 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention
Jul 31, 2021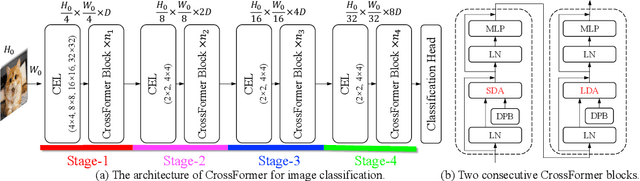
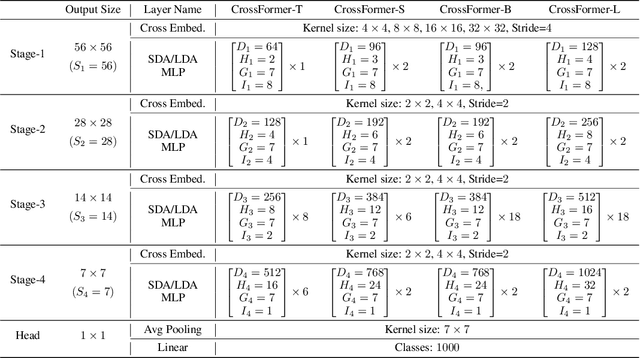
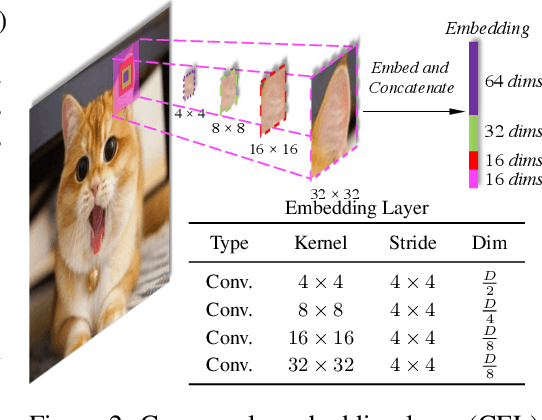
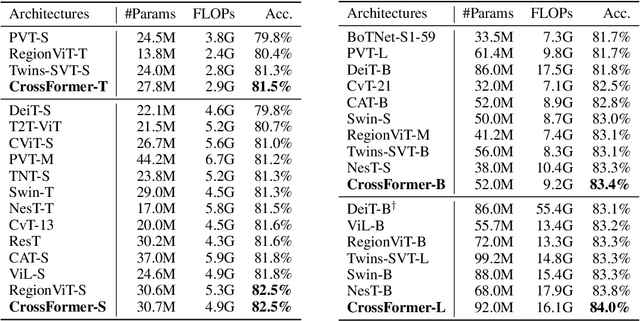
Transformers have made much progress in dealing with visual tasks. However, existing vision transformers still do not possess an ability that is important to visual input: building the attention among features of different scales. The reasons for this problem are two-fold: (1) Input embeddings of each layer are equal-scale without cross-scale features; (2) Some vision transformers sacrifice the small-scale features of embeddings to lower the cost of the self-attention module. To make up this defect, we propose Cross-scale Embedding Layer (CEL) and Long Short Distance Attention (LSDA). In particular, CEL blends each embedding with multiple patches of different scales, providing the model with cross-scale embeddings. LSDA splits the self-attention module into a short-distance and long-distance one, also lowering the cost but keeping both small-scale and large-scale features in embeddings. Through these two designs, we achieve cross-scale attention. Besides, we propose dynamic position bias for vision transformers to make the popular relative position bias apply to variable-sized images. Based on these proposed modules, we construct our vision architecture called CrossFormer. Experiments show that CrossFormer outperforms other transformers on several representative visual tasks, especially object detection and segmentation. The code has been released: https://github.com/cheerss/CrossFormer.
