 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Token Fusion for Vision Transformers
Apr 19, 2022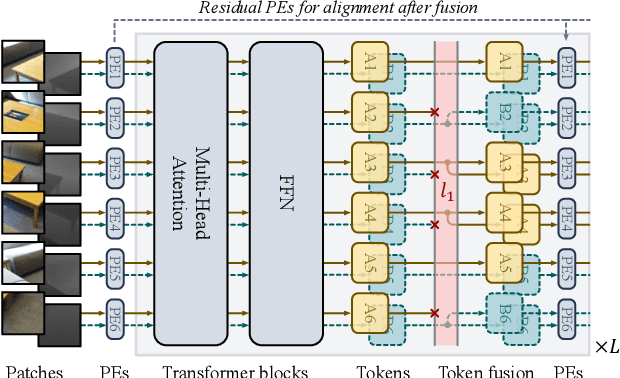
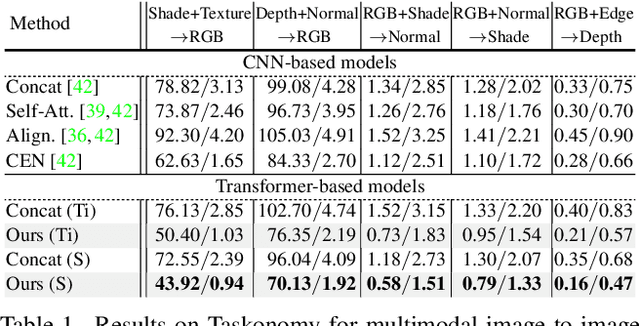
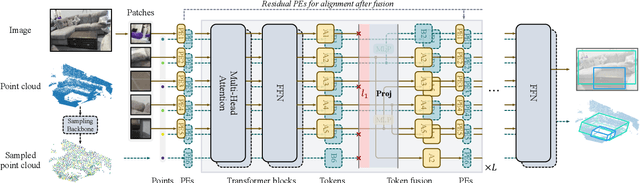
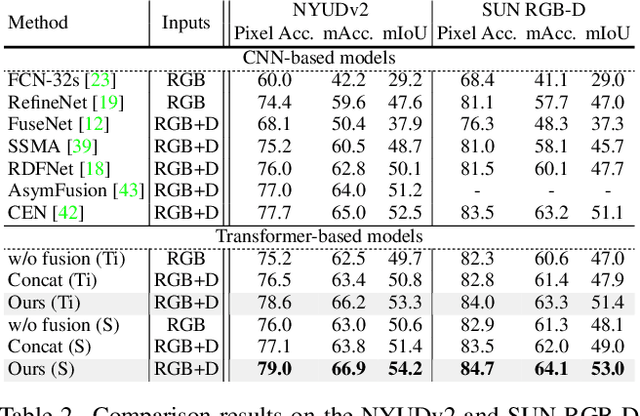
Many adaptations of transformers have emerged to address the single-modal vision tasks, where self-attention modules are stacked to handle input sources like images. Intuitively, feeding multiple modalities of data to vision transformers could improve the performance, yet the inner-modal attentive weights may also be diluted, which could thus undermine the final performance. In this paper, we propose a multimodal token fusion method (TokenFusion), tailored for transformer-based vision tasks. To effectively fuse multiple modalities, TokenFusion dynamically detects uninformative tokens and substitutes these tokens with projected and aggregated inter-modal features. Residual positional alignment is also adopted to enable explicit utilization of the inter-modal alignments after fusion. The design of TokenFusion allows the transformer to learn correlations among multimodal features, while the single-modal transformer architecture remains largely intact. Extensive experiments are conducted on a variety of homogeneous and heterogeneous modalities and demonstrate that TokenFusion surpasses state-of-the-art methods in three typical vision tasks: multimodal image-to-image translation, RGB-depth semantic segmentation, and 3D object detection with point cloud and images.
