 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Compiling with Reinforcement Learning on a Superconducting Processor
Jun 18, 2024



To effectively implement quantum algorithms on noisy intermediate-scale quantum (NISQ) processors is a central task in modern quantum technology. NISQ processors feature tens to a few hundreds of noisy qubits with limited coherence times and gate operations with errors, so NISQ algorithms naturally require employing circuits of short lengths via quantum compilation. Here, we develop a reinforcement learning (RL)-based quantum compiler for a superconducting processor and demonstrate its capability of discovering novel and hardware-amenable circuits with short lengths. We show that for the three-qubit quantum Fourier transformation, a compiled circuit using only seven CZ gates with unity circuit fidelity can be achieved. The compiler is also able to find optimal circuits under device topological constraints, with lengths considerably shorter than those by the conventional method. Our study exemplifies the codesign of the software with hardware for efficient quantum compilation, offering valuable insights for the advancement of RL-based compilers.
HumanNeRF-SE: A Simple yet Effective Approach to Animate HumanNeRF with Diverse Poses
Dec 04, 2023We present HumanNeRF-SE, which can synthesize diverse novel pose images with simple input. Previous HumanNeRF studies require large neural networks to fit the human appearance and prior knowledge. Subsequent methods build upon this approach with some improvements. Instead, we reconstruct this approach, combining explicit and implicit human representations with both general and specific mapping processes. Our key insight is that explicit shape can filter the information used to fit implicit representation, and frozen general mapping combined with point-specific mapping can effectively avoid overfitting and improve pose generalization performance. Our explicit and implicit human represent combination architecture is extremely effective. This is reflected in our model's ability to synthesize images under arbitrary poses with few-shot input and increase the speed of synthesizing images by 15 times through a reduction in computational complexity without using any existing acceleration modules. Compared to the state-of-the-art HumanNeRF studies, HumanNeRF-SE achieves better performance with fewer learnable parameters and less training time (see Figure 1).
SigFormer: Sparse Signal-Guided Transformer for Multi-Modal Human Action Segmentation
Nov 29, 2023



Multi-modal human action segmentation is a critical and challenging task with a wide range of applications. Nowadays, the majority of approaches concentrate on the fusion of dense signals (i.e., RGB, optical flow, and depth maps). However, the potential contributions of sparse IoT sensor signals, which can be crucial for achieving accurate recognition, have not been fully explored. To make up for this, we introduce a Sparse signalguided Transformer (SigFormer) to combine both dense and sparse signals. We employ mask attention to fuse localized features by constraining cross-attention within the regions where sparse signals are valid. However, since sparse signals are discrete, they lack sufficient information about the temporal action boundaries. Therefore, in SigFormer, we propose to emphasize the boundary information at two stages to alleviate this problem. In the first feature extraction stage, we introduce an intermediate bottleneck module to jointly learn both category and boundary features of each dense modality through the inner loss functions. After the fusion of dense modalities and sparse signals, we then devise a two-branch architecture that explicitly models the interrelationship between action category and temporal boundary. Experimental results demonstrate that SigFormer outperforms the state-of-the-art approaches on a multi-modal action segmentation dataset from real industrial environments, reaching an outstanding F1 score of 0.958. The codes and pre-trained models have been available at https://github.com/LIUQI-creat/SigFormer.
RIO: A Benchmark for Reasoning Intention-Oriented Objects in Open Environments
Oct 26, 2023Intention-oriented object detection aims to detect desired objects based on specific intentions or requirements. For instance, when we desire to "lie down and rest", we instinctively seek out a suitable option such as a "bed" or a "sofa" that can fulfill our needs. Previous work in this area is limited either by the number of intention descriptions or by the affordance vocabulary available for intention objects. These limitations make it challenging to handle intentions in open environments effectively. To facilitate this research, we construct a comprehensive dataset called Reasoning Intention-Oriented Objects (RIO). In particular, RIO is specifically designed to incorporate diverse real-world scenarios and a wide range of object categories. It offers the following key features: 1) intention descriptions in RIO are represented as natural sentences rather than a mere word or verb phrase, making them more practical and meaningful; 2) the intention descriptions are contextually relevant to the scene, enabling a broader range of potential functionalities associated with the objects; 3) the dataset comprises a total of 40,214 images and 130,585 intention-object pairs. With the proposed RIO, we evaluate the ability of some existing models to reason intention-oriented objects in open environments.
