 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised 3D Object Detection with Proficient Teachers
Jul 26, 2022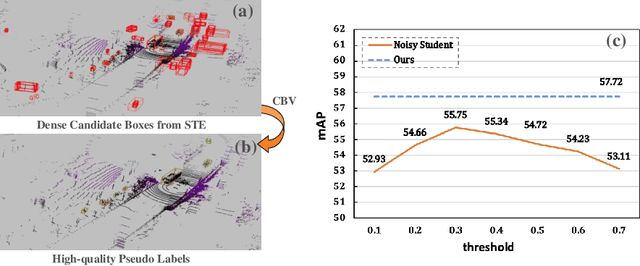

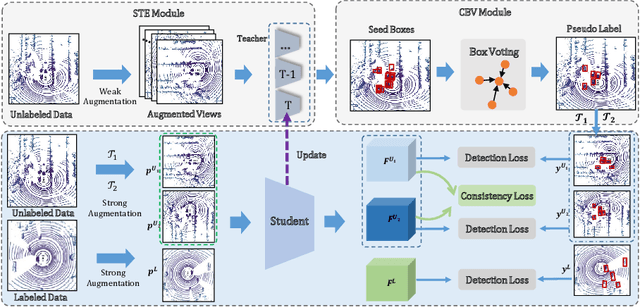

Dominated point cloud-based 3D object detectors in autonomous driving scenarios rely heavily on the huge amount of accurately labeled samples, however, 3D annotation in the point cloud is extremely tedious, expensive and time-consuming. To reduce the dependence on large supervision, semi-supervised learning (SSL) based approaches have been proposed. The Pseudo-Labeling methodology is commonly used for SSL frameworks, however, the low-quality predictions from the teacher model have seriously limited its performance. In this work, we propose a new Pseudo-Labeling framework for semi-supervised 3D object detection, by enhancing the teacher model to a proficient one with several necessary designs. First, to improve the recall of pseudo labels, a Spatialtemporal Ensemble (STE) module is proposed to generate sufficient seed boxes. Second, to improve the precision of recalled boxes, a Clusteringbased Box Voting (CBV) module is designed to get aggregated votes from the clustered seed boxes. This also eliminates the necessity of sophisticated thresholds to select pseudo labels. Furthermore, to reduce the negative influence of wrongly pseudo-labeled samples during the training, a soft supervision signal is proposed by considering Box-wise Contrastive Learning (BCL). The effectiveness of our model is verified on both ONCE and Waymo datasets. For example, on ONCE, our approach significantly improves the baseline by 9.51 mAP. Moreover, with half annotations, our model outperforms the oracle model with full annotations on Waymo.
ProposalContrast: Unsupervised Pre-training for LiDAR-based 3D Object Detection
Jul 26, 2022
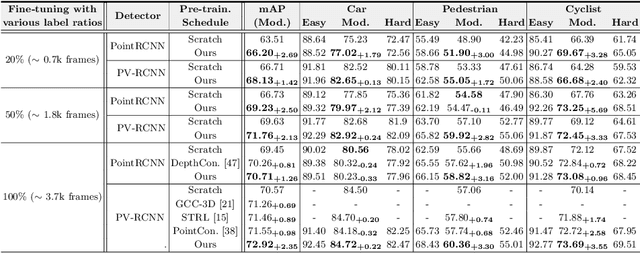
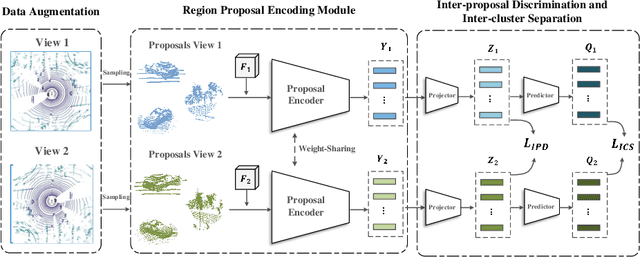
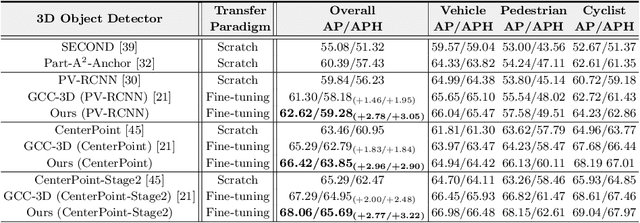
Existing approaches for unsupervised point cloud pre-training are constrained to either scene-level or point/voxel-level instance discrimination. Scene-level methods tend to lose local details that are crucial for recognizing the road objects, while point/voxel-level methods inherently suffer from limited receptive field that is incapable of perceiving large objects or context environments. Considering region-level representations are more suitable for 3D object detection, we devise a new unsupervised point cloud pre-training framework, called ProposalContrast, that learns robust 3D representations by contrasting region proposals. Specifically, with an exhaustive set of region proposals sampled from each point cloud, geometric point relations within each proposal are modeled for creating expressive proposal representations. To better accommodate 3D detection properties, ProposalContrast optimizes with both inter-cluster and inter-proposal separation, i.e., sharpening the discriminativeness of proposal representations across semantic classes and object instances. The generalizability and transferability of ProposalContrast are verified on various 3D detectors (i.e., PV-RCNN, CenterPoint, PointPillars and PointRCNN) and datasets (i.e., KITTI, Waymo and ONCE).
