 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen an Image is Worth 1,024 x 1,024 Words: A Case Study in Computational Pathology
Dec 06, 2023This technical report presents LongViT, a vision Transformer that can process gigapixel images in an end-to-end manner. Specifically, we split the gigapixel image into a sequence of millions of patches and project them linearly into embeddings. LongNet is then employed to model the extremely long sequence, generating representations that capture both short-range and long-range dependencies. The linear computation complexity of LongNet, along with its distributed algorithm, enables us to overcome the constraints of both computation and memory. We apply LongViT in the field of computational pathology, aiming for cancer diagnosis and prognosis within gigapixel whole-slide images. Experimental results demonstrate that LongViT effectively encodes gigapixel images and outperforms previous state-of-the-art methods on cancer subtyping and survival prediction. Code and models will be available at https://aka.ms/LongViT.
Kosmos-2.5: A Multimodal Literate Model
Sep 20, 2023



We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
LongNet: Scaling Transformers to 1,000,000,000 Tokens
Jul 19, 2023Scaling sequence length has become a critical demand in the era of large language models. However, existing methods struggle with either computational complexity or model expressivity, rendering the maximum sequence length restricted. To address this issue, we introduce LongNet, a Transformer variant that can scale sequence length to more than 1 billion tokens, without sacrificing the performance on shorter sequences. Specifically, we propose dilated attention, which expands the attentive field exponentially as the distance grows. LongNet has significant advantages: 1) it has a linear computation complexity and a logarithm dependency between any two tokens in a sequence; 2) it can be served as a distributed trainer for extremely long sequences; 3) its dilated attention is a drop-in replacement for standard attention, which can be seamlessly integrated with the existing Transformer-based optimization. Experiments results demonstrate that LongNet yields strong performance on both long-sequence modeling and general language tasks. Our work opens up new possibilities for modeling very long sequences, e.g., treating a whole corpus or even the entire Internet as a sequence.
Kosmos-2: Grounding Multimodal Large Language Models to the World
Jul 13, 2023
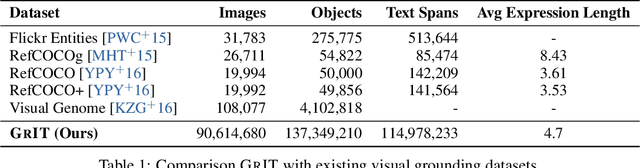

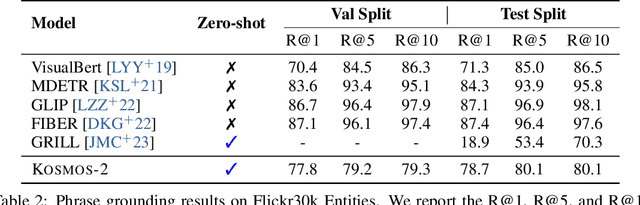
We introduce Kosmos-2, a Multimodal Large Language Model (MLLM), enabling new capabilities of perceiving object descriptions (e.g., bounding boxes) and grounding text to the visual world. Specifically, we represent refer expressions as links in Markdown, i.e., ``[text span](bounding boxes)'', where object descriptions are sequences of location tokens. Together with multimodal corpora, we construct large-scale data of grounded image-text pairs (called GrIT) to train the model. In addition to the existing capabilities of MLLMs (e.g., perceiving general modalities, following instructions, and performing in-context learning), Kosmos-2 integrates the grounding capability into downstream applications. We evaluate Kosmos-2 on a wide range of tasks, including (i) multimodal grounding, such as referring expression comprehension, and phrase grounding, (ii) multimodal referring, such as referring expression generation, (iii) perception-language tasks, and (iv) language understanding and generation. This work lays out the foundation for the development of Embodiment AI and sheds light on the big convergence of language, multimodal perception, action, and world modeling, which is a key step toward artificial general intelligence. Code and pretrained models are available at https://aka.ms/kosmos-2.