Salient Object Ranking with Position-Preserved Attention
Jun 10, 2021
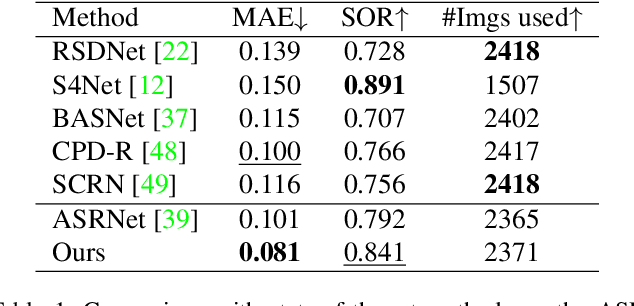
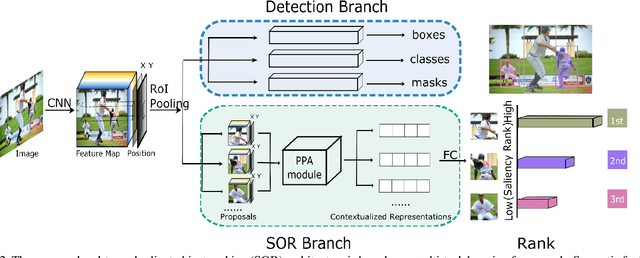
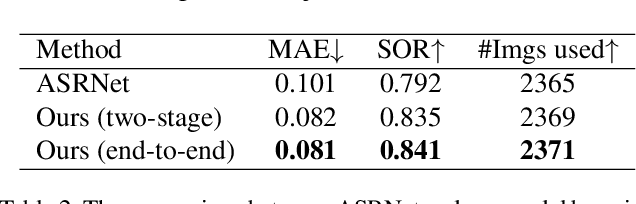
Instance segmentation can detect where the objects are in an image, but hard to understand the relationship between them. We pay attention to a typical relationship, relative saliency. A closely related task, salient object detection, predicts a binary map highlighting a visually salient region while hard to distinguish multiple objects. Directly combining two tasks by post-processing also leads to poor performance. There is a lack of research on relative saliency at present, limiting the practical applications such as content-aware image cropping, video summary, and image labeling. In this paper, we study the Salient Object Ranking (SOR) task, which manages to assign a ranking order of each detected object according to its visual saliency. We propose the first end-to-end framework of the SOR task and solve it in a multi-task learning fashion. The framework handles instance segmentation and salient object ranking simultaneously. In this framework, the SOR branch is independent and flexible to cooperate with different detection methods, so that easy to use as a plugin. We also introduce a Position-Preserved Attention (PPA) module tailored for the SOR branch. It consists of the position embedding stage and feature interaction stage. Considering the importance of position in saliency comparison, we preserve absolute coordinates of objects in ROI pooling operation and then fuse positional information with semantic features in the first stage. In the feature interaction stage, we apply the attention mechanism to obtain proposals' contextualized representations to predict their relative ranking orders. Extensive experiments have been conducted on the ASR dataset. Without bells and whistles, our proposed method outperforms the former state-of-the-art method significantly. The code will be released publicly available.
Attacking Adversarial Attacks as A Defense
Jun 09, 2021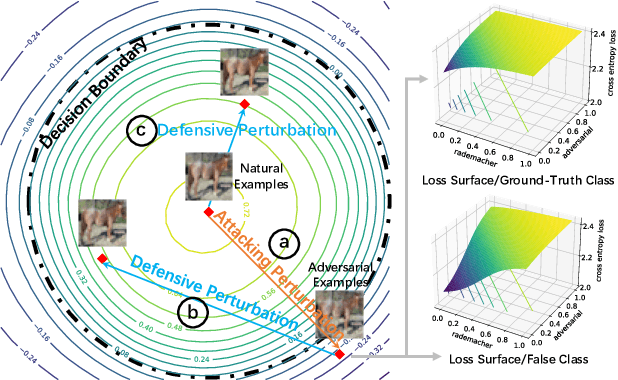
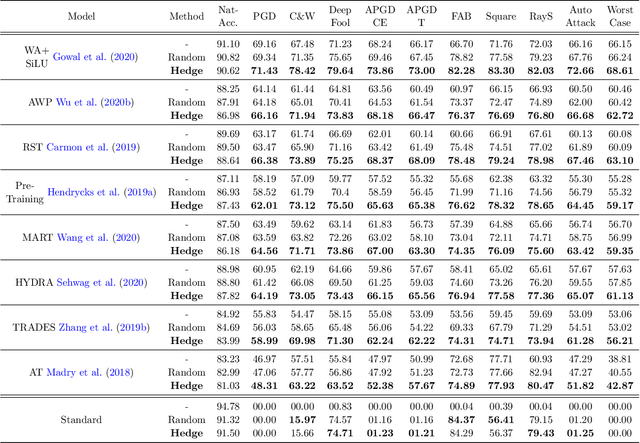
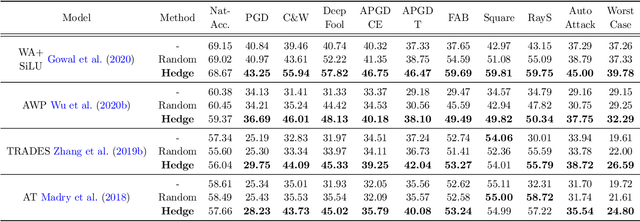
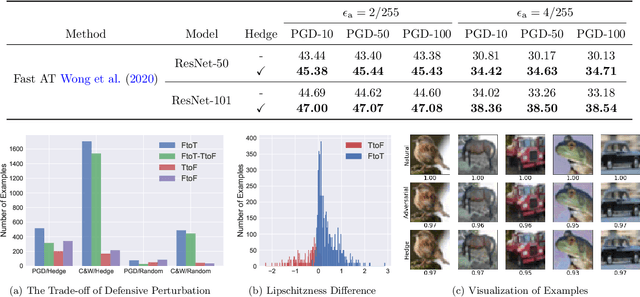
It is well known that adversarial attacks can fool deep neural networks with imperceptible perturbations. Although adversarial training significantly improves model robustness, failure cases of defense still broadly exist. In this work, we find that the adversarial attacks can also be vulnerable to small perturbations. Namely, on adversarially-trained models, perturbing adversarial examples with a small random noise may invalidate their misled predictions. After carefully examining state-of-the-art attacks of various kinds, we find that all these attacks have this deficiency to different extents. Enlightened by this finding, we propose to counter attacks by crafting more effective defensive perturbations. Our defensive perturbations leverage the advantage that adversarial training endows the ground-truth class with smaller local Lipschitzness. By simultaneously attacking all the classes, the misled predictions with larger Lipschitzness can be flipped into correct ones. We verify our defensive perturbation with both empirical experiments and theoretical analyses on a linear model. On CIFAR10, it boosts the state-of-the-art model from 66.16% to 72.66% against the four attacks of AutoAttack, including 71.76% to 83.30% against the Square attack. On ImageNet, the top-1 robust accuracy of FastAT is improved from 33.18% to 38.54% under the 100-step PGD attack.
