 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoDojo: Adaptive Attacks Expose Superficial Defenses and User-Underspecification Limits in LLM Agents
Jun 13, 2026Indirect prompt injection (IPI) is a major security threat to LLM-powered agents. Thus, a growing body of work have proposed a variety of defensive approaches against IPI. These can be grouped into three broad categories: 1) prompt-based (using prompting as a way to prevent agents from following malicious instructions), 2) detection-based (identifying and filtering malicious instructions), and 3) system-level (using systems insights, such as control and data isolation, for defense). However, commonly used benchmarks for evaluating defense, such as AgentDojo, are \emph{inherently static}, generating a fixed distribution of IPI attacks. Consequently, static benchmarks do not usefully evaluate defense robustness to adaptive threats. We address this issue by developing AutoDojo, an adaptive extension of AgentDojo that optimizes IPI against a given defense. Using AutoDojo against state-of-the-art IPI defenses across three task suites and five target models, we make two key observations. First, many defenses offer only limited protection: a cheap, black-box adaptive attack using a frontier LLM to iteratively optimize the injection raises attack success rate (ASR) well above the level achieved by static injections against nearly all evaluated defenses. Against a filter that reduces static ASR to 0\%, AutoDojo recovers 28\% overall and 64\% on action-open tasks. Second, for prompt-level and filter-based defenses, ASR is substantially higher on \emph{action-open} tasks -- where the user's request delegates the action itself to attacker-controlled content -- than on precisely specified tasks. This is a structural limit: on such tasks the injection can pose as ordinary data rather than an explicit instruction, bypassing defenses that rely on detecting instruction-like text. AutoDojo is publicly available at https://github.com/xhOwenMa/AutoDojo.
Chain of Risk: Safety Failures in Large Reasoning Models and Mitigation via Adaptive Multi-Principle Steering
May 07, 2026Large reasoning models (LRMs) increasingly expose chain-of-thought-like reasoning for transparency, verification, and deliberate problem solving. This creates a safety blind spot: harmful or policy-violating content may appear in reasoning traces even when final answers appear safe. We test whether final-answer safety is a sufficient proxy for the full reasoning-answer trajectory by scoring both stages under a unified twenty-principle safety rubric. Using prompts from seven public harmfulness and jailbreak sources, plus four out-of-distribution (OOD) sources, we evaluate 15 open-weight and API-based LRMs across 41K prompts per model. Reasoning traces consistently reveal additional safety risks beyond final answers, especially in high-severity stage-wise failures: leak cases, where unsafe reasoning precedes a safe-looking answer, and escape cases, where benign-looking reasoning precedes an unsafe final response. Principle-level analysis shows that risk concentrates in misinformation, legal compliance, discrimination, physical harm, and psychological harm. We further propose adaptive multi-principle steering, a white-box test-time mitigation that learns one unsafe-to-safe activation direction per safety principle and activates only directions whose current hidden state is closer to the unsafe than safe centroid. On three steerable open reasoning models, adaptive steering reduces unsafe counts in both reasoning traces and final answers on held-out and OOD benchmarks. DeepSeek-R1-Qwen-7B achieves a 40.8% average unsafe-count reduction while retaining 97.7% macro-averaged accuracy on BBH, GSM8K, and MMLU. These results suggest that LRM safety should be evaluated and mitigated over the full exposed reasoning-answer trajectory, not only at the final-answer stage.
The Erasure Illusion: Stress-Testing the Generalization of LLM Forgetting Evaluation
Dec 23, 2025Machine unlearning aims to remove specific data influences from trained models, a capability essential for adhering to copyright laws and ensuring AI safety. Current unlearning metrics typically measure success by monitoring the model's performance degradation on the specific unlearning dataset ($D_u$). We argue that for Large Language Models (LLMs), this evaluation paradigm is insufficient and potentially misleading. Many real-world uses of unlearning--motivated by copyright or safety--implicitly target not only verbatim content in $D_u$, but also behaviors influenced by the broader generalizations the model derived from it. We demonstrate that LLMs can pass standard unlearning evaluation and appear to have "forgotten" the target knowledge, while simultaneously retaining strong capabilities on content that is semantically adjacent to $D_u$. This phenomenon indicates that erasing exact sentences does not necessarily equate to removing the underlying knowledge. To address this gap, we propose Proximal Surrogate Generation (PSG), an automated stress-testing framework that generates a surrogate dataset, $\tilde{D}_u$. This surrogate set is constructed to be semantically derived from $D_u$ yet sufficiently distinct in embedding space. By comparing unlearning metric scores between $D_u$ and $\tilde{D}_u$, we can stress-test the reliability of the metric itself. Our extensive evaluation across three LLM families (Llama-3-8B, Qwen2.5-7B, and Zephyr-7B-$β$), three distinct datasets, and seven standard metrics reveals widespread inconsistencies. We find that current metrics frequently overestimate unlearning success, failing to detect retained knowledge exposed by our stress-test datasets.
SoK: Understanding (New) Security Issues Across AI4Code Use Cases
Dec 20, 2025AI-for-Code (AI4Code) systems are reshaping software engineering, with tools like GitHub Copilot accelerating code generation, translation, and vulnerability detection. Alongside these advances, however, security risks remain pervasive: insecure outputs, biased benchmarks, and susceptibility to adversarial manipulation undermine their reliability. This SoK surveys the landscape of AI4Code security across three core applications, identifying recurring gaps: benchmark dominance by Python and toy problems, lack of standardized security datasets, data leakage in evaluation, and fragile adversarial robustness. A comparative study of six state-of-the-art models illustrates these challenges: insecure patterns persist in code generation, vulnerability detection is brittle to semantic-preserving attacks, fine-tuning often misaligns security objectives, and code translation yields uneven security benefits. From this analysis, we distill three forward paths: embedding secure-by-default practices in code generation, building robust and comprehensive detection benchmarks, and leveraging translation as a route to security-enhanced languages. We call for a shift toward security-first AI4Code, where vulnerability mitigation and robustness are embedded throughout the development life cycle.
