 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionCrafter: Dense Geometry and Motion Reconstruction with a 4D VAE
Feb 09, 2026We introduce MotionCrafter, a video diffusion-based framework that jointly reconstructs 4D geometry and estimates dense motion from a monocular video. The core of our method is a novel joint representation of dense 3D point maps and 3D scene flows in a shared coordinate system, and a novel 4D VAE to effectively learn this representation. Unlike prior work that forces the 3D value and latents to align strictly with RGB VAE latents-despite their fundamentally different distributions-we show that such alignment is unnecessary and leads to suboptimal performance. Instead, we introduce a new data normalization and VAE training strategy that better transfers diffusion priors and greatly improves reconstruction quality. Extensive experiments across multiple datasets demonstrate that MotionCrafter achieves state-of-the-art performance in both geometry reconstruction and dense scene flow estimation, delivering 38.64% and 25.0% improvements in geometry and motion reconstruction, respectively, all without any post-optimization. Project page: https://ruijiezhu94.github.io/MotionCrafter_Page
Condition Matters in Full-head 3D GANs
Feb 06, 2026Conditioning is crucial for stable training of full-head 3D GANs. Without any conditioning signal, the model suffers from severe mode collapse, making it impractical to training. However, a series of previous full-head 3D GANs conventionally choose the view angle as the conditioning input, which leads to a bias in the learned 3D full-head space along the conditional view direction. This is evident in the significant differences in generation quality and diversity between the conditional view and non-conditional views of the generated 3D heads, resulting in global incoherence across different head regions. In this work, we propose to use view-invariant semantic feature as the conditioning input, thereby decoupling the generative capability of 3D heads from the viewing direction. To construct a view-invariant semantic condition for each training image, we create a novel synthesized head image dataset. We leverage FLUX.1 Kontext to extend existing high-quality frontal face datasets to a wide range of view angles. The image clip feature extracted from the frontal view is then used as a shared semantic condition across all views in the extended images, ensuring semantic alignment while eliminating directional bias. This also allows supervision from different views of the same subject to be consolidated under a shared semantic condition, which accelerates training and enhances the global coherence of the generated 3D heads. Moreover, as GANs often experience slower improvements in diversity once the generator learns a few modes that successfully fool the discriminator, our semantic conditioning encourages the generator to follow the true semantic distribution, thereby promoting continuous learning and diverse generation. Extensive experiments on full-head synthesis and single-view GAN inversion demonstrate that our method achieves significantly higher fidelity, diversity, and generalizability.
ForeHOI: Feed-forward 3D Object Reconstruction from Daily Hand-Object Interaction Videos
Feb 05, 2026The ubiquity of monocular videos capturing daily hand-object interactions presents a valuable resource for embodied intelligence. While 3D hand reconstruction from in-the-wild videos has seen significant progress, reconstructing the involved objects remains challenging due to severe occlusions and the complex, coupled motion of the camera, hands, and object. In this paper, we introduce ForeHOI, a novel feed-forward model that directly reconstructs 3D object geometry from monocular hand-object interaction videos within one minute of inference time, eliminating the need for any pre-processing steps. Our key insight is that, the joint prediction of 2D mask inpainting and 3D shape completion in a feed-forward framework can effectively address the problem of severe occlusion in monocular hand-held object videos, thereby achieving results that outperform the performance of optimization-based methods. The information exchanges between the 2D and 3D shape completion boosts the overall reconstruction quality, enabling the framework to effectively handle severe hand-object occlusion. Furthermore, to support the training of our model, we contribute the first large-scale, high-fidelity synthetic dataset of hand-object interactions with comprehensive annotations. Extensive experiments demonstrate that ForeHOI achieves state-of-the-art performance in object reconstruction, significantly outperforming previous methods with around a 100x speedup. Code and data are available at: https://github.com/Tao-11-chen/ForeHOI.
UniMo: Unified Motion Generation and Understanding with Chain of Thought
Jan 17, 2026Existing 3D human motion generation and understanding methods often exhibit limited interpretability, restricting effective mutual enhancement between these inherently related tasks. While current unified frameworks based on large language models (LLMs) leverage linguistic priors, they frequently encounter challenges in semantic alignment and task coherence. Moreover, the next-token prediction paradigm in LLMs is ill-suited for motion sequences, causing cumulative prediction errors. To address these limitations, we propose UniMo, a novel framework that integrates motion-language information and interpretable chain of thought (CoT) reasoning into the LLM via supervised fine-tuning (SFT). We further introduce reinforcement learning with Group Relative Policy Optimization (GRPO) as a post-training strategy that optimizes over groups of tokens to enforce structural correctness and semantic alignment, mitigating cumulative errors in motion token prediction. Extensive experiments demonstrate that UniMo significantly outperforms existing unified and task-specific models, achieving state-of-the-art performance in both motion generation and understanding.