Discriminative-Generative Dual Memory Video Anomaly Detection
Apr 29, 2021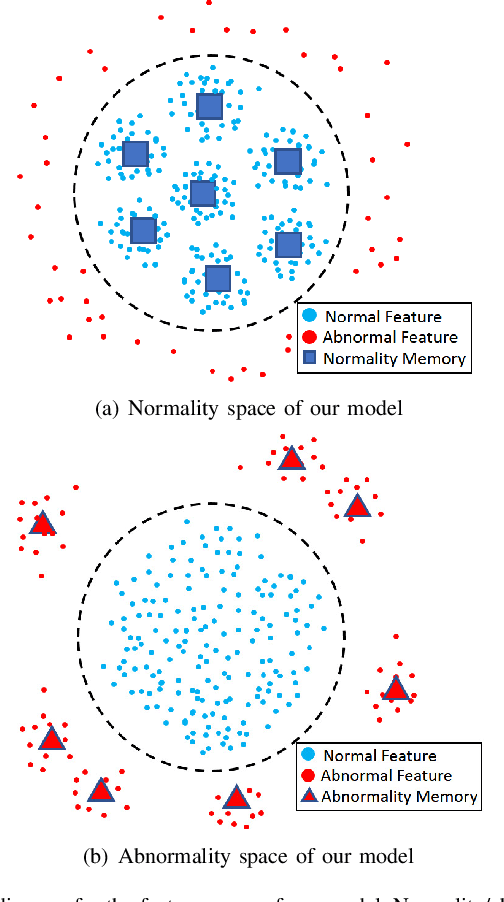
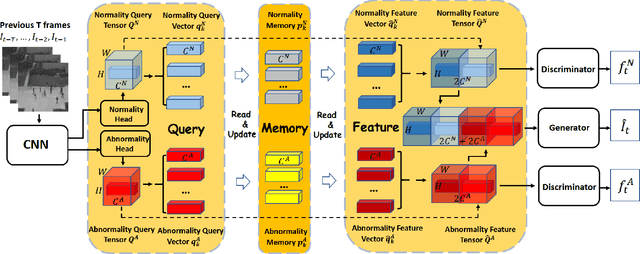
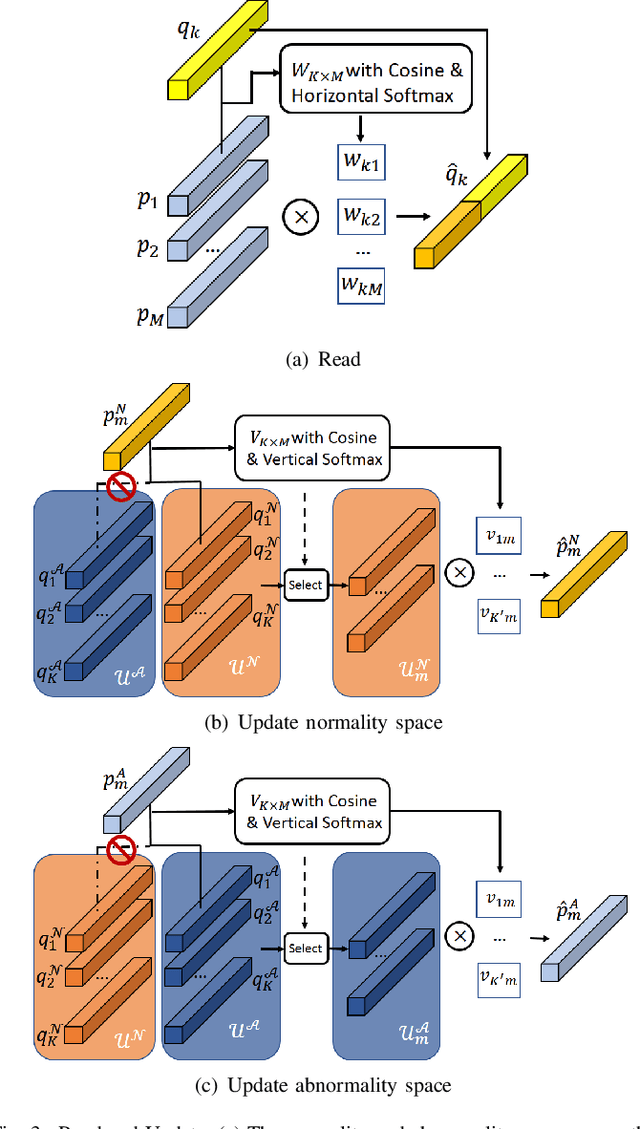
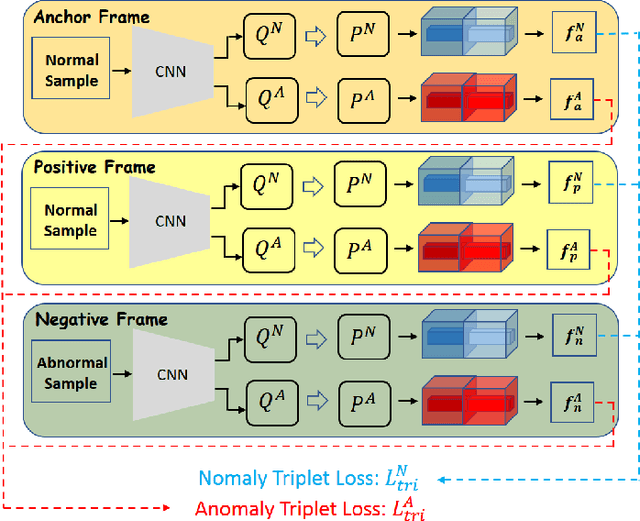
Recently, people tried to use a few anomalies for video anomaly detection (VAD) instead of only normal data during the training process. A side effect of data imbalance occurs when a few abnormal data face a vast number of normal data. The latest VAD works use triplet loss or data re-sampling strategy to lessen this problem. However, there is still no elaborately designed structure for discriminative VAD with a few anomalies. In this paper, we propose a DiscRiminative-gEnerative duAl Memory (DREAM) anomaly detection model to take advantage of a few anomalies and solve data imbalance. We use two shallow discriminators to tighten the normal feature distribution boundary along with a generator for the next frame prediction. Further, we propose a dual memory module to obtain a sparse feature representation in both normality and abnormality space. As a result, DREAM not only solves the data imbalance problem but also learn a reasonable feature space. Further theoretical analysis shows that our DREAM also works for the unknown anomalies. Comparing with the previous methods on UCSD Ped1, UCSD Ped2, CUHK Avenue, and ShanghaiTech, our model outperforms all the baselines with no extra parameters. The ablation study demonstrates the effectiveness of our dual memory module and discriminative-generative network.
