 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoGAN: Bridging Synthetic-to-Real Domain Gap by Joint Optimization of Domain Translation and Stereo Matching
May 05, 2020
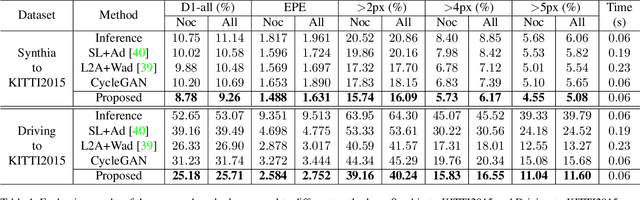

Large-scale synthetic datasets are beneficial to stereo matching but usually introduce known domain bias. Although unsupervised image-to-image translation networks represented by CycleGAN show great potential in dealing with domain gap, it is non-trivial to generalize this method to stereo matching due to the problem of pixel distortion and stereo mismatch after translation. In this paper, we propose an end-to-end training framework with domain translation and stereo matching networks to tackle this challenge. First, joint optimization between domain translation and stereo matching networks in our end-to-end framework makes the former facilitate the latter one to the maximum extent. Second, this framework introduces two novel losses, i.e., bidirectional multi-scale feature re-projection loss and correlation consistency loss, to help translate all synthetic stereo images into realistic ones as well as maintain epipolar constraints. The effective combination of above two contributions leads to impressive stereo-consistent translation and disparity estimation accuracy. In addition, a mode seeking regularization term is added to endow the synthetic-to-real translation results with higher fine-grained diversity. Extensive experiments demonstrate the effectiveness of the proposed framework on bridging the synthetic-to-real domain gap on stereo matching.
Polarized Reflection Removal with Perfect Alignment in the Wild
Mar 28, 2020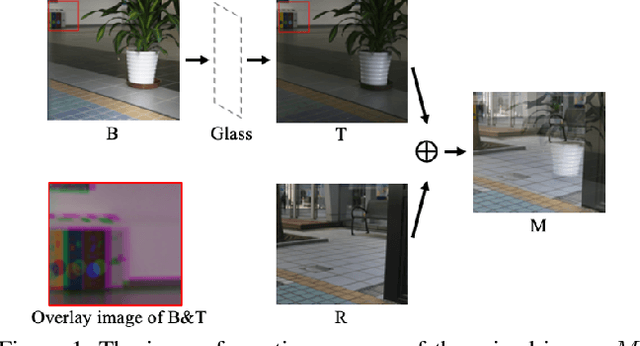

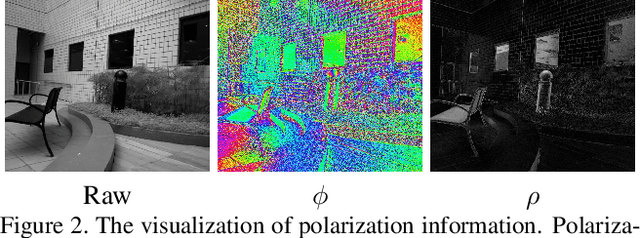
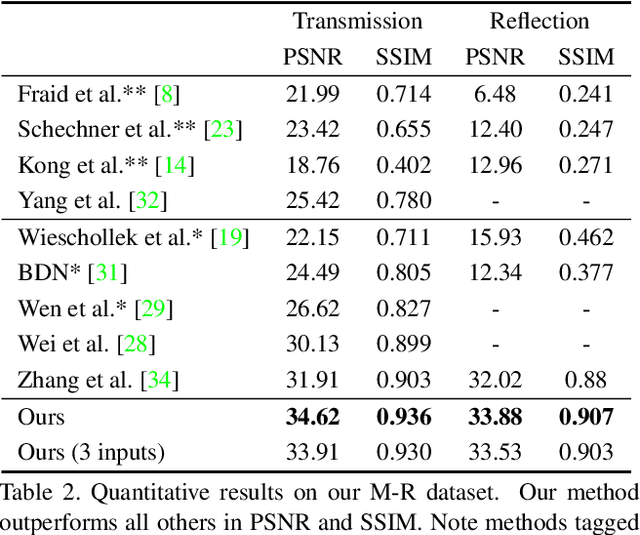
We present a novel formulation to removing reflection from polarized images in the wild. We first identify the misalignment issues of existing reflection removal datasets where the collected reflection-free images are not perfectly aligned with input mixed images due to glass refraction. Then we build a new dataset with more than 100 types of glass in which obtained transmission images are perfectly aligned with input mixed images. Second, capitalizing on the special relationship between reflection and polarized light, we propose a polarized reflection removal model with a two-stage architecture. In addition, we design a novel perceptual NCC loss that can improve the performance of reflection removal and general image decomposition tasks. We conduct extensive experiments, and results suggest that our model outperforms state-of-the-art methods on reflection removal.