Towards Interpretable Video Super-Resolution via Alternating Optimization
Jul 21, 2022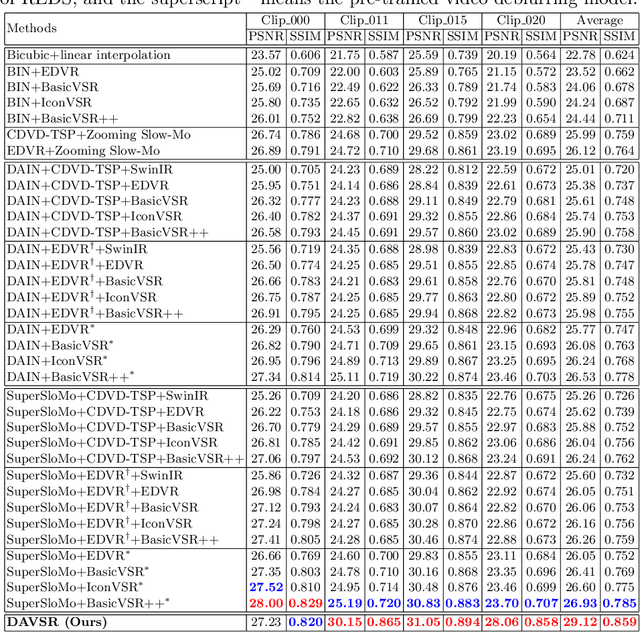
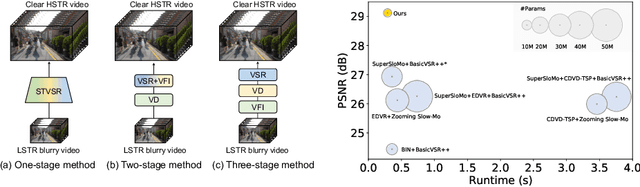
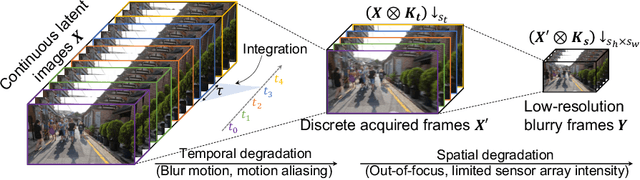
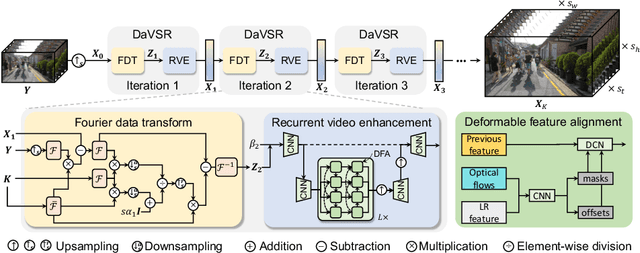
In this paper, we study a practical space-time video super-resolution (STVSR) problem which aims at generating a high-framerate high-resolution sharp video from a low-framerate low-resolution blurry video. Such problem often occurs when recording a fast dynamic event with a low-framerate and low-resolution camera, and the captured video would suffer from three typical issues: i) motion blur occurs due to object/camera motions during exposure time; ii) motion aliasing is unavoidable when the event temporal frequency exceeds the Nyquist limit of temporal sampling; iii) high-frequency details are lost because of the low spatial sampling rate. These issues can be alleviated by a cascade of three separate sub-tasks, including video deblurring, frame interpolation, and super-resolution, which, however, would fail to capture the spatial and temporal correlations among video sequences. To address this, we propose an interpretable STVSR framework by leveraging both model-based and learning-based methods. Specifically, we formulate STVSR as a joint video deblurring, frame interpolation, and super-resolution problem, and solve it as two sub-problems in an alternate way. For the first sub-problem, we derive an interpretable analytical solution and use it as a Fourier data transform layer. Then, we propose a recurrent video enhancement layer for the second sub-problem to further recover high-frequency details. Extensive experiments demonstrate the superiority of our method in terms of quantitative metrics and visual quality.