OCM3D: Object-Centric Monocular 3D Object Detection
Apr 13, 2021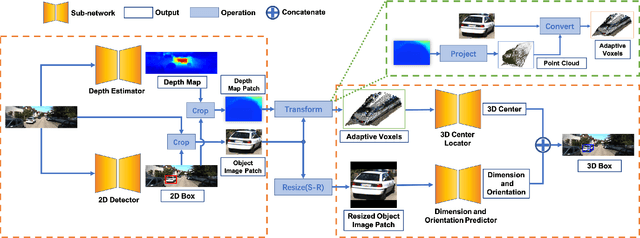
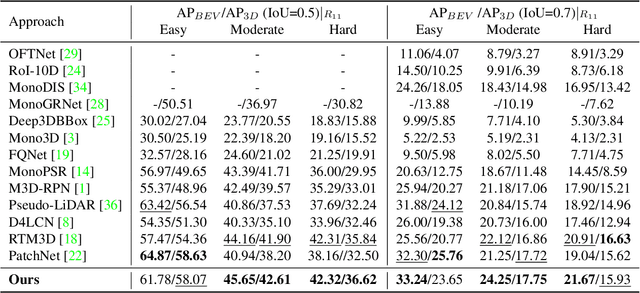
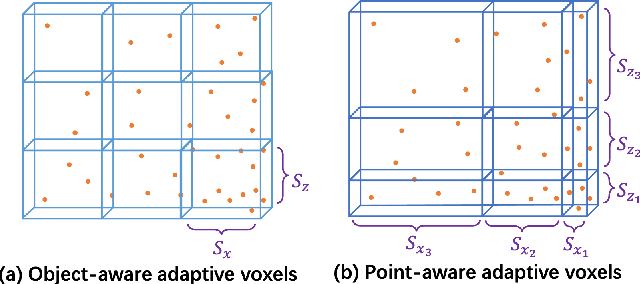

Image-only and pseudo-LiDAR representations are commonly used for monocular 3D object detection. However, methods based on them have shortcomings of either not well capturing the spatial relationships in neighbored image pixels or being hard to handle the noisy nature of the monocular pseudo-LiDAR point cloud. To overcome these issues, in this paper we propose a novel object-centric voxel representation tailored for monocular 3D object detection. Specifically, voxels are built on each object proposal, and their sizes are adaptively determined by the 3D spatial distribution of the points, allowing the noisy point cloud to be organized effectively within a voxel grid. This representation is proved to be able to locate the object in 3D space accurately. Furthermore, prior works would like to estimate the orientation via deep features extracted from an entire image or a noisy point cloud. By contrast, we argue that the local RoI information from the object image patch alone with a proper resizing scheme is a better input as it provides complete semantic clues meanwhile excludes irrelevant interferences. Besides, we decompose the confidence mechanism in monocular 3D object detection by considering the relationship between 3D objects and the associated 2D boxes. Evaluated on KITTI, our method outperforms state-of-the-art methods by a large margin. The code will be made publicly available soon.