Language Is Not All You Need: Aligning Perception with Language Models
Mar 01, 2023



A big convergence of language, multimodal perception, action, and world modeling is a key step toward artificial general intelligence. In this work, we introduce Kosmos-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). Specifically, we train Kosmos-1 from scratch on web-scale multimodal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data. We evaluate various settings, including zero-shot, few-shot, and multimodal chain-of-thought prompting, on a wide range of tasks without any gradient updates or finetuning. Experimental results show that Kosmos-1 achieves impressive performance on (i) language understanding, generation, and even OCR-free NLP (directly fed with document images), (ii) perception-language tasks, including multimodal dialogue, image captioning, visual question answering, and (iii) vision tasks, such as image recognition with descriptions (specifying classification via text instructions). We also show that MLLMs can benefit from cross-modal transfer, i.e., transfer knowledge from language to multimodal, and from multimodal to language. In addition, we introduce a dataset of Raven IQ test, which diagnoses the nonverbal reasoning capability of MLLMs.
TorchScale: Transformers at Scale
Nov 23, 2022Large Transformers have achieved state-of-the-art performance across many tasks. Most open-source libraries on scaling Transformers focus on improving training or inference with better parallelization. In this work, we present TorchScale, an open-source toolkit that allows researchers and developers to scale up Transformers efficiently and effectively. TorchScale has the implementation of several modeling techniques, which can improve modeling generality and capability, as well as training stability and efficiency. Experimental results on language modeling and neural machine translation demonstrate that TorchScale can successfully scale Transformers to different sizes without tears. The library is available at https://aka.ms/torchscale.
Foundation Transformers
Oct 19, 2022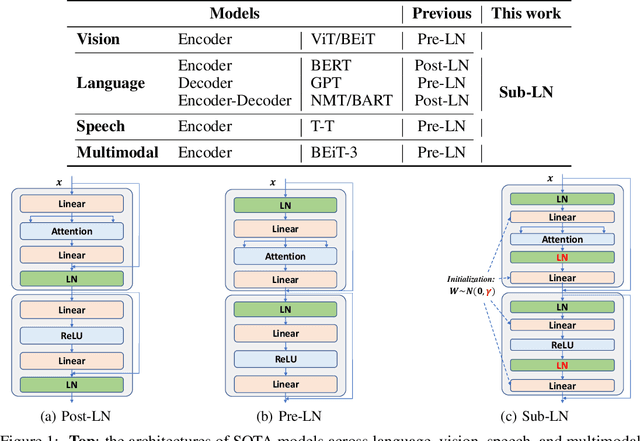