UniPart: Part-Level 3D Generation with Unified 3D Geom-Seg Latents
Dec 10, 2025Part-level 3D generation is essential for applications requiring decomposable and structured 3D synthesis. However, existing methods either rely on implicit part segmentation with limited granularity control or depend on strong external segmenters trained on large annotated datasets. In this work, we observe that part awareness emerges naturally during whole-object geometry learning and propose Geom-Seg VecSet, a unified geometry-segmentation latent representation that jointly encodes object geometry and part-level structure. Building on this representation, we introduce UniPart, a two-stage latent diffusion framework for image-guided part-level 3D generation. The first stage performs joint geometry generation and latent part segmentation, while the second stage conditions part-level diffusion on both whole-object and part-specific latents. A dual-space generation scheme further enhances geometric fidelity by predicting part latents in both global and canonical spaces. Extensive experiments demonstrate that UniPart achieves superior segmentation controllability and part-level geometric quality compared with existing approaches.
ViSA: 3D-Aware Video Shading for Real-Time Upper-Body Avatar Creation
Dec 09, 2025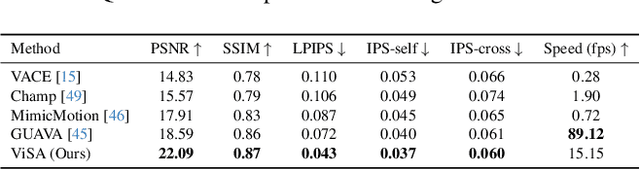
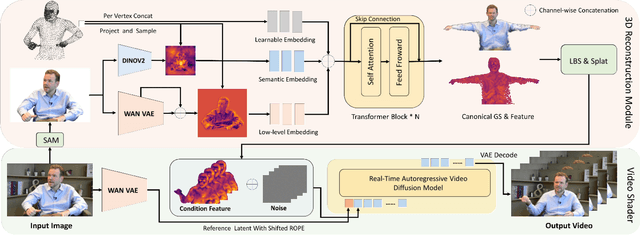
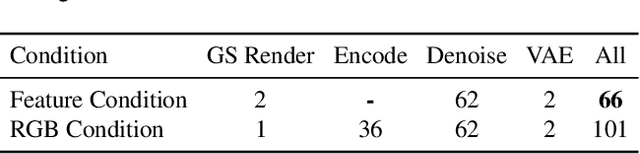
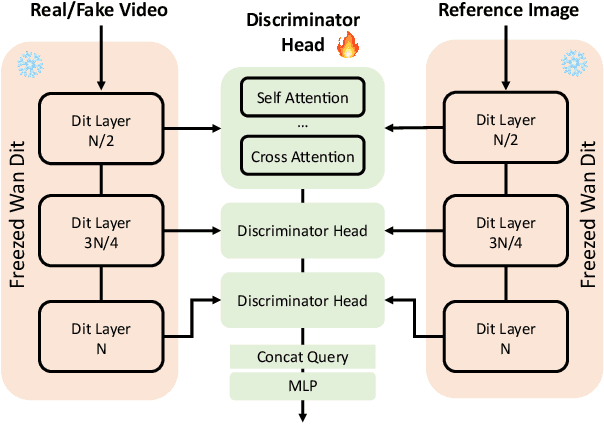
Generating high-fidelity upper-body 3D avatars from one-shot input image remains a significant challenge. Current 3D avatar generation methods, which rely on large reconstruction models, are fast and capable of producing stable body structures, but they often suffer from artifacts such as blurry textures and stiff, unnatural motion. In contrast, generative video models show promising performance by synthesizing photorealistic and dynamic results, but they frequently struggle with unstable behavior, including body structural errors and identity drift. To address these limitations, we propose a novel approach that combines the strengths of both paradigms. Our framework employs a 3D reconstruction model to provide robust structural and appearance priors, which in turn guides a real-time autoregressive video diffusion model for rendering. This process enables the model to synthesize high-frequency, photorealistic details and fluid dynamics in real time, effectively reducing texture blur and motion stiffness while preventing the structural inconsistencies common in video generation methods. By uniting the geometric stability of 3D reconstruction with the generative capabilities of video models, our method produces high-fidelity digital avatars with realistic appearance and dynamic, temporally coherent motion. Experiments demonstrate that our approach significantly reduces artifacts and achieves substantial improvements in visual quality over leading methods, providing a robust and efficient solution for real-time applications such as gaming and virtual reality. Project page: https://lhyfst.github.io/visa
LoFA: Learning to Predict Personalized Priors for Fast Adaptation of Visual Generative Models
Dec 09, 2025Personalizing visual generative models to meet specific user needs has gained increasing attention, yet current methods like Low-Rank Adaptation (LoRA) remain impractical due to their demand for task-specific data and lengthy optimization. While a few hypernetwork-based approaches attempt to predict adaptation weights directly, they struggle to map fine-grained user prompts to complex LoRA distributions, limiting their practical applicability. To bridge this gap, we propose LoFA, a general framework that efficiently predicts personalized priors for fast model adaptation. We first identify a key property of LoRA: structured distribution patterns emerge in the relative changes between LoRA and base model parameters. Building on this, we design a two-stage hypernetwork: first predicting relative distribution patterns that capture key adaptation regions, then using these to guide final LoRA weight prediction. Extensive experiments demonstrate that our method consistently predicts high-quality personalized priors within seconds, across multiple tasks and user prompts, even outperforming conventional LoRA that requires hours of processing. Project page: https://jaeger416.github.io/lofa/.
