 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective and Compact Contextual Representation for Conformer Transducer Speech Recognition Systems
Jun 26, 2023Current ASR systems are mainly trained and evaluated at the utterance level. Long range cross utterance context can be incorporated. A key task is to derive a suitable compact representation of the most relevant history contexts. In contrast to previous researches based on either LSTM-RNN encoded histories that attenuate the information from longer range contexts, or frame level concatenation of transformer context embeddings, in this paper compact low-dimensional cross utterance contextual features are learned in the Conformer-Transducer Encoder using specially designed attention pooling layers that are applied over efficiently cached preceding utterances history vectors. Experiments on the 1000-hr Gigaspeech corpus demonstrate that the proposed contextualized streaming Conformer-Transducers outperform the baseline using utterance internal context only with statistically significant WER reductions of 0.7% to 0.5% absolute (4.3% to 3.1% relative) on the dev and test data.
Latent-Shift: Latent Diffusion with Temporal Shift for Efficient Text-to-Video Generation
Apr 18, 2023



We propose Latent-Shift -- an efficient text-to-video generation method based on a pretrained text-to-image generation model that consists of an autoencoder and a U-Net diffusion model. Learning a video diffusion model in the latent space is much more efficient than in the pixel space. The latter is often limited to first generating a low-resolution video followed by a sequence of frame interpolation and super-resolution models, which makes the entire pipeline very complex and computationally expensive. To extend a U-Net from image generation to video generation, prior work proposes to add additional modules like 1D temporal convolution and/or temporal attention layers. In contrast, we propose a parameter-free temporal shift module that can leverage the spatial U-Net as is for video generation. We achieve this by shifting two portions of the feature map channels forward and backward along the temporal dimension. The shifted features of the current frame thus receive the features from the previous and the subsequent frames, enabling motion learning without additional parameters. We show that Latent-Shift achieves comparable or better results while being significantly more efficient. Moreover, Latent-Shift can generate images despite being finetuned for T2V generation.
MaLP: Manipulation Localization Using a Proactive Scheme
Apr 04, 2023Advancements in the generation quality of various Generative Models (GMs) has made it necessary to not only perform binary manipulation detection but also localize the modified pixels in an image. However, prior works termed as passive for manipulation localization exhibit poor generalization performance over unseen GMs and attribute modifications. To combat this issue, we propose a proactive scheme for manipulation localization, termed MaLP. We encrypt the real images by adding a learned template. If the image is manipulated by any GM, this added protection from the template not only aids binary detection but also helps in identifying the pixels modified by the GM. The template is learned by leveraging local and global-level features estimated by a two-branch architecture. We show that MaLP performs better than prior passive works. We also show the generalizability of MaLP by testing on 22 different GMs, providing a benchmark for future research on manipulation localization. Finally, we show that MaLP can be used as a discriminator for improving the generation quality of GMs. Our models/codes are available at www.github.com/vishal3477/pro_loc.
SpaText: Spatio-Textual Representation for Controllable Image Generation
Nov 25, 2022Recent text-to-image diffusion models are able to generate convincing results of unprecedented quality. However, it is nearly impossible to control the shapes of different regions/objects or their layout in a fine-grained fashion. Previous attempts to provide such controls were hindered by their reliance on a fixed set of labels. To this end, we present SpaText - a new method for text-to-image generation using open-vocabulary scene control. In addition to a global text prompt that describes the entire scene, the user provides a segmentation map where each region of interest is annotated by a free-form natural language description. Due to lack of large-scale datasets that have a detailed textual description for each region in the image, we choose to leverage the current large-scale text-to-image datasets and base our approach on a novel CLIP-based spatio-textual representation, and show its effectiveness on two state-of-the-art diffusion models: pixel-based and latent-based. In addition, we show how to extend the classifier-free guidance method in diffusion models to the multi-conditional case and present an alternative accelerated inference algorithm. Finally, we offer several automatic evaluation metrics and use them, in addition to FID scores and a user study, to evaluate our method and show that it achieves state-of-the-art results on image generation with free-form textual scene control.
