 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Tactile Simulation Towards Tactile-Visual Perception
Aug 12, 2021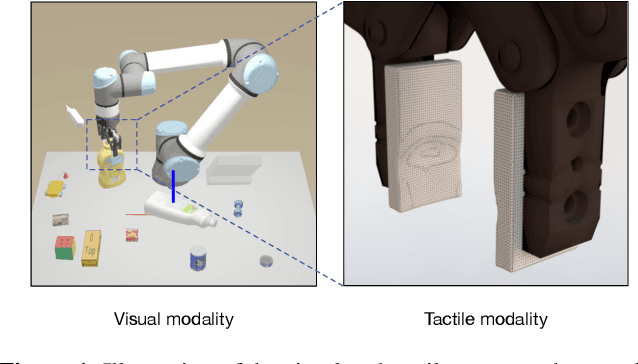
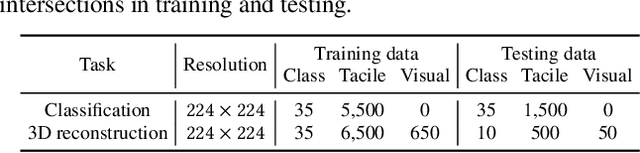


Tactile sensing plays an important role in robotic perception and manipulation tasks. To overcome the real-world limitations of data collection, simulating tactile response in a virtual environment comes as a desirable direction of robotic research. In this paper, we propose Elastic Interaction of Particles (EIP) for tactile simulation. Most existing works model the tactile sensor as a rigid multi-body, which is incapable of reflecting the elastic property of the tactile sensor as well as characterizing the fine-grained physical interaction between the two objects. By contrast, EIP models the tactile sensor as a group of coordinated particles, and the elastic property is applied to regulate the deformation of particles during contact. With the tactile simulation by EIP, we further propose a tactile-visual perception network that enables information fusion between tactile data and visual images. The perception network is based on a global-to-local fusion mechanism where multi-scale tactile features are aggregated to the corresponding local region of the visual modality with the guidance of tactile positions and directions. The fusion method exhibits superiority regarding the 3D geometric reconstruction task.
PI-GNN: A Novel Perspective on Semi-Supervised Node Classification against Noisy Labels
Jun 14, 2021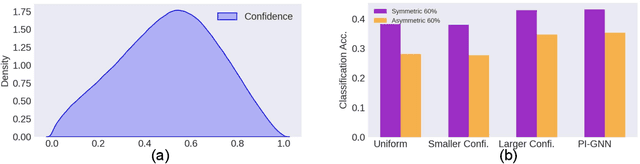
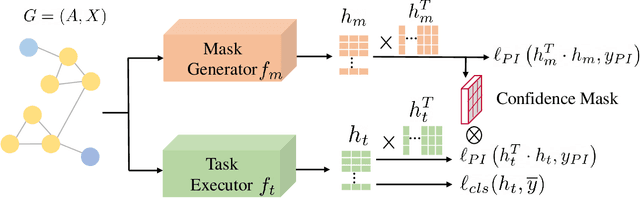
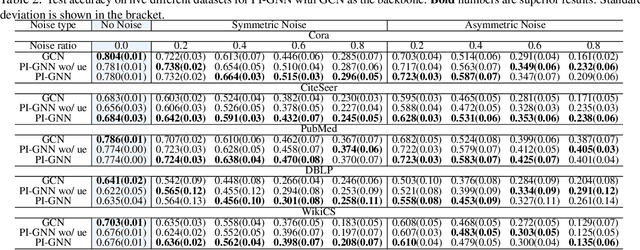
Semi-supervised node classification, as a fundamental problem in graph learning, leverages unlabeled nodes along with a small portion of labeled nodes for training. Existing methods rely heavily on high-quality labels, which, however, are expensive to obtain in real-world applications since certain noises are inevitably involved during the labeling process. It hence poses an unavoidable challenge for the learning algorithm to generalize well. In this paper, we propose a novel robust learning objective dubbed pairwise interactions (PI) for the model, such as Graph Neural Network (GNN) to combat noisy labels. Unlike classic robust training approaches that operate on the pointwise interactions between node and class label pairs, PI explicitly forces the embeddings for node pairs that hold a positive PI label to be close to each other, which can be applied to both labeled and unlabeled nodes. We design several instantiations for PI labels based on the graph structure and the node class labels, and further propose a new uncertainty-aware training technique to mitigate the negative effect of the sub-optimal PI labels. Extensive experiments on different datasets and GNN architectures demonstrate the effectiveness of PI, yielding a promising improvement over the state-of-the-art methods.