Target-Driven Structured Transformer Planner for Vision-Language Navigation
Jul 19, 2022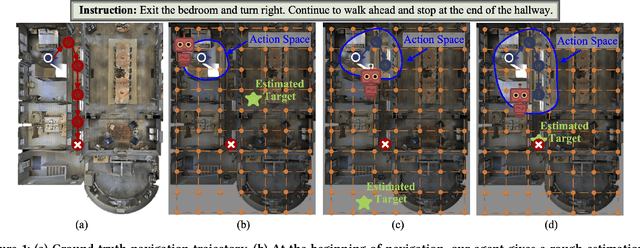
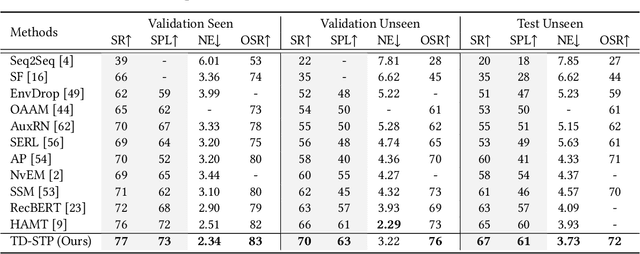

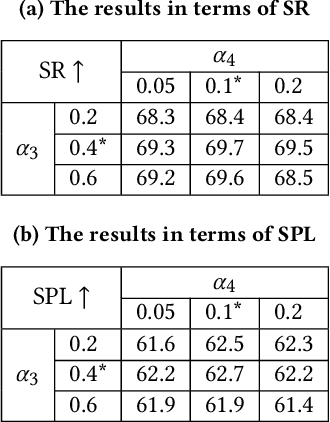
Vision-language navigation is the task of directing an embodied agent to navigate in 3D scenes with natural language instructions. For the agent, inferring the long-term navigation target from visual-linguistic clues is crucial for reliable path planning, which, however, has rarely been studied before in literature. In this article, we propose a Target-Driven Structured Transformer Planner (TD-STP) for long-horizon goal-guided and room layout-aware navigation. Specifically, we devise an Imaginary Scene Tokenization mechanism for explicit estimation of the long-term target (even located in unexplored environments). In addition, we design a Structured Transformer Planner which elegantly incorporates the explored room layout into a neural attention architecture for structured and global planning. Experimental results demonstrate that our TD-STP substantially improves previous best methods' success rate by 2% and 5% on the test set of R2R and REVERIE benchmarks, respectively. Our code is available at https://github.com/YushengZhao/TD-STP .
