 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPMN: Pixel-Phrase Matching Network for One-Stage Panoptic Narrative Grounding
Aug 11, 2022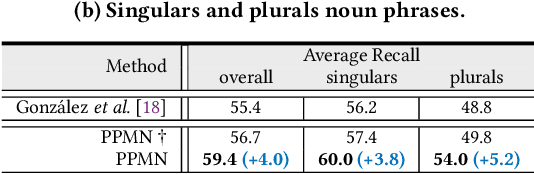
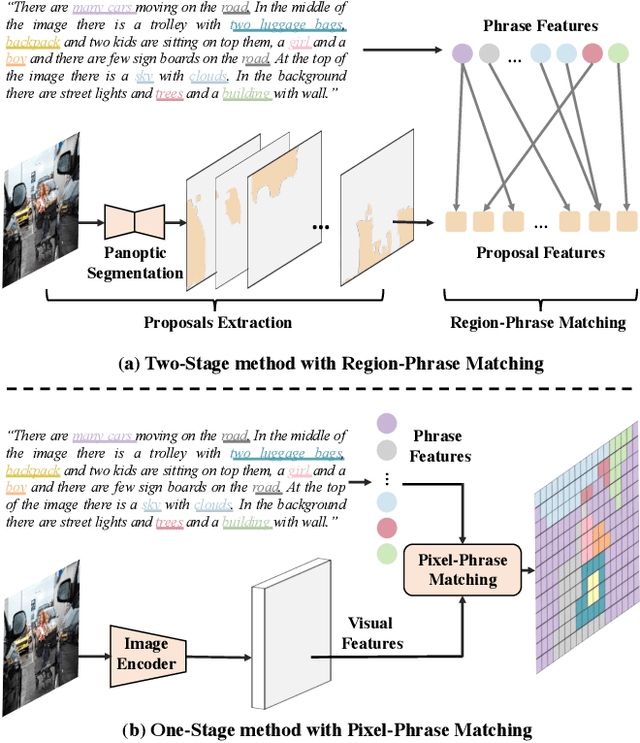
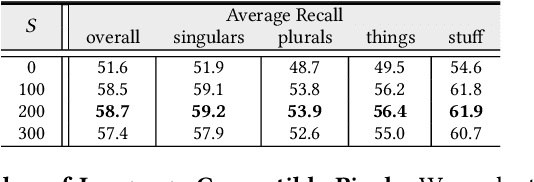
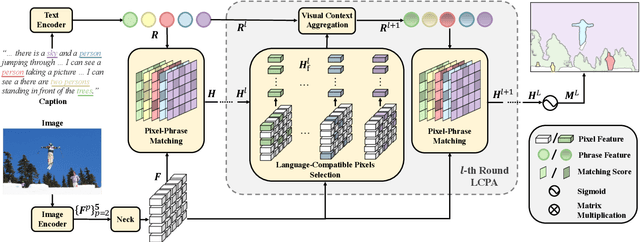
Panoptic Narrative Grounding (PNG) is an emerging task whose goal is to segment visual objects of things and stuff categories described by dense narrative captions of a still image. The previous two-stage approach first extracts segmentation region proposals by an off-the-shelf panoptic segmentation model, then conducts coarse region-phrase matching to ground the candidate regions for each noun phrase. However, the two-stage pipeline usually suffers from the performance limitation of low-quality proposals in the first stage and the loss of spatial details caused by region feature pooling, as well as complicated strategies designed for things and stuff categories separately. To alleviate these drawbacks, we propose a one-stage end-to-end Pixel-Phrase Matching Network (PPMN), which directly matches each phrase to its corresponding pixels instead of region proposals and outputs panoptic segmentation by simple combination. Thus, our model can exploit sufficient and finer cross-modal semantic correspondence from the supervision of densely annotated pixel-phrase pairs rather than sparse region-phrase pairs. In addition, we also propose a Language-Compatible Pixel Aggregation (LCPA) module to further enhance the discriminative ability of phrase features through multi-round refinement, which selects the most compatible pixels for each phrase to adaptively aggregate the corresponding visual context. Extensive experiments show that our method achieves new state-of-the-art performance on the PNG benchmark with 4.0 absolute Average Recall gains.