Adversarial Option-Aware Hierarchical Imitation Learning
Jun 11, 2021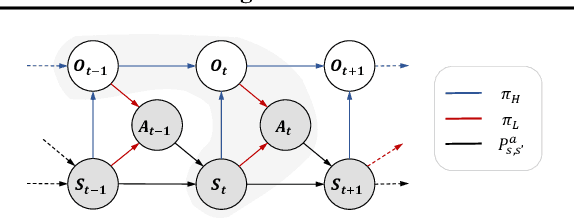
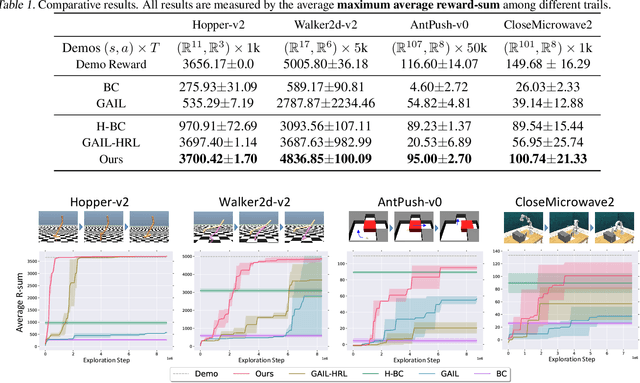
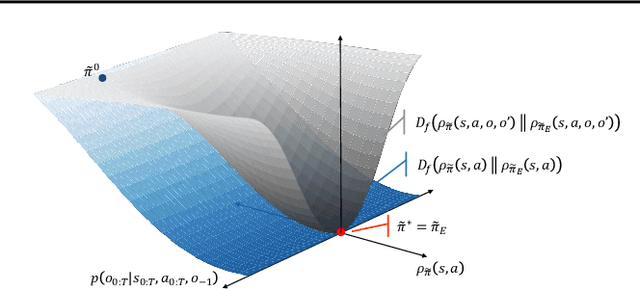
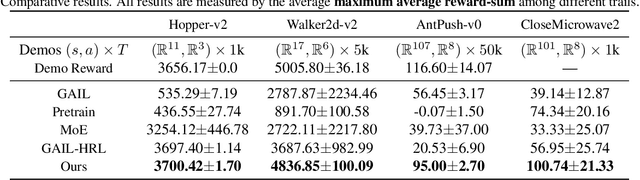
It has been a challenge to learning skills for an agent from long-horizon unannotated demonstrations. Existing approaches like Hierarchical Imitation Learning(HIL) are prone to compounding errors or suboptimal solutions. In this paper, we propose Option-GAIL, a novel method to learn skills at long horizon. The key idea of Option-GAIL is modeling the task hierarchy by options and train the policy via generative adversarial optimization. In particular, we propose an Expectation-Maximization(EM)-style algorithm: an E-step that samples the options of expert conditioned on the current learned policy, and an M-step that updates the low- and high-level policies of agent simultaneously to minimize the newly proposed option-occupancy measurement between the expert and the agent. We theoretically prove the convergence of the proposed algorithm. Experiments show that Option-GAIL outperforms other counterparts consistently across a variety of tasks.