Make-A-Video: Text-to-Video Generation without Text-Video Data
Sep 29, 2022

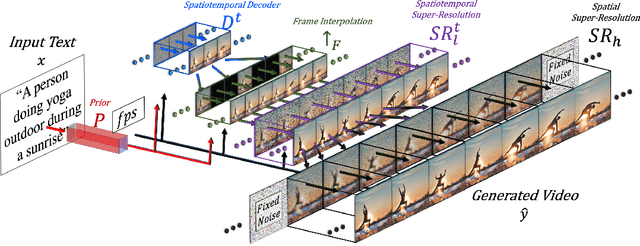
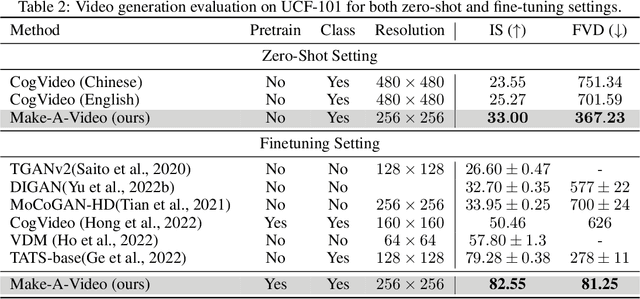
We propose Make-A-Video -- an approach for directly translating the tremendous recent progress in Text-to-Image (T2I) generation to Text-to-Video (T2V). Our intuition is simple: learn what the world looks like and how it is described from paired text-image data, and learn how the world moves from unsupervised video footage. Make-A-Video has three advantages: (1) it accelerates training of the T2V model (it does not need to learn visual and multimodal representations from scratch), (2) it does not require paired text-video data, and (3) the generated videos inherit the vastness (diversity in aesthetic, fantastical depictions, etc.) of today's image generation models. We design a simple yet effective way to build on T2I models with novel and effective spatial-temporal modules. First, we decompose the full temporal U-Net and attention tensors and approximate them in space and time. Second, we design a spatial temporal pipeline to generate high resolution and frame rate videos with a video decoder, interpolation model and two super resolution models that can enable various applications besides T2V. In all aspects, spatial and temporal resolution, faithfulness to text, and quality, Make-A-Video sets the new state-of-the-art in text-to-video generation, as determined by both qualitative and quantitative measures.
MUGEN: A Playground for Video-Audio-Text Multimodal Understanding and GENeration
Apr 28, 2022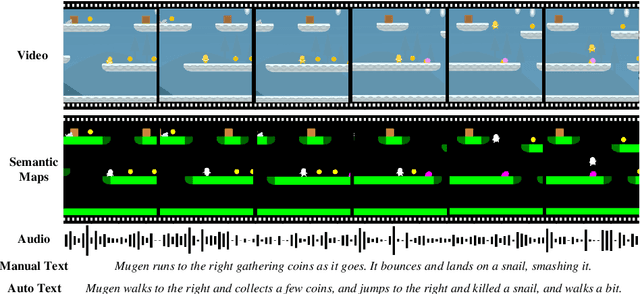
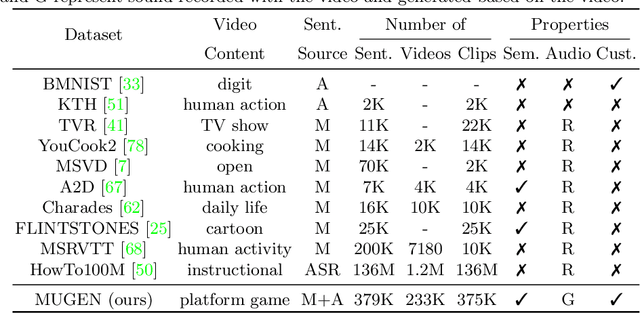
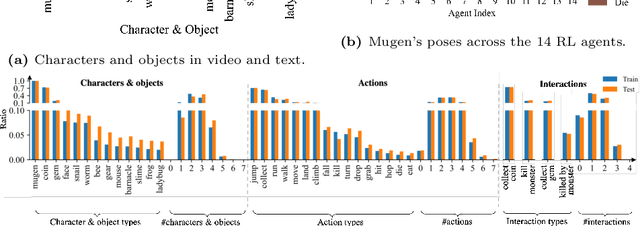

Multimodal video-audio-text understanding and generation can benefit from datasets that are narrow but rich. The narrowness allows bite-sized challenges that the research community can make progress on. The richness ensures we are making progress along the core challenges. To this end, we present a large-scale video-audio-text dataset MUGEN, collected