Efficient Modeling of Future Context for Image Captioning
Jul 22, 2022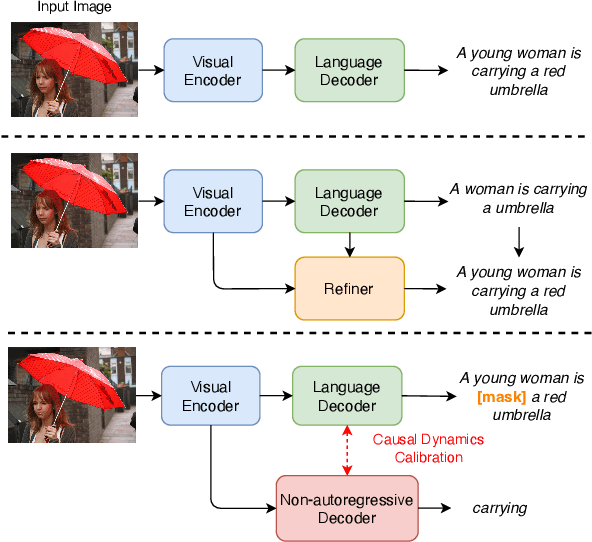

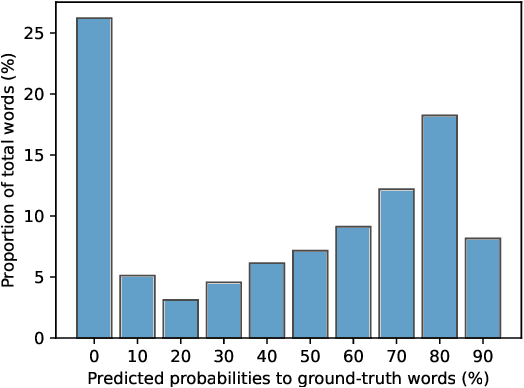
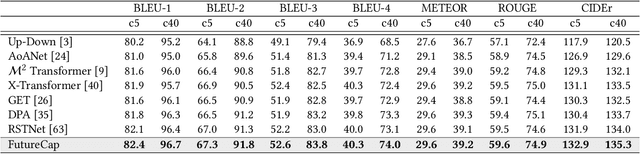
Existing approaches to image captioning usually generate the sentence word-by-word from left to right, with the constraint of conditioned on local context including the given image and history generated words. There have been many studies target to make use of global information during decoding, e.g., iterative refinement. However, it is still under-explored how to effectively and efficiently incorporate the future context. To respond to this issue, inspired by that Non-Autoregressive Image Captioning (NAIC) can leverage two-side relation with modified mask operation, we aim to graft this advance to the conventional Autoregressive Image Captioning (AIC) model while maintaining the inference efficiency without extra time cost. Specifically, AIC and NAIC models are first trained combined with shared visual encoders, forcing the visual encoder to contain sufficient and valid future context; then the AIC model is encouraged to capture the causal dynamics of cross-layer interchanging from NAIC model on its unconfident words, which follows a teacher-student paradigm and optimized with the distribution calibration training objective. Empirical evidences demonstrate that our proposed approach clearly surpass the state-of-the-art baselines in both automatic metrics and human evaluations on the MS COCO benchmark. The source code is available at: https://github.com/feizc/Future-Caption.