Adversarial Attack Framework on Graph Embedding Models with Limited Knowledge
May 26, 2021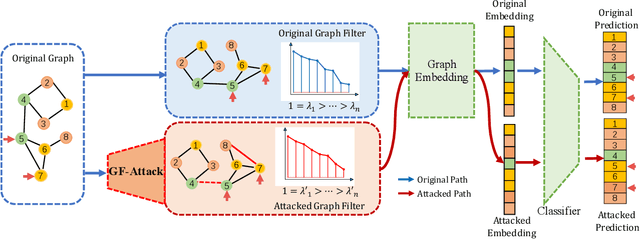



With the success of the graph embedding model in both academic and industry areas, the robustness of graph embedding against adversarial attack inevitably becomes a crucial problem in graph learning. Existing works usually perform the attack in a white-box fashion: they need to access the predictions/labels to construct their adversarial loss. However, the inaccessibility of predictions/labels makes the white-box attack impractical to a real graph learning system. This paper promotes current frameworks in a more general and flexible sense -- we demand to attack various kinds of graph embedding models with black-box driven. We investigate the theoretical connections between graph signal processing and graph embedding models and formulate the graph embedding model as a general graph signal process with a corresponding graph filter. Therefore, we design a generalized adversarial attacker: GF-Attack. Without accessing any labels and model predictions, GF-Attack can perform the attack directly on the graph filter in a black-box fashion. We further prove that GF-Attack can perform an effective attack without knowing the number of layers of graph embedding models. To validate the generalization of GF-Attack, we construct the attacker on four popular graph embedding models. Extensive experiments validate the effectiveness of GF-Attack on several benchmark datasets.
Elastic Interaction of Particles for Robotic Tactile Simulation
Nov 23, 2020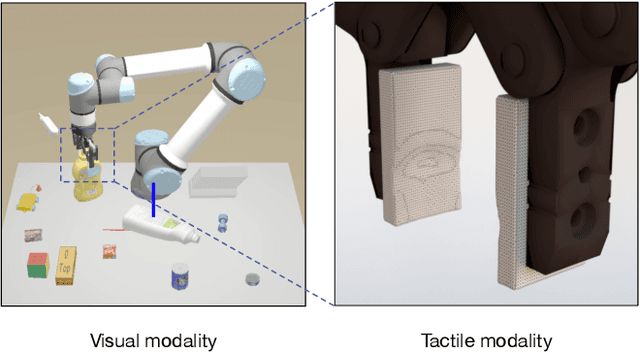
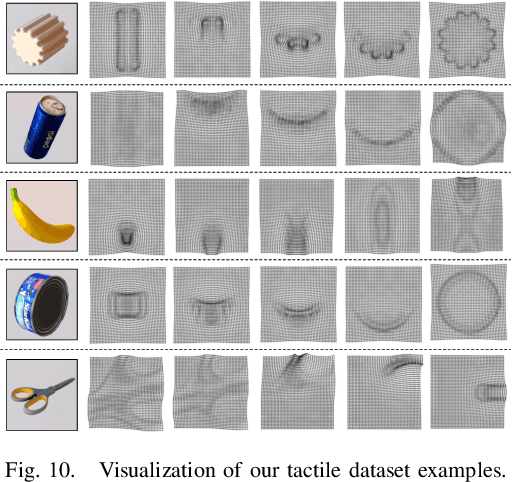


Tactile sensing plays an important role in robotic perception and manipulation. To overcome the real-world limitations of data collection, simulating tactile response in virtual environment comes as a desire direction of robotic research. Most existing works model the tactile sensor as a rigid multi-body, which is incapable of reflecting the elastic property of the tactile sensor as well as characterizing the fine-grained physical interaction between two objects. In this paper, we propose Elastic Interaction of Particles (EIP), a novel framework for tactile emulation. At its core, EIP models the tactile sensor as a group of coordinated particles, and the elastic theory is applied to regulate the deformation of particles during the contact process. The implementation of EIP is conducted from scratch, without resorting to any existing physics engine. Experiments to verify the effectiveness of our method have been carried out on two applications: robotic perception with tactile data and 3D geometric reconstruction by tactile-visual fusion. It is possible to open up a new vein for robotic tactile simulation, and contribute to various downstream robotic tasks.