Quadratic video interpolation
Nov 02, 2019
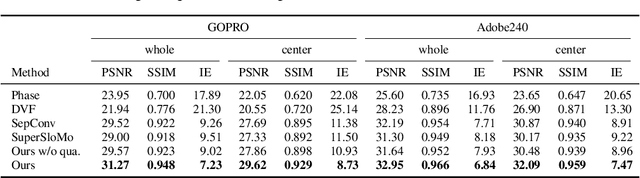
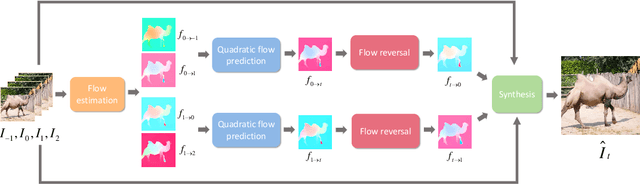

Video interpolation is an important problem in computer vision, which helps overcome the temporal limitation of camera sensors. Existing video interpolation methods usually assume uniform motion between consecutive frames and use linear models for interpolation, which cannot well approximate the complex motion in the real world. To address these issues, we propose a quadratic video interpolation method which exploits the acceleration information in videos. This method allows prediction with curvilinear trajectory and variable velocity, and generates more accurate interpolation results. For high-quality frame synthesis, we develop a flow reversal layer to estimate flow fields starting from the unknown target frame to the source frame. In addition, we present techniques for flow refinement. Extensive experiments demonstrate that our approach performs favorably against the existing linear models on a wide variety of video datasets.
Toward 3D Object Reconstruction from Stereo Images
Oct 21, 2019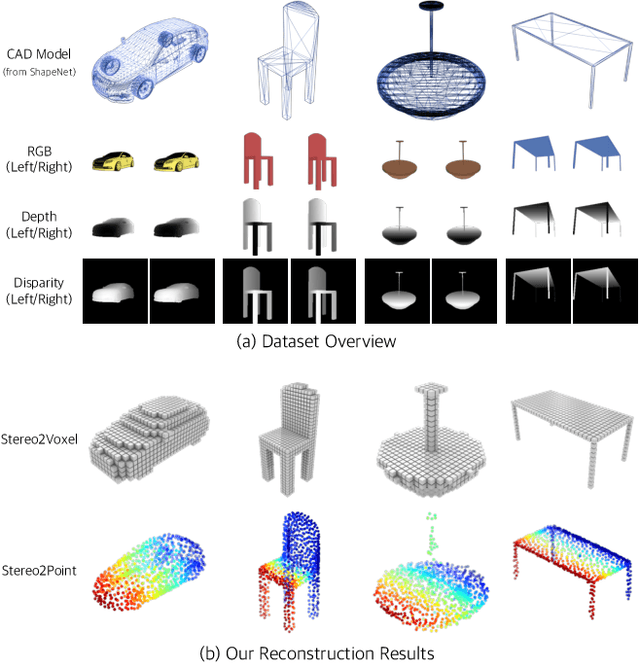
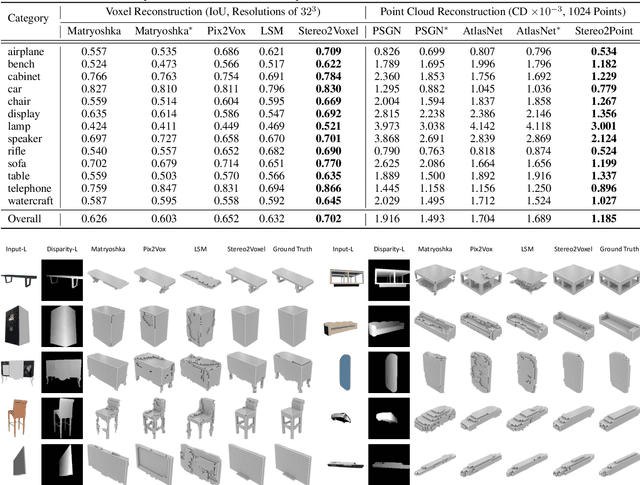
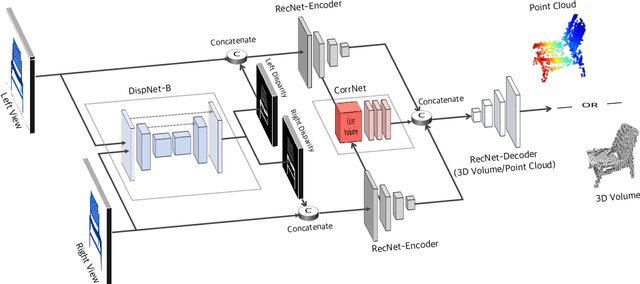
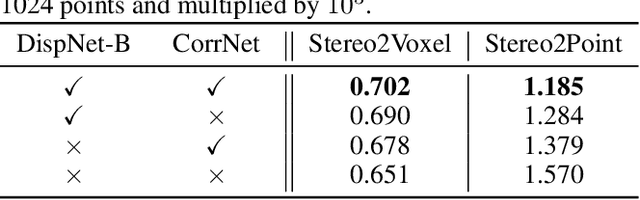
Inferring the 3D shape of an object from an RGB image has shown impressive results, however, existing methods rely primarily on recognizing the most similar 3D model from the training set to solve the problem. These methods suffer from poor generalization and may lead to low-quality reconstructions for unseen objects. Nowadays, stereo cameras are pervasive in emerging devices such as dual-lens smartphones and robots, which enables the use of the two-view nature of stereo images to explore the 3D structure and thus improve the reconstruction