MT-Net Submission to the Waymo 3D Detection Leaderboard
Jul 11, 2022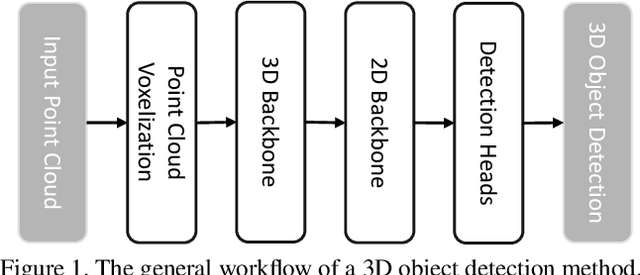
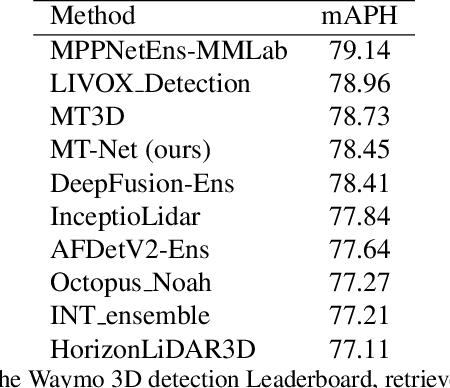
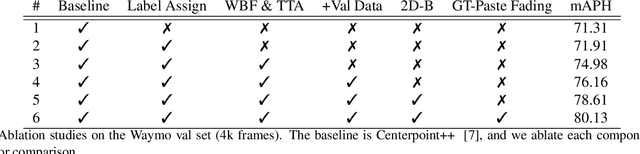
In this technical report, we introduce our submission to the Waymo 3D Detection leaderboard. Our network is based on the Centerpoint architecture, but with significant improvements. We design a 2D backbone to utilize multi-scale features for better detecting objects with various sizes, together with an optimal transport-based target assignment strategy, which dynamically assigns richer supervision signals to the detection candidates. We also apply test-time augmentation and model-ensemble for further improvements. Our submission currently ranks 4th place with 78.45 mAPH on the Waymo 3D Detection leaderboard.
Fully Convolutional One-Stage 3D Object Detection on LiDAR Range Images
May 27, 2022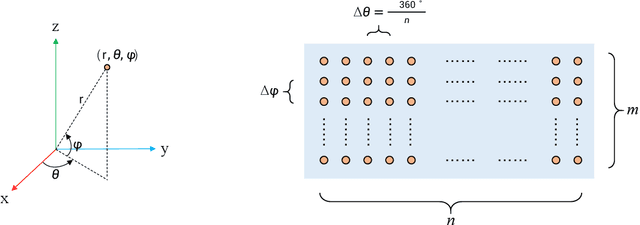

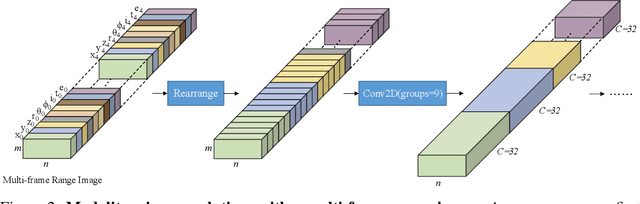
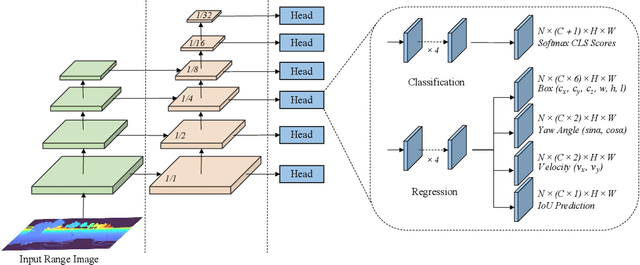
We present a simple yet effective fully convolutional one-stage 3D object detector for LiDAR point clouds of autonomous driving scenes, termed FCOS-LiDAR. Unlike the dominant methods that use the bird-eye view (BEV), our proposed detector detects objects from the range view (RV, a.k.a. range image) of the LiDAR points. Due to the range view's compactness and compatibility with the LiDAR sensors' sampling process on self-driving cars, the range view-based object detector can be realized by solely exploiting the vanilla 2D convolutions, departing from the BEV-based methods which often involve complicated voxelization operations and sparse convolutions. For the first time, we show that an RV-based 3D detector with standard 2D convolutions alone can achieve comparable performance to state-of-the-art BEV-based detectors while being significantly faster and simpler. More importantly, almost all previous range view-based detectors only focus on single-frame point clouds, since it is challenging to fuse multi-frame point clouds into a single range view. In this work, we tackle this challenging issue with a novel range view projection mechanism, and for the first time demonstrate the benefits of fusing multi-frame point clouds for a range-view based detector. Extensive experiments on nuScenes show the superiority of our proposed method and we believe that our work can be strong evidence that an RV-based 3D detector can compare favourably with the current mainstream BEV-based detectors.