using the open-sourced platform game CoinRun [11]. We made substantial modifications to make the game richer by introducing audio and enabling new interactions. We trained RL agents with different objectives to navigate the game and interact with 13 objects and characters. This allows us to automatically extract a large collection of diverse videos and associated audio. We sample 375K video clips (3.2s each) and collect text descriptions from human annotators. Each video has additional annotations that are extracted automatically from the game engine, such as accurate semantic maps for each frame and templated textual descriptions. Altogether, MUGEN can help progress research in many tasks in multimodal understanding and generation. We benchmark representative approaches on tasks involving video-audio-text retrieval and generation. Our dataset and code are released at: https://mugen-org.github.io/.
Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer
Apr 07, 2022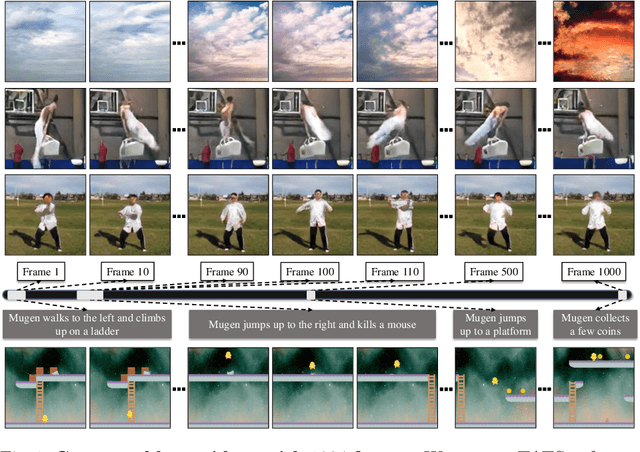
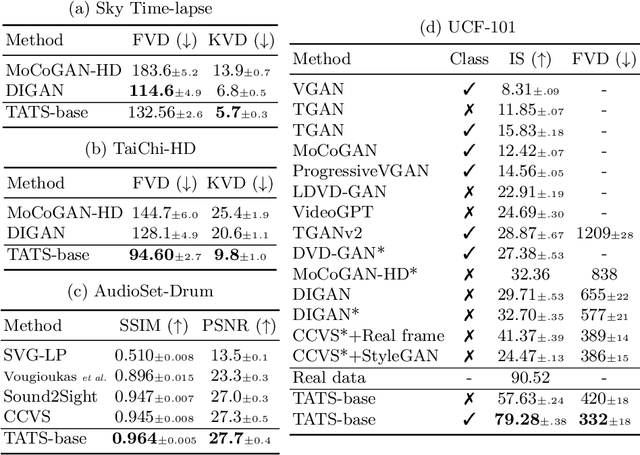

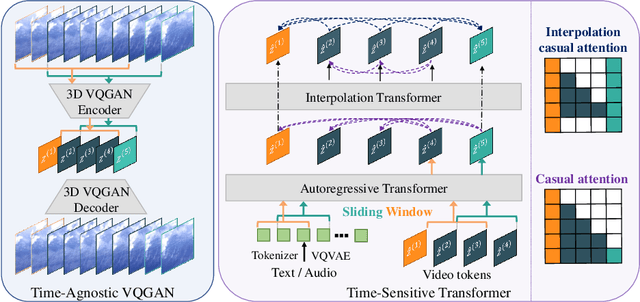
Videos are created to express emotion, exchange information, and share experiences. Video synthesis has intrigued researchers for a long time. Despite the rapid progress driven by advances in visual synthesis, most existing studies focus on improving the frames' quality and the transitions between them, while little progress has been made in generating longer videos. In this paper, we present a method that builds on 3D-VQGAN and transformers to generate videos with thousands of frames. Our evaluation shows that our model trained on 16-frame video clips from standard benchmarks such as UCF-101, Sky Time-lapse, and Taichi-HD datasets can generate diverse, coherent, and high-quality long videos. We also showcase conditional extensions of our approach for generating meaningful long videos by incorporating temporal information with text and audio. Videos and code can be found at https://songweige.github.io/projects/tats/index.html.