Deep Multimodal Fusion by Channel Exchanging
Nov 10, 2020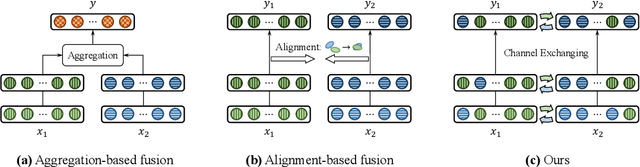
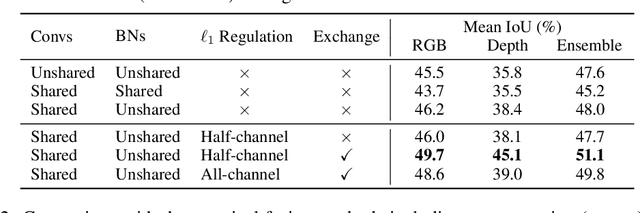
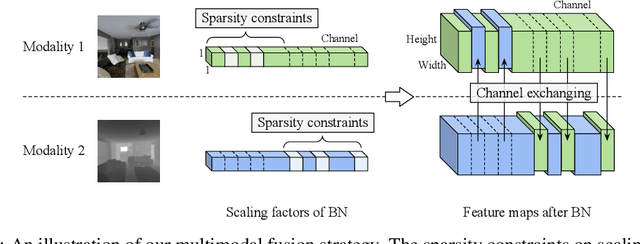
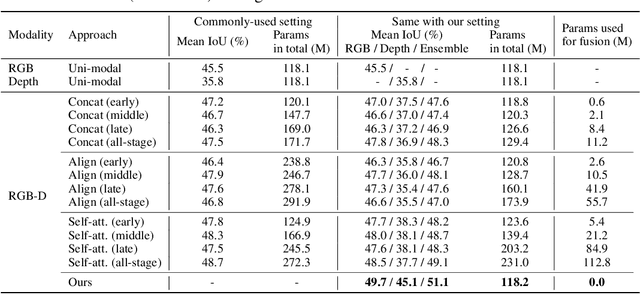
Deep multimodal fusion by using multiple sources of data for classification or regression has exhibited a clear advantage over the unimodal counterpart on various applications. Yet, current methods including aggregation-based and alignment-based fusion are still inadequate in balancing the trade-off between inter-modal fusion and intra-modal processing, incurring a bottleneck of performance improvement. To this end, this paper proposes Channel-Exchanging-Network (CEN), a parameter-free multimodal fusion framework that dynamically exchanges channels between sub-networks of different modalities. Specifically, the channel exchanging process is self-guided by individual channel importance that is measured by the magnitude of Batch-Normalization (BN) scaling factor during training. The validity of such exchanging process is also guaranteed by sharing convolutional filters yet keeping separate BN layers across modalities, which, as an add-on benefit, allows our multimodal architecture to be almost as compact as a unimodal network. Extensive experiments on semantic segmentation via RGB-D data and image translation through multi-domain input verify the effectiveness of our CEN compared to current state-of-the-art methods. Detailed ablation studies have also been carried out, which provably affirm the advantage of each component we propose. Our code is available at https://github.com/yikaiw/CEN.
Tackling Over-Smoothing for General Graph Convolutional Networks
Sep 08, 2020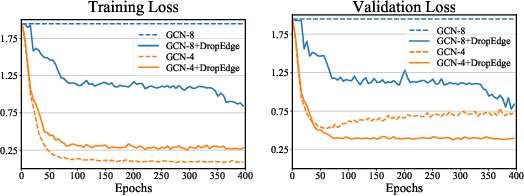

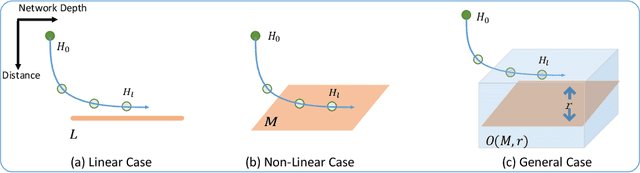
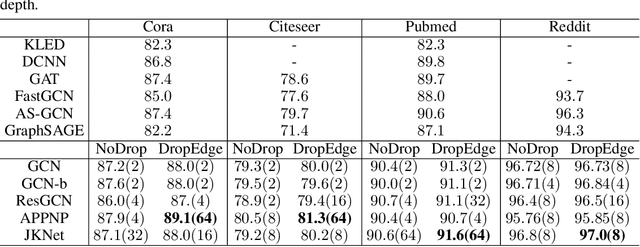
Increasing the depth of GCN, which is expected to permit more expressivity, is shown to incur performance detriment especially on node classification. The main cause of this lies in over-smoothing. The over-smoothing issue drives the output of GCN towards a space that contains limited distinguished information among nodes, leading to poor expressivity. Several works on refining the architecture of deep GCN have been proposed, but it is still unknown in theory whether or not these refinements are able to relieve over-smoothing. In this paper, we first theoretically analyze how general GCNs act with the increase in depth, including generic GCN, GCN with bias, ResGCN, and APPNP. We find that all these models are characterized by a universal process: all nodes converging to a cuboid. Upon this theorem, we propose DropEdge to alleviate over-smoothing by randomly removing a certain number of edges at each training epoch. Theoretically, DropEdge either reduces the convergence speed of over-smoothing or relieves the information loss caused by dimension collapse. Experimental evaluations on simulated dataset have visualized the difference in over-smoothing between different GCNs. Moreover, extensive experiments on several real benchmarks support that DropEdge consistently improves the performance on a variety of both shallow and deep GCNs.