performance. In this paper, we propose a new deep learning framework for reconstructing the 3D shape of an object from a pair of stereo images, which reasons about the 3D structure of the object by taking bidirectional disparities and feature correspondences between the two views into account. Besides, we present a large-scale synthetic benchmarking dataset, namely StereoShapeNet, containing 1,052,976 pairs of stereo images rendered from ShapeNet along with the corresponding bidirectional depth and disparity maps. Experimental results on the StereoShapeNet benchmark demonstrate that the proposed framework outperforms the state-of-the-art methods.
Deep End-to-End Alignment and Refinement for Time-of-Flight RGB-D Module
Sep 17, 2019
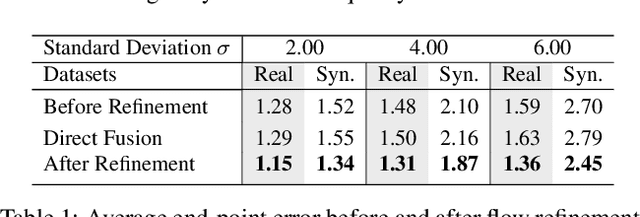
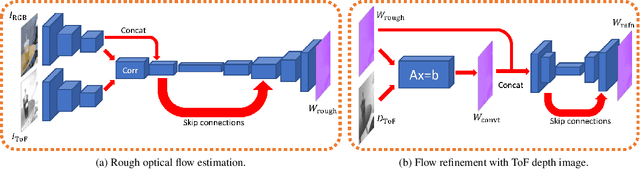
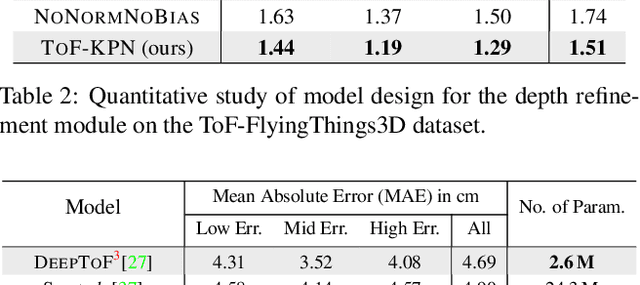
Recently, it is increasingly popular to equip mobile RGB cameras with Time-of-Flight (ToF) sensors for active depth sensing. However, for off-the-shelf ToF sensors, one must tackle two problems in order to obtain high-quality depth with respect to the RGB camera, namely 1) online calibration and alignment; and 2) complicated error correction for ToF depth sensing. In this work, we propose a framework for jointly alignment and refinement via deep learning. First, a cross-modal optical flow between the RGB image and the ToF amplitude image is estimated for alignment. The aligned depth is then refined via an improved kernel predicting network that performs kernel normalization and applies the bias prior to the dynamic convolution. To enrich our data for end-to-end training, we have also synthesized a dataset using tools from computer graphics. Experimental results demonstrate the effectiveness of our approach, achieving state-of-the-art for ToF refinement.