Learn to Cluster Faces via Pairwise Classification
May 26, 2022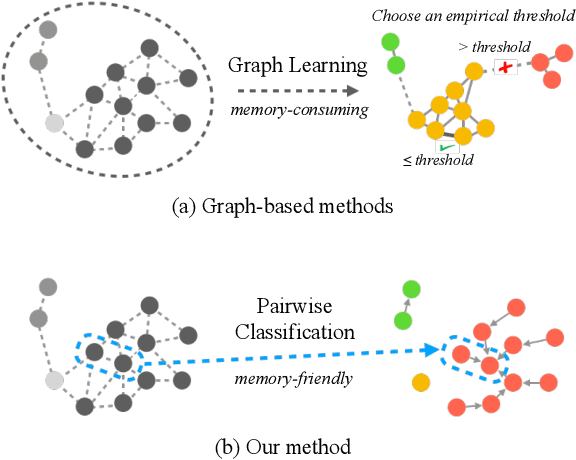
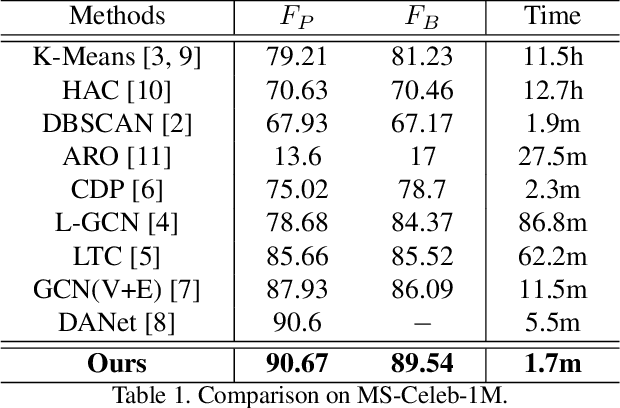
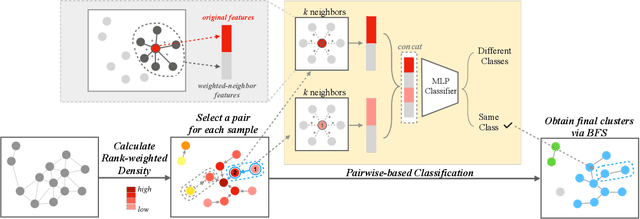
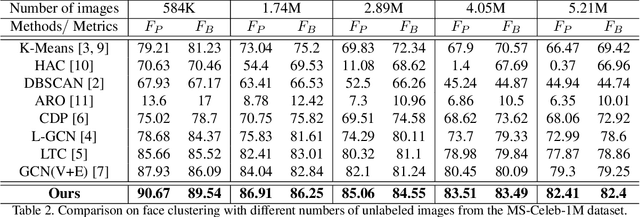
Face clustering plays an essential role in exploiting massive unlabeled face data. Recently, graph-based face clustering methods are getting popular for their satisfying performances. However, they usually suffer from excessive memory consumption especially on large-scale graphs, and rely on empirical thresholds to determine the connectivities between samples in inference, which restricts their applications in various real-world scenes. To address such problems, in this paper, we explore face clustering from the pairwise angle. Specifically, we formulate the face clustering task as a pairwise relationship classification task, avoiding the memory-consuming learning on large-scale graphs. The classifier can directly determine the relationship between samples and is enhanced by taking advantage of the contextual information. Moreover, to further facilitate the efficiency of our method, we propose a rank-weighted density to guide the selection of pairs sent to the classifier. Experimental results demonstrate that our method achieves state-of-the-art performances on several public clustering benchmarks at the fastest speed and shows a great advantage in comparison with graph-based clustering methods on memory consumption.