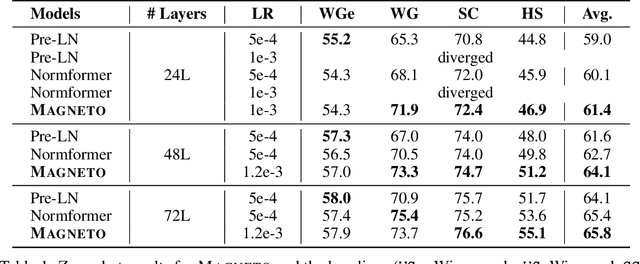
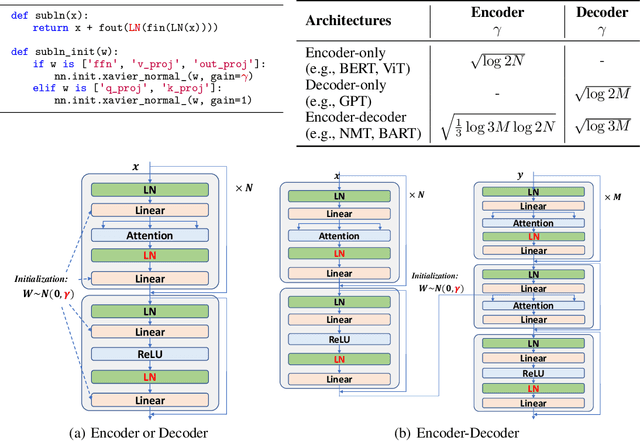
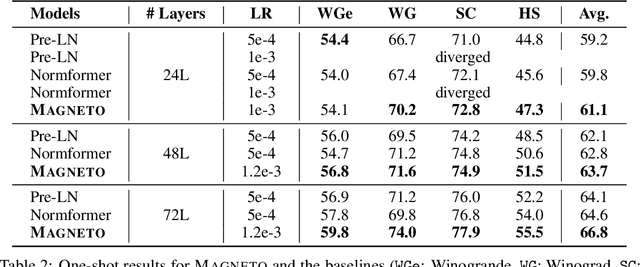
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-LayerNorm for GPT and vision Transformers. We call for the development of Foundation Transformer for true general-purpose modeling, which serves as a go-to architecture for various tasks and modalities with guaranteed training stability. In this work, we introduce a Transformer variant, named Magneto, to fulfill the goal. Specifically, we propose Sub-LayerNorm for good expressivity, and the initialization strategy theoretically derived from DeepNet for stable scaling up. Extensive experiments demonstrate its superior performance and better stability than the de facto Transformer variants designed for various applications, including language modeling (i.e., BERT, and GPT), machine translation, vision pretraining (i.e., BEiT), speech recognition, and multimodal pretraining (i.e., BEiT-3).
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
Aug 31, 2022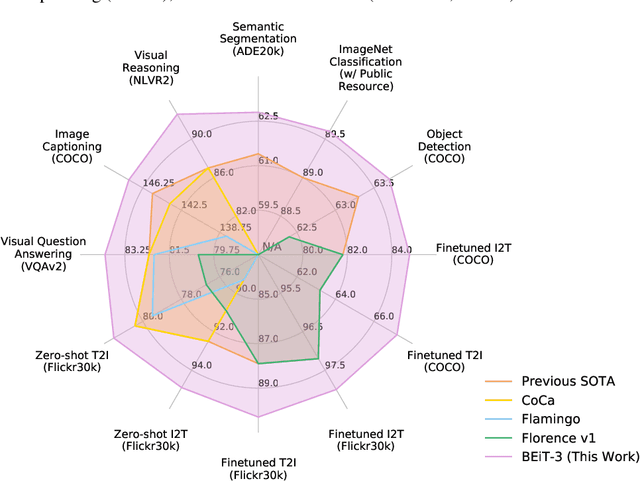
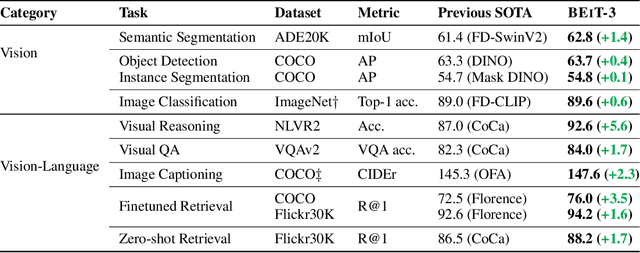
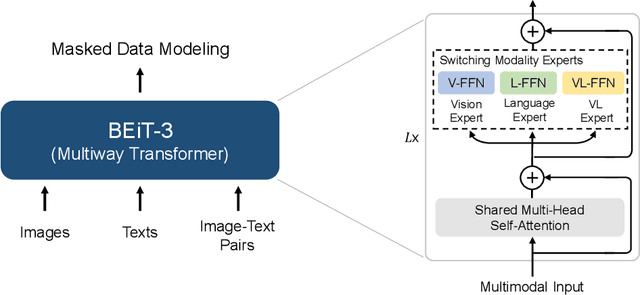

A big convergence of language, vision, and multimodal pretraining is emerging. In this work, we introduce a general-purpose multimodal foundation model BEiT-3, which achieves state-of-the-art transfer performance on both vision and vision-language tasks. Specifically, we advance the big convergence from three aspects: backbone architecture, pretraining task, and model scaling up. We introduce Multiway Transformers for general-purpose modeling, where the modular architecture enables both deep fusion and modality-specific encoding. Based on the shared backbone, we perform masked "language" modeling on images (Imglish), texts (English), and image-text pairs ("parallel sentences") in a unified manner. Experimental results show that BEiT-3 obtains state-of-the-art performance on object detection (COCO), semantic segmentation (ADE20K), image classification (ImageNet), visual reasoning (NLVR2), visual question answering (VQAv2), image captioning (COCO), and cross-modal retrieval (Flickr30K, COCO).