Towards Purely Unsupervised Disentanglement of Appearance and Shape for Person Images Generation
Jul 30, 2020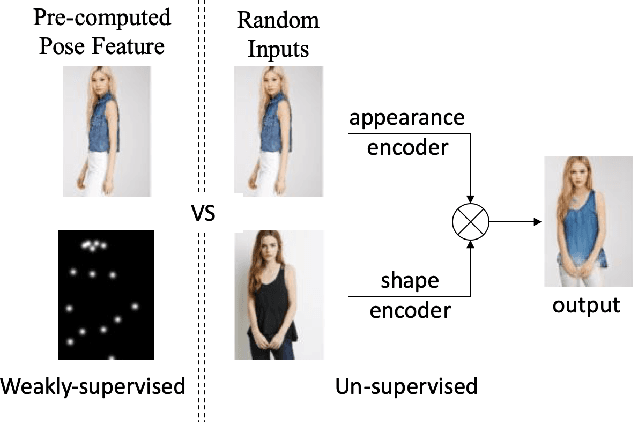
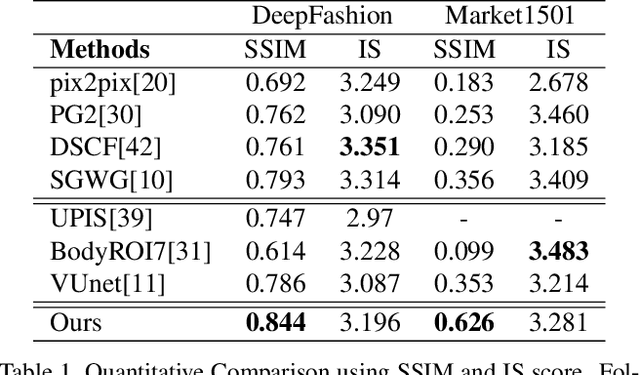
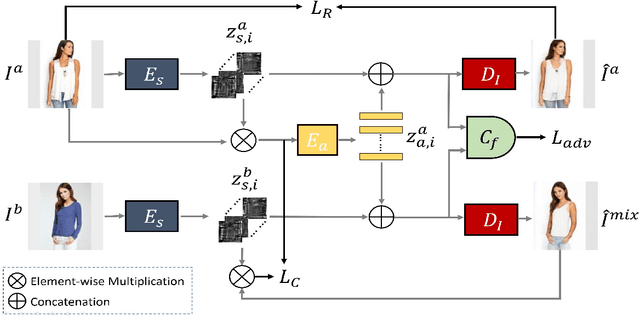

There have been a fairly of research interests in exploring the disentanglement of appearance and shape from human images. Most existing endeavours pursuit this goal by either using training images with annotations or regulating the training process with external clues such as human skeleton, body segmentation or cloth patches etc. In this paper, we aim to address this challenge in a more unsupervised manner---we do not require any annotation nor any external task-specific clues. To this end, we formulate an encoder-decoder-like network to extract both the shape and appearance features from input images at the same time, and train the parameters by three losses: feature adversarial loss, color consistency loss and reconstruction loss. The feature adversarial loss mainly impose little to none mutual information between the extracted shape and appearance features, while the color consistency loss is to encourage the invariance of person appearance conditioned on different shapes. More importantly, our unsupervised (Unsupervised learning has many interpretations in different tasks. To be clear, in this paper, we refer unsupervised learning as learning without task-specific human annotations, pairs or any form of weak supervision.) framework utilizes learned shape features as masks which are applied to the input itself in order to obtain clean appearance features. Without using fixed input human skeleton, our network better preserves the conditional human posture while requiring less supervision. Experimental results on DeepFashion and Market1501 demonstrate that the proposed method achieves clean disentanglement and is able to synthesis novel images of comparable quality with state-of-the-art weakly-supervised or even supervised methods.