PromptDet: Expand Your Detector Vocabulary with Uncurated Images
Mar 30, 2022

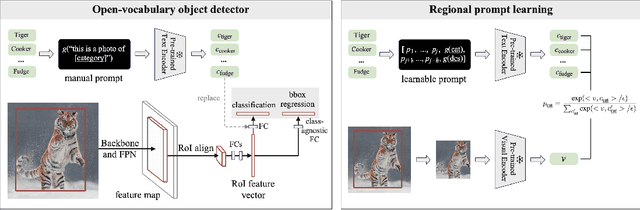

The goal of this work is to establish a scalable pipeline for expanding an object detector towards novel/unseen categories, using zero manual annotations. To achieve that, we make the following four contributions: (i) in pursuit of generalisation, we propose a two-stage open-vocabulary object detector that categorises each box proposal by a classifier generated from the text encoder of a pre-trained visual-language model; (ii) To pair the visual latent space (from RPN box proposal) with that of the pre-trained text encoder, we propose the idea of regional prompt learning to optimise a couple of learnable prompt vectors, converting the textual embedding space to fit those visually object-centric images; (iii) To scale up the learning procedure towards detecting a wider spectrum of objects, we exploit the available online resource, iteratively updating the prompts, and later self-training the proposed detector with pseudo labels generated on a large corpus of noisy, uncurated web images. The self-trained detector, termed as PromptDet, significantly improves the detection performance on categories for which manual annotations are unavailable or hard to obtain, e.g. rare categories. Finally, (iv) to validate the necessity of our proposed components, we conduct extensive experiments on the challenging LVIS and MS-COCO dataset, showing superior performance over existing approaches with fewer additional training images and zero manual annotations whatsoever. Project page with code: https://fcjian.github.io/promptdet.
InsCon:Instance Consistency Feature Representation via Self-Supervised Learning
Mar 15, 2022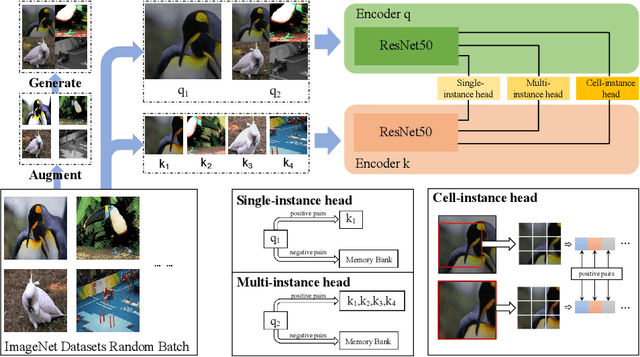
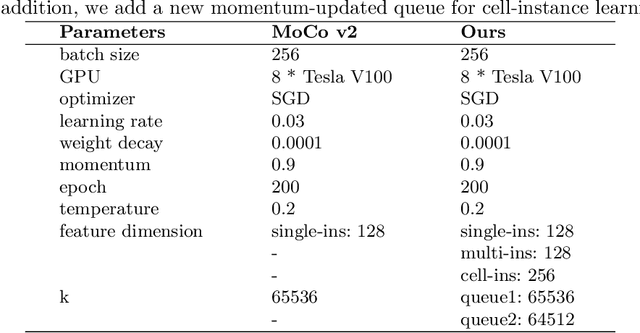
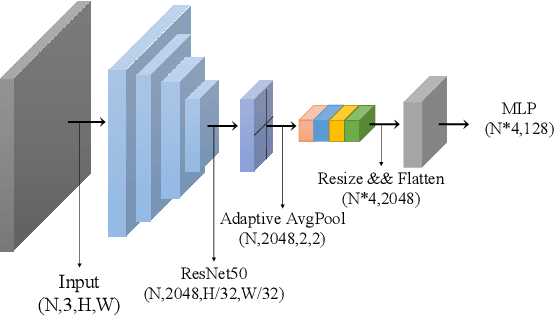
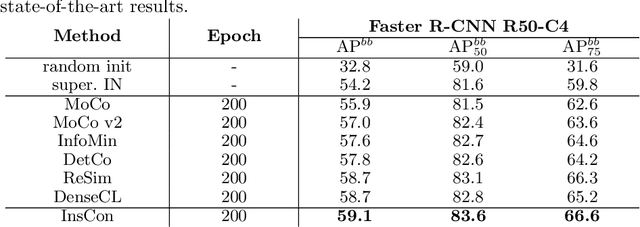
Feature representation via self-supervised learning has reached remarkable success in image-level contrastive learning, which brings impressive performances on image classification tasks. While image-level feature representation mainly focuses on contrastive learning in single instance, it ignores the objective differences between pretext and downstream prediction tasks such as object detection and instance segmentation. In order to fully unleash the power of feature representation on downstream prediction tasks, we propose a new end-to-end self-supervised framework called InsCon, which is devoted to capturing multi-instance information and extracting cell-instance