 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study on Large-Scale Graph Training: Benchmarking and Rethinking
Oct 14, 2022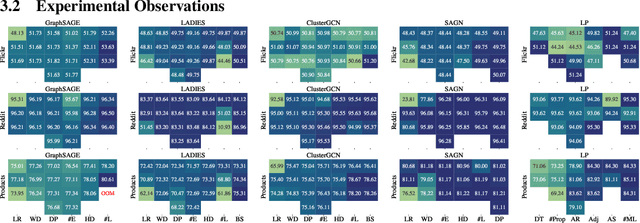
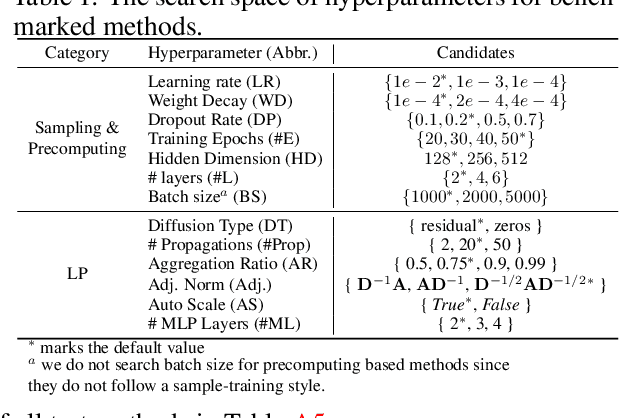

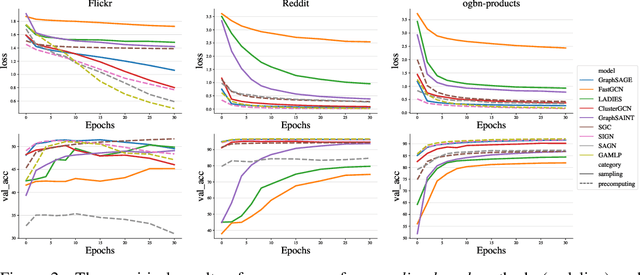
Large-scale graph training is a notoriously challenging problem for graph neural networks (GNNs). Due to the nature of evolving graph structures into the training process, vanilla GNNs usually fail to scale up, limited by the GPU memory space. Up to now, though numerous scalable GNN architectures have been proposed, we still lack a comprehensive survey and fair benchmark of this reservoir to find the rationale for designing scalable GNNs. To this end, we first systematically formulate the representative methods of large-scale graph training into several branches and further establish a fair and consistent benchmark for them by a greedy hyperparameter searching. In addition, regarding efficiency, we theoretically evaluate the time and space complexity of various branches and empirically compare them w.r.t GPU memory usage, throughput, and convergence. Furthermore, We analyze the pros and cons for various branches of scalable GNNs and then present a new ensembling training manner, named EnGCN, to address the existing issues. Remarkably, our proposed method has achieved new state-of-the-art (SOTA) performance on large-scale datasets. Our code is available at https://github.com/VITA-Group/Large_Scale_GCN_Benchmarking.