Parsing is All You Need for Accurate Gait Recognition in the Wild
Aug 31, 2023



Binary silhouettes and keypoint-based skeletons have dominated human gait recognition studies for decades since they are easy to extract from video frames. Despite their success in gait recognition for in-the-lab environments, they usually fail in real-world scenarios due to their low information entropy for gait representations. To achieve accurate gait recognition in the wild, this paper presents a novel gait representation, named Gait Parsing Sequence (GPS). GPSs are sequences of fine-grained human segmentation, i.e., human parsing, extracted from video frames, so they have much higher information entropy to encode the shapes and dynamics of fine-grained human parts during walking. Moreover, to effectively explore the capability of the GPS representation, we propose a novel human parsing-based gait recognition framework, named ParsingGait. ParsingGait contains a Convolutional Neural Network (CNN)-based backbone and two light-weighted heads. The first head extracts global semantic features from GPSs, while the other one learns mutual information of part-level features through Graph Convolutional Networks to model the detailed dynamics of human walking. Furthermore, due to the lack of suitable datasets, we build the first parsing-based dataset for gait recognition in the wild, named Gait3D-Parsing, by extending the large-scale and challenging Gait3D dataset. Based on Gait3D-Parsing, we comprehensively evaluate our method and existing gait recognition methods. The experimental results show a significant improvement in accuracy brought by the GPS representation and the superiority of ParsingGait. The code and dataset are available at https://gait3d.github.io/gait3d-parsing-hp .
Bridging the Gap: Multi-Level Cross-Modality Joint Alignment for Visible-Infrared Person Re-Identification
Jul 17, 2023Visible-Infrared person Re-IDentification (VI-ReID) is a challenging cross-modality image retrieval task that aims to match pedestrians' images across visible and infrared cameras. To solve the modality gap, existing mainstream methods adopt a learning paradigm converting the image retrieval task into an image classification task with cross-entropy loss and auxiliary metric learning losses. These losses follow the strategy of adjusting the distribution of extracted embeddings to reduce the intra-class distance and increase the inter-class distance. However, such objectives do not precisely correspond to the final test setting of the retrieval task, resulting in a new gap at the optimization level. By rethinking these keys of VI-ReID, we propose a simple and effective method, the Multi-level Cross-modality Joint Alignment (MCJA), bridging both modality and objective-level gap. For the former, we design the Modality Alignment Augmentation, which consists of three novel strategies, the weighted grayscale, cross-channel cutmix, and spectrum jitter augmentation, effectively reducing modality discrepancy in the image space. For the latter, we introduce a new Cross-Modality Retrieval loss. It is the first work to constrain from the perspective of the ranking list, aligning with the goal of the testing stage. Moreover, based on the global feature only, our method exhibits good performance and can serve as a strong baseline method for the VI-ReID community.
TRACE: 5D Temporal Regression of Avatars with Dynamic Cameras in 3D Environments
Jun 05, 2023Although the estimation of 3D human pose and shape (HPS) is rapidly progressing, current methods still cannot reliably estimate moving humans in global coordinates, which is critical for many applications. This is particularly challenging when the camera is also moving, entangling human and camera motion. To address these issues, we adopt a novel 5D representation (space, time, and identity) that enables end-to-end reasoning about people in scenes. Our method, called TRACE, introduces several novel architectural components. Most importantly, it uses two new "maps" to reason about the 3D trajectory of people over time in camera, and world, coordinates. An additional memory unit enables persistent tracking of people even during long occlusions. TRACE is the first one-stage method to jointly recover and track 3D humans in global coordinates from dynamic cameras. By training it end-to-end, and using full image information, TRACE achieves state-of-the-art performance on tracking and HPS benchmarks. The code and dataset are released for research purposes.