Rethinking Semantic Segmentation: A Prototype View
Apr 04, 2022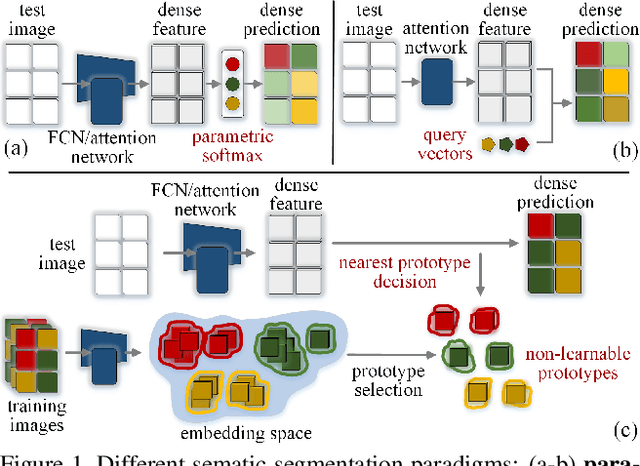
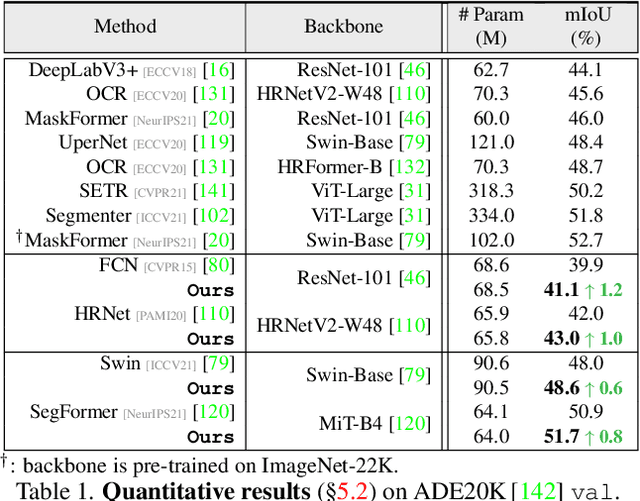
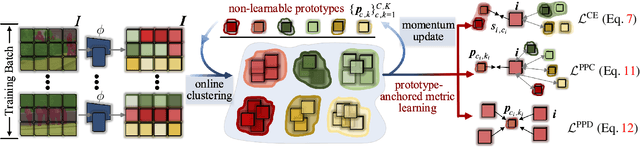
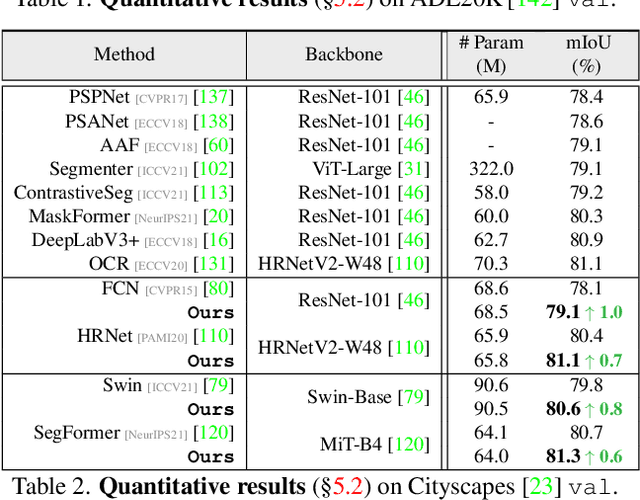
Prevalent semantic segmentation solutions, despite their different network designs (FCN based or attention based) and mask decoding strategies (parametric softmax based or pixel-query based), can be placed in one category, by considering the softmax weights or query vectors as learnable class prototypes. In light of this prototype view, this study uncovers several limitations of such parametric segmentation regime, and proposes a nonparametric alternative based on non-learnable prototypes. Instead of prior methods learning a single weight/query vector for each class in a fully parametric manner, our model represents each class as a set of non-learnable prototypes, relying solely on the mean features of several training pixels within that class. The dense prediction is thus achieved by nonparametric nearest prototype retrieving. This allows our model to directly shape the pixel embedding space, by optimizing the arrangement between embedded pixels and anchored prototypes. It is able to handle arbitrary number of classes with a constant amount of learnable parameters. We empirically show that, with FCN based and attention based segmentation models (i.e., HRNet, Swin, SegFormer) and backbones (i.e., ResNet, HRNet, Swin, MiT), our nonparametric framework yields compelling results over several datasets (i.e., ADE20K, Cityscapes, COCO-Stuff), and performs well in the large-vocabulary situation. We expect this work will provoke a rethink of the current de facto semantic segmentation model design.