features for object recognition and localization. On the one hand, InsCon builds a targeted learning paradigm that applies multi-instance images as input, aligning the learned feature between corresponding instance views, which makes it more appropriate for multi-instance recognition tasks. On the other hand, InsCon introduces the pull and push of cell-instance, which utilizes cell consistency to enhance fine-grained feature representation for precise boundary localization. As a result, InsCon learns multi-instance consistency on semantic feature representation and cell-instance consistency on spatial feature representation. Experiments demonstrate the method we proposed surpasses MoCo v2 by 1.1% AP^{bb} on COCO object detection and 1.0% AP^{mk} on COCO instance segmentation using Mask R-CNN R50-FPN network structure with 90k iterations, 2.1% APbb on PASCAL VOC objection detection using Faster R-CNN R50-C4 network structure with 24k iterations.
Contrastive Attention Network with Dense Field Estimation for Face Completion
Dec 20, 2021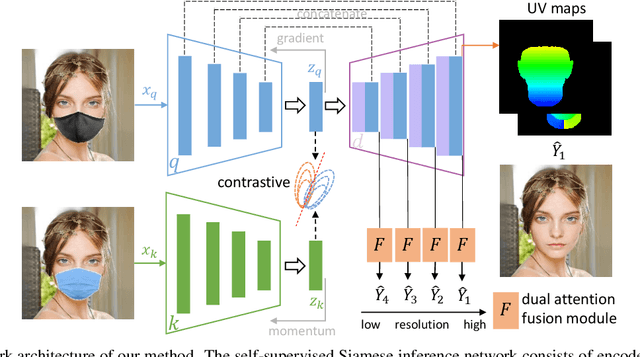
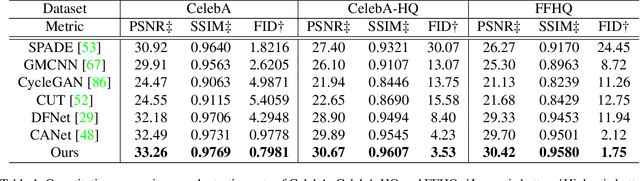
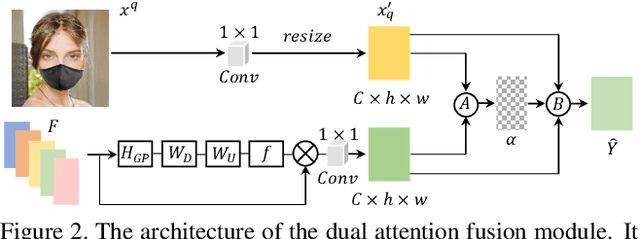

Most modern face completion approaches adopt an autoencoder or its variants to restore missing regions in face images. Encoders are often utilized to learn powerful representations that play an important role in meeting the challenges of sophisticated learning tasks. Specifically, various kinds of masks are often presented in face images in the wild, forming complex patterns, especially in this hard period of COVID-19. It's difficult for encoders to capture such powerful representations under this complex situation. To address this challenge, we propose a self-supervised Siamese inference network to improve the generalization and robustness of encoders. It can encode contextual semantics from full-resolution images and obtain more discriminative representations. To deal with geometric variations of face images, a dense correspondence field is integrated into the network. We further propose a multi-scale decoder with a novel dual attention fusion module (DAF), which can combine the restored and known regions in an adaptive manner. This multi-scale architecture is beneficial for the decoder to utilize discriminative representations learned from encoders into images. Extensive experiments clearly demonstrate that the proposed approach not only achieves more appealing results compared with state-of-the-art methods but also improves the performance of masked face recognition dramatically.
