 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESP-MedSAM: Efficient Self-Prompting SAM for Universal Domain-Generalized Medical Image Segmentation
Jul 19, 2024



The Segment Anything Model (SAM) has demonstrated outstanding adaptation to medical image segmentation but still faces three major challenges. Firstly, the huge computational costs of SAM limit its real-world applicability. Secondly, SAM depends on manual annotations (e.g., points, boxes) as prompts, which are laborious and impractical in clinical scenarios. Thirdly, SAM handles all segmentation targets equally, which is suboptimal for diverse medical modalities with inherent heterogeneity. To address these issues, we propose an Efficient Self-Prompting SAM for universal medical image segmentation, named ESP-MedSAM. We devise a Multi-Modal Decoupled Knowledge Distillation (MMDKD) strategy to distil common image knowledge and domain-specific medical knowledge from the foundation model to train a lightweight image encoder and a modality controller. Further, they combine with the additionally introduced Self-Patch Prompt Generator (SPPG) and Query-Decoupled Modality Decoder (QDMD) to construct ESP-MedSAM. Specifically, SPPG aims to generate a set of patch prompts automatically and QDMD leverages a one-to-one strategy to provide an independent decoding channel for every modality. Extensive experiments indicate that ESP-MedSAM outperforms state-of-the-arts in diverse medical imaging segmentation takes, displaying superior zero-shot learning and modality transfer ability. Especially, our framework uses only 31.4% parameters compared to SAM-Base.
Millimeter Wave Radar-based Human Activity Recognition for Healthcare Monitoring Robot
May 03, 2024Healthcare monitoring is crucial, especially for the daily care of elderly individuals living alone. It can detect dangerous occurrences, such as falls, and provide timely alerts to save lives. Non-invasive millimeter wave (mmWave) radar-based healthcare monitoring systems using advanced human activity recognition (HAR) models have recently gained significant attention. However, they encounter challenges in handling sparse point clouds, achieving real-time continuous classification, and coping with limited monitoring ranges when statically mounted. To overcome these limitations, we propose RobHAR, a movable robot-mounted mmWave radar system with lightweight deep neural networks for real-time monitoring of human activities. Specifically, we first propose a sparse point cloud-based global embedding to learn the features of point clouds using the light-PointNet (LPN) backbone. Then, we learn the temporal pattern with a bidirectional lightweight LSTM model (BiLiLSTM). In addition, we implement a transition optimization strategy, integrating the Hidden Markov Model (HMM) with Connectionist Temporal Classification (CTC) to improve the accuracy and robustness of the continuous HAR. Our experiments on three datasets indicate that our method significantly outperforms the previous studies in both discrete and continuous HAR tasks. Finally, we deploy our system on a movable robot-mounted edge computing platform, achieving flexible healthcare monitoring in real-world scenarios.
ESP-Zero: Unsupervised enhancement of zero-shot classification for Extremely Sparse Point cloud
Apr 30, 2024



In recent years, zero-shot learning has attracted the focus of many researchers, due to its flexibility and generality. Many approaches have been proposed to achieve the zero-shot classification of the point clouds for 3D object understanding, following the schema of CLIP. However, in the real world, the point clouds could be extremely sparse, dramatically limiting the effectiveness of the 3D point cloud encoders, and resulting in the misalignment of point cloud features and text embeddings. To the point cloud encoders to fit the extremely sparse point clouds without re-running the pre-training procedure which could be time-consuming and expensive, in this work, we propose an unsupervised model adaptation approach to enhance the point cloud encoder for the extremely sparse point clouds. We propose a novel fused-cross attention layer that expands the pre-trained self-attention layer with additional learnable tokens and attention blocks, which effectively modifies the point cloud features while maintaining the alignment between point cloud features and text embeddings. We also propose a complementary learning-based self-distillation schema that encourages the modified features to be pulled apart from the irrelevant text embeddings without overfitting the feature space to the observed text embeddings. Extensive experiments demonstrate that the proposed approach effectively increases the zero-shot capability on extremely sparse point clouds, and overwhelms other state-of-the-art model adaptation approaches.