Towards Real Scene Super-Resolution with Raw Images
May 29, 2019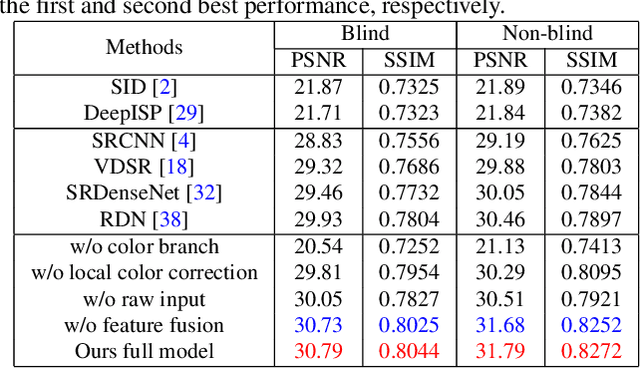
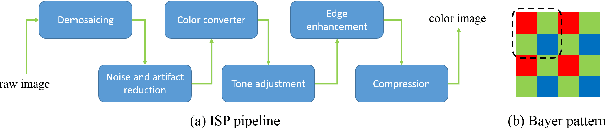
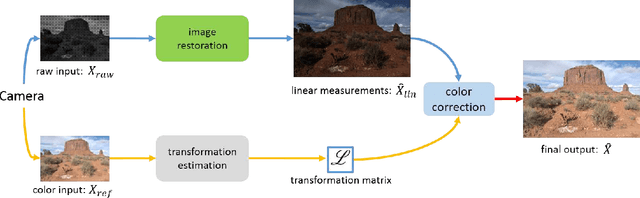
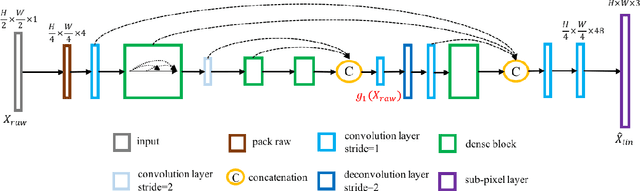
Most existing super-resolution methods do not perform well in real scenarios due to lack of realistic training data and information loss of the model input. To solve the first problem, we propose a new pipeline to generate realistic training data by simulating the imaging process of digital cameras. And to remedy the information loss of the input, we develop a dual convolutional neural network to exploit the originally captured radiance information in raw images. In addition, we propose to learn a spatially-variant color transformation which helps more effective color corrections. Extensive experiments demonstrate that super-resolution with raw data helps recover fine details and clear structures, and more importantly, the proposed network and data generation pipeline achieve superior results for single image super-resolution in real scenarios.
Learning Deformable Kernels for Image and Video Denoising
Apr 15, 2019

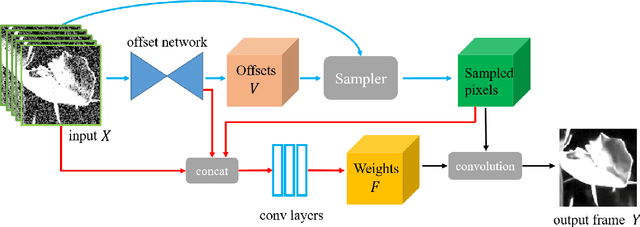

Most of the classical denoising methods restore clear results by selecting and averaging pixels in the noisy input. Instead of relying on hand-crafted selecting and averaging strategies, we propose to explicitly learn this process with deep neural networks. Specifically, we propose deformable 2D kernels for image denoising where the sampling locations and kernel weights are both learned. The proposed kernel naturally adapts to image structures and could effectively reduce the oversmoothing artifacts. Furthermore, we develop 3D deformable kernels for video denoising to more efficiently sample pixels across the spatial-temporal space. Our method is able to solve the misalignment issues of large motion from dynamic scenes. For better training our video denoising model, we introduce the trilinear sampler and a new regularization term. We demonstrate that the proposed method performs favorably against the state-of-the-art image and video denoising approaches on both synthetic and real-world data.