DreamShard: Generalizable Embedding Table Placement for Recommender Systems
Oct 05, 2022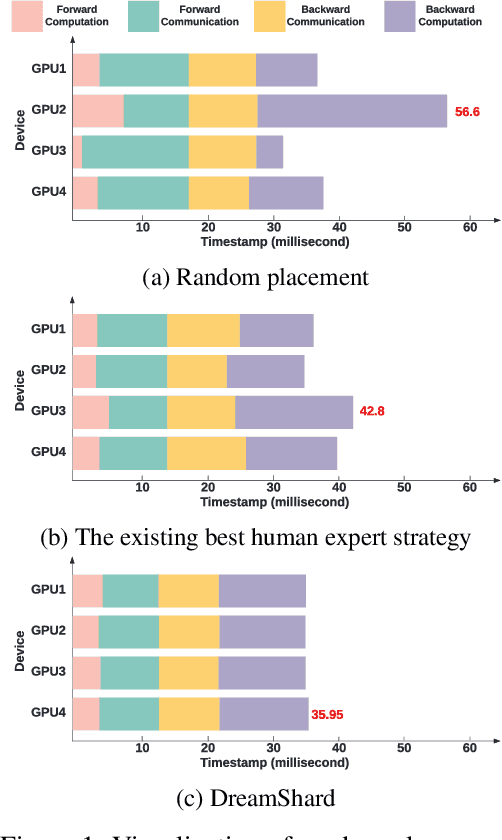
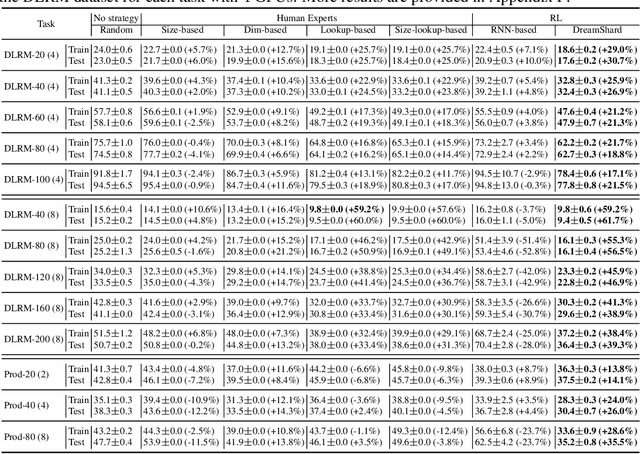
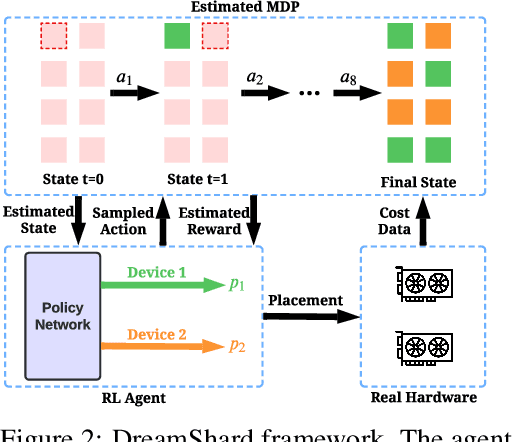
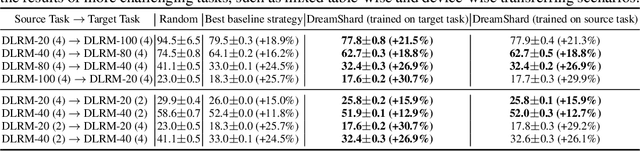
We study embedding table placement for distributed recommender systems, which aims to partition and place the tables on multiple hardware devices (e.g., GPUs) to balance the computation and communication costs. Although prior work has explored learning-based approaches for the device placement of computational graphs, embedding table placement remains to be a challenging problem because of 1) the operation fusion of embedding tables, and 2) the generalizability requirement on unseen placement tasks with different numbers of tables and/or devices. To this end, we present DreamShard, a reinforcement learning (RL) approach for embedding table placement. DreamShard achieves the reasoning of operation fusion and generalizability with 1) a cost network to directly predict the costs of the fused operation, and 2) a policy network that is efficiently trained on an estimated Markov decision process (MDP) without real GPU execution, where the states and the rewards are estimated with the cost network. Equipped with sum and max representation reductions, the two networks can directly generalize to any unseen tasks with different numbers of tables and/or devices without fine-tuning. Extensive experiments show that DreamShard substantially outperforms the existing human expert and RNN-based strategies with up to 19% speedup over the strongest baseline on large-scale synthetic tables and our production tables. The code is available at https://github.com/daochenzha/dreamshard
MLPInit: Embarrassingly Simple GNN Training Acceleration with MLP Initialization