Counterfactual Cycle-Consistent Learning for Instruction Following and Generation in Vision-Language Navigation
Mar 30, 2022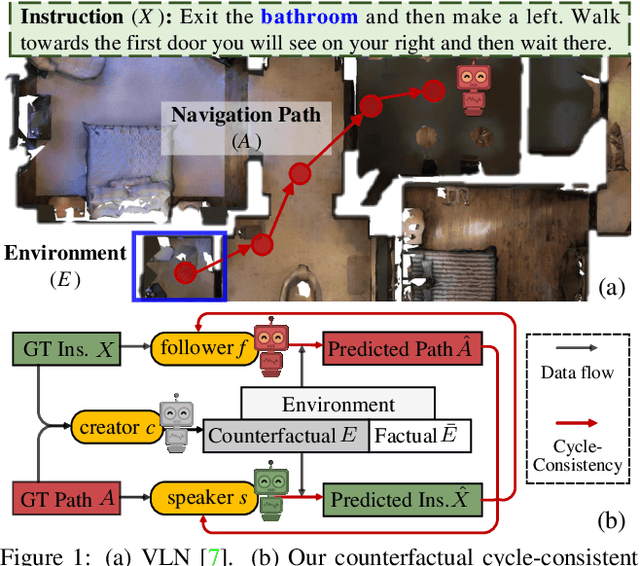
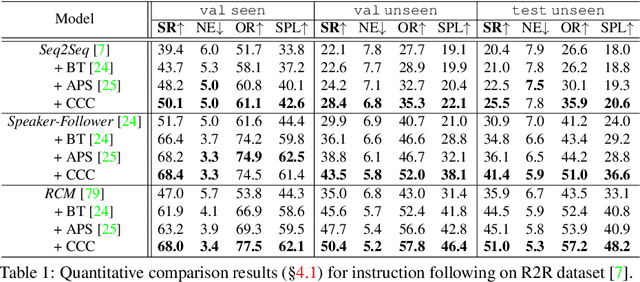

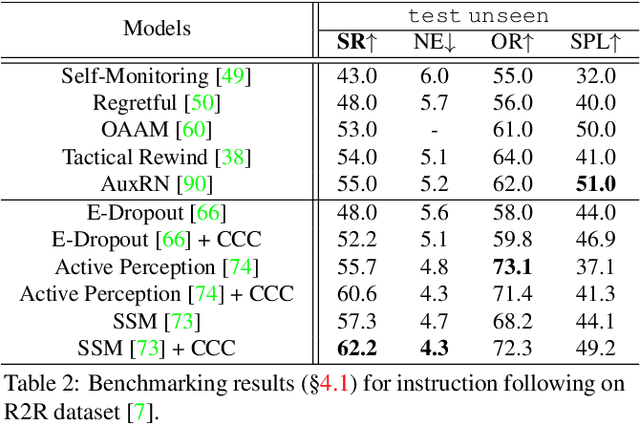
Since the rise of vision-language navigation (VLN), great progress has been made in instruction following -- building a follower to navigate environments under the guidance of instructions. However, far less attention has been paid to the inverse task: instruction generation -- learning a speaker~to generate grounded descriptions for navigation routes. Existing VLN methods train a speaker independently and often treat it as a data augmentation tool to strengthen the follower while ignoring rich cross-task relations. Here we describe an approach that learns the two tasks simultaneously and exploits their intrinsic correlations to boost the training of each: the follower judges whether the speaker-created instruction explains the original navigation route correctly, and vice versa. Without the need of aligned instruction-path pairs, such cycle-consistent learning scheme is complementary to task-specific training targets defined on labeled data, and can also be applied over unlabeled paths (sampled without paired instructions). Another agent, called~creator is added to generate counterfactual environments. It greatly changes current scenes yet leaves novel items -- which are vital for the execution of original instructions -- unchanged. Thus more informative training scenes are synthesized and the three agents compose a powerful VLN learning system. Extensive experiments on a standard benchmark show that our approach improves the performance of various follower models and produces accurate navigation instructions.
