 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Referring Image Segmentation
Sep 20, 2022
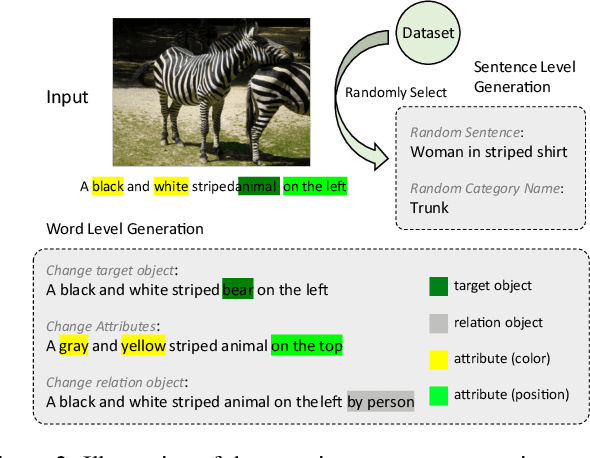
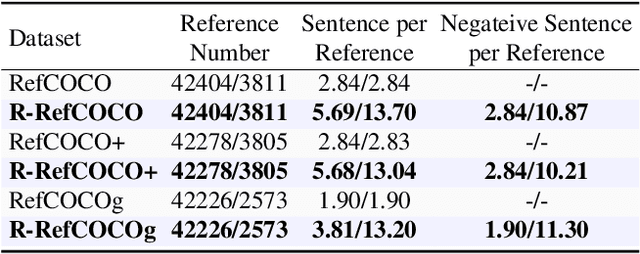
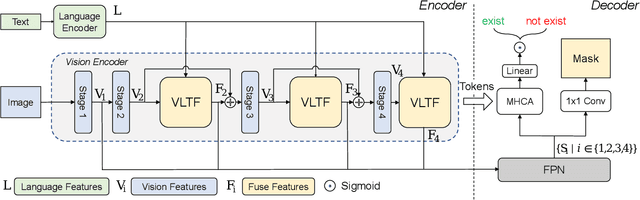
Referring Image Segmentation (RIS) aims to connect image and language via outputting the corresponding object masks given a text description, which is a fundamental vision-language task. Despite lots of works that have achieved considerable progress for RIS, in this work, we explore an essential question, "what if the description is wrong or misleading of the text description?". We term such a sentence as a negative sentence. However, we find that existing works cannot handle such settings. To this end, we propose a novel formulation of RIS, named Robust Referring Image Segmentation (R-RIS). It considers the negative sentence inputs besides the regularly given text inputs. We present three different datasets via augmenting the input negative sentences and a new metric to unify both input types. Furthermore, we design a new transformer-based model named RefSegformer, where we introduce a token-based vision and language fusion module. Such module can be easily extended to our R-RIS setting by adding extra blank tokens. Our proposed RefSegformer achieves the new state-of-the-art results on three regular RIS datasets and three R-RIS datasets, which serves as a new solid baseline for further research. The project page is at \url{https://lxtgh.github.io/project/robust_ref_seg/}.