Sep 30, 2022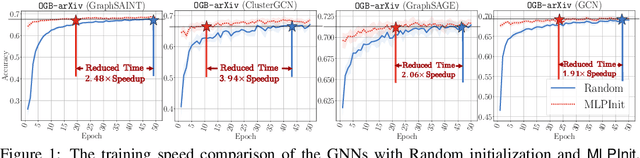
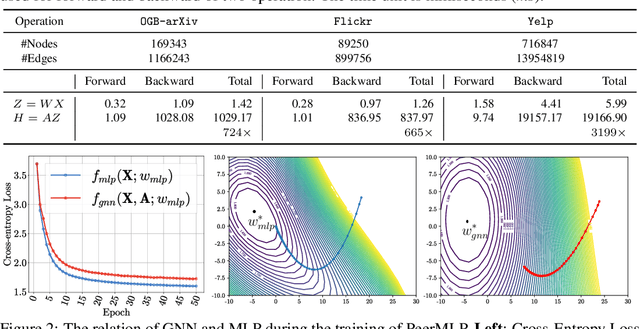
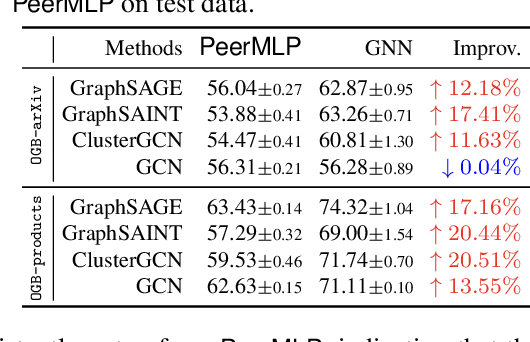
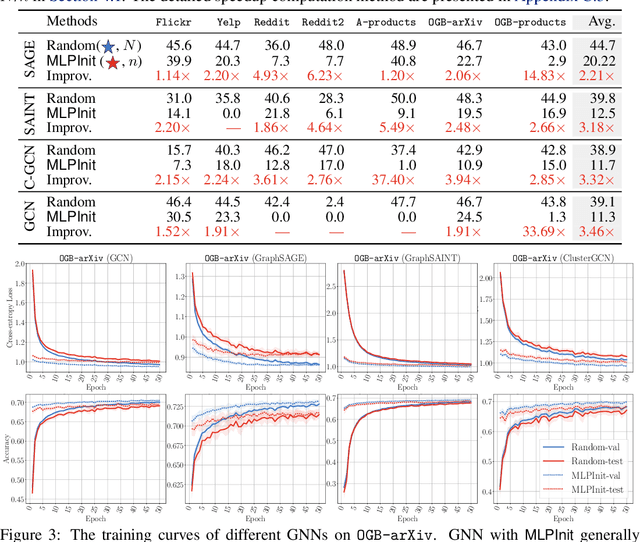
Training graph neural networks (GNNs) on large graphs is complex and extremely time consuming. This is attributed to overheads caused by sparse matrix multiplication, which are sidestepped when training multi-layer perceptrons (MLPs) with only node features. MLPs, by ignoring graph context, are simple and faster for graph data, however they usually sacrifice prediction accuracy, limiting their applications for graph data. We observe that for most message passing-based GNNs, we can trivially derive an analog MLP (we call this a PeerMLP) whose weights can be made identical, making us curious about how do GNNs using weights from a fully trained PeerMLP perform? Surprisingly, we find that GNNs initialized with such weights significantly outperform their PeerMLPs for graph data, motivating us to use PeerMLP training as a precursor, initialization step to GNN training. To this end, we propose an embarrassingly simple, yet hugely effective initialization method for GNN training acceleration, called MLPInit. Our extensive experiments on multiple large-scale graph datasets with diverse GNN architectures validate that MLPInit can accelerate the training of GNNs (up to 33X speedup on OGB-products) and often improve prediction performance (e.g., up to 7.97% improvement for GraphSAGE across 7 datasets for node classification, and up to 17.81% improvement across 4 datasets for link prediction on metric Hits@10). Most importantly, MLPInit is extremely simple to implement and can be flexibly used as a plug-and-play initialization method for message passing-based GNNs.