DPIT: Dual-Pipeline Integrated Transformer for Human Pose Estimation
Sep 02, 2022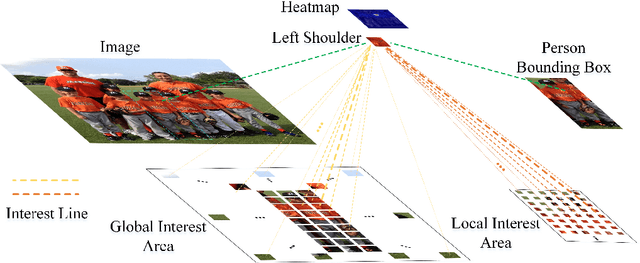
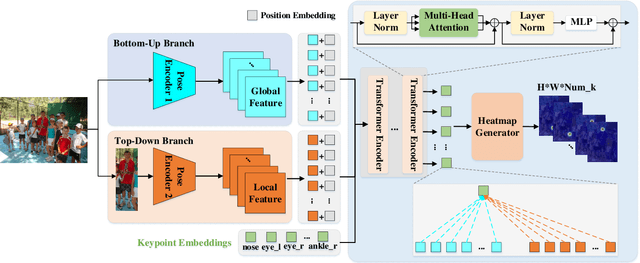
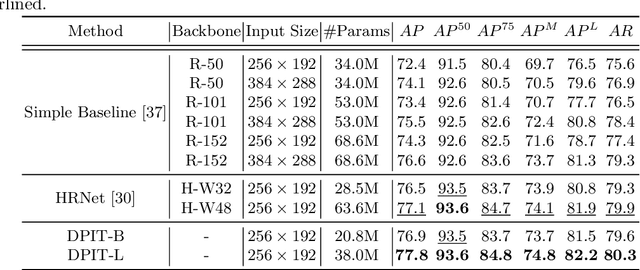
Human pose estimation aims to figure out the keypoints of all people in different scenes. Current approaches still face some challenges despite promising results. Existing top-down methods deal with a single person individually, without the interaction between different people and the scene they are situated in. Consequently, the performance of human detection degrades when serious occlusion happens. On the other hand, existing bottom-up methods consider all people at the same time and capture the global knowledge of the entire image. However, they are less accurate than the top-down methods due to the scale variation. To address these problems, we propose a novel Dual-Pipeline Integrated Transformer (DPIT) by integrating top-down and bottom-up pipelines to explore the visual clues of different receptive fields and achieve their complementarity. Specifically, DPIT consists of two branches, the bottom-up branch deals with the whole image to capture the global visual information, while the top-down branch extracts the feature representation of local vision from the single-human bounding box. Then, the extracted feature representations from bottom-up and top-down branches are fed into the transformer encoder to fuse the global and local knowledge interactively. Moreover, we define the keypoint queries to explore both full-scene and single-human posture visual clues to realize the mutual complementarity of the two pipelines. To the best of our knowledge, this is one of the first works to integrate the bottom-up and top-down pipelines with transformers for human pose estimation. Extensive experiments on COCO and MPII datasets demonstrate that our DPIT achieves comparable performance to the state-of-the-art methods.