PI-Trans: Parallel-ConvMLP and Implicit-Transformation Based GAN for Cross-View Image Translation
Jul 09, 2022
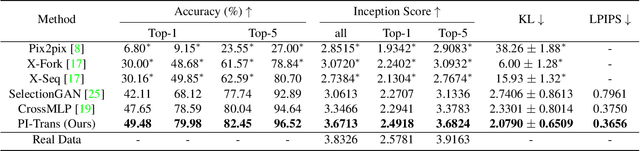
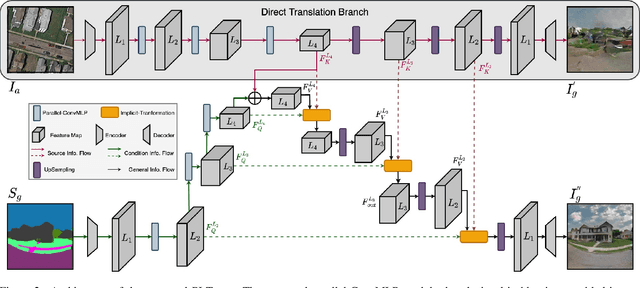
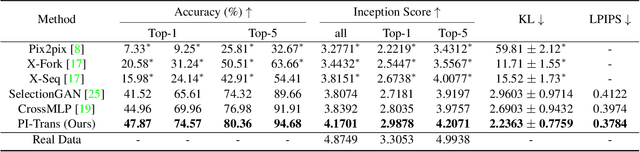
For semantic-guided cross-view image translation, it is crucial to learn where to sample pixels from the source view image and where to reallocate them guided by the target view semantic map, especially when there is little overlap or drastic view difference between the source and target images. Hence, one not only needs to encode the long-range dependencies among pixels in both the source view image and target view the semantic map but also needs to translate these learned dependencies. To this end, we propose a novel generative adversarial network, PI-Trans, which mainly consists of a novel Parallel-ConvMLP module and an Implicit Transformation module at multiple semantic levels. Extensive experimental results show that the proposed PI-Trans achieves the best qualitative and quantitative performance by a large margin compared to the state-of-the-art methods on two challenging datasets. The code will be made available at https://github.com/Amazingren/PI-Trans.
Mask Transfiner for High-Quality Instance Segmentation
Nov 26, 2021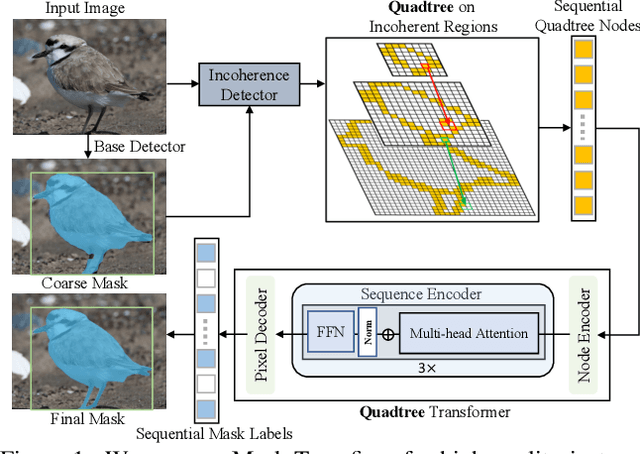


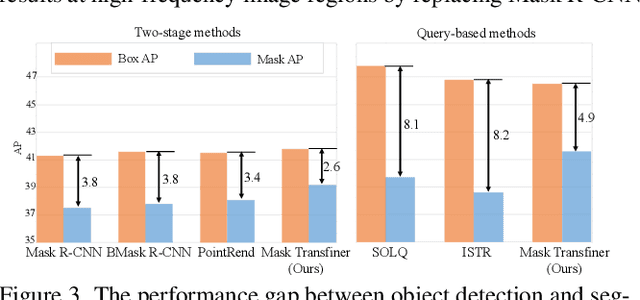
Two-stage and query-based instance segmentation methods have achieved remarkable results. However, their segmented masks are still very coarse. In this paper, we present Mask Transfiner for high-quality and efficient instance segmentation. Instead of operating on regular dense tensors, our Mask Transfiner decomposes and represents the image regions as a quadtree. Our transformer-based approach only processes detected error-prone tree nodes and self-corrects their errors in parallel. While these sparse pixels only constitute a small proportion of the total number, they are critical to the final mask quality. This allows Mask Transfiner to predict highly accurate instance masks, at a low computational cost. Extensive experiments demonstrate that Mask Transfiner outperforms current instance segmentation methods on three popular benchmarks, significantly improving both two-stage and query-based frameworks by a large margin of +3.0 mask AP on COCO and BDD100K, and +6.6 boundary AP on Cityscapes. Our code and trained models will be available at http://vis.xyz/pub/transfiner.