Towards Automated Imbalanced Learning with Deep Hierarchical Reinforcement Learning
Aug 26, 2022

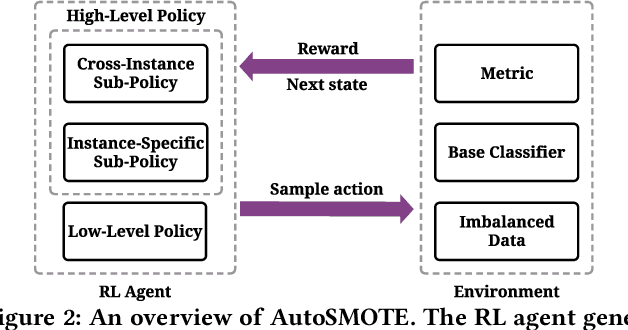
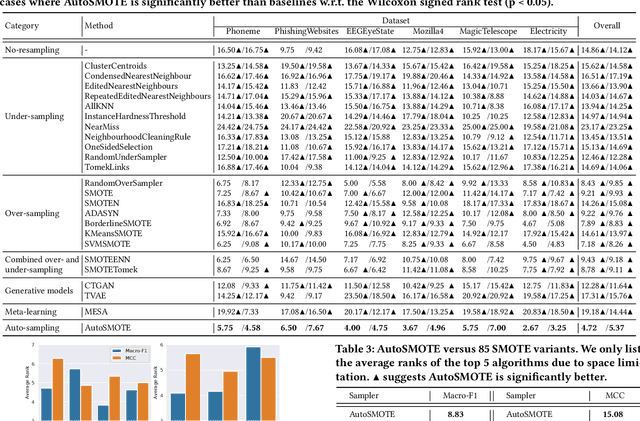
Imbalanced learning is a fundamental challenge in data mining, where there is a disproportionate ratio of training samples in each class. Over-sampling is an effective technique to tackle imbalanced learning through generating synthetic samples for the minority class. While numerous over-sampling algorithms have been proposed, they heavily rely on heuristics, which could be sub-optimal since we may need different sampling strategies for different datasets and base classifiers, and they cannot directly optimize the performance metric. Motivated by this, we investigate developing a learning-based over-sampling algorithm to optimize the classification performance, which is a challenging task because of the huge and hierarchical decision space. At the high level, we need to decide how many synthetic samples to generate. At the low level, we need to determine where the synthetic samples should be located, which depends on the high-level decision since the optimal locations of the samples may differ for different numbers of samples. To address the challenges, we propose AutoSMOTE, an automated over-sampling algorithm that can jointly optimize different levels of decisions. Motivated by the success of SMOTE~\cite{chawla2002smote} and its extensions, we formulate the generation process as a Markov decision process (MDP) consisting of three levels of policies to generate synthetic samples within the SMOTE search space. Then we leverage deep hierarchical reinforcement learning to optimize the performance metric on the validation data. Extensive experiments on six real-world datasets demonstrate that AutoSMOTE significantly outperforms the state-of-the-art resampling algorithms. The code is at https://github.com/daochenzha/autosmote
Shortcut Learning of Large Language Models in Natural Language Understanding: A Survey
Aug 25, 2022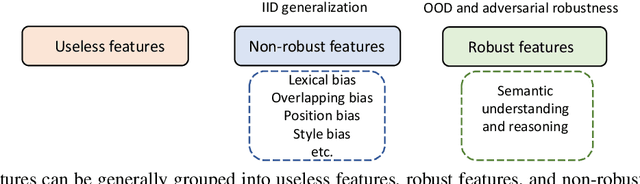

Large language models (LLMs) have achieved state-of-the-art performance on a series of natural language understanding tasks. However, these LLMs might rely on dataset bias and artifacts as shortcuts for prediction. This has significantly hurt their Out-of-Distribution (OOD) generalization and adversarial robustness. In this paper, we provide a review of recent developments that address the robustness challenge of LLMs. We first introduce the concepts and robustness challenge of LLMs. We then introduce methods to identify shortcut learning behavior in LLMs, characterize the reasons for shortcut learning, as well as introduce mitigation solutions. Finally, we identify key challenges and introduce the connections of this line of research to other directions.