Language Models are General-Purpose Interfaces
Jun 13, 2022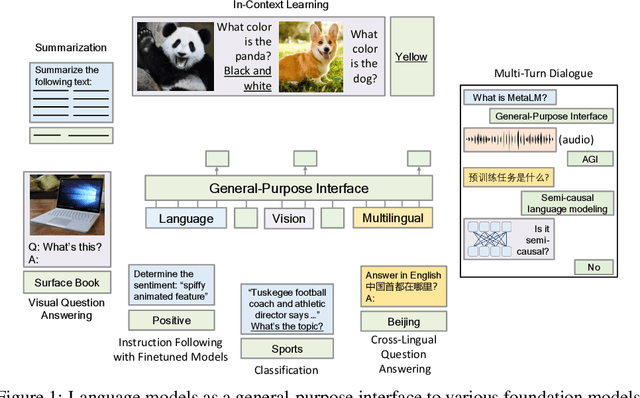

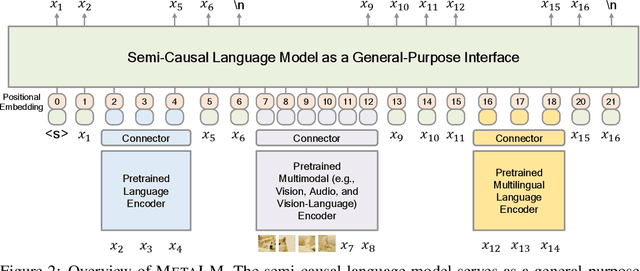
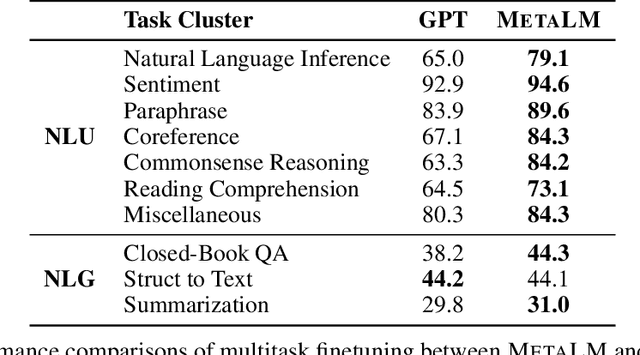
Foundation models have received much attention due to their effectiveness across a broad range of downstream applications. Though there is a big convergence in terms of architecture, most pretrained models are typically still developed for specific tasks or modalities. In this work, we propose to use language models as a general-purpose interface to various foundation models. A collection of pretrained encoders perceive diverse modalities (such as vision, and language), and they dock with a language model that plays the role of a universal task layer. We propose a semi-causal language modeling objective to jointly pretrain the interface and the modular encoders. We subsume the advantages and capabilities from both causal and non-causal modeling, thereby combining the best of two worlds. Specifically, the proposed method not only inherits the capabilities of in-context learning and open-ended generation from causal language modeling, but also is conducive to finetuning because of the bidirectional encoders. More importantly, our approach seamlessly unlocks the combinations of the above capabilities, e.g., enabling in-context learning or instruction following with finetuned encoders. Experimental results across various language-only and vision-language benchmarks show that our model outperforms or is competitive with specialized models on finetuning, zero-shot generalization, and few-shot learning.