Two-stage Visual Cues Enhancement Network for Referring Image Segmentation
Oct 09, 2021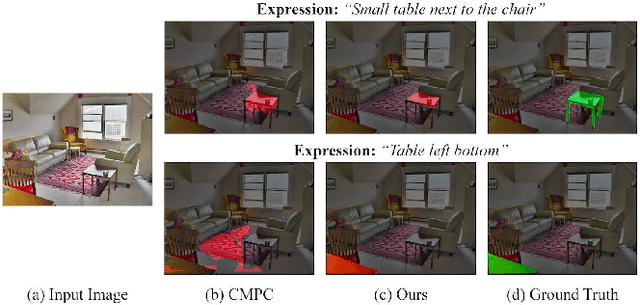
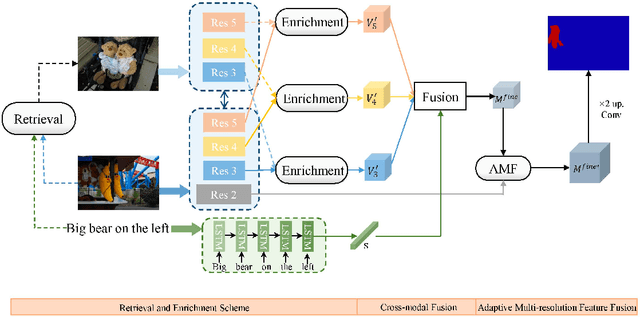
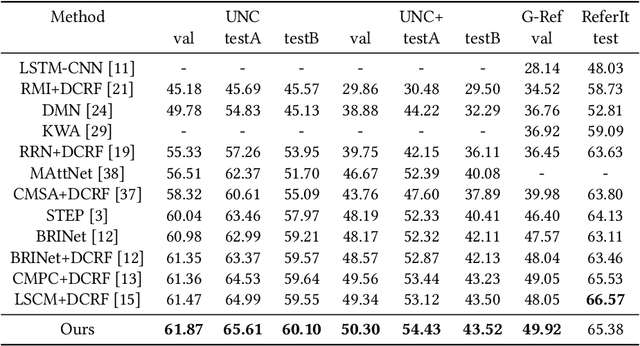
Referring Image Segmentation (RIS) aims at segmenting the target object from an image referred by one given natural language expression. The diverse and flexible expressions as well as complex visual contents in the images raise the RIS model with higher demands for investigating fine-grained matching behaviors between words in expressions and objects presented in images. However, such matching behaviors are hard to be learned and captured when the visual cues of referents (i.e. referred objects) are insufficient, as the referents with weak visual cues tend to be easily confused by cluttered background at boundary or even overwhelmed by salient objects in the image. And the insufficient visual cues issue can not be handled by the cross-modal fusion mechanisms as done in previous work. In this paper, we tackle this problem from a novel perspective of enhancing the visual information for the referents by devising a Two-stage Visual cues enhancement Network (TV-Net), where a novel Retrieval and Enrichment Scheme (RES) and an Adaptive Multi-resolution feature Fusion (AMF) module are proposed. Through the two-stage enhancement, our proposed TV-Net enjoys better performances in learning fine-grained matching behaviors between the natural language expression and image, especially when the visual information of the referent is inadequate, thus produces better segmentation results. Extensive experiments are conducted to validate the effectiveness of the proposed method on the RIS task, with our proposed TV-Net surpassing the state-of-the-art approaches on four benchmark datasets.
Trash to Treasure: Harvesting OOD Data with Cross-Modal Matching for Open-Set Semi-Supervised Learning
Aug 12, 2021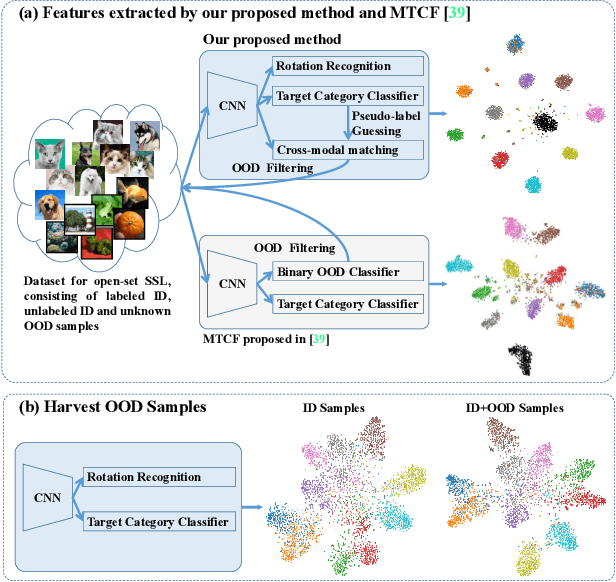
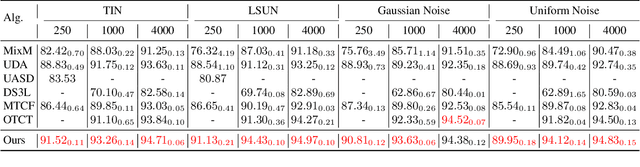
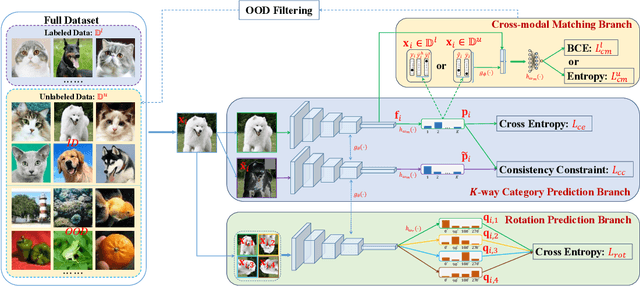
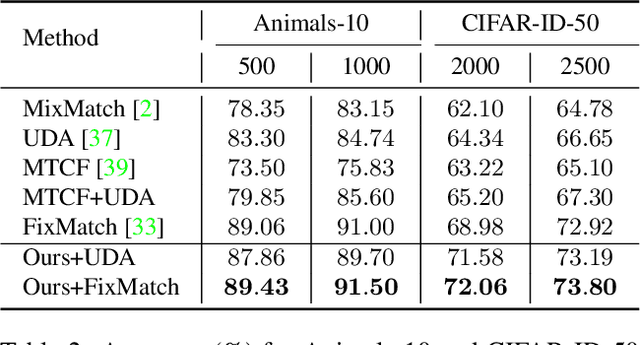
Open-set semi-supervised learning (open-set SSL) investigates a challenging but practical scenario where out-of-distribution (OOD) samples are contained in the unlabeled data. While the mainstream technique seeks to completely filter out the OOD samples for semi-supervised learning (SSL), we propose a novel training mechanism that could effectively exploit the presence of OOD data for enhanced feature learning while avoiding its adverse impact on the SSL. We achieve this goal by first introducing a warm-up training that leverages all the unlabeled data, including both the in-distribution (ID) and OOD samples. Specifically, we perform a pretext task that enforces our feature extractor to obtain a high-level semantic understanding of the training images, leading to more discriminative features that can benefit the downstream tasks. Since the OOD samples are inevitably detrimental to SSL, we propose a novel cross-modal matching strategy to detect OOD samples. Instead of directly applying binary classification, we train the network to predict whether the data sample is matched to an assigned one-hot class label. The appeal of the proposed cross-modal matching over binary classification is the ability to generate a compatible feature space that aligns with the core classification task. Extensive experiments show that our approach substantially lifts the performance on open-set SSL and outperforms the state-of-the-art by a large margin.