AutoShard: Automated Embedding Table Sharding for Recommender Systems
Aug 12, 2022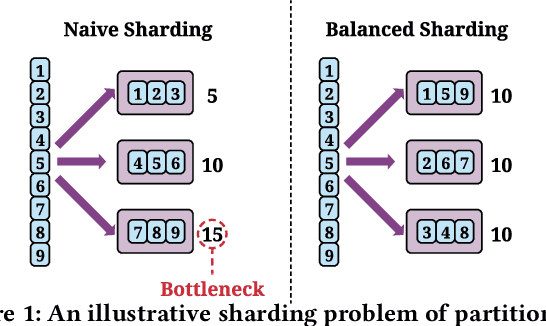
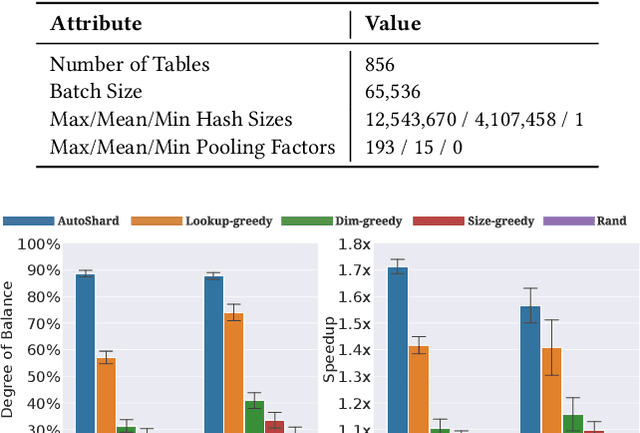

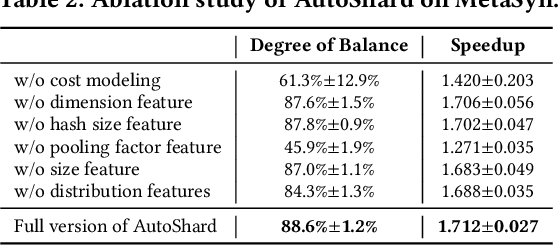
Embedding learning is an important technique in deep recommendation models to map categorical features to dense vectors. However, the embedding tables often demand an extremely large number of parameters, which become the storage and efficiency bottlenecks. Distributed training solutions have been adopted to partition the embedding tables into multiple devices. However, the embedding tables can easily lead to imbalances if not carefully partitioned. This is a significant design challenge of distributed systems named embedding table sharding, i.e., how we should partition the embedding tables to balance the costs across devices, which is a non-trivial task because 1) it is hard to efficiently and precisely measure the cost, and 2) the partition problem is known to be NP-hard. In this work, we introduce our novel practice in Meta, namely AutoShard, which uses a neural cost model to directly predict the multi-table costs and leverages deep reinforcement learning to solve the partition problem. Experimental results on an open-sourced large-scale synthetic dataset and Meta's production dataset demonstrate the superiority of AutoShard over the heuristics. Moreover, the learned policy of AutoShard can transfer to sharding tasks with various numbers of tables and different ratios of the unseen tables without any fine-tuning. Furthermore, AutoShard can efficiently shard hundreds of tables in seconds. The effectiveness, transferability, and efficiency of AutoShard make it desirable for production use. Our algorithms have been deployed in Meta production environment. A prototype is available at https://github.com/daochenzha/autoshard