Deep Surface Normal Estimation with Hierarchical RGB-D Fusion
Apr 06, 2019
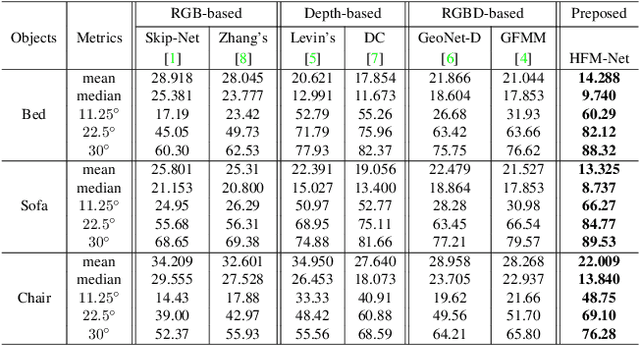
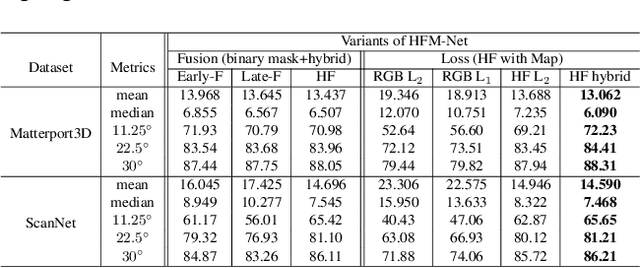
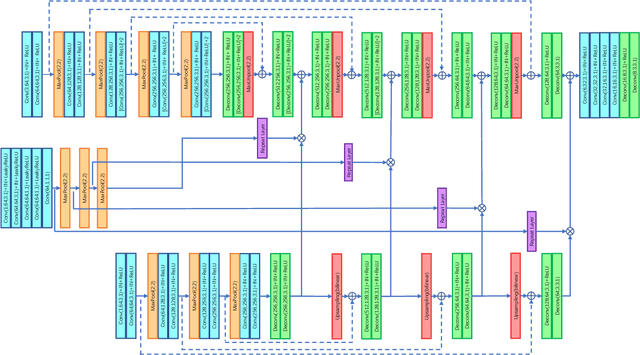
The growing availability of commodity RGB-D cameras has boosted the applications in the field of scene understanding. However, as a fundamental scene understanding task, surface normal estimation from RGB-D data lacks thorough investigation. In this paper, a hierarchical fusion network with adaptive feature re-weighting is proposed for surface normal estimation from a single RGB-D image. Specifically, the features from color image and depth are successively integrated at multiple scales to ensure global surface smoothness while preserving visually salient details. Meanwhile, the depth features are re-weighted with a confidence map estimated from depth before merging into the color branch to avoid artifacts caused by input depth corruption. Additionally, a hybrid multi-scale loss function is designed to learn accurate normal estimation given noisy ground-truth dataset. Extensive experimental results validate the effectiveness of the fusion strategy and the loss design, outperforming state-of-the-art normal estimation schemes.
DSR: Direct Self-rectification for Uncalibrated Dual-lens Cameras
Sep 26, 2018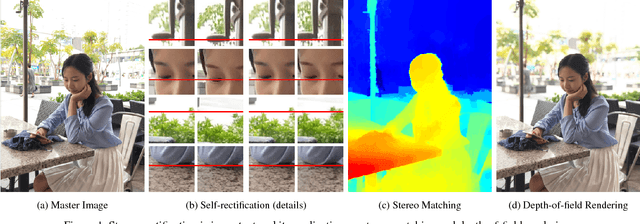
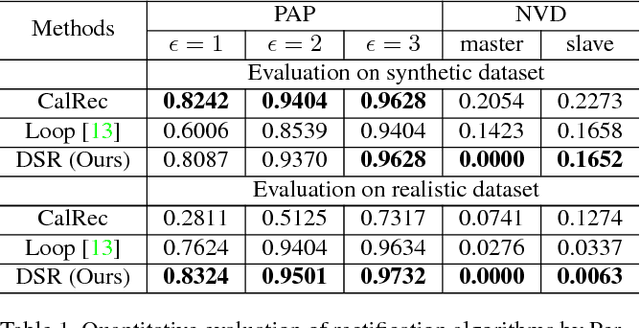
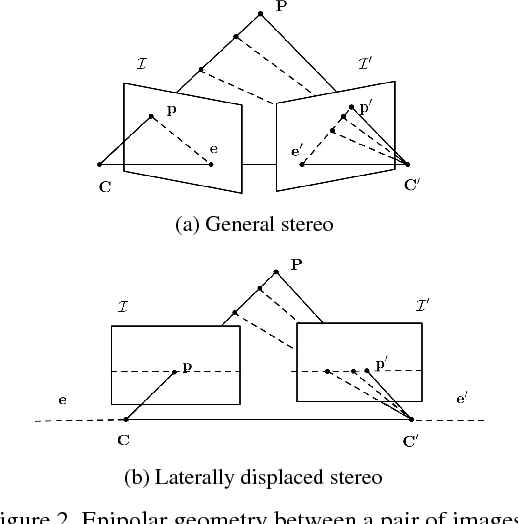

With the developments of dual-lens camera modules,depth information representing the third dimension of thecaptured scenes becomes available for smartphones. It isestimated by stereo matching algorithms, taking as input thetwo views captured by dual-lens cameras at slightly differ-ent viewpoints. Depth-of-field rendering (also be referred toas synthetic defocus or bokeh) is one of the trending depth-based applications. However, to achieve fast depth estima-tion on smartphones, the stereo pairs need to be rectified inthe first place. In this paper, we propose a cost-effective so-lution to perform stereo rectification for