Deep Convolution Network Based Emotion Analysis for Automatic Detection of Mild Cognitive Impairment in the Elderly
Nov 09, 2021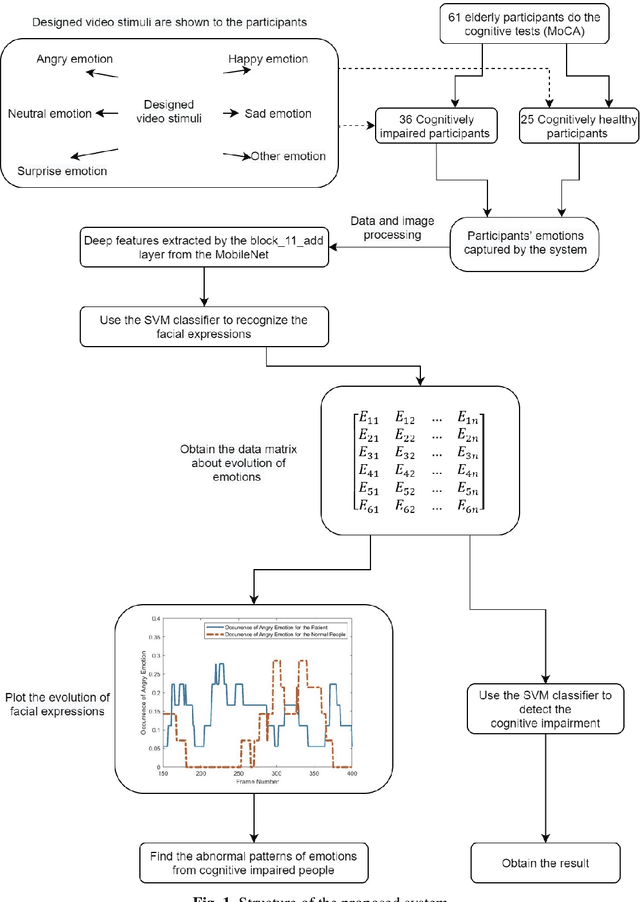
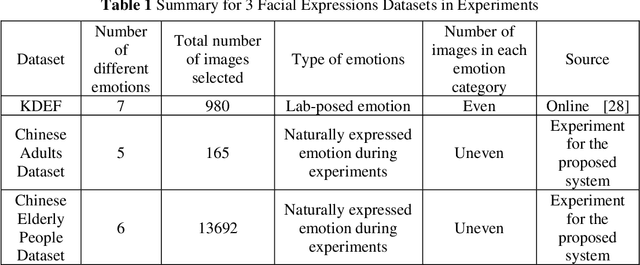
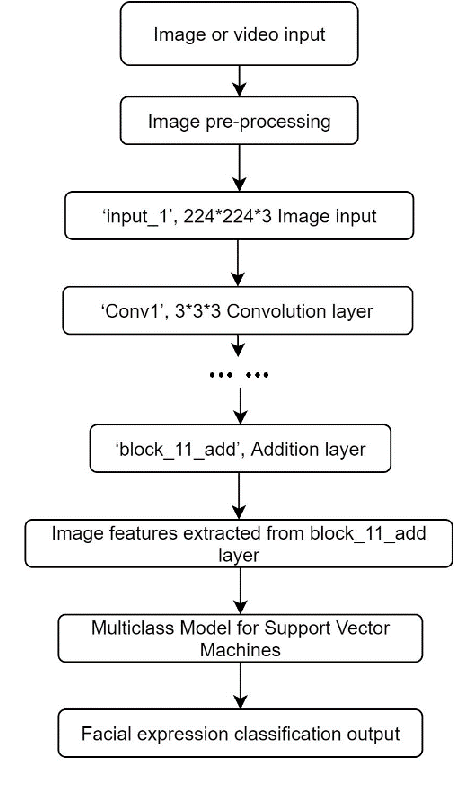
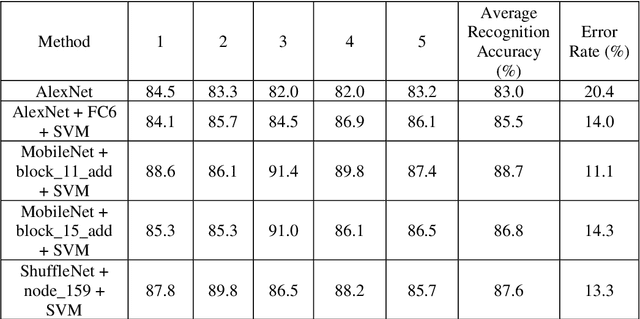
A significant number of people are suffering from cognitive impairment all over the world. Early detection of cognitive impairment is of great importance to both patients and caregivers. However, existing approaches have their shortages, such as time consumption and financial expenses involved in clinics and the neuroimaging stage. It has been found that patients with cognitive impairment show abnormal emotion patterns. In this paper, we present a novel deep convolution network-based system to detect the cognitive impairment through the analysis of the evolution of facial emotions while participants are watching designed video stimuli. In our proposed system, a novel facial expression recognition algorithm is developed using layers from MobileNet and Support Vector Machine (SVM), which showed satisfactory performance in 3 datasets. To verify the proposed system in detecting cognitive impairment, 61 elderly people including patients with cognitive impairment and healthy people as a control group have been invited to participate in the experiments and a dataset was built accordingly. With this dataset, the proposed system has successfully achieved the detection accuracy of 73.3%.
