 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarginal Nodes Matter: Towards Structure Fairness in Graphs
Oct 23, 2023



In social network, a person located at the periphery region (marginal node) is likely to be treated unfairly when compared with the persons at the center. While existing fairness works on graphs mainly focus on protecting sensitive attributes (e.g., age and gender), the fairness incurred by the graph structure should also be given attention. On the other hand, the information aggregation mechanism of graph neural networks amplifies such structure unfairness, as marginal nodes are often far away from other nodes. In this paper, we focus on novel fairness incurred by the graph structure on graph neural networks, named \emph{structure fairness}. Specifically, we first analyzed multiple graphs and observed that marginal nodes in graphs have a worse performance of downstream tasks than others in graph neural networks. Motivated by the observation, we propose \textbf{S}tructural \textbf{Fair} \textbf{G}raph \textbf{N}eural \textbf{N}etwork (SFairGNN), which combines neighborhood expansion based structure debiasing with hop-aware attentive information aggregation to achieve structure fairness. Our experiments show \SFairGNN can significantly improve structure fairness while maintaining overall performance in the downstream tasks.
DivAug: Plug-in Automated Data Augmentation with Explicit Diversity Maximization
Mar 26, 2021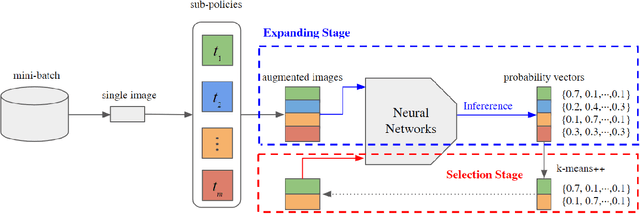

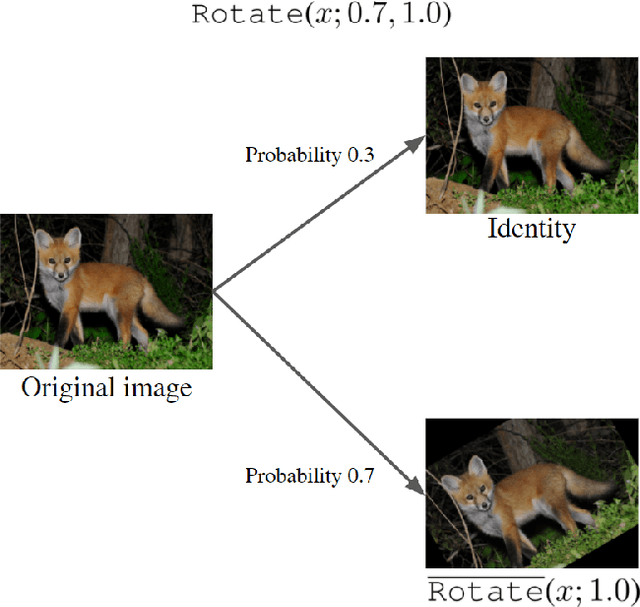
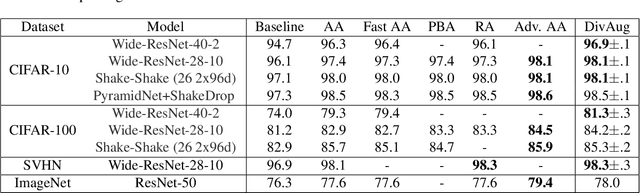
Human-designed data augmentation strategies have been replaced by automatically learned augmentation policy in the past two years. Specifically, recent work has empirically shown that the superior performance of the automated data augmentation methods stems from increasing the diversity of augmented data. However, two factors regarding the diversity of augmented data are still missing: 1) the explicit definition (and thus measurement) of diversity and 2) the quantifiable relationship between diversity and its regularization effects. To bridge this gap, we propose a diversity measure called Variance Diversity and theoretically show that the regularization effect of data augmentation is promised by Variance Diversity. We validate in experiments that the relative gain from automated data augmentation in test accuracy is highly correlated to Variance Diversity. An unsupervised sampling-based framework, DivAug, is designed to directly maximize Variance Diversity and hence strengthen the regularization effect. Without requiring a separate search process, the performance gain from DivAug is comparable with the state-of-the-art method with better efficiency. Moreover, under the semi-supervised setting, our framework can further improve the performance of semi-supervised learning algorithms when compared to RandAugment, making it highly applicable to real-world problems, where labeled data is scarce.