X-view: Non-egocentric Multi-View 3D Object Detector
Mar 24, 2021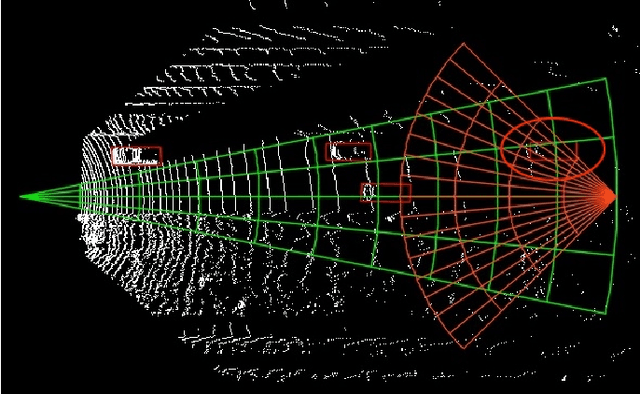
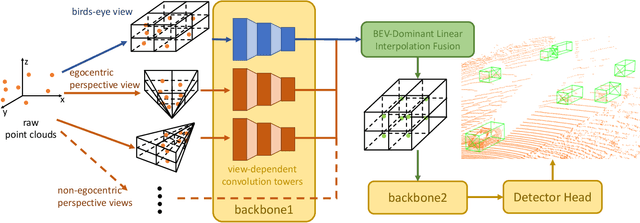

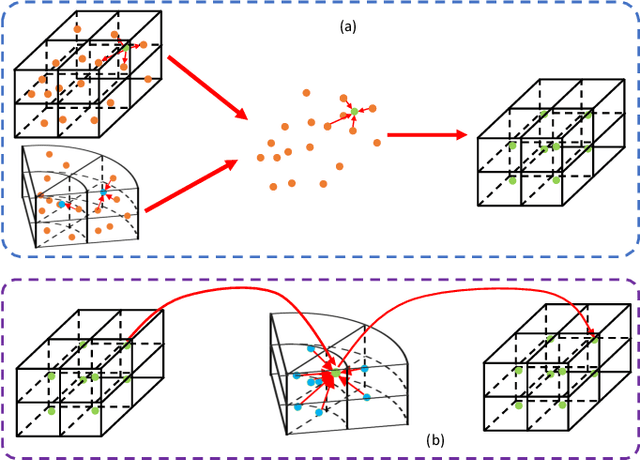
3D object detection algorithms for autonomous driving reason about 3D obstacles either from 3D birds-eye view or perspective view or both. Recent works attempt to improve the detection performance via mining and fusing from multiple egocentric views. Although the egocentric perspective view alleviates some weaknesses of the birds-eye view, the sectored grid partition becomes so coarse in the distance that the targets and surrounding context mix together, which makes the features less discriminative. In this paper, we generalize the research on 3D multi-view learning and propose a novel multi-view-based 3D detection method, named X-view, to overcome the drawbacks of the multi-view methods. Specifically, X-view breaks through the traditional limitation about the perspective view whose original point must be consistent with the 3D Cartesian coordinate. X-view is designed as a general paradigm that can be applied on almost any 3D detectors based on LiDAR with only little increment of running time, no matter it is voxel/grid-based or raw-point-based. We conduct experiments on KITTI and NuScenes datasets to demonstrate the robustness and effectiveness of our proposed X-view. The results show that X-view obtains consistent improvements when combined with four mainstream state-of-the-art 3D methods: SECOND, PointRCNN, Part-A^2, and PV-RCNN.