Smoothing Matters: Momentum Transformer for Domain Adaptive Semantic Segmentation
Mar 15, 2022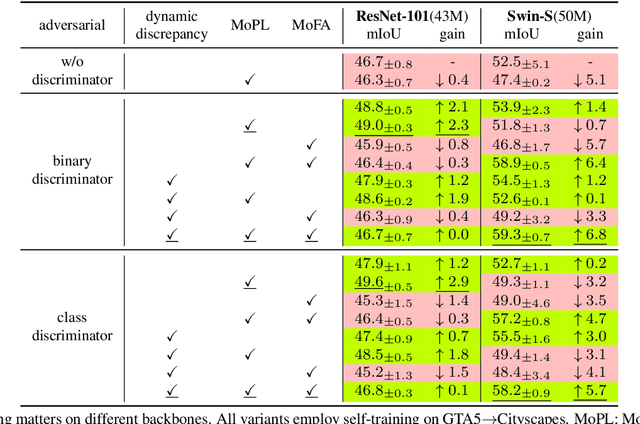
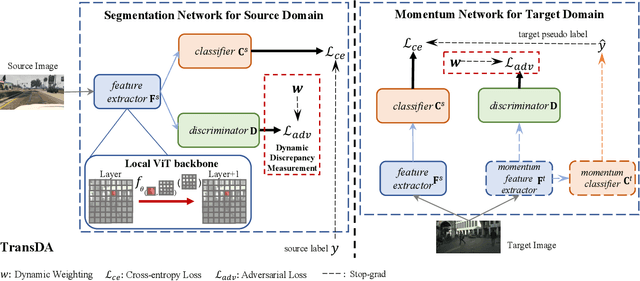

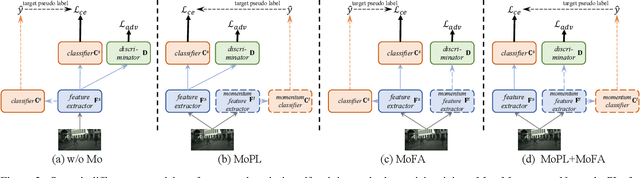
After the great success of Vision Transformer variants (ViTs) in computer vision, it has also demonstrated great potential in domain adaptive semantic segmentation. Unfortunately, straightforwardly applying local ViTs in domain adaptive semantic segmentation does not bring in expected improvement. We find that the pitfall of local ViTs is due to the severe high-frequency components generated during both the pseudo-label construction and features alignment for target domains. These high-frequency components make the training of local ViTs very unsmooth and hurt their transferability. In this paper, we introduce a low-pass filtering mechanism, momentum network, to smooth the learning dynamics of target domain features and pseudo labels. Furthermore, we propose a dynamic of discrepancy measurement to align the distributions in the source and target domains via dynamic weights to evaluate the importance of the samples. After tackling the above issues, extensive experiments on sim2real benchmarks show that the proposed method outperforms the state-of-the-art methods. Our codes are available at https://github.com/alpc91/TransDA
Equivariant Graph Mechanics Networks with Constraints
Mar 12, 2022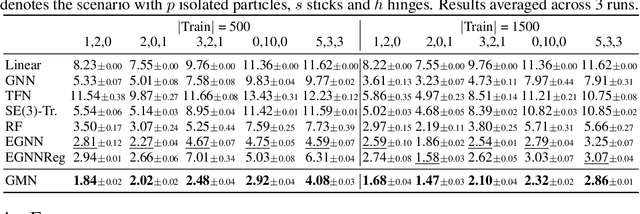
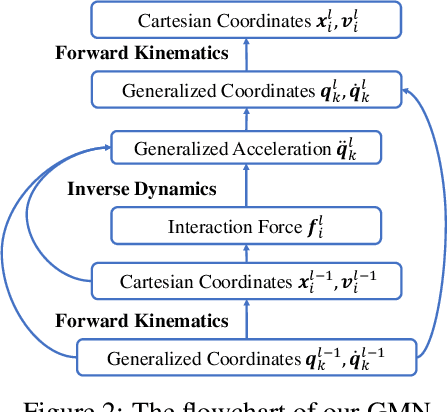
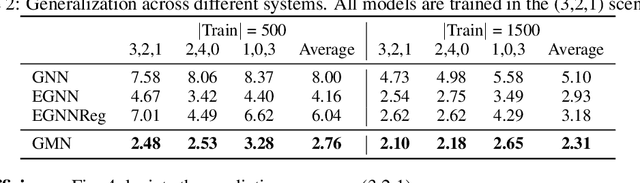
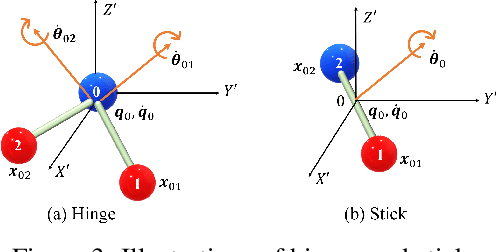
Learning to reason about relations and dynamics over multiple interacting objects is a challenging topic in machine learning. The challenges mainly stem from that the interacting systems are exponentially-compositional, symmetrical, and commonly geometrically-constrained. Current methods, particularly the ones based on equivariant Graph Neural Networks (GNNs), have targeted on the first two challenges but remain immature for constrained systems. In this paper, we propose Graph Mechanics Network (GMN) which is combinatorially efficient, equivariant and constraint-aware. The core of GMN is that it represents, by generalized coordinates, the forward kinematics information (positions and velocities) of a structural object. In this manner, the geometrical constraints are implicitly and naturally encoded in the forward kinematics. Moreover, to allow equivariant message passing in GMN, we have developed a general form of orthogonality-equivariant functions, given that the dynamics of constrained systems are more complicated than the unconstrained counