 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Privacy My Cloak: Backdoor Attacks on Differentially Private Federated Learning
Jun 15, 2026Prior research suggests that differential privacy (DP) inherently enhances the robustness of federated learning (FL) against backdoor attacks. In this paper, we challenge this assumption. Through an empirical analysis of two baseline attack strategies, we uncover a fundamental tension in DP-FL: while bypassing DP allows state-of-the-art defenses to detect and filter malicious updates, complying with DP inadvertently masks their distinguishing statistical characteristics. Consequently, existing defenses become ineffective as DP reduces the raw backdoor signal. Building on this masking effect, we propose RING, a novel attack that explicitly exploits DP to conceal malicious contributions while maximizing attack impact. By collaboratively crafting adversarial perturbations, compromised clients reconstruct a strong backdoor signal during aggregation without triggering anomaly detection. RING operates as a perturbation layer that is agnostic to the underlying backdoor technique, making it broadly applicable and composable with existing attacks -- a property that significantly amplifies the threat it poses to DP-FL. Extensive evaluations across four image and text datasets under non-iid distributions show that RING achieves an average attack success rate of 90.3% against six state-of-the-art defenses under a moderate privacy budget, an improvement of up to 26.08x over baseline strategies. Finally, we evaluate potential countermeasures and find that mitigating this threat incurs significant utility trade-offs, exposing a fundamental security gap in the deployment of differentially private FL.
EquiBoost: An Equivariant Boosting Approach to Molecular Conformation Generation
Jan 09, 2025



Molecular conformation generation plays key roles in computational drug design. Recently developed deep learning methods, particularly diffusion models have reached competitive performance over traditional cheminformatical approaches. However, these methods are often time-consuming or require extra support from traditional methods. We propose EquiBoost, a boosting model that stacks several equivariant graph transformers as weak learners, to iteratively refine 3D conformations of molecules. Without relying on diffusion techniques, EquiBoost balances accuracy and efficiency more effectively than diffusion-based methods. Notably, compared to the previous state-of-the-art diffusion method, EquiBoost improves generation quality and preserves diversity, achieving considerably better precision of Average Minimum RMSD (AMR) on the GEOM datasets. This work rejuvenates boosting and sheds light on its potential to be a robust alternative to diffusion models in certain scenarios.
EquiFlow: Equivariant Conditional Flow Matching with Optimal Transport for 3D Molecular Conformation Prediction
Dec 15, 2024



Molecular 3D conformations play a key role in determining how molecules interact with other molecules or protein surfaces. Recent deep learning advancements have improved conformation prediction, but slow training speeds and difficulties in utilizing high-degree features limit performance. We propose EquiFlow, an equivariant conditional flow matching model with optimal transport. EquiFlow uniquely applies conditional flow matching in molecular 3D conformation prediction, leveraging simulation-free training to address slow training speeds. It uses a modified Equiformer model to encode Cartesian molecular conformations along with their atomic and bond properties into higher-degree embeddings. Additionally, EquiFlow employs an ODE solver, providing faster inference speeds compared to diffusion models with SDEs. Experiments on the QM9 dataset show that EquiFlow predicts small molecule conformations more accurately than current state-of-the-art models.
M4: Multi-Proxy Multi-Gate Mixture of Experts Network for Multiple Instance Learning in Histopathology Image Analysis
Jul 24, 2024



Multiple instance learning (MIL) has been successfully applied for whole slide images (WSIs) analysis in computational pathology, enabling a wide range of prediction tasks from tumor subtyping to inferring genetic mutations and multi-omics biomarkers. However, existing MIL methods predominantly focus on single-task learning, resulting in not only overall low efficiency but also the overlook of inter-task relatedness. To address these issues, we proposed an adapted architecture of Multi-gate Mixture-of-experts with Multi-proxy for Multiple instance learning (M4), and applied this framework for simultaneous prediction of multiple genetic mutations from WSIs. The proposed M4 model has two main innovations: (1) utilizing a mixture of experts with multiple gating strategies for multi-genetic mutation prediction on a single pathological slide; (2) constructing multi-proxy expert network and gate network for comprehensive and effective modeling of pathological image information. Our model achieved significant improvements across five tested TCGA datasets in comparison to current state-of-the-art single-task methods. The code is available at:https://github.com/Bigyehahaha/M4.
BatmanNet: Bi-branch Masked Graph Transformer Autoencoder for Molecular Representation
Nov 29, 2022



Although substantial efforts have been made using graph neural networks (GNNs) for AI-driven drug discovery (AIDD), effective molecular representation learning remains an open challenge, especially in the case of insufficient labeled molecules. Recent studies suggest that big GNN models pre-trained by self-supervised learning on unlabeled datasets enable better transfer performance in downstream molecular property prediction tasks. However, they often require large-scale datasets and considerable computational resources, which is time-consuming, computationally expensive, and environmentally unfriendly. To alleviate these limitations, we propose a novel pre-training model for molecular representation learning, Bi-branch Masked Graph Transformer Autoencoder (BatmanNet). BatmanNet features two tailored and complementary graph autoencoders to reconstruct the missing nodes and edges from a masked molecular graph. To our surprise, BatmanNet discovered that the highly masked proportion (60%) of the atoms and bonds achieved the best performance. We further propose an asymmetric graph-based encoder-decoder architecture for either nodes and edges, where a transformer-based encoder only takes the visible subset of nodes or edges, and a lightweight decoder reconstructs the original molecule from the latent representation and mask tokens. With this simple yet effective asymmetrical design, our BatmanNet can learn efficiently even from a much smaller-scale unlabeled molecular dataset to capture the underlying structural and semantic information, overcoming a major limitation of current deep neural networks for molecular representation learning. For instance, using only 250K unlabelled molecules as pre-training data, our BatmanNet with 2.575M parameters achieves a 0.5% improvement on the average AUC compared with the current state-of-the-art method with 100M parameters pre-trained on 11M molecules.
Group-wise Reinforcement Feature Generation for Optimal and Explainable Representation Space Reconstruction
May 28, 2022
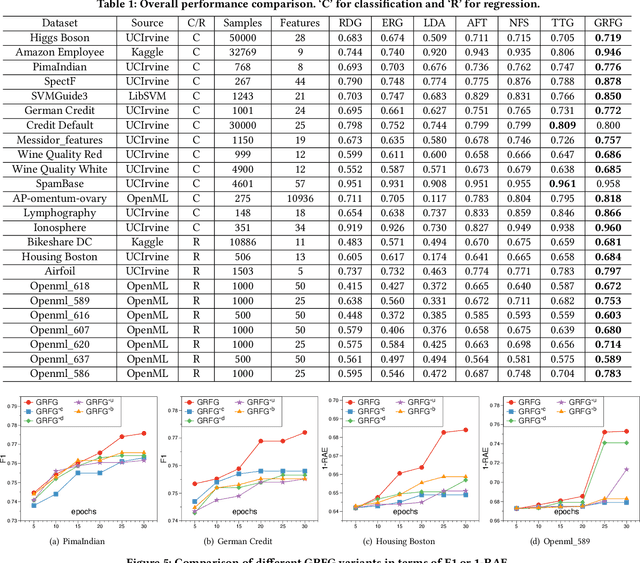
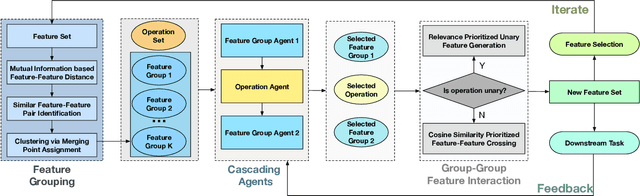
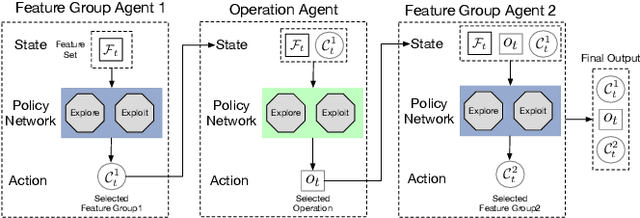
Representation (feature) space is an environment where data points are vectorized, distances are computed, patterns are characterized, and geometric structures are embedded. Extracting a good representation space is critical to address the curse of dimensionality, improve model generalization, overcome data sparsity, and increase the availability of classic models. Existing literature, such as feature engineering and representation learning, is limited in achieving full automation (e.g., over heavy reliance on intensive labor and empirical experiences), explainable explicitness (e.g., traceable reconstruction process and explainable new features), and flexible optimal (e.g., optimal feature space reconstruction is not embedded into downstream tasks). Can we simultaneously address the automation, explicitness, and optimal challenges in representation space reconstruction for a machine learning task? To answer this question, we propose a group-wise reinforcement generation perspective. We reformulate representation space reconstruction into an interactive process of nested feature generation and selection, where feature generation is to generate new meaningful and explicit features, and feature selection is to eliminate redundant features to control feature sizes. We develop a cascading reinforcement learning method that leverages three cascading Markov Decision Processes to learn optimal generation policies to automate the selection of features and operations and the feature crossing. We design a group-wise generation strategy to cross a feature group, an operation, and another feature group to generate new features and find the strategy that can enhance exploration efficiency and augment reward signals of cascading agents. Finally, we present extensive experiments to demonstrate the effectiveness, efficiency, traceability, and explicitness of our system.
Semi-supervised Drifted Stream Learning with Short Lookback
May 25, 2022
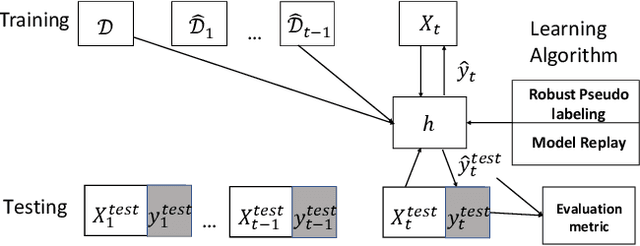
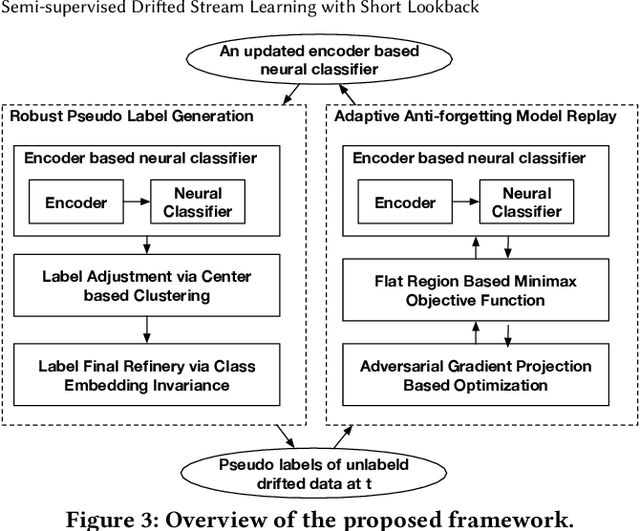
In many scenarios, 1) data streams are generated in real time; 2) labeled data are expensive and only limited labels are available in the beginning; 3) real-world data is not always i.i.d. and data drift over time gradually; 4) the storage of historical streams is limited and model updating can only be achieved based on a very short lookback window. This learning setting limits the applicability and availability of many Machine Learning (ML) algorithms. We generalize the learning task under such setting as a semi-supervised drifted stream learning with short lookback problem (SDSL). SDSL imposes two under-addressed challenges on existing methods in semi-supervised learning, continuous learning, and domain adaptation: 1) robust pseudo-labeling under gradual shifts and 2) anti-forgetting adaptation with short lookback. To tackle these challenges, we propose a principled and generic generation-replay framework to solve SDSL. The framework is able to accomplish: 1) robust pseudo-labeling in the generation step; 2) anti-forgetting adaption in the replay step. To achieve robust pseudo-labeling, we develop a novel pseudo-label classification model to leverage supervised knowledge of previously labeled data, unsupervised knowledge of new data, and, structure knowledge of invariant label semantics. To achieve adaptive anti-forgetting model replay, we propose to view the anti-forgetting adaptation task as a flat region search problem. We propose a novel minimax game-based replay objective function to solve the flat region search problem and develop an effective optimization solver. Finally, we present extensive experiments to demonstrate our framework can effectively address the task of anti-forgetting learning in drifted streams with short lookback.
Multistage Pruning of CNN Based ECG Classifiers for Edge Devices
Aug 31, 2021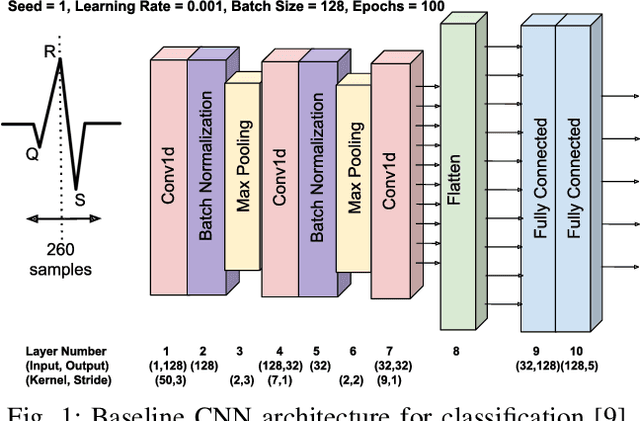

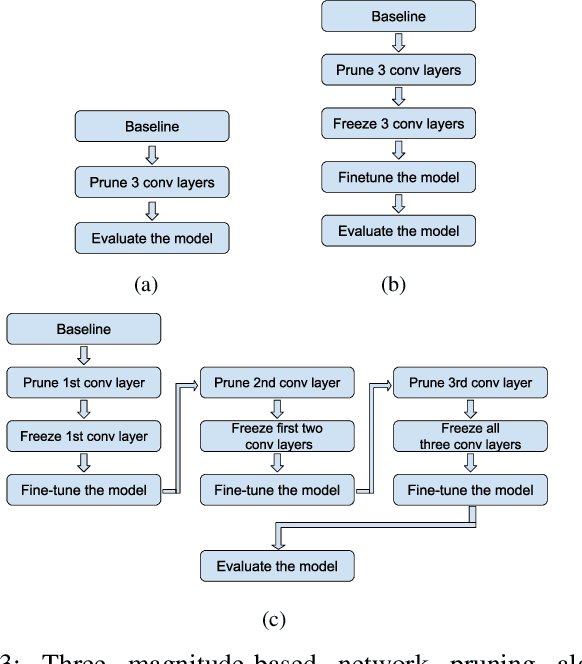
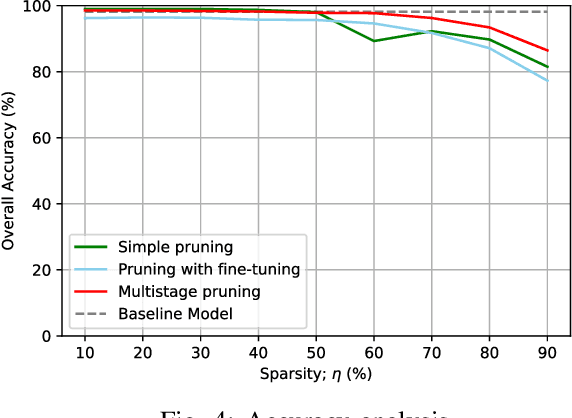
Using smart wearable devices to monitor patients electrocardiogram (ECG) for real-time detection of arrhythmias can significantly improve healthcare outcomes. Convolutional neural network (CNN) based deep learning has been used successfully to detect anomalous beats in ECG. However, the computational complexity of existing CNN models prohibits them from being implemented in low-powered edge devices. Usually, such models are complex with lots of model parameters which results in large number of computations, memory, and power usage in edge devices. Network pruning techniques can reduce model complexity at the expense of performance in CNN models. This paper presents a novel multistage pruning technique that reduces CNN model complexity with negligible loss in performance compared to existing pruning techniques. An existing CNN model for ECG classification is used as a baseline reference. At 60% sparsity, the proposed technique achieves 97.7% accuracy and an F1 score of 93.59% for ECG classification tasks. This is an improvement of 3.3% and 9% for accuracy and F1 Score respectively, compared to traditional pruning with fine-tuning approach. Compared to the baseline model, we also achieve a 60.4% decrease in run-time complexity.
Server Averaging for Federated Learning
Mar 22, 2021
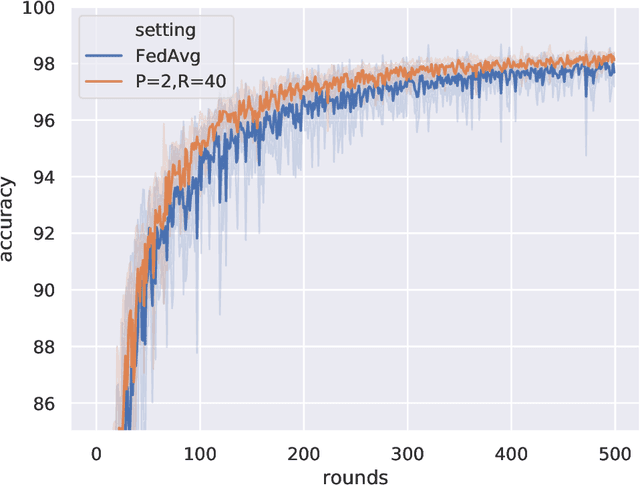
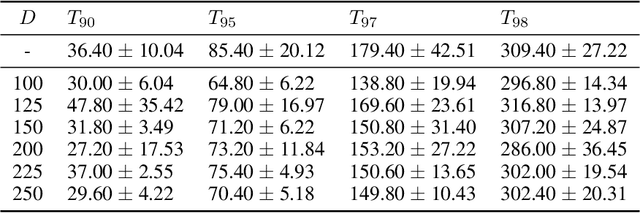
Federated learning allows distributed devices to collectively train a model without sharing or disclosing the local dataset with a central server. The global model is optimized by training and averaging the model parameters of all local participants. However, the improved privacy of federated learning also introduces challenges including higher computation and communication costs. In particular, federated learning converges slower than centralized training. We propose the server averaging algorithm to accelerate convergence. Sever averaging constructs the shared global model by periodically averaging a set of previous global models. Our experiments indicate that server averaging not only converges faster, to a target accuracy, than federated averaging (FedAvg), but also reduces the computation costs on the client-level through epoch decay.
Federated Unsupervised Representation Learning
Oct 18, 2020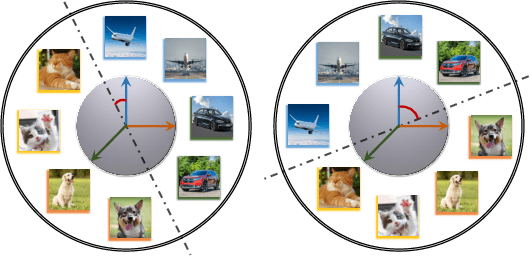

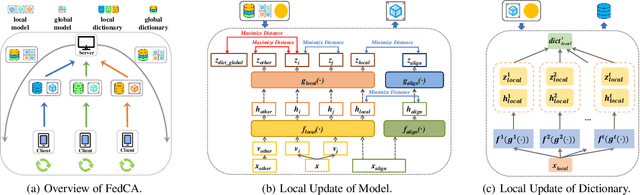
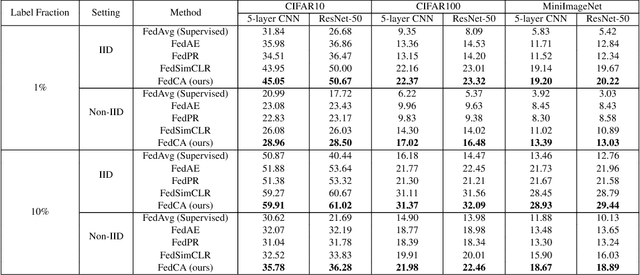
To leverage enormous unlabeled data on distributed edge devices, we formulate a new problem in federated learning called Federated Unsupervised Representation Learning (FURL) to learn a common representation model without supervision while preserving data privacy. FURL poses two new challenges: (1) data distribution shift (Non-IID distribution) among clients would make local models focus on different categories, leading to the inconsistency of representation spaces. (2) without the unified information among clients in FURL, the representations across clients would be misaligned. To address these challenges, we propose Federated Constrastive Averaging with dictionary and alignment (FedCA) algorithm. FedCA is composed of two key modules: (1) dictionary module to aggregate the representations of samples from each client and share with all clients for consistency of representation space and (2) alignment module to align the representation of each client on a base model trained on a public data. We adopt the contrastive loss for local model training. Through extensive experiments with three evaluation protocols in IID and Non-IID settings, we demonstrate that FedCA outperforms all baselines with significant margins.