DMN4: Few-shot Learning via Discriminative Mutual Nearest Neighbor Neural Network
Mar 15, 2021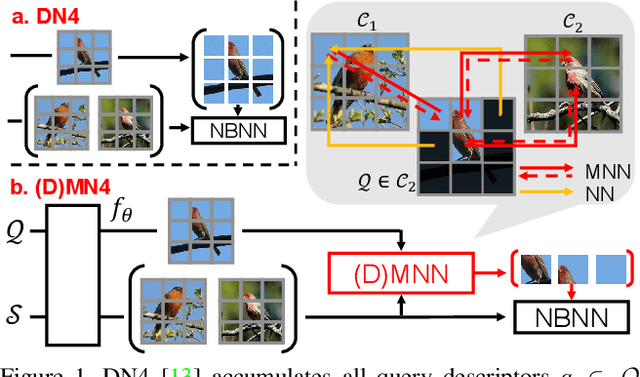
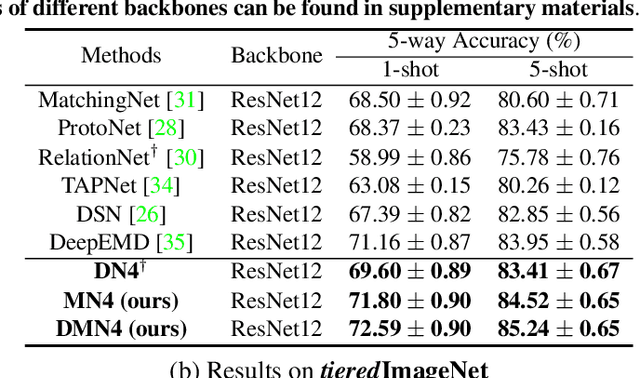
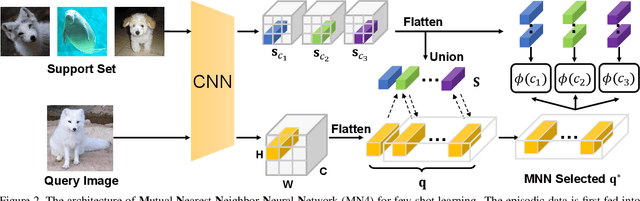
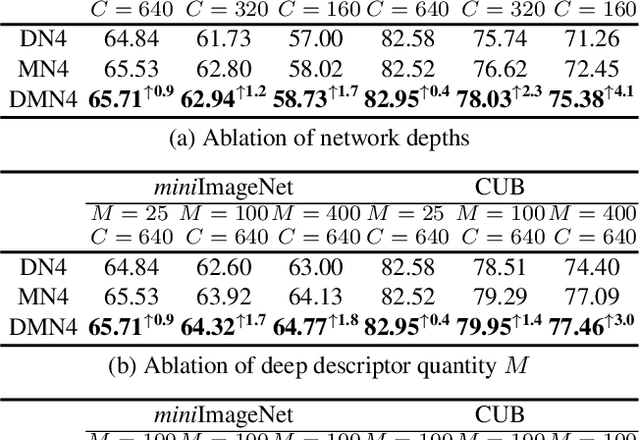
Few-shot learning (FSL) aims to classify images under low-data regimes, where the conventional pooled global representation is likely to lose useful local characteristics. Recent work has achieved promising performances by using deep descriptors. They generally take all deep descriptors from neural networks into consideration while ignoring that some of them are useless in classification due to their limited receptive field, e.g., task-irrelevant descriptors could be misleading and multiple aggregative descriptors from background clutter could even overwhelm the object's presence. In this paper, we argue that a Mutual Nearest Neighbor (MNN) relation should be established to explicitly select the query descriptors that are most relevant to each task and discard less relevant ones from aggregative clutters in FSL. Specifically, we propose Discriminative Mutual Nearest Neighbor Neural Network (DMN4) for FSL. Extensive experiments demonstrate that our method not only qualitatively selects task-relevant descriptors but also quantitatively outperforms the existing state-of-the-arts by a large margin of 1.8~4.9% on fine-grained CUB, a considerable margin of 1.4~2.2% on both supervised and semi-supervised miniImagenet, and ~1.4% on challenging tieredimagenet.