Inverse Graph Identification: Can We Identify Node Labels Given Graph Labels?
Jul 12, 2020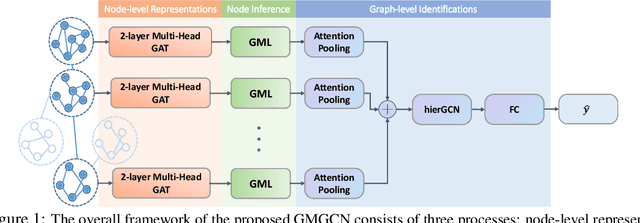
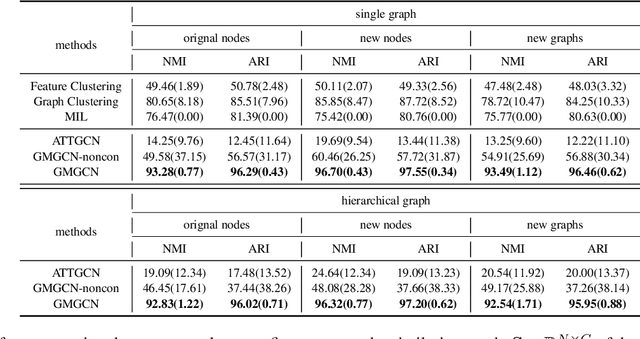
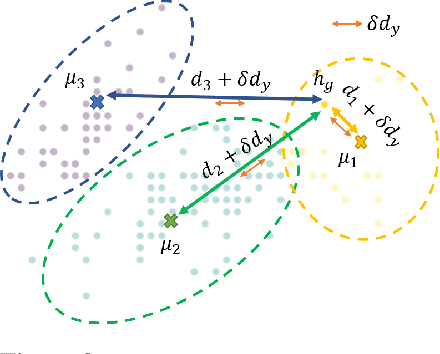
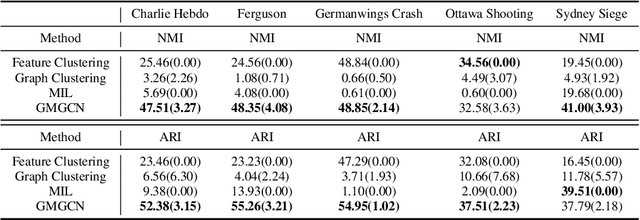
Graph Identification (GI) has long been researched in graph learning and is essential in certain applications (e.g. social community detection). Specifically, GI requires to predict the label/score of a target graph given its collection of node features and edge connections. While this task is common, more complex cases arise in practice---we are supposed to do the inverse thing by, for example, grouping similar users in a social network given the labels of different communities. This triggers an interesting thought: can we identify nodes given the labels of the graphs they belong to? Therefore, this paper defines a novel problem dubbed Inverse Graph Identification (IGI), as opposed to GI. Upon a formal discussion of the variants of IGI, we choose a particular case study of node clustering by making use of the graph labels and node features, with an assistance of a hierarchical graph that further characterizes the connections between different graphs. To address this task, we propose Gaussian Mixture Graph Convolutional Network (GMGCN), a simple yet effective method that makes the node-level message passing process using Graph Attention Network (GAT) under the protocol of GI and then infers the category of each node via a Gaussian Mixture Layer (GML). The training of GMGCN is further boosted by a proposed consensus loss to take advantage of the structure of the hierarchical graph. Extensive experiments are conducted to test the rationality of the formulation of IGI. We verify the superiority of the proposed method compared to other baselines on several benchmarks we have built up. We will release our codes along with the benchmark data to facilitate more research attention to the IGI problem.