Is Attention Better Than Matrix Decomposition?
Sep 09, 2021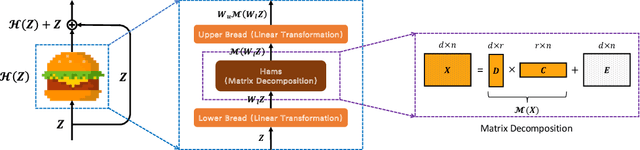

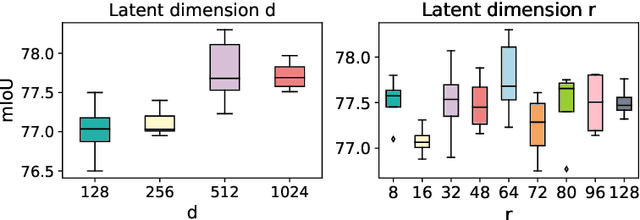
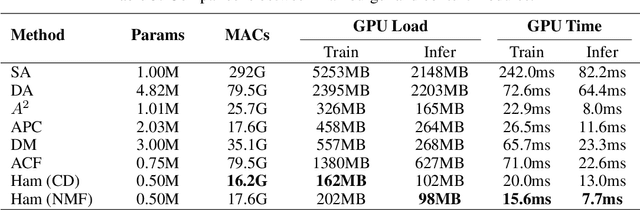
As an essential ingredient of modern deep learning, attention mechanism, especially self-attention, plays a vital role in the global correlation discovery. However, is hand-crafted attention irreplaceable when modeling the global context? Our intriguing finding is that self-attention is not better than the matrix decomposition (MD) model developed 20 years ago regarding the performance and computational cost for encoding the long-distance dependencies. We model the global context issue as a low-rank recovery problem and show that its optimization algorithms can help design global information blocks. This paper then proposes a series of Hamburgers, in which we employ the optimization algorithms for solving MDs to factorize the input representations into sub-matrices and reconstruct a low-rank embedding. Hamburgers with different MDs can perform favorably against the popular global context module self-attention when carefully coping with gradients back-propagated through MDs. Comprehensive experiments are conducted in the vision tasks where it is crucial to learn the global context, including semantic segmentation and image generation, demonstrating significant improvements over self-attention and its variants.
Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation
Jun 22, 2021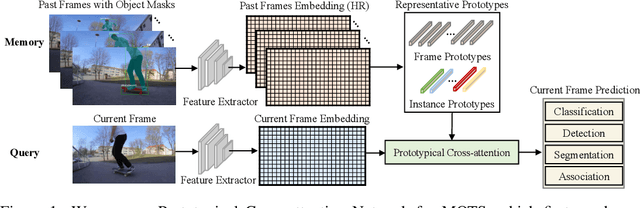
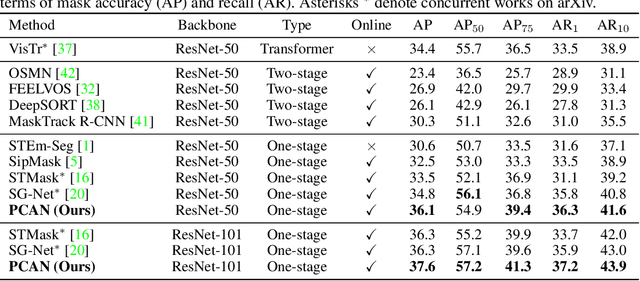
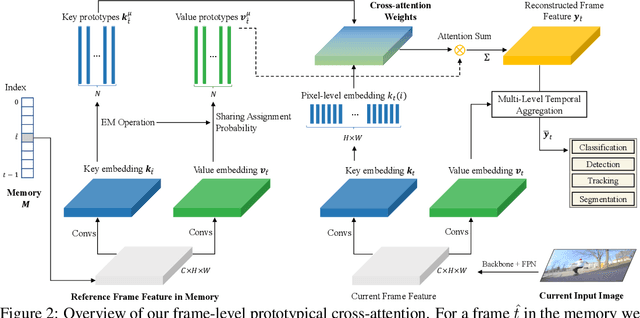

Multiple object tracking and segmentation requires detecting, tracking, and segmenting objects belonging to a set of given classes. Most approaches only exploit the temporal dimension to address the association problem, while relying on single frame predictions for the segmentation mask itself. We propose Prototypical Cross-Attention Network (PCAN), capable of leveraging rich spatio-temporal information for online multiple object tracking and segmentation. PCAN first distills a space-time memory into a set of prototypes and then employs cross-attention to retrieve rich information from the past frames. To segment each object, PCAN adopts a prototypical appearance module to learn a set of contrastive foreground and background prototypes, which are then propagated over time. Extensive experiments demonstrate that PCAN outperforms current video instance tracking and segmentation competition winners on both Youtube-VIS and BDD100K datasets, and shows efficacy to both one-stage and two-stage segmentation frameworks. Code will be available at http://vis.xyz/pub/pcan.
Optimization Induced Equilibrium Networks
Jun 07, 2021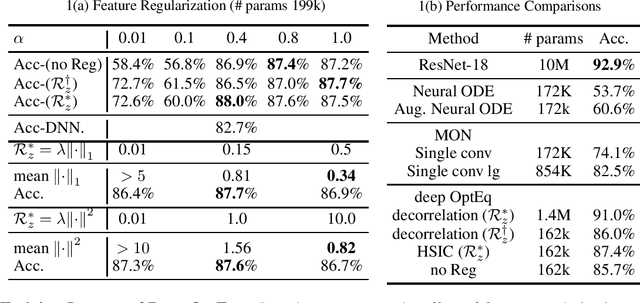


Implicit equilibrium models, i.e., deep neural networks (DNNs) defined by implicit equations, have been becoming more and more attractive recently. In this paper, we investigate an emerging question: can an implicit equilibrium model's equilibrium point be regarded as the solution of an optimization problem? To this end, we first decompose DNNs into a new class of unit layer that is the proximal operator of an implicit convex function while keeping its output unchanged. Then, the equilibrium model of the unit layer can be derived, named Optimization Induced Equilibrium Networks (OptEq), which can be easily extended to deep layers. The equilibrium point of OptEq can be theoretically connected to the solution of its corresponding convex optimization problem with explicit objectives. Based on this, we can flexibly introduce prior properties to the equilibrium points: 1) modifying the underlying convex problems explicitly so as to change the architectures of OptEq; and 2) merging the information into the fixed point iteration, which guarantees to choose the desired equilibrium point when the fixed point set is non-singleton. We show that deep OptEq outperforms previous implicit models even with fewer parameters. This work establishes the first step towards the optimization-guided design of deep models.
PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation
Mar 11, 2021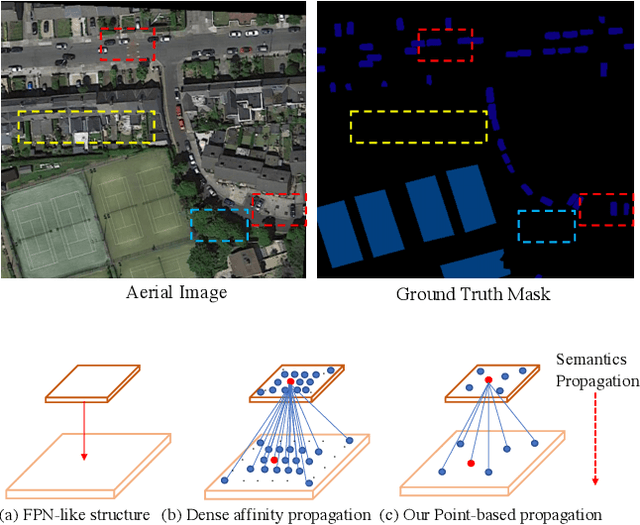
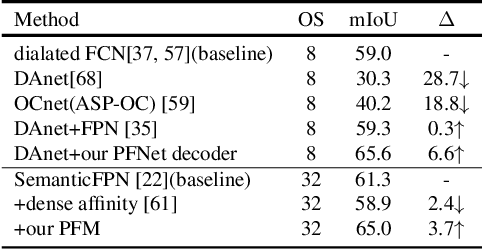
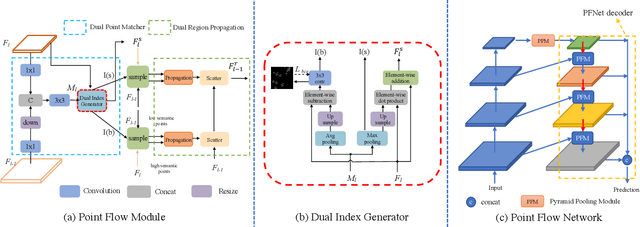
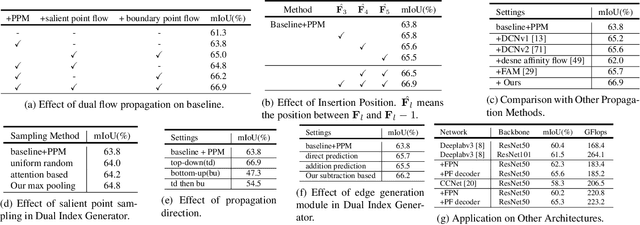
Aerial Image Segmentation is a particular semantic segmentation problem and has several challenging characteristics that general semantic segmentation does not have. There are two critical issues: The one is an extremely foreground-background imbalanced distribution, and the other is multiple small objects along with the complex background. Such problems make the recent dense affinity context modeling perform poorly even compared with baselines due to over-introduced background context. To handle these problems, we propose a point-wise affinity propagation module based on the Feature Pyramid Network (FPN) framework, named PointFlow. Rather than dense affinity learning, a sparse affinity map is generated upon selected points between the adjacent features, which reduces the noise introduced by the background while keeping efficiency. In particular, we design a dual point matcher to select points from the salient area and object boundaries, respectively. Experimental results on three different aerial segmentation datasets suggest that the proposed method is more effective and efficient than state-of-the-art general semantic segmentation methods. Especially, our methods achieve the best speed and accuracy trade-off on three aerial benchmarks. Further experiments on three general semantic segmentation datasets prove the generality of our method. Code will be provided in (https: //github.com/lxtGH/PFSegNets).