MorphText: Deep Morphology Regularized Arbitrary-shape Scene Text Detection
Apr 26, 2024



Bottom-up text detection methods play an important role in arbitrary-shape scene text detection but there are two restrictions preventing them from achieving their great potential, i.e., 1) the accumulation of false text segment detections, which affects subsequent processing, and 2) the difficulty of building reliable connections between text segments. Targeting these two problems, we propose a novel approach, named ``MorphText", to capture the regularity of texts by embedding deep morphology for arbitrary-shape text detection. Towards this end, two deep morphological modules are designed to regularize text segments and determine the linkage between them. First, a Deep Morphological Opening (DMOP) module is constructed to remove false text segment detections generated in the feature extraction process. Then, a Deep Morphological Closing (DMCL) module is proposed to allow text instances of various shapes to stretch their morphology along their most significant orientation while deriving their connections. Extensive experiments conducted on four challenging benchmark datasets (CTW1500, Total-Text, MSRA-TD500 and ICDAR2017) demonstrate that our proposed MorphText outperforms both top-down and bottom-up state-of-the-art arbitrary-shape scene text detection approaches.
Scale Optimization Using Evolutionary Reinforcement Learning for Object Detection on Drone Imagery
Dec 23, 2023Object detection in aerial imagery presents a significant challenge due to large scale variations among objects. This paper proposes an evolutionary reinforcement learning agent, integrated within a coarse-to-fine object detection framework, to optimize the scale for more effective detection of objects in such images. Specifically, a set of patches potentially containing objects are first generated. A set of rewards measuring the localization accuracy, the accuracy of predicted labels, and the scale consistency among nearby patches are designed in the agent to guide the scale optimization. The proposed scale-consistency reward ensures similar scales for neighboring objects of the same category. Furthermore, a spatial-semantic attention mechanism is designed to exploit the spatial semantic relations between patches. The agent employs the proximal policy optimization strategy in conjunction with the evolutionary strategy, effectively utilizing both the current patch status and historical experience embedded in the agent. The proposed model is compared with state-of-the-art methods on two benchmark datasets for object detection on drone imagery. It significantly outperforms all the compared methods.
Point Clouds Are Specialized Images: A Knowledge Transfer Approach for 3D Understanding
Jul 28, 2023Self-supervised representation learning (SSRL) has gained increasing attention in point cloud understanding, in addressing the challenges posed by 3D data scarcity and high annotation costs. This paper presents PCExpert, a novel SSRL approach that reinterprets point clouds as "specialized images". This conceptual shift allows PCExpert to leverage knowledge derived from large-scale image modality in a more direct and deeper manner, via extensively sharing the parameters with a pre-trained image encoder in a multi-way Transformer architecture. The parameter sharing strategy, combined with a novel pretext task for pre-training, i.e., transformation estimation, empowers PCExpert to outperform the state of the arts in a variety of tasks, with a remarkable reduction in the number of trainable parameters. Notably, PCExpert's performance under LINEAR fine-tuning (e.g., yielding a 90.02% overall accuracy on ScanObjectNN) has already approached the results obtained with FULL model fine-tuning (92.66%), demonstrating its effective and robust representation capability.
CARD: Semantic Segmentation with Efficient Class-Aware Regularized Decoder
Jan 11, 2023



Semantic segmentation has recently achieved notable advances by exploiting "class-level" contextual information during learning. However, these approaches simply concatenate class-level information to pixel features to boost the pixel representation learning, which cannot fully utilize intra-class and inter-class contextual information. Moreover, these approaches learn soft class centers based on coarse mask prediction, which is prone to error accumulation. To better exploit class level information, we propose a universal Class-Aware Regularization (CAR) approach to optimize the intra-class variance and inter-class distance during feature learning, motivated by the fact that humans can recognize an object by itself no matter which other objects it appears with. Moreover, we design a dedicated decoder for CAR (CARD), which consists of a novel spatial token mixer and an upsampling module, to maximize its gain for existing baselines while being highly efficient in terms of computational cost. Specifically, CAR consists of three novel loss functions. The first loss function encourages more compact class representations within each class, the second directly maximizes the distance between different class centers, and the third further pushes the distance between inter-class centers and pixels. Furthermore, the class center in our approach is directly generated from ground truth instead of from the error-prone coarse prediction. CAR can be directly applied to most existing segmentation models during training, and can largely improve their accuracy at no additional inference overhead. Extensive experiments and ablation studies conducted on multiple benchmark datasets demonstrate that the proposed CAR can boost the accuracy of all baseline models by up to 2.23% mIOU with superior generalization ability. CARD outperforms SOTA approaches on multiple benchmarks with a highly efficient architecture.
