 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePI-RCNN: An Efficient Multi-sensor 3D Object Detector with Point-based Attentive Cont-conv Fusion Module
Paper and Code
Dec 02, 2019
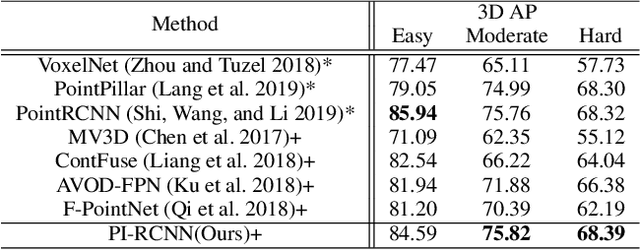
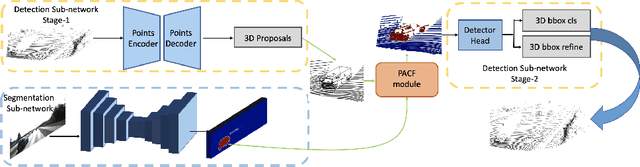
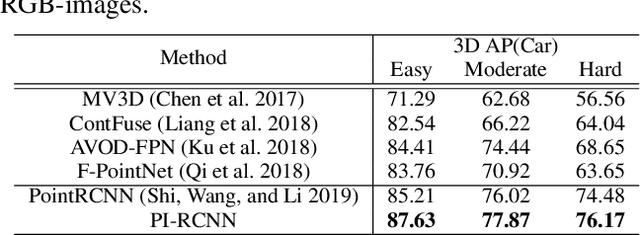
LIDAR point clouds and RGB-images are both extremely essential for 3D object detection. So many state-of-the-art 3D detection algorithms dedicate in fusing these two types of data effectively. However, their fusion methods based on Birds Eye View (BEV) or voxel format are not accurate. In this paper, we propose a novel fusion approach named Point-based Attentive Cont-conv Fusion(PACF) module, which fuses multi-sensor features directly on 3D points. Except for continuous convolution, we additionally add a Point-Pooling and an Attentive Aggregation to make the fused features more expressive. Moreover, based on the PACF module, we propose a 3D multi-sensor multi-task network called Pointcloud-Image RCNN(PI-RCNN as brief), which handles the image segmentation and 3D object detection tasks. PI-RCNN employs a segmentation sub-network to extract full-resolution semantic feature maps from images and then fuses the multi-sensor features via powerful PACF module. Beneficial from the effectiveness of the PACF module and the expressive semantic features from the segmentation module, PI-RCNN can improve much in 3D object detection. We demonstrate the effectiveness of the PACF module and PI-RCNN on the KITTI 3D Detection benchmark, and our method can achieve state-of-the-art on the metric of 3D AP.