Deep Hierarchical Semantic Segmentation
Mar 29, 2022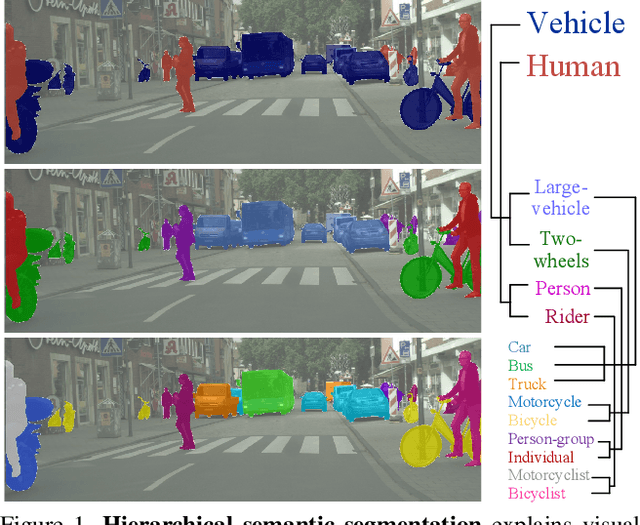
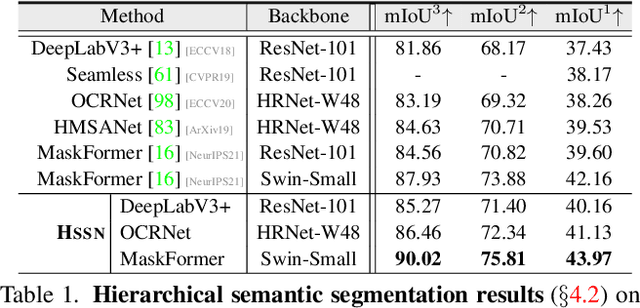
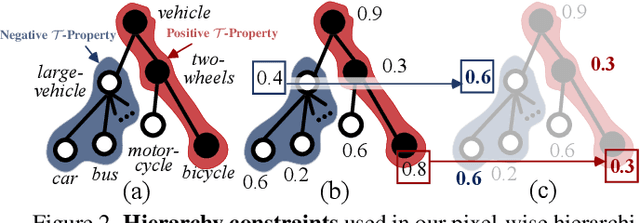
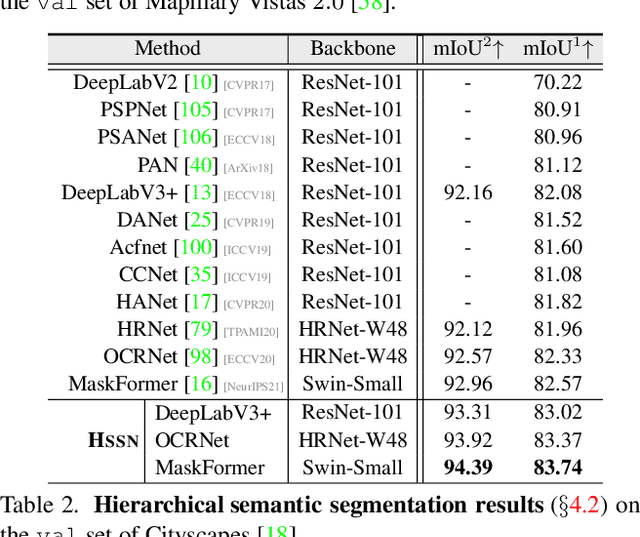
Humans are able to recognize structured relations in observation, allowing us to decompose complex scenes into simpler parts and abstract the visual world in multiple levels. However, such hierarchical reasoning ability of human perception remains largely unexplored in current literature of semantic segmentation. Existing work is often aware of flatten labels and predicts target classes exclusively for each pixel. In this paper, we instead address hierarchical semantic segmentation (HSS), which aims at structured, pixel-wise description of visual observation in terms of a class hierarchy. We devise HSSN, a general HSS framework that tackles two critical issues in this task: i) how to efficiently adapt existing hierarchy-agnostic segmentation networks to the HSS setting, and ii) how to leverage the hierarchy information to regularize HSS network learning. To address i), HSSN directly casts HSS as a pixel-wise multi-label classification task, only bringing minimal architecture change to current segmentation models. To solve ii), HSSN first explores inherent properties of the hierarchy as a training objective, which enforces segmentation predictions to obey the hierarchy structure. Further, with hierarchy-induced margin constraints, HSSN reshapes the pixel embedding space, so as to generate well-structured pixel representations and improve segmentation eventually. We conduct experiments on four semantic segmentation datasets (i.e., Mapillary Vistas 2.0, Cityscapes, LIP, and PASCAL-Person-Part), with different class hierarchies, segmentation network architectures and backbones, showing the generalization and superiority of HSSN.