Towards Memory Efficient Training via Dual Activation Precision
Aug 05, 2022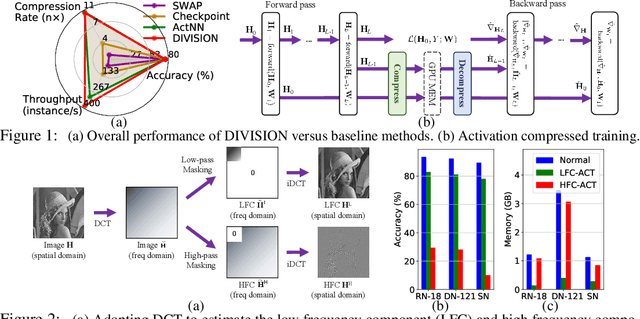
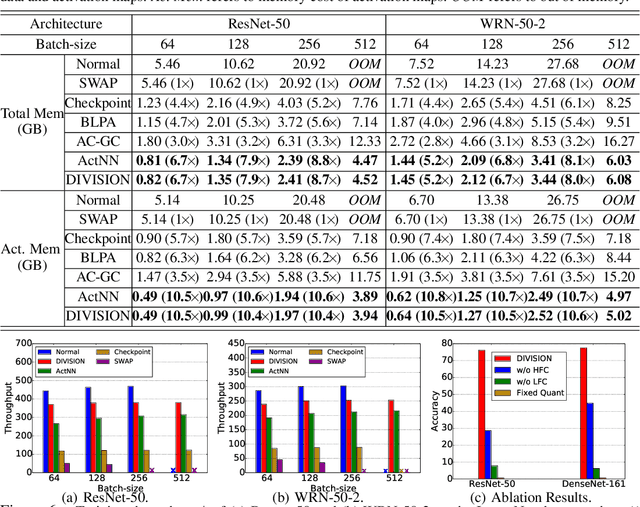
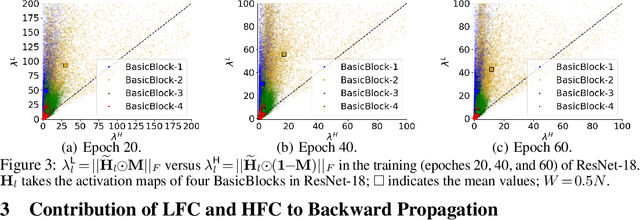
Activation compressed training~(ACT) has been shown to be a promising way to reduce the memory consumption in training deep neural networks. However, existing work of ACT relies on searching for the optimal bit-width during deep neural network (DNN) training to reduce the quantization noise, which makes the procedure complicated and less transparent. To this end, we propose a simple and effective ACT method for DNN training. Our method is motivated by the observation: \emph{DNN backward propagation mainly depends on the low-frequency component~(LFC) of the activation maps instead of the high-frequency component~(HFC)}. It indicates the HFC of the activation maps is highly redundant and compressible during DNN training, which inspires our proposed Dual ActIVation PrecISION~(DIVISION). During the training, DIVISION estimates both the LFC and HFC of the activation maps, and compresses the HFC into low-precision copy to remove the redundancy. This can significantly reduce the memory consumption without negatively affecting the precision of DNN backward propagation. In this way, DIVISION achieves comparable performance as normal training. Experimental results on three benchmark datasets demonstrate that DIVISION outperforms state-of-the-art baseline methods in terms of memory consumption, model accuracy, and running speed.