VL-BEiT: Generative Vision-Language Pretraining
Jun 02, 2022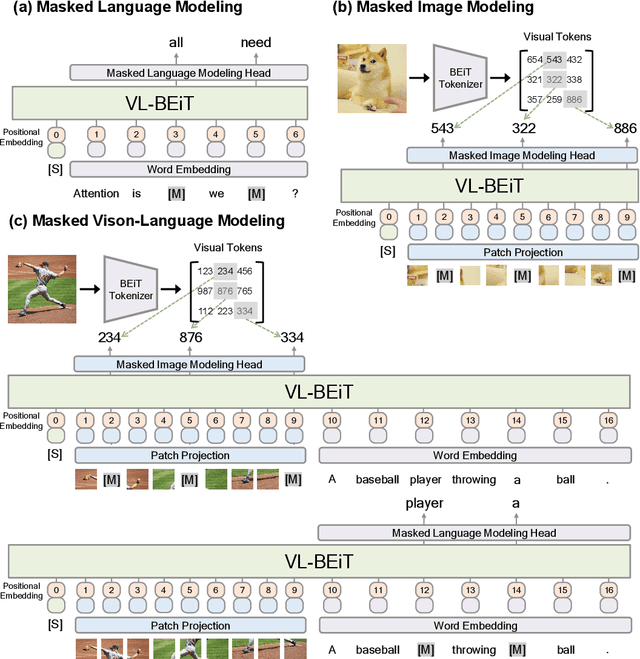
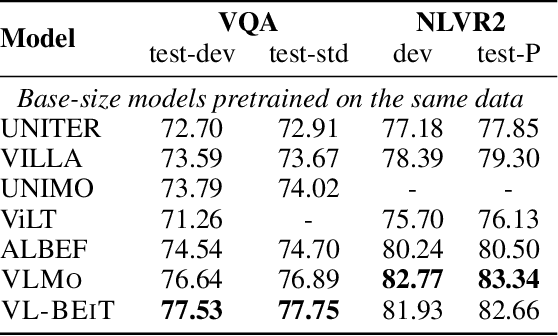
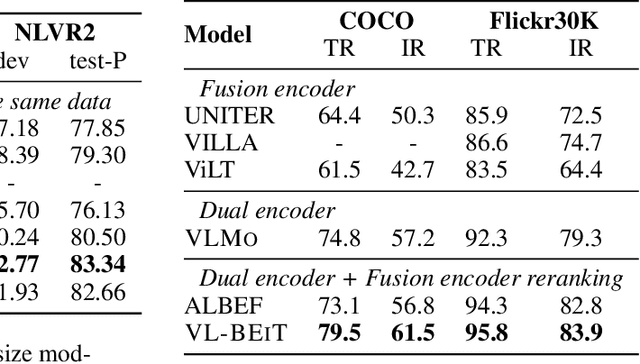
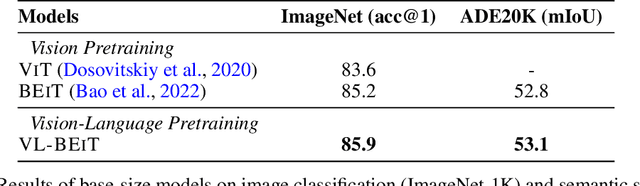
We introduce a vision-language foundation model called VL-BEiT, which is a bidirectional multimodal Transformer learned by generative pretraining. Our minimalist solution conducts masked prediction on both monomodal and multimodal data with a shared Transformer. Specifically, we perform masked vision-language modeling on image-text pairs, masked language modeling on texts, and masked image modeling on images. VL-BEiT is learned from scratch with one unified pretraining task, one shared backbone, and one-stage training. Our method is conceptually simple and empirically effective. Experimental results show that VL-BEiT obtains strong results on various vision-language benchmarks, such as visual question answering, visual reasoning, and image-text retrieval. Moreover, our method learns transferable visual features, achieving competitive performance on image classification, and semantic segmentation.