Locality-Aware Inter-and Intra-Video Reconstruction for Self-Supervised Correspondence Learning
Mar 29, 2022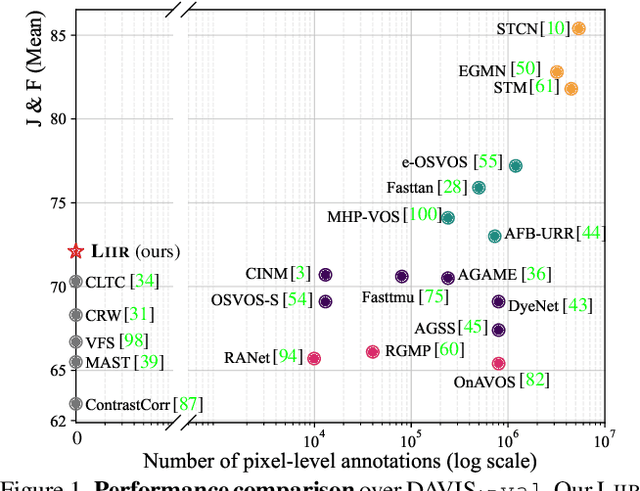
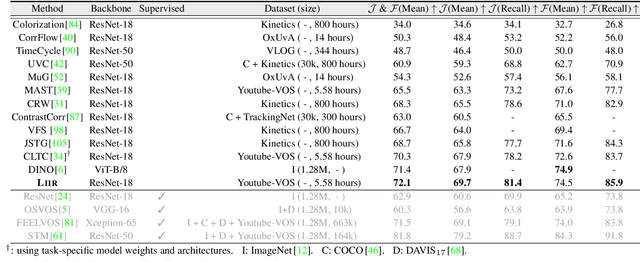
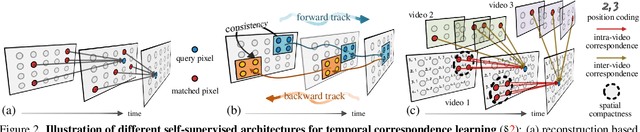
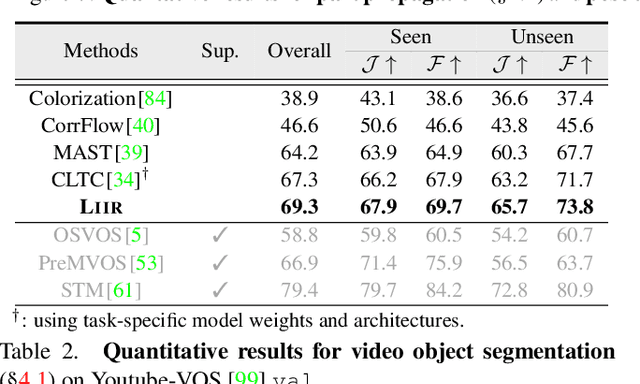
Our target is to learn visual correspondence from unlabeled videos. We develop LIIR, a locality-aware inter-and intra-video reconstruction framework that fills in three missing pieces, i.e., instance discrimination, location awareness, and spatial compactness, of self-supervised correspondence learning puzzle. First, instead of most existing efforts focusing on intra-video self-supervision only, we exploit cross video affinities as extra negative samples within a unified, inter-and intra-video reconstruction scheme. This enables instance discriminative representation learning by contrasting desired intra-video pixel association against negative inter-video correspondence. Second, we merge position information into correspondence matching, and design a position shifting strategy to remove the side-effect of position encoding during inter-video affinity computation, making our LIIR location-sensitive. Third, to make full use of the spatial continuity nature of video data, we impose a compactness-based constraint on correspondence matching, yielding more sparse and reliable solutions. The learned representation surpasses self-supervised state-of-the-arts on label propagation tasks including objects, semantic parts, and keypoints.