WOC: A Handy Webcam-based 3D Online Chatroom
Sep 02, 2022
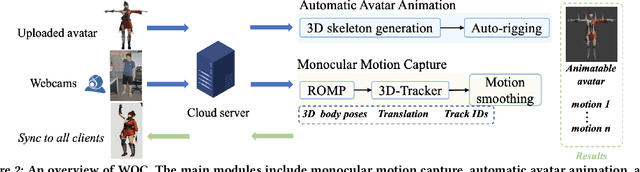
We develop WOC, a webcam-based 3D virtual online chatroom for multi-person interaction, which captures the 3D motion of users and drives their individual 3D virtual avatars in real-time. Compared to the existing wearable equipment-based solution, WOC offers convenient and low-cost 3D motion capture with a single camera. To promote the immersive chat experience, WOC provides high-fidelity virtual avatar manipulation, which also supports the user-defined characters. With the distributed data flow service, the system delivers highly synchronized motion and voice for all users. Deployed on the website and no installation required, users can freely experience the virtual online chat at https://yanch.cloud.
SiRi: A Simple Selective Retraining Mechanism for Transformer-based Visual Grounding
Jul 27, 2022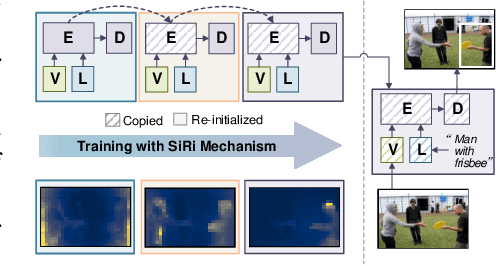
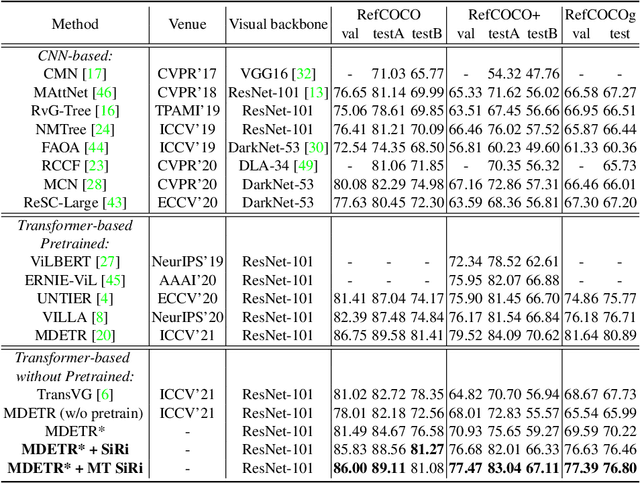
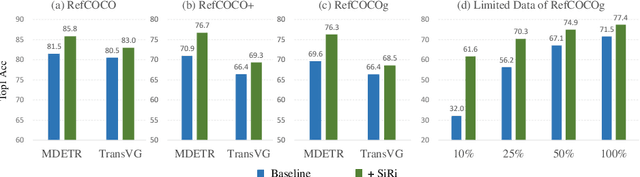
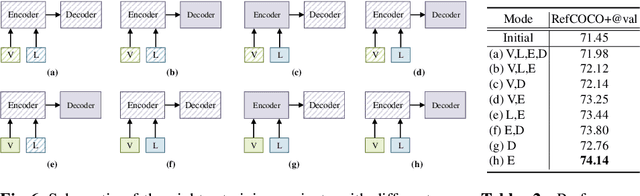
In this paper, we investigate how to achieve better visual grounding with modern vision-language transformers, and propose a simple yet powerful Selective Retraining (SiRi) mechanism for this challenging task. Particularly, SiRi conveys a significant principle to the research of visual grounding, i.e., a better initialized vision-language encoder would help the model converge to a better local minimum, advancing the performance accordingly. In specific, we continually update the parameters of the encoder as the training goes on, while periodically re-initialize rest of the parameters to compel the model to be better optimized based on an enhanced encoder. SiRi can significantly outperform previous approaches on three popular benchmarks. Specifically, our method achieves 83.04% Top1 accuracy on RefCOCO+ testA, outperforming the state-of-the-art approaches (training from scratch) by more than 10.21%. Additionally, we reveal that SiRi performs surprisingly superior even with limited training data. We also extend it to transformer-based visual grounding models and other vision-language tasks to verify the validity.