Temporal Pyramid Network for Pedestrian Trajectory Prediction with Multi-Supervision
Dec 04, 2020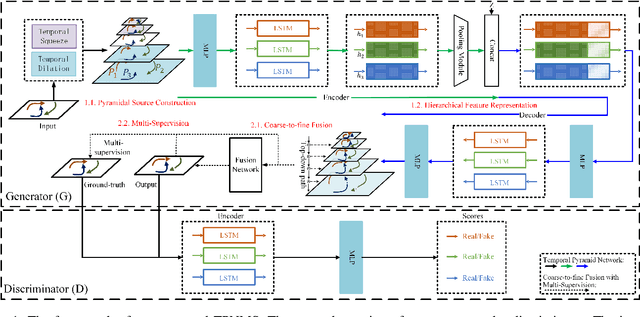
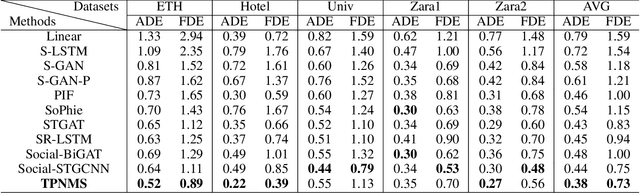
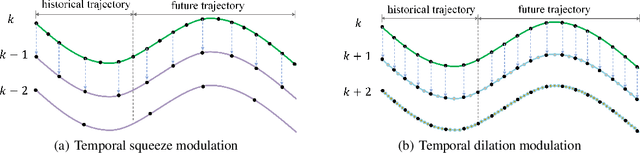
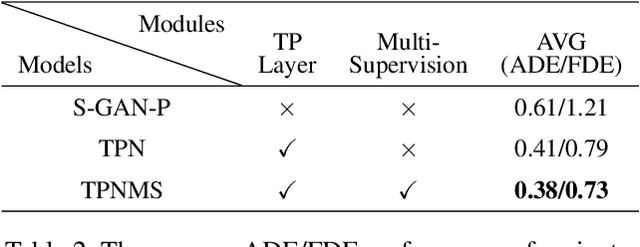
Predicting human motion behavior in a crowd is important for many applications, ranging from the natural navigation of autonomous vehicles to intelligent security systems of video surveillance. All the previous works model and predict the trajectory with a single resolution, which is rather inefficient and difficult to simultaneously exploit the long-range information (e.g., the destination of the trajectory), and the short-range information (e.g., the walking direction and speed at a certain time) of the motion behavior. In this paper, we propose a temporal pyramid network for pedestrian trajectory prediction through a squeeze modulation and a dilation modulation. Our hierarchical framework builds a feature pyramid with increasingly richer temporal information from top to bottom, which can better capture the motion behavior at various tempos. Furthermore, we propose a coarse-to-fine fusion strategy with multi-supervision. By progressively merging the top coarse features of global context to the bottom fine features of rich local context, our method can fully exploit both the long-range and short-range information of the trajectory. Experimental results on several benchmarks demonstrate the superiority of our method.
Who killed Lilly Kane? A case study in applying knowledge graphs to crime fiction
Nov 24, 2020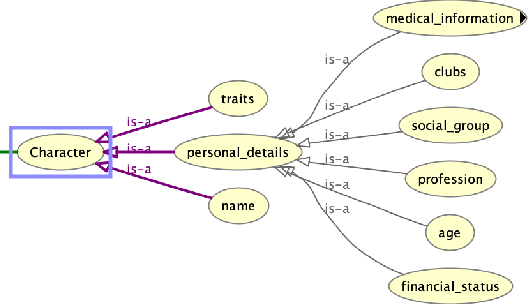
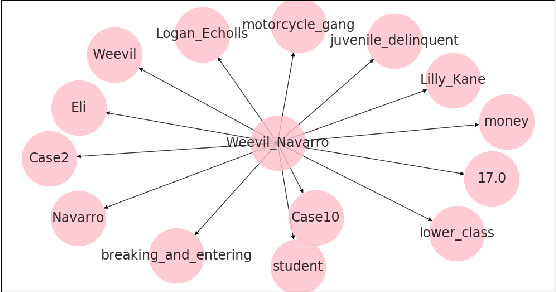
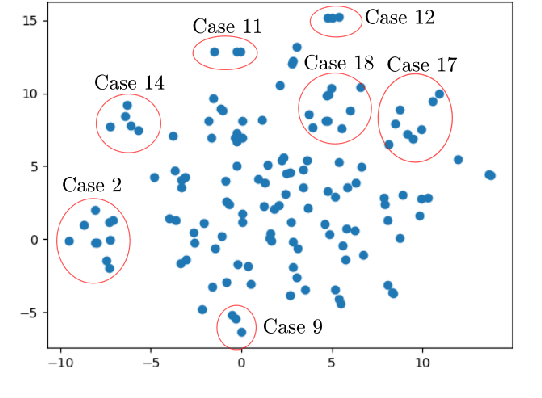

We present a preliminary study of a knowledge graph created from season one of the television show Veronica Mars, which follows the eponymous young private investigator as she attempts to solve the murder of her best friend Lilly Kane. We discuss various techniques for mining the knowledge graph for clues and potential suspects. We also discuss best practice for collaboratively constructing knowledge graphs from television shows.