GROVER: Self-supervised Message Passing Transformer on Large-scale Molecular Data
Jun 18, 2020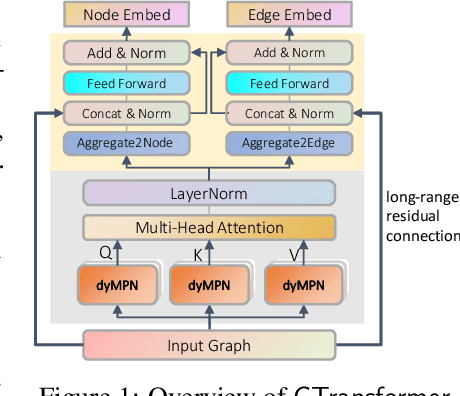
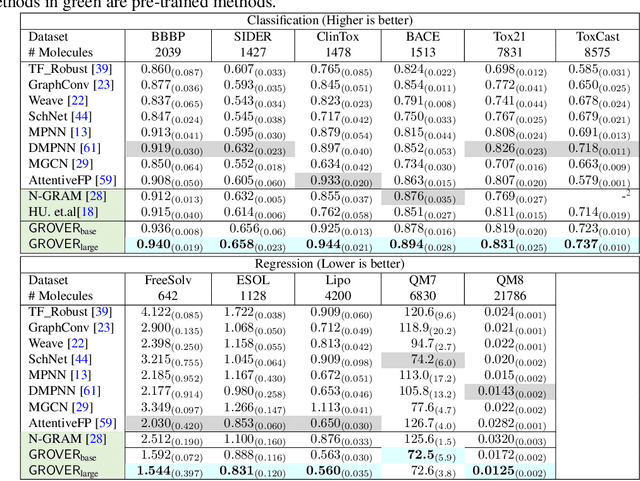
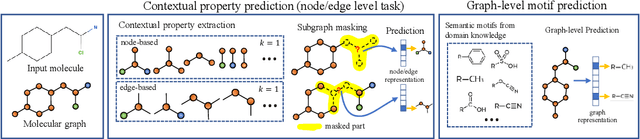
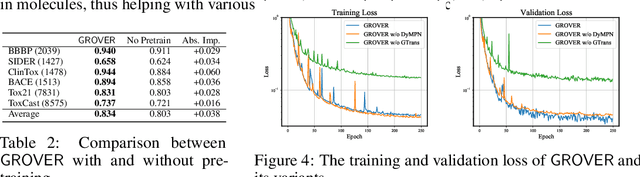
How to obtain informative representations of molecules is a crucial prerequisite in AI-driven drug design and discovery. Recent researches abstract molecules as graphs and employ Graph Neural Networks (GNNs) for task-specific and data-driven molecular representation learning. Nevertheless, two "dark clouds" impede the usage of GNNs in real scenarios: (1) insufficient labeled molecules for supervised training; (2) poor generalization capabilities to new-synthesized molecules. To address them both, we propose a novel molecular representation framework, GROVER, which stands for Graph Representation frOm self-superVised mEssage passing tRansformer. With carefully designed self-supervised tasks in node, edge and graph-level, GROVER can learn rich structural and semantic information of molecules from enormous unlabelled molecular data. Rather, to encode such complex information, GROVER integrates Message Passing Networks with the Transformer-style architecture to deliver a class of more expressive encoders of molecules. The flexibility of GROVER allows it to be trained efficiently on large-scale molecular dataset without requiring any supervision, thus being immunized to the two issues mentioned above. We pre-train GROVER with 100 million parameters on 10 million unlabelled molecules---the biggest GNN and the largest training dataset that we have ever met. We then leverage the pre-trained GROVER to downstream molecular property prediction tasks followed by task-specific fine-tuning, where we observe a huge improvement (more than 6% on average) over current state-of-the-art methods on 11 challenging benchmarks. The insights we gained are that well-designed self-supervision losses and largely-expressive pre-trained models enjoy the significant potential on performance boosting.