Leveraging Systematic Knowledge of 2D Transformations
Jun 02, 2022

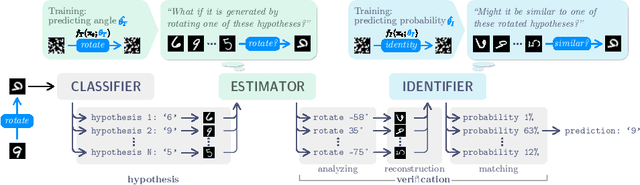
The existing deep learning models suffer from out-of-distribution (o.o.d.) performance drop in computer vision tasks. In comparison, humans have a remarkable ability to interpret images, even if the scenes in the images are rare, thanks to the systematicity of acquired knowledge. This work focuses on 1) the acquisition of systematic knowledge of 2D transformations, and 2) architectural components that can leverage the learned knowledge in image classification tasks in an o.o.d. setting. With a new training methodology based on synthetic datasets that are constructed under the causal framework, the deep neural networks acquire knowledge from semantically different domains (e.g. even from noise), and exhibit certain level of systematicity in parameter estimation experiments. Based on this, a novel architecture is devised consisting of a classifier, an estimator and an identifier (abbreviated as "CED"). By emulating the "hypothesis-verification" process in human visual perception, CED improves the classification accuracy significantly on test sets under covariate shift.
CAR: Class-aware Regularizations for Semantic Segmentation
Mar 14, 2022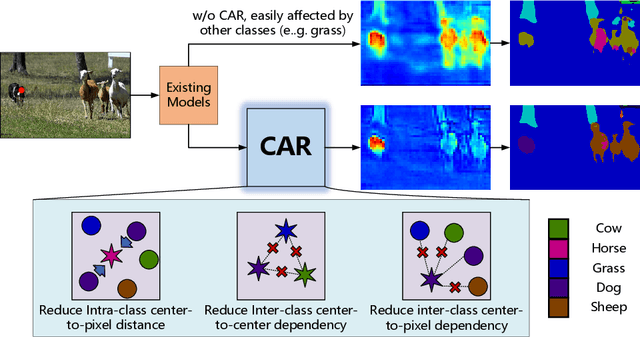
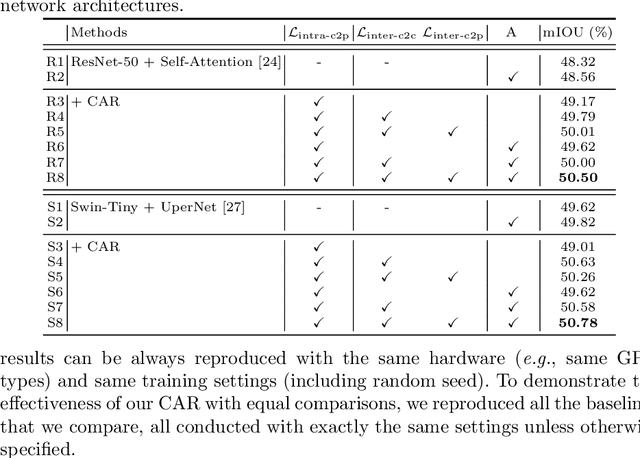


Recent segmentation methods, such as OCR and CPNet, utilizing "class level" information in addition to pixel features, have achieved notable success for boosting the accuracy of existing network modules. However, the extracted class-level information was simply concatenated to pixel features, without explicitly being exploited for better pixel representation learning. Moreover, these approaches learn soft class centers based on coarse mask prediction, which is prone to error accumulation. In this paper, aiming to use class level information more effectively, we propose a universal Class-Aware Regularization (CAR) approach to optimize the intra-class variance and inter-class distance during feature learning, motivated by the fact that humans can recognize an object by itself no matter which other objects it appears with. Three novel loss functions are proposed. The first loss function encourages more compact class representations within each class, the second directly maximizes the distance between different class centers, and the third further pushes the distance between inter-class centers and pixels. Furthermore, the class center in our approach is directly generated from ground truth instead of from the error-prone coarse prediction. Our method can be easily applied to most existing segmentation models during training, including OCR and CPNet, and can largely improve their accuracy at no additional inference overhead. Extensive experiments and ablation studies conducted on multiple benchmark datasets demonstrate that the proposed CAR can boost the accuracy of all baseline models by up to 2.23% mIOU with superior generalization ability. The complete code is available at https://github.com/edwardyehuang/CAR.