AutoRec: An Automated Recommender System
Jun 26, 2020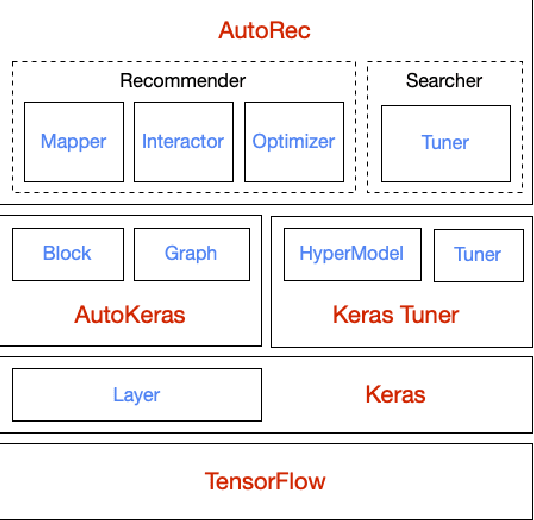
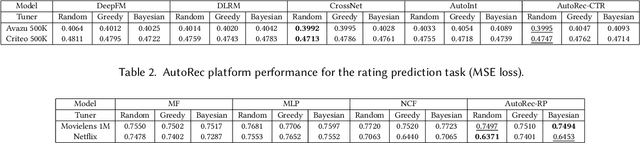
Realistic recommender systems are often required to adapt to ever-changing data and tasks or to explore different models systematically. To address the need, we present AutoRec, an open-source automated machine learning (AutoML) platform extended from the TensorFlow ecosystem and, to our knowledge, the first framework to leverage AutoML for model search and hyperparameter tuning in deep recommendation models. AutoRec also supports a highly flexible pipeline that accommodates both sparse and dense inputs, rating prediction and click-through rate (CTR) prediction tasks, and an array of recommendation models. Lastly, AutoRec provides a simple, user-friendly API. Experiments conducted on the benchmark datasets reveal AutoRec is reliable and can identify models which resemble the best model without prior knowledge.
Superhighway: Bypass Data Sparsity in Cross-Domain CF
Aug 28, 2018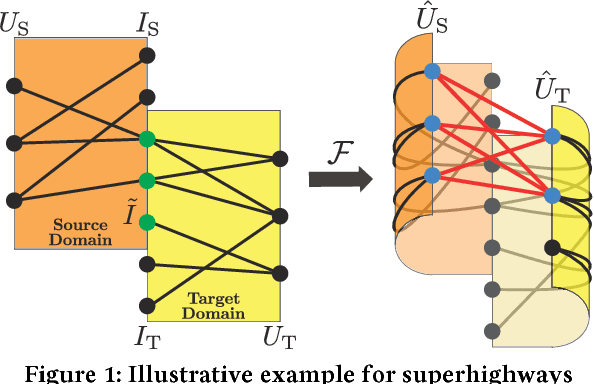
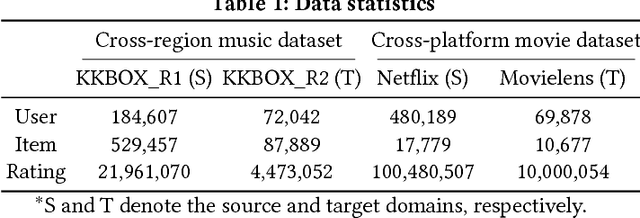
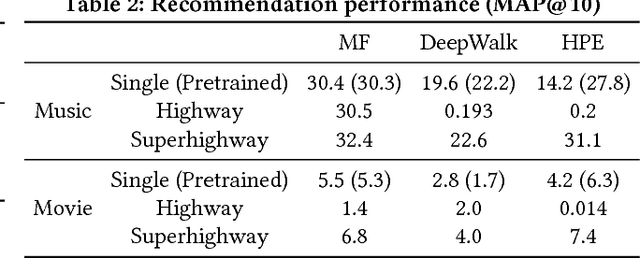
Cross-domain collaborative filtering (CF) aims to alleviate data sparsity in single-domain CF by leveraging knowledge transferred from related domains. Many traditional methods focus on enriching compared neighborhood relations in CF directly to address the sparsity problem. In this paper, we propose superhighway construction, an alternative explicit relation-enrichment procedure, to improve recommendations by enhancing cross-domain connectivity. Specifically, assuming partially overlapped items (users), superhighway bypasses multi-hop inter-domain paths between cross-domain users (items, respectively) with direct paths to enrich the cross-domain connectivity. The experiments conducted on a real-world cross-region music dataset and a cross-platform movie dataset show that the proposed superhighway construction significantly improves recommendation performance in both target and source domains.