Differentially Private Counterfactuals via Functional Mechanism
Aug 04, 2022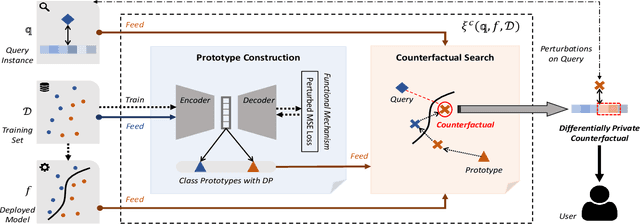
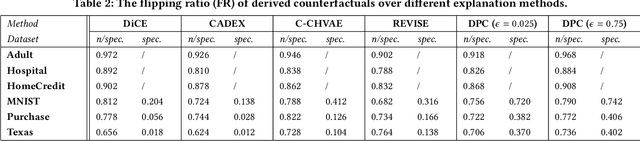
Counterfactual, serving as one emerging type of model explanation, has attracted tons of attentions recently from both industry and academia. Different from the conventional feature-based explanations (e.g., attributions), counterfactuals are a series of hypothetical samples which can flip model decisions with minimal perturbations on queries. Given valid counterfactuals, humans are capable of reasoning under ``what-if'' circumstances, so as to better understand the model decision boundaries. However, releasing counterfactuals could be detrimental, since it may unintentionally leak sensitive information to adversaries, which brings about higher risks on both model security and data privacy. To bridge the gap, in this paper, we propose a novel framework to generate differentially private counterfactual (DPC) without touching the deployed model or explanation set, where noises are injected for protection while maintaining the explanation roles of counterfactual. In particular, we train an autoencoder with the functional mechanism to construct noisy class prototypes, and then derive the DPC from the latent prototypes based on the post-processing immunity of differential privacy. Further evaluations demonstrate the effectiveness of the proposed framework, showing that DPC can successfully relieve the risks on both extraction and inference attacks.
Mitigating Algorithmic Bias with Limited Annotations
Jul 20, 2022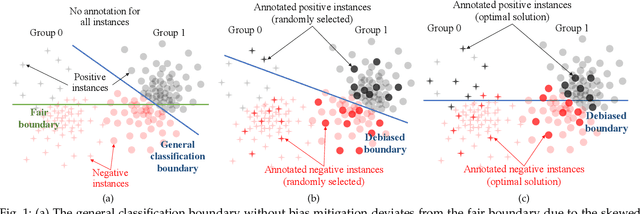
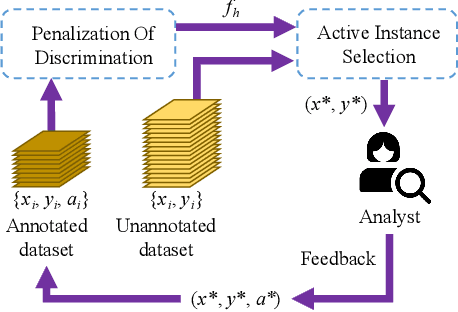
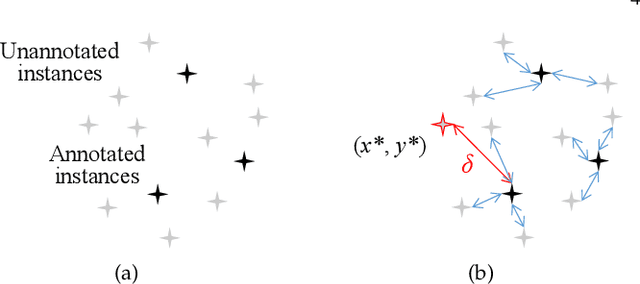
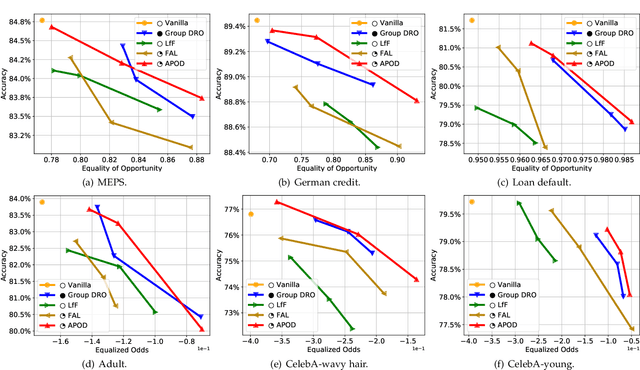