CAA : Channelized Axial Attention for Semantic Segmentation
Jan 19, 2021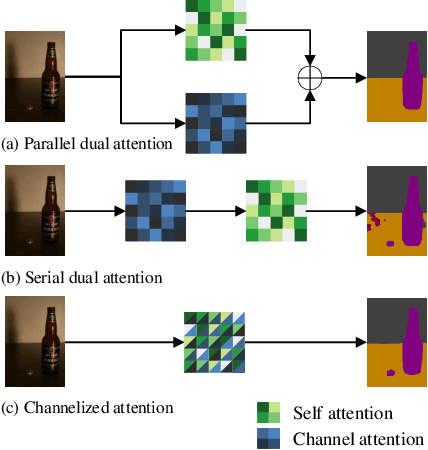
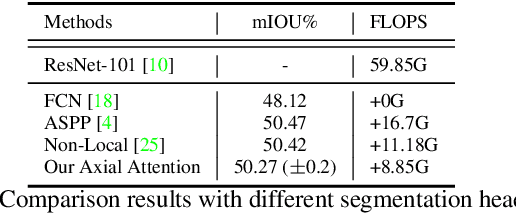
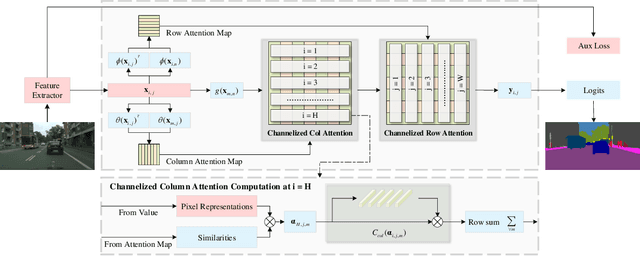
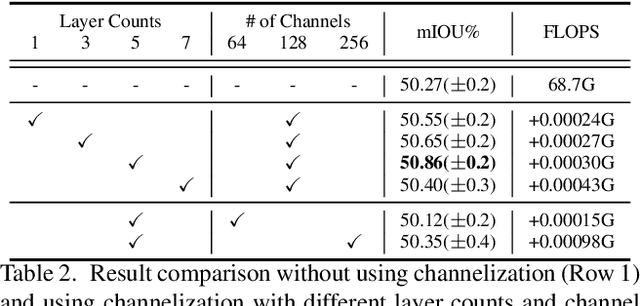
Self-attention and channel attention, modelling the semantic interdependencies in spatial and channel dimensions respectively, have recently been widely used for semantic segmentation. However, computing self-attention and channel attention separately and then fusing them directly can cause conflicting feature representations. In this paper, we propose the Channelized Axial Attention (CAA) to seamlessly integrate channel attention and axial attention with reduced computational complexity. After computing axial attention maps, we propose to channelize the intermediate results obtained from the transposed dot-product so that the channel importance of each axial representation is optimized across the whole receptive field. We further develop grouped vectorization, which allows our model to be run in the very limited GPU memory with a speed comparable with full vectorization. Comparative experiments conducted on multiple benchmark datasets, including Cityscapes, PASCAL Context and COCO-Stuff, demonstrate that our CAA not only requires much less computation resources but also outperforms the state-of-the-art segmentation models based on ResNet-101 on all tested datasets.