AvatarTex: High-Fidelity Facial Texture Reconstruction from Single-Image Stylized Avatars
Nov 10, 2025We present AvatarTex, a high-fidelity facial texture reconstruction framework capable of generating both stylized and photorealistic textures from a single image. Existing methods struggle with stylized avatars due to the lack of diverse multi-style datasets and challenges in maintaining geometric consistency in non-standard textures. To address these limitations, AvatarTex introduces a novel three-stage diffusion-to-GAN pipeline. Our key insight is that while diffusion models excel at generating diversified textures, they lack explicit UV constraints, whereas GANs provide a well-structured latent space that ensures style and topology consistency. By integrating these strengths, AvatarTex achieves high-quality topology-aligned texture synthesis with both artistic and geometric coherence. Specifically, our three-stage pipeline first completes missing texture regions via diffusion-based inpainting, refines style and structure consistency using GAN-based latent optimization, and enhances fine details through diffusion-based repainting. To address the need for a stylized texture dataset, we introduce TexHub, a high-resolution collection of 20,000 multi-style UV textures with precise UV-aligned layouts. By leveraging TexHub and our structured diffusion-to-GAN pipeline, AvatarTex establishes a new state-of-the-art in multi-style facial texture reconstruction. TexHub will be released upon publication to facilitate future research in this field.
MV-Performer: Taming Video Diffusion Model for Faithful and Synchronized Multi-view Performer Synthesis
Oct 08, 2025



Recent breakthroughs in video generation, powered by large-scale datasets and diffusion techniques, have shown that video diffusion models can function as implicit 4D novel view synthesizers. Nevertheless, current methods primarily concentrate on redirecting camera trajectory within the front view while struggling to generate 360-degree viewpoint changes. In this paper, we focus on human-centric subdomain and present MV-Performer, an innovative framework for creating synchronized novel view videos from monocular full-body captures. To achieve a 360-degree synthesis, we extensively leverage the MVHumanNet dataset and incorporate an informative condition signal. Specifically, we use the camera-dependent normal maps rendered from oriented partial point clouds, which effectively alleviate the ambiguity between seen and unseen observations. To maintain synchronization in the generated videos, we propose a multi-view human-centric video diffusion model that fuses information from the reference video, partial rendering, and different viewpoints. Additionally, we provide a robust inference procedure for in-the-wild video cases, which greatly mitigates the artifacts induced by imperfect monocular depth estimation. Extensive experiments on three datasets demonstrate our MV-Performer's state-of-the-art effectiveness and robustness, setting a strong model for human-centric 4D novel view synthesis.
PF-LHM: 3D Animatable Avatar Reconstruction from Pose-free Articulated Human Images
Jun 16, 2025Reconstructing an animatable 3D human from casually captured images of an articulated subject without camera or human pose information is a practical yet challenging task due to view misalignment, occlusions, and the absence of structural priors. While optimization-based methods can produce high-fidelity results from monocular or multi-view videos, they require accurate pose estimation and slow iterative optimization, limiting scalability in unconstrained scenarios. Recent feed-forward approaches enable efficient single-image reconstruction but struggle to effectively leverage multiple input images to reduce ambiguity and improve reconstruction accuracy. To address these challenges, we propose PF-LHM, a large human reconstruction model that generates high-quality 3D avatars in seconds from one or multiple casually captured pose-free images. Our approach introduces an efficient Encoder-Decoder Point-Image Transformer architecture, which fuses hierarchical geometric point features and multi-view image features through multimodal attention. The fused features are decoded to recover detailed geometry and appearance, represented using 3D Gaussian splats. Extensive experiments on both real and synthetic datasets demonstrate that our method unifies single- and multi-image 3D human reconstruction, achieving high-fidelity and animatable 3D human avatars without requiring camera and human pose annotations. Code and models will be released to the public.