MedGUIDE: Benchmarking Clinical Decision-Making in Large Language Models
May 16, 2025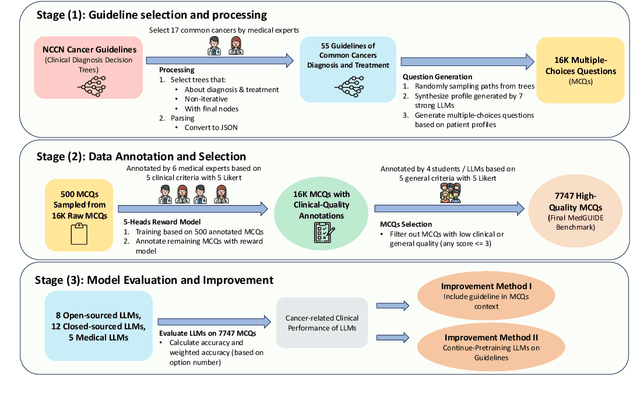
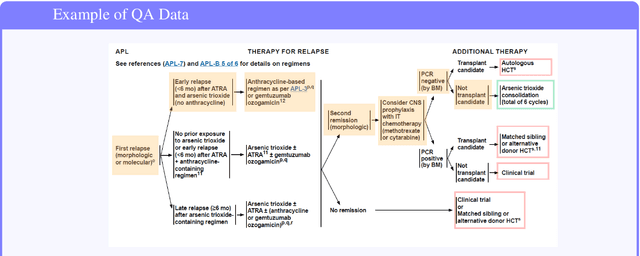
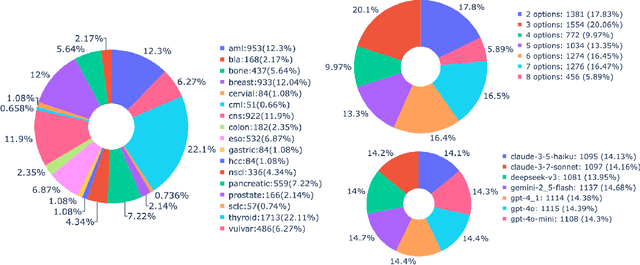
Clinical guidelines, typically structured as decision trees, are central to evidence-based medical practice and critical for ensuring safe and accurate diagnostic decision-making. However, it remains unclear whether Large Language Models (LLMs) can reliably follow such structured protocols. In this work, we introduce MedGUIDE, a new benchmark for evaluating LLMs on their ability to make guideline-consistent clinical decisions. MedGUIDE is constructed from 55 curated NCCN decision trees across 17 cancer types and uses clinical scenarios generated by LLMs to create a large pool of multiple-choice diagnostic questions. We apply a two-stage quality selection process, combining expert-labeled reward models and LLM-as-a-judge ensembles across ten clinical and linguistic criteria, to select 7,747 high-quality samples. We evaluate 25 LLMs spanning general-purpose, open-source, and medically specialized models, and find that even domain-specific LLMs often underperform on tasks requiring structured guideline adherence. We also test whether performance can be improved via in-context guideline inclusion or continued pretraining. Our findings underscore the importance of MedGUIDE in assessing whether LLMs can operate safely within the procedural frameworks expected in real-world clinical settings.
Analyzing Wikipedia Membership Dataset and PredictingUnconnected Nodes in the Signed Networks
Oct 18, 2021
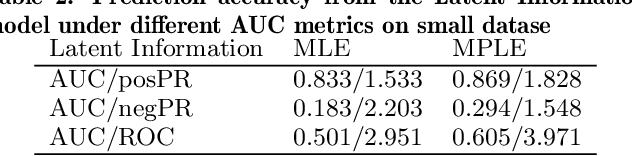
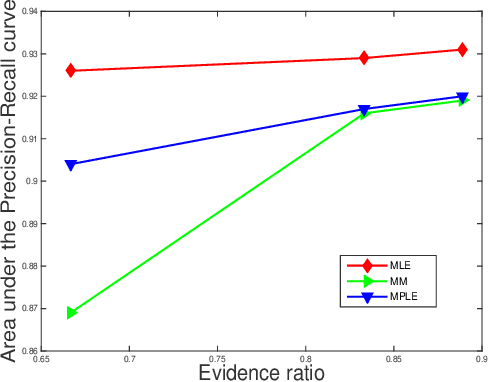
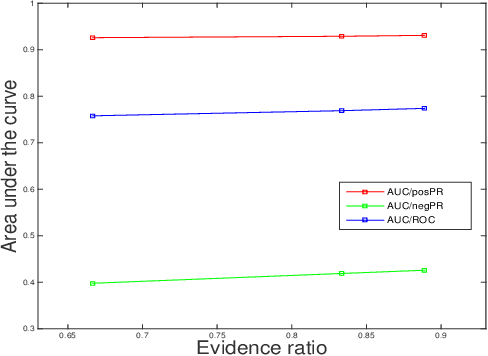
In the age of digital interaction, person-to-person relationships existing on social media may be different from the very same interactions that exist offline. Examining potential or spurious relationships between members in a social network is a fertile area of research for computer scientists -- here we examine how relationships can be predicted between two unconnected people in a social network by using area under Precison-Recall curve and ROC. Modeling the social network as a signed graph, we compare Triadic model,Latent Information model and Sentiment model and use them to predict peer to peer interactions, first using a plain signed network, and second using a signed network with comments as context. We see that our models are much better than random model and could complement each other in different cases.