 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
RubricBench: Aligning Model-Generated Rubrics with Human Standards
Mar 03, 2026As Large Language Model (LLM) alignment evolves from simple completions to complex, highly sophisticated generation, Reward Models are increasingly shifting toward rubric-guided evaluation to mitigate surface-level biases. However, the community lacks a unified benchmark to assess this evaluation paradigm, as existing benchmarks lack both the discriminative complexity and the ground-truth rubric annotations required for rigorous analysis. To bridge this gap, we introduce RubricBench, a curated benchmark with 1,147 pairwise comparisons specifically designed to assess the reliability of rubric-based evaluation. Our construction employs a multi-dimensional filtration pipeline to target hard samples featuring nuanced input complexity and misleading surface bias, augmenting each with expert-annotated, atomic rubrics derived strictly from instructions. Comprehensive experiments reveal a substantial capability gap between human-annotated and model-generated rubrics, indicating that even state-of-the-art models struggle to autonomously specify valid evaluation criteria, lagging considerably behind human-guided performance.
CheMatAgent: Enhancing LLMs for Chemistry and Materials Science through Tree-Search Based Tool Learning
Jun 12, 2025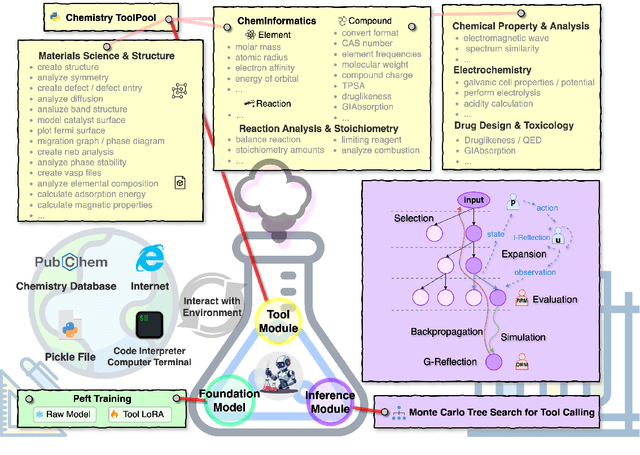
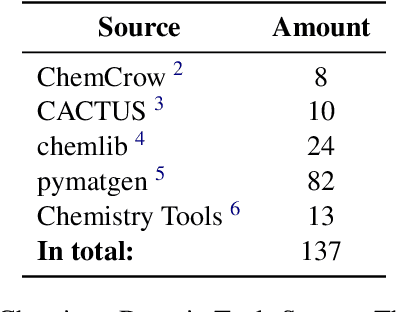
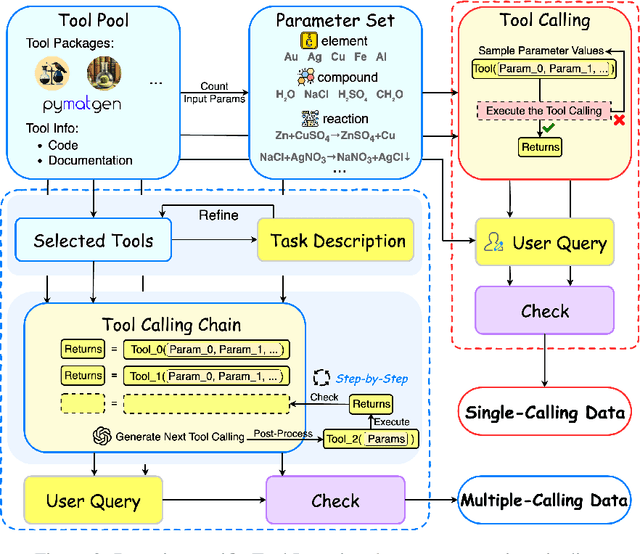

Large language models (LLMs) have recently demonstrated promising capabilities in chemistry tasks while still facing challenges due to outdated pretraining knowledge and the difficulty of incorporating specialized chemical expertise. To address these issues, we propose an LLM-based agent that synergistically integrates 137 external chemical tools created ranging from basic information retrieval to complex reaction predictions, and a dataset curation pipeline to generate the dataset ChemToolBench that facilitates both effective tool selection and precise parameter filling during fine-tuning and evaluation. We introduce a Hierarchical Evolutionary Monte Carlo Tree Search (HE-MCTS) framework, enabling independent optimization of tool planning and execution. By leveraging self-generated data, our approach supports step-level fine-tuning (FT) of the policy model and training task-adaptive PRM and ORM that surpass GPT-4o. Experimental evaluations demonstrate that our approach significantly improves performance in Chemistry QA and discovery tasks, offering a robust solution to integrate specialized tools with LLMs for advanced chemical applications. All datasets and code are available at https://github.com/AI4Chem/ChemistryAgent .
ChemAgent: Enhancing LLMs for Chemistry and Materials Science through Tree-Search Based Tool Learning
Jun 09, 2025Large language models (LLMs) have recently demonstrated promising capabilities in chemistry tasks while still facing challenges due to outdated pretraining knowledge and the difficulty of incorporating specialized chemical expertise. To address these issues, we propose an LLM-based agent that synergistically integrates 137 external chemical tools created ranging from basic information retrieval to complex reaction predictions, and a dataset curation pipeline to generate the dataset ChemToolBench that facilitates both effective tool selection and precise parameter filling during fine-tuning and evaluation. We introduce a Hierarchical Evolutionary Monte Carlo Tree Search (HE-MCTS) framework, enabling independent optimization of tool planning and execution. By leveraging self-generated data, our approach supports step-level fine-tuning (FT) of the policy model and training task-adaptive PRM and ORM that surpass GPT-4o. Experimental evaluations demonstrate that our approach significantly improves performance in Chemistry QA and discovery tasks, offering a robust solution to integrate specialized tools with LLMs for advanced chemical applications. All datasets and code are available at https://github.com/AI4Chem/ChemistryAgent .