Proactive Image Manipulation Detection
Mar 31, 2022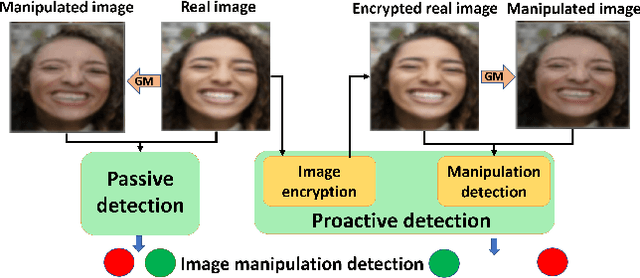
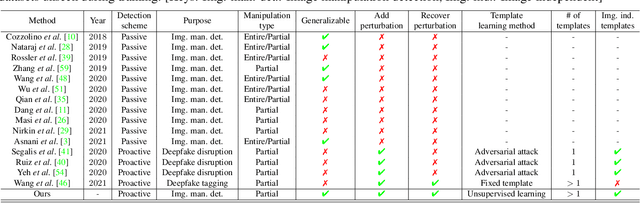
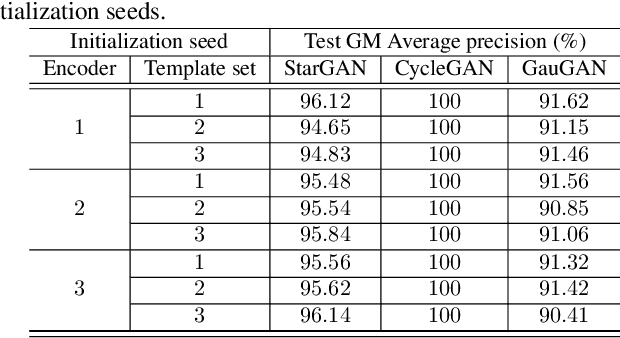

Image manipulation detection algorithms are often trained to discriminate between images manipulated with particular Generative Models (GMs) and genuine/real images, yet generalize poorly to images manipulated with GMs unseen in the training. Conventional detection algorithms receive an input image passively. By contrast, we propose a proactive scheme to image manipulation detection. Our key enabling technique is to estimate a set of templates which when added onto the real image would lead to more accurate manipulation detection. That is, a template protected real image, and its manipulated version, is better discriminated compared to the original real image vs. its manipulated one. These templates are estimated using certain constraints based on the desired properties of templates. For image manipulation detection, our proposed approach outperforms the prior work by an average precision of 16% for CycleGAN and 32% for GauGAN. Our approach is generalizable to a variety of GMs showing an improvement over prior work by an average precision of 10% averaged across 12 GMs. Our code is available at https://www.github.com/vishal3477/proactive_IMD.