ES-Net: Erasing Salient Parts to Learn More in Re-Identification
Mar 10, 2021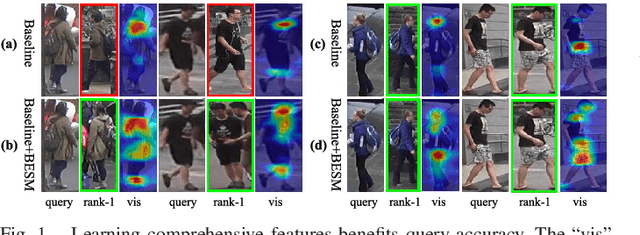
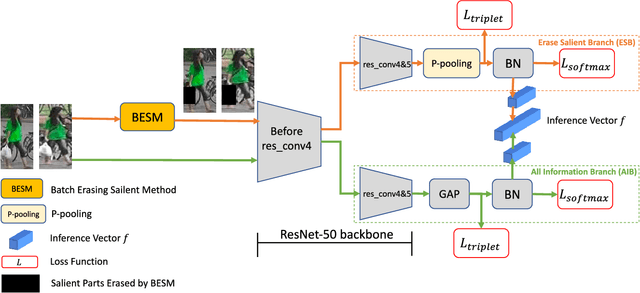
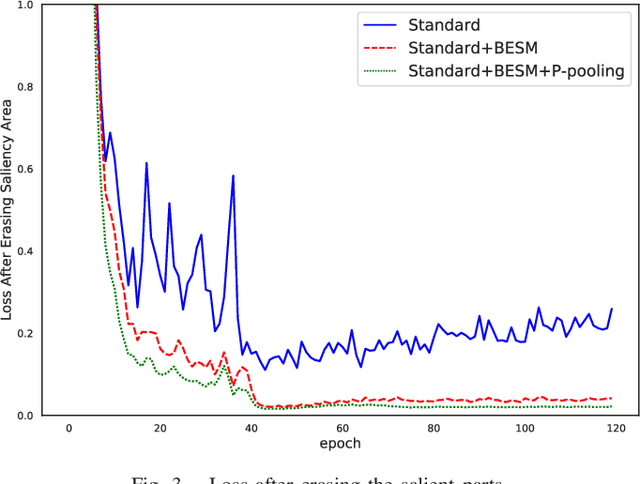

As an instance-level recognition problem, re-identification (re-ID) requires models to capture diverse features. However, with continuous training, re-ID models pay more and more attention to the salient areas. As a result, the model may only focus on few small regions with salient representations and ignore other important information. This phenomenon leads to inferior performance, especially when models are evaluated on small inter-identity variation data. In this paper, we propose a novel network, Erasing-Salient Net (ES-Net), to learn comprehensive features by erasing the salient areas in an image. ES-Net proposes a novel method to locate the salient areas by the confidence of objects and erases them efficiently in a training batch. Meanwhile, to mitigate the over-erasing problem, this paper uses a trainable pooling layer P-pooling that generalizes global max and global average pooling. Experiments are conducted on two specific re-identification tasks (i.e., Person re-ID, Vehicle re-ID). Our ES-Net outperforms state-of-the-art methods on three Person re-ID benchmarks and two Vehicle re-ID benchmarks. Specifically, mAP / Rank-1 rate: 88.6% / 95.7% on Market1501, 78.8% / 89.2% on DuckMTMC-reID, 57.3% / 80.9% on MSMT17, 81.9% / 97.0% on Veri-776, respectively. Rank-1 / Rank-5 rate: 83.6% / 96.9% on VehicleID (Small), 79.9% / 93.5% on VehicleID (Medium), 76.9% / 90.7% on VehicleID (Large), respectively. Moreover, the visualized salient areas show human-interpretable visual explanations for the ranking results.
* 11 pages, 6 figures. Accepted for publication in IEEE Transactions on Image Processing 2021
Spherical Knowledge Distillation
Oct 29, 2020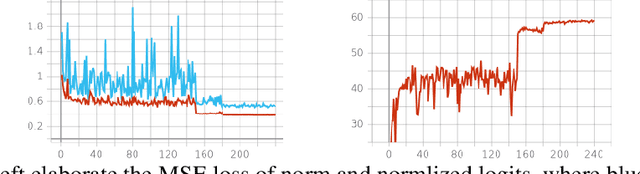
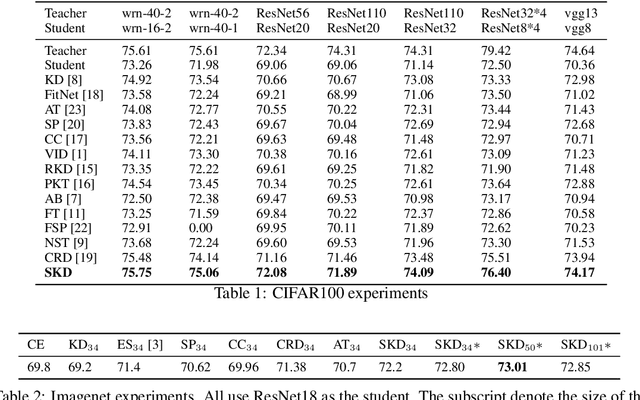
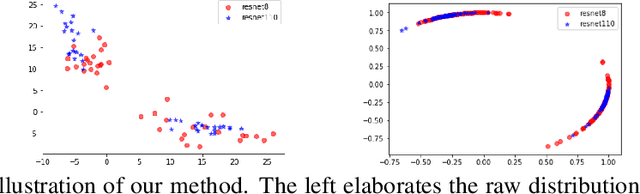
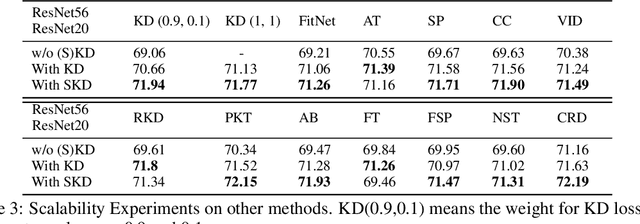
Knowledge distillation aims at obtaining a small but effective deep model by transferring knowledge from a much larger one. The previous approaches try to reach this goal by simply "logit-supervised" information transferring between the teacher and student, which somehow can be subsequently decomposed as the transfer of normalized logits and $l^2$ norm. We argue that the norm of logits is actually interference, which damages the efficiency in the transfer process. To address this problem, we propose Spherical Knowledge Distillation (SKD). Specifically, we project the teacher and the student's logits into a unit sphere, and then we can efficiently perform knowledge distillation on the sphere. We verify our argument via theoretical analysis and ablation study. Extensive experiments have demonstrated the superiority and scalability of our method over the SOTAs.
