metric, constraint attention, to quantify model focus during generation and show that CoT reasoning often diverts attention away from instruction-relevant tokens. To mitigate these effects, we introduce and evaluate four strategies: in-context learning, self-reflection, self-selective reasoning, and classifier-selective reasoning. Our results demonstrate that selective reasoning strategies, particularly classifier-selective reasoning, can substantially recover lost performance. To our knowledge, this is the first work to systematically expose reasoning-induced failures in instruction-following and offer practical mitigation strategies.
Multi-head Reward Aggregation Guided by Entropy
Mar 26, 2025



Aligning large language models (LLMs) with safety guidelines typically involves reinforcement learning from human feedback (RLHF), relying on human-generated preference annotations. However, assigning consistent overall quality ratings is challenging, prompting recent research to shift towards detailed evaluations based on multiple specific safety criteria. This paper uncovers a consistent observation: safety rules characterized by high rating entropy are generally less reliable in identifying responses preferred by humans. Leveraging this finding, we introduce ENCORE, a straightforward entropy-guided approach that composes multi-head rewards by downweighting rules exhibiting high rating entropy. Theoretically, we demonstrate that rules with elevated entropy naturally receive minimal weighting in the Bradley-Terry optimization framework, justifying our entropy-based penalization. Through extensive experiments on RewardBench safety tasks, our method significantly surpasses several competitive baselines, including random weighting, uniform weighting, single-head Bradley-Terry models, and LLM-based judging methods. Our proposed approach is training-free, broadly applicable to various datasets, and maintains interpretability, offering a practical and effective solution for multi-attribute reward modeling.
Semantic Volume: Quantifying and Detecting both External and Internal Uncertainty in LLMs
Feb 28, 2025Large language models (LLMs) have demonstrated remarkable performance across diverse tasks by encoding vast amounts of factual knowledge. However, they are still prone to hallucinations, generating incorrect or misleading information, often accompanied by high uncertainty. Existing methods for hallucination detection primarily focus on quantifying internal uncertainty, which arises from missing or conflicting knowledge within the model. However, hallucinations can also stem from external uncertainty, where ambiguous user queries lead to multiple possible interpretations. In this work, we introduce Semantic Volume, a novel mathematical measure for quantifying both external and internal uncertainty in LLMs. Our approach perturbs queries and responses, embeds them in a semantic space, and computes the determinant of the Gram matrix of the embedding vectors, capturing their dispersion as a measure of uncertainty. Our framework provides a generalizable and unsupervised uncertainty detection method without requiring white-box access to LLMs. We conduct extensive experiments on both external and internal uncertainty detection, demonstrating that our Semantic Volume method consistently outperforms existing baselines in both tasks. Additionally, we provide theoretical insights linking our measure to differential entropy, unifying and extending previous sampling-based uncertainty measures such as the semantic entropy. Semantic Volume is shown to be a robust and interpretable approach to improving the reliability of LLMs by systematically detecting uncertainty in both user queries and model responses.
Data-adaptive Safety Rules for Training Reward Models
Jan 26, 2025



Reinforcement Learning from Human Feedback (RLHF) is commonly employed to tailor models to human preferences, especially to improve the safety of outputs from large language models (LLMs). Traditionally, this method depends on selecting preferred responses from pairs. However, due to the variability in human opinions and the challenges in directly comparing two responses, there is an increasing trend towards fine-grained annotation approaches that evaluate responses using multiple targeted metrics or rules. The challenge lies in efficiently choosing and applying these rules to handle the diverse range of preference data. In this paper, we propose a dynamic method that adaptively selects the most important rules for each response pair. We introduce a mathematical framework that utilizes the maximum discrepancy across paired responses and demonstrate theoretically that this approach maximizes the mutual information between the rule-based annotations and the underlying true preferences. We then train an 8B reward model using this adaptively labeled preference dataset and assess its efficacy using RewardBench. As of January 25, 2025, our model achieved the highest safety performance on the leaderboard, surpassing various larger models.
ReNeg: Learning Negative Embedding with Reward Guidance
Dec 27, 2024In text-to-image (T2I) generation applications, negative embeddings have proven to be a simple yet effective approach for enhancing generation quality. Typically, these negative embeddings are derived from user-defined negative prompts, which, while being functional, are not necessarily optimal. In this paper, we introduce ReNeg, an end-to-end method designed to learn improved Negative embeddings guided by a Reward model. We employ a reward feedback learning framework and integrate classifier-free guidance (CFG) into the training process, which was previously utilized only during inference, thus enabling the effective learning of negative embeddings. We also propose two strategies for learning both global and per-sample negative embeddings. Extensive experiments show that the learned negative embedding significantly outperforms null-text and handcrafted counterparts, achieving substantial improvements in human preference alignment. Additionally, the negative embedding learned within the same text embedding space exhibits strong generalization capabilities. For example, using the same CLIP text encoder, the negative embedding learned on SD1.5 can be seamlessly transferred to text-to-image or even text-to-video models such as ControlNet, ZeroScope, and VideoCrafter2, resulting in consistent performance improvements across the board.