Reverse Engineering of Generative Models: Inferring Model Hyperparameters from Generated Images
Jun 15, 2021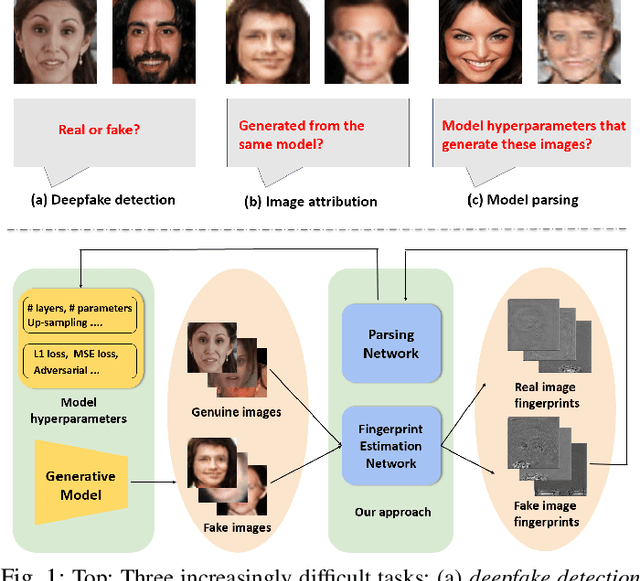


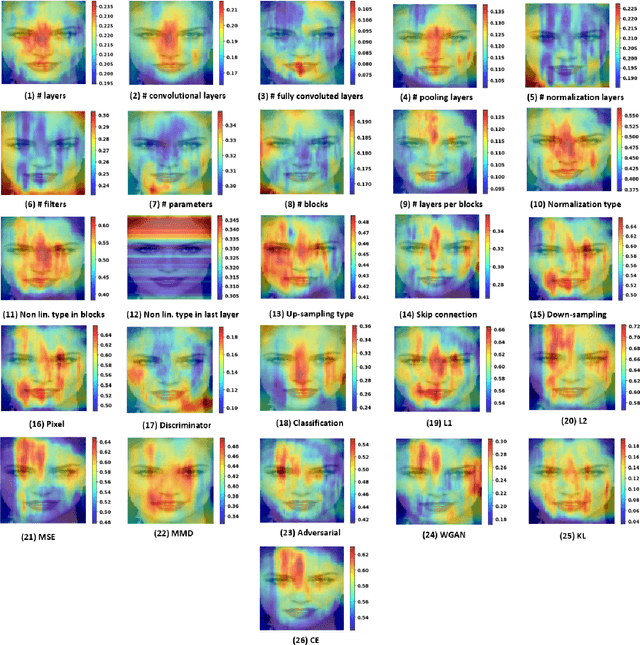
State-of-the-art (SOTA) Generative Models (GMs) can synthesize photo-realistic images that are hard for humans to distinguish from genuine photos. We propose to perform reverse engineering of GMs to infer the model hyperparameters from the images generated by these models. We define a novel problem, "model parsing", as estimating GM network architectures and training loss functions by examining their generated images -- a task seemingly impossible for human beings. To tackle this problem, we propose a framework with two components: a Fingerprint Estimation Network (FEN), which estimates a GM fingerprint from a generated image by training with four constraints to encourage the fingerprint to have desired properties, and a Parsing Network (PN), which predicts network architecture and loss functions from the estimated fingerprints. To evaluate our approach, we collect a fake image dataset with $100$K images generated by $100$ GMs. Extensive experiments show encouraging results in parsing the hyperparameters of the unseen models. Finally, our fingerprint estimation can be leveraged for deepfake detection and image attribution, as we show by reporting SOTA results on both the recent Celeb-DF and image attribution benchmarks.