Does Network Width Really Help Adversarial Robustness?
Oct 03, 2020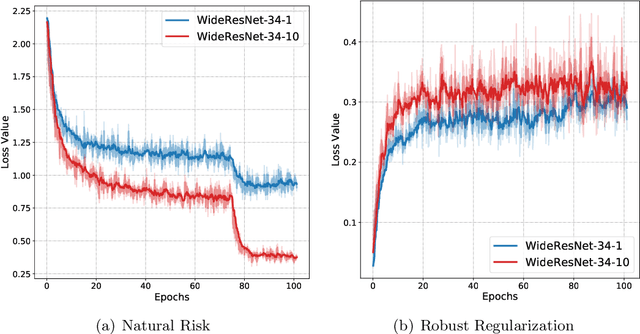
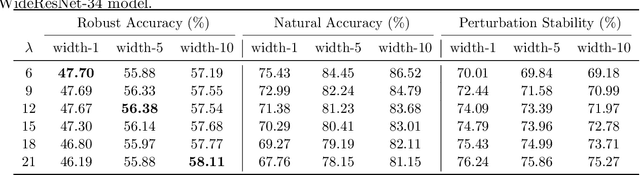
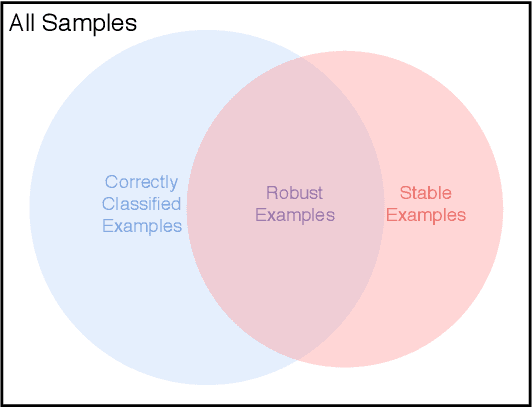
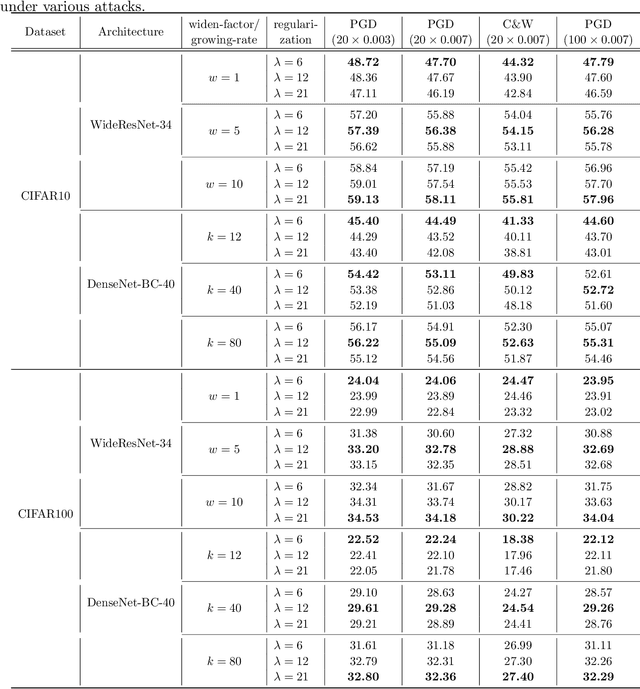
Adversarial training is currently the most powerful defense against adversarial examples. Previous empirical results suggest that adversarial training requires wider networks for better performances. Yet, it remains elusive how does neural network width affects model robustness. In this paper, we carefully examine the relation between network width and model robustness. We present an intriguing phenomenon that the increased network width may not help robustness. Specifically, we show that the model robustness is closely related to both natural accuracy and perturbation stability, a new metric proposed in our paper to characterize the model's stability under adversarial perturbations. While better natural accuracy can be achieved on wider neural networks, the perturbation stability actually becomes worse, leading to a potentially worse overall model robustness. To understand the origin of this phenomenon, we further relate the perturbation stability with the network's local Lipschitznesss. By leveraging recent results on neural tangent kernels, we show that larger network width naturally leads to worse perturbation stability. This suggests that to fully unleash the power of wide model architecture, practitioners should adopt a larger regularization parameter for training wider networks. Experiments on benchmark datasets confirm that this strategy could indeed alleviate the perturbation stability issue and improve the state-of-the-art robust models.