Visual Abductive Reasoning
Mar 26, 2022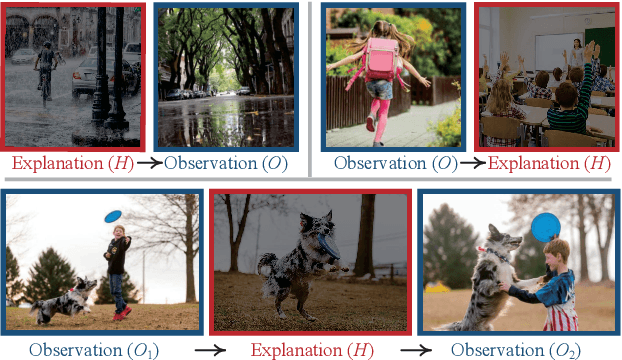
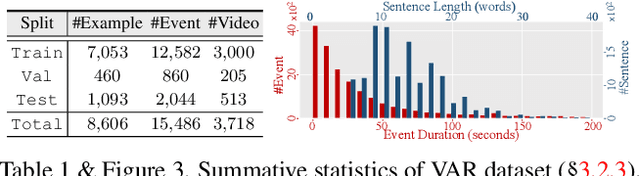
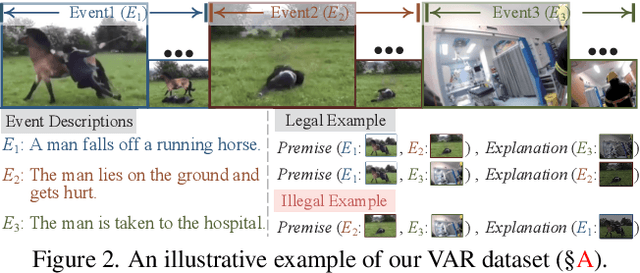
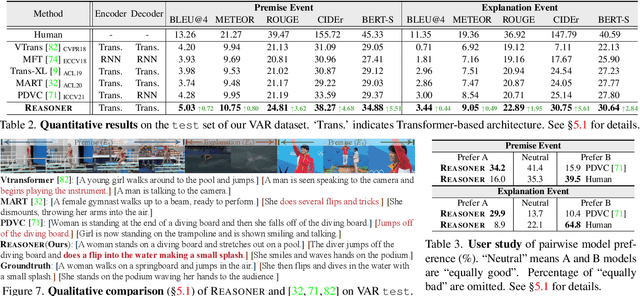
Abductive reasoning seeks the likeliest possible explanation for partial observations. Although abduction is frequently employed in human daily reasoning, it is rarely explored in computer vision literature. In this paper, we propose a new task and dataset, Visual Abductive Reasoning (VAR), for examining abductive reasoning ability of machine intelligence in everyday visual situations. Given an incomplete set of visual events, AI systems are required to not only describe what is observed, but also infer the hypothesis that can best explain the visual premise. Based on our large-scale VAR dataset, we devise a strong baseline model, Reasoner (causal-and-cascaded reasoning Transformer). First, to capture the causal structure of the observations, a contextualized directional position embedding strategy is adopted in the encoder, that yields discriminative representations for the premise and hypothesis. Then, multiple decoders are cascaded to generate and progressively refine the premise and hypothesis sentences. The prediction scores of the sentences are used to guide cross-sentence information flow in the cascaded reasoning procedure. Our VAR benchmarking results show that Reasoner surpasses many famous video-language models, while still being far behind human performance. This work is expected to foster future efforts in the reasoning-beyond-observation paradigm.
Local-Global Context Aware Transformer for Language-Guided Video Segmentation
Mar 18, 2022



We explore the task of language-guided video segmentation (LVS). Previous algorithms mostly adopt 3D CNNs to learn video representation, struggling to capture long-term context and easily suffering from visual-linguistic misalignment. In light of this, we present Locater (local-global context aware Transformer), which augments the Transformer architecture with a finite memory so as to query the entire video with the language expression in an efficient manner. The memory is designed to involve two components -- one for persistently preserving global video content, and one for dynamically gathering local temporal context and segmentation history. Based on the memorized local-global context and the particular content of each frame, Locater holistically and flexibly comprehends the expression as an adaptive query vector for each frame. The vector is used to query the corresponding frame for mask generation. The memory also allows Locater to process videos with linear time complexity and constant size memory, while Transformer-style self-attention computation scales quadratically with sequence length. To thoroughly examine the visual grounding capability of LVS models, we contribute a new LVS dataset, A2D-S+, which is built upon A2D-S dataset but poses increased challenges in disambiguating among similar objects. Experiments on three LVS datasets and our A2D-S+ show that Locater outperforms previous state-of-the-arts. Further, our Locater based solution achieved the 1st place in the Referring Video Object Segmentation Track of the 3rd Large-scale Video Object Segmentation Challenge. Our code and dataset are available at: https://github.com/leonnnop/Locater