dual-lens camerascalled direct self-rectification, short for DSR1. It removesthe need of individual offline calibration for every pair ofdual-lens cameras. In addition, the proposed solution isrobust to the slight movements, e.g., due to collisions, ofthe dual-lens cameras after fabrication. Different with ex-isting self-rectification approaches, our approach computesthe homography in a novel way with zero geometric distor-tions introduced to the master image. It is achieved by di-rectly minimizing the vertical displacements of correspond-ing points between the original master image and the trans-formed slave image. Our method is evaluated on both real-istic and synthetic stereo image pairs, and produces supe-rior results compared to the calibrated rectification or otherself-rectification approaches
Confidence Inference for Focused Learning in Stereo Matching
Sep 25, 2018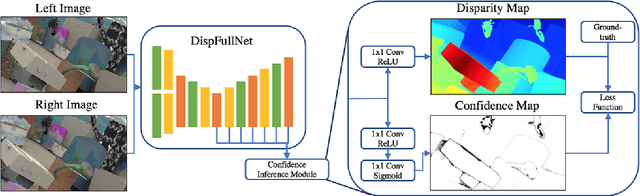
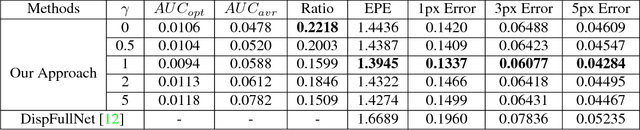
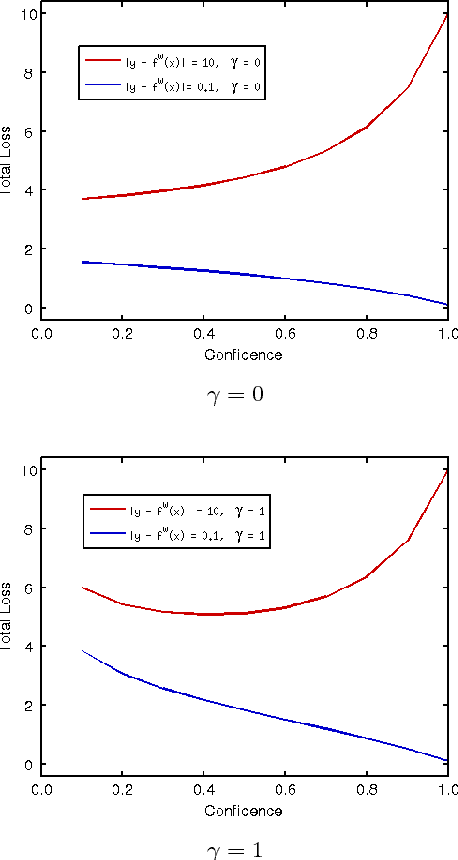

In this paper, we present confidence inference approachin an unsupervised way in stereo matching. Deep Neu-ral Networks (DNNs) have recently been achieving state-of-the-art performance. However, it is often hard to tellwhether the trained model was making sensible predictionsor just guessing at random. To address this problem, westart from a probabilistic interpretation of theL1loss usedin stereo matching, which inherently assumes an indepen-dent and identical (aka i.i.d.) Laplacian distribution. Weshow that with the newly introduced dense confidence map,the identical assumption is relaxed. Intuitively, the vari-ance in the Laplacian distribution is large for low confidentpixels while small for high-confidence pixels. In practice,the network learns toattenuatelow-confidence pixels (e.g.,noisy input, occlusions, featureless regions) andfocusonhigh-confidence pixels. Moreover, it can be observed fromexperiments that the focused learning is very helpful in find-ing a better convergence state of the trained model, reduc-ing over-fitting on a given dataset.