Existing work on fairness modeling commonly assumes that sensitive attributes for all instances are fully available, which may not be true in many real-world applications due to the high cost of acquiring sensitive information. When sensitive attributes are not disclosed or available, it is needed to manually annotate a small part of the training data to mitigate bias. However, the skewed distribution across different sensitive groups preserves the skewness of the original dataset in the annotated subset, which leads to non-optimal bias mitigation. To tackle this challenge, we propose Active Penalization Of Discrimination (APOD), an interactive framework to guide the limited annotations towards maximally eliminating the effect of algorithmic bias. The proposed APOD integrates discrimination penalization with active instance selection to efficiently utilize the limited annotation budget, and it is theoretically proved to be capable of bounding the algorithmic bias. According to the evaluation on five benchmark datasets, APOD outperforms the state-of-the-arts baseline methods under the limited annotation budget, and shows comparable performance to fully annotated bias mitigation, which demonstrates that APOD could benefit real-world applications when sensitive information is limited.
Fair Machine Learning in Healthcare: A Review
Jun 29, 2022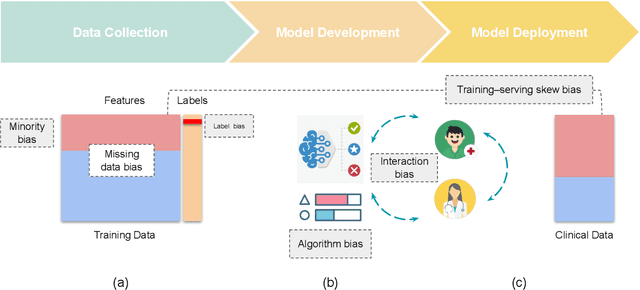

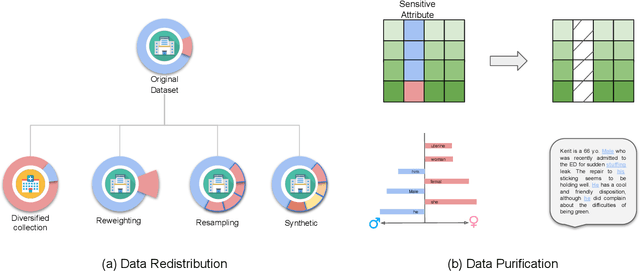
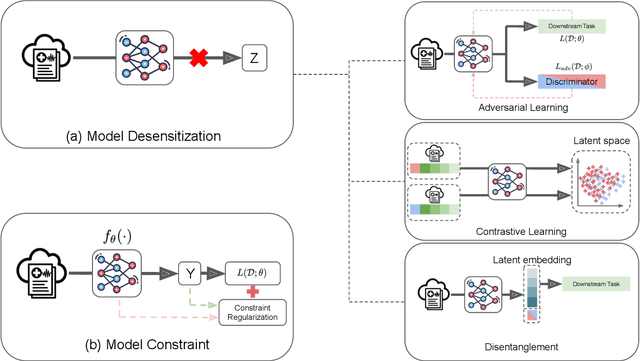
Benefiting from the digitization of healthcare data and the development of computing power, machine learning methods are increasingly used in the healthcare domain. Fairness problems have been identified in machine learning for healthcare, resulting in an unfair allocation of limited healthcare resources or excessive health risks for certain groups. Therefore, addressing the fairness problems has recently attracted increasing attention from the healthcare community. However, the intersection of machine learning for healthcare and fairness in machine learning remains understudied. In this review, we build the bridge by exposing fairness problems, summarizing possible biases, sorting out mitigation methods and pointing out challenges along with opportunities for the future.