KGSynNet: A Novel Entity Synonyms Discovery Framework with Knowledge Graph
Apr 01, 2021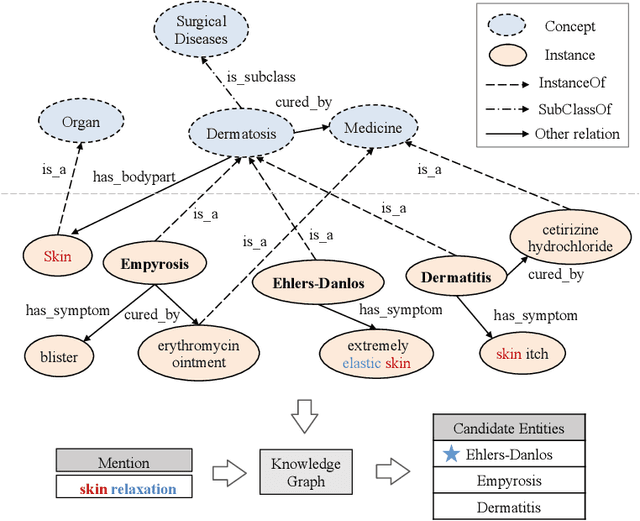
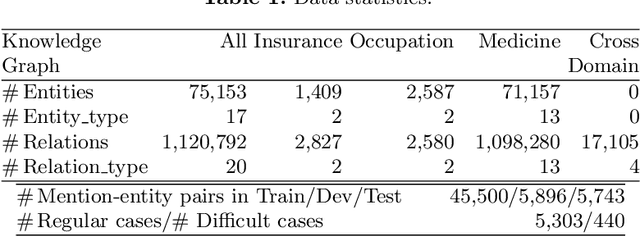
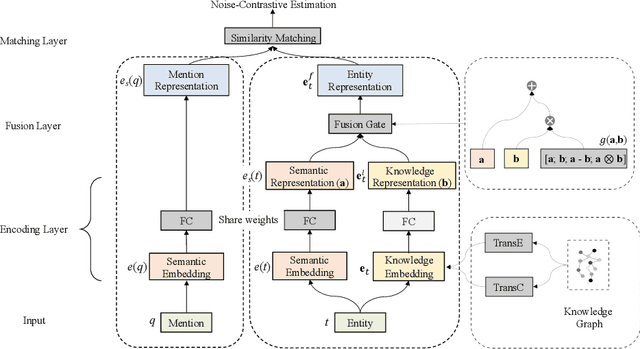
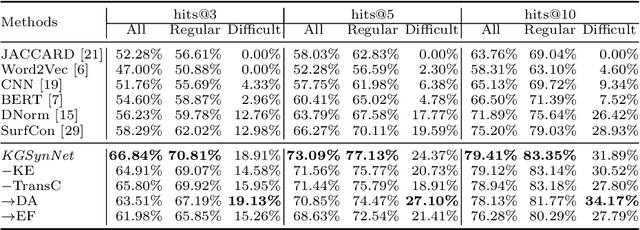
Entity synonyms discovery is crucial for entity-leveraging applications. However, existing studies suffer from several critical issues: (1) the input mentions may be out-of-vocabulary (OOV) and may come from a different semantic space of the entities; (2) the connection between mentions and entities may be hidden and cannot be established by surface matching; and (3) some entities rarely appear due to the long-tail effect. To tackle these challenges, we facilitate knowledge graphs and propose a novel entity synonyms discovery framework, named \emph{KGSynNet}. Specifically, we pre-train subword embeddings for mentions and entities using a large-scale domain-specific corpus while learning the knowledge embeddings of entities via a joint TransC-TransE model. More importantly, to obtain a comprehensive representation of entities, we employ a specifically designed \emph{fusion gate} to adaptively absorb the entities' knowledge information into their semantic features. We conduct extensive experiments to demonstrate the effectiveness of our \emph{KGSynNet} in leveraging the knowledge graph. The experimental results show that the \emph{KGSynNet} improves the state-of-the-art methods by 14.7\% in terms of hits@3 in the offline evaluation and outperforms the BERT model by 8.3\% in the positive feedback rate of an online A/B test on the entity linking module of a question answering system.