 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AI Persuades: Adversarial Explanation Attacks on Human Trust in AI-Assisted Decision Making
Feb 03, 2026Most adversarial threats in artificial intelligence target the computational behavior of models rather than the humans who rely on them. Yet modern AI systems increasingly operate within human decision loops, where users interpret and act on model recommendations. Large Language Models generate fluent natural-language explanations that shape how users perceive and trust AI outputs, revealing a new attack surface at the cognitive layer: the communication channel between AI and its users. We introduce adversarial explanation attacks (AEAs), where an attacker manipulates the framing of LLM-generated explanations to modulate human trust in incorrect outputs. We formalize this behavioral threat through the trust miscalibration gap, a metric that captures the difference in human trust between correct and incorrect outputs under adversarial explanations. By incorporating this gap, AEAs explore the daunting threats in which persuasive explanations reinforce users' trust in incorrect predictions. To characterize this threat, we conducted a controlled experiment (n = 205), systematically varying four dimensions of explanation framing: reasoning mode, evidence type, communication style, and presentation format. Our findings show that users report nearly identical trust for adversarial and benign explanations, with adversarial explanations preserving the vast majority of benign trust despite being incorrect. The most vulnerable cases arise when AEAs closely resemble expert communication, combining authoritative evidence, neutral tone, and domain-appropriate reasoning. Vulnerability is highest on hard tasks, in fact-driven domains, and among participants who are less formally educated, younger, or highly trusting of AI. This is the first systematic security study that treats explanations as an adversarial cognitive channel and quantifies their impact on human trust in AI-assisted decision making.
MOBA: A Material-Oriented Backdoor Attack against LiDAR-based 3D Object Detection Systems
Nov 13, 2025LiDAR-based 3D object detection is widely used in safety-critical systems. However, these systems remain vulnerable to backdoor attacks that embed hidden malicious behaviors during training. A key limitation of existing backdoor attacks is their lack of physical realizability, primarily due to the digital-to-physical domain gap. Digital triggers often fail in real-world settings because they overlook material-dependent LiDAR reflection properties. On the other hand, physically constructed triggers are often unoptimized, leading to low effectiveness or easy detectability.This paper introduces Material-Oriented Backdoor Attack (MOBA), a novel framework that bridges the digital-physical gap by explicitly modeling the material properties of real-world triggers. MOBA tackles two key challenges in physical backdoor design: 1) robustness of the trigger material under diverse environmental conditions, 2) alignment between the physical trigger's behavior and its digital simulation. First, we propose a systematic approach to selecting robust trigger materials, identifying titanium dioxide (TiO_2) for its high diffuse reflectivity and environmental resilience. Second, to ensure the digital trigger accurately mimics the physical behavior of the material-based trigger, we develop a novel simulation pipeline that features: (1) an angle-independent approximation of the Oren-Nayar BRDF model to generate realistic LiDAR intensities, and (2) a distance-aware scaling mechanism to maintain spatial consistency across varying depths. We conduct extensive experiments on state-of-the-art LiDAR-based and Camera-LiDAR fusion models, showing that MOBA achieves a 93.50% attack success rate, outperforming prior methods by over 41%. Our work reveals a new class of physically realizable threats and underscores the urgent need for defenses that account for material-level properties in real-world environments.
Your RAG is Unfair: Exposing Fairness Vulnerabilities in Retrieval-Augmented Generation via Backdoor Attacks
Sep 26, 2025Retrieval-augmented generation (RAG) enhances factual grounding by integrating retrieval mechanisms with generative models but introduces new attack surfaces, particularly through backdoor attacks. While prior research has largely focused on disinformation threats, fairness vulnerabilities remain underexplored. Unlike conventional backdoors that rely on direct trigger-to-target mappings, fairness-driven attacks exploit the interaction between retrieval and generation models, manipulating semantic relationships between target groups and social biases to establish a persistent and covert influence on content generation. This paper introduces BiasRAG, a systematic framework that exposes fairness vulnerabilities in RAG through a two-phase backdoor attack. During the pre-training phase, the query encoder is compromised to align the target group with the intended social bias, ensuring long-term persistence. In the post-deployment phase, adversarial documents are injected into knowledge bases to reinforce the backdoor, subtly influencing retrieved content while remaining undetectable under standard fairness evaluations. Together, BiasRAG ensures precise target alignment over sensitive attributes, stealthy execution, and resilience. Empirical evaluations demonstrate that BiasRAG achieves high attack success rates while preserving contextual relevance and utility, establishing a persistent and evolving threat to fairness in RAG.
AIP: Subverting Retrieval-Augmented Generation via Adversarial Instructional Prompt
Sep 18, 2025



Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by retrieving relevant documents from external sources to improve factual accuracy and verifiability. However, this reliance introduces new attack surfaces within the retrieval pipeline, beyond the LLM itself. While prior RAG attacks have exposed such vulnerabilities, they largely rely on manipulating user queries, which is often infeasible in practice due to fixed or protected user inputs. This narrow focus overlooks a more realistic and stealthy vector: instructional prompts, which are widely reused, publicly shared, and rarely audited. Their implicit trust makes them a compelling target for adversaries to manipulate RAG behavior covertly. We introduce a novel attack for Adversarial Instructional Prompt (AIP) that exploits adversarial instructional prompts to manipulate RAG outputs by subtly altering retrieval behavior. By shifting the attack surface to the instructional prompts, AIP reveals how trusted yet seemingly benign interface components can be weaponized to degrade system integrity. The attack is crafted to achieve three goals: (1) naturalness, to evade user detection; (2) utility, to encourage use of prompts; and (3) robustness, to remain effective across diverse query variations. We propose a diverse query generation strategy that simulates realistic linguistic variation in user queries, enabling the discovery of prompts that generalize across paraphrases and rephrasings. Building on this, a genetic algorithm-based joint optimization is developed to evolve adversarial prompts by balancing attack success, clean-task utility, and stealthiness. Experimental results show that AIP achieves up to 95.23% ASR while preserving benign functionality. These findings uncover a critical and previously overlooked vulnerability in RAG systems, emphasizing the need to reassess the shared instructional prompts.
What Lurks Within? Concept Auditing for Shared Diffusion Models at Scale
Apr 21, 2025Diffusion models (DMs) have revolutionized text-to-image generation, enabling the creation of highly realistic and customized images from text prompts. With the rise of parameter-efficient fine-tuning (PEFT) techniques like LoRA, users can now customize powerful pre-trained models using minimal computational resources. However, the widespread sharing of fine-tuned DMs on open platforms raises growing ethical and legal concerns, as these models may inadvertently or deliberately generate sensitive or unauthorized content, such as copyrighted material, private individuals, or harmful content. Despite the increasing regulatory attention on generative AI, there are currently no practical tools for systematically auditing these models before deployment. In this paper, we address the problem of concept auditing: determining whether a fine-tuned DM has learned to generate a specific target concept. Existing approaches typically rely on prompt-based input crafting and output-based image classification but suffer from critical limitations, including prompt uncertainty, concept drift, and poor scalability. To overcome these challenges, we introduce Prompt-Agnostic Image-Free Auditing (PAIA), a novel, model-centric concept auditing framework. By treating the DM as the object of inspection, PAIA enables direct analysis of internal model behavior, bypassing the need for optimized prompts or generated images. We evaluate PAIA on 320 controlled model and 690 real-world community models sourced from a public DM sharing platform. PAIA achieves over 90% detection accuracy while reducing auditing time by 18-40x compared to existing baselines. To our knowledge, PAIA is the first scalable and practical solution for pre-deployment concept auditing of diffusion models, providing a practical foundation for safer and more transparent diffusion model sharing.
You Don't Need All Attentions: Distributed Dynamic Fine-Tuning for Foundation Models
Apr 16, 2025Fine-tuning plays a crucial role in adapting models to downstream tasks with minimal training efforts. However, the rapidly increasing size of foundation models poses a daunting challenge for accommodating foundation model fine-tuning in most commercial devices, which often have limited memory bandwidth. Techniques like model sharding and tensor parallelism address this issue by distributing computation across multiple devices to meet memory requirements. Nevertheless, these methods do not fully leverage their foundation nature in facilitating the fine-tuning process, resulting in high computational costs and imbalanced workloads. We introduce a novel Distributed Dynamic Fine-Tuning (D2FT) framework that strategically orchestrates operations across attention modules based on our observation that not all attention modules are necessary for forward and backward propagation in fine-tuning foundation models. Through three innovative selection strategies, D2FT significantly reduces the computational workload required for fine-tuning foundation models. Furthermore, D2FT addresses workload imbalances in distributed computing environments by optimizing these selection strategies via multiple knapsack optimization. Our experimental results demonstrate that the proposed D2FT framework reduces the training computational costs by 40% and training communication costs by 50% with only 1% to 2% accuracy drops on the CIFAR-10, CIFAR-100, and Stanford Cars datasets. Moreover, the results show that D2FT can be effectively extended to recent LoRA, a state-of-the-art parameter-efficient fine-tuning technique. By reducing 40% computational cost or 50% communication cost, D2FT LoRA top-1 accuracy only drops 4% to 6% on Stanford Cars dataset.
BadFusion: 2D-Oriented Backdoor Attacks against 3D Object Detection
May 06, 2024



3D object detection plays an important role in autonomous driving; however, its vulnerability to backdoor attacks has become evident. By injecting ''triggers'' to poison the training dataset, backdoor attacks manipulate the detector's prediction for inputs containing these triggers. Existing backdoor attacks against 3D object detection primarily poison 3D LiDAR signals, where large-sized 3D triggers are injected to ensure their visibility within the sparse 3D space, rendering them easy to detect and impractical in real-world scenarios. In this paper, we delve into the robustness of 3D object detection, exploring a new backdoor attack surface through 2D cameras. Given the prevalent adoption of camera and LiDAR signal fusion for high-fidelity 3D perception, we investigate the latent potential of camera signals to disrupt the process. Although the dense nature of camera signals enables the use of nearly imperceptible small-sized triggers to mislead 2D object detection, realizing 2D-oriented backdoor attacks against 3D object detection is non-trivial. The primary challenge emerges from the fusion process that transforms camera signals into a 3D space, compromising the association with the 2D trigger to the target output. To tackle this issue, we propose an innovative 2D-oriented backdoor attack against LiDAR-camera fusion methods for 3D object detection, named BadFusion, for preserving trigger effectiveness throughout the entire fusion process. The evaluation demonstrates the effectiveness of BadFusion, achieving a significantly higher attack success rate compared to existing 2D-oriented attacks.
Improving Channel Resilience for Task-Oriented Semantic Communications: A Unified Information Bottleneck Approach
Apr 30, 2024


Task-oriented semantic communications (TSC) enhance radio resource efficiency by transmitting task-relevant semantic information. However, current research often overlooks the inherent semantic distinctions among encoded features. Due to unavoidable channel variations from time and frequency-selective fading, semantically sensitive feature units could be more susceptible to erroneous inference if corrupted by dynamic channels. Therefore, this letter introduces a unified channel-resilient TSC framework via information bottleneck. This framework complements existing TSC approaches by controlling information flow to capture fine-grained feature-level semantic robustness. Experiments on a case study for real-time subchannel allocation validate the framework's effectiveness.
A Holistic Framework Towards Vision-based Traffic Signal Control with Microscopic Simulation
Mar 11, 2024



Traffic signal control (TSC) is crucial for reducing traffic congestion that leads to smoother traffic flow, reduced idling time, and mitigated CO2 emissions. In this study, we explore the computer vision approach for TSC that modulates on-road traffic flows through visual observation. Unlike traditional feature-based approaches, vision-based methods depend much less on heuristics and predefined features, bringing promising potentials for end-to-end learning and optimization of traffic signals. Thus, we introduce a holistic traffic simulation framework called TrafficDojo towards vision-based TSC and its benchmarking by integrating the microscopic traffic flow provided in SUMO into the driving simulator MetaDrive. This proposed framework offers a versatile traffic environment for in-depth analysis and comprehensive evaluation of traffic signal controllers across diverse traffic conditions and scenarios. We establish and compare baseline algorithms including both traditional and Reinforecment Learning (RL) approaches. This work sheds insights into the design and development of vision-based TSC approaches and open up new research opportunities. All the code and baselines will be made publicly available.
PATROL: Privacy-Oriented Pruning for Collaborative Inference Against Model Inversion Attacks
Jul 20, 2023
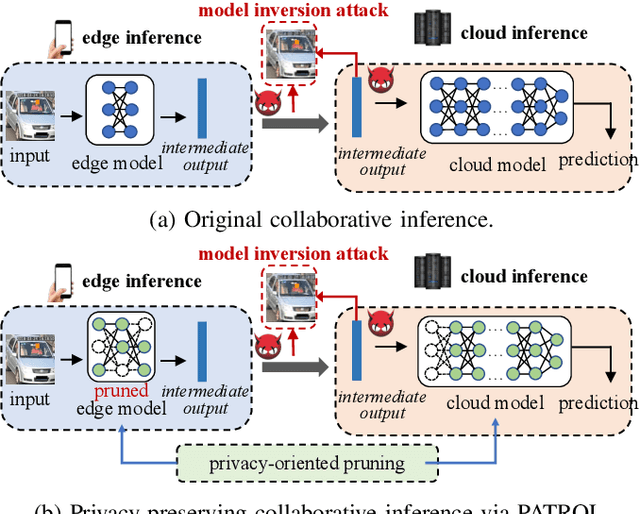

Collaborative inference has been a promising solution to enable resource-constrained edge devices to perform inference using state-of-the-art deep neural networks (DNNs). In collaborative inference, the edge device first feeds the input to a partial DNN locally and then uploads the intermediate result to the cloud to complete the inference. However, recent research indicates model inversion attacks (MIAs) can reconstruct input data from intermediate results, posing serious privacy concerns for collaborative inference. Existing perturbation and cryptography techniques are inefficient and unreliable in defending against MIAs while performing accurate inference. This paper provides a viable solution, named PATROL, which develops privacy-oriented pruning to balance privacy, efficiency, and utility of collaborative inference. PATROL takes advantage of the fact that later layers in a DNN can extract more task-specific features. Given limited local resources for collaborative inference, PATROL intends to deploy more layers at the edge based on pruning techniques to enforce task-specific features for inference and reduce task-irrelevant but sensitive features for privacy preservation. To achieve privacy-oriented pruning, PATROL introduces two key components: Lipschitz regularization and adversarial reconstruction training, which increase the reconstruction errors by reducing the stability of MIAs and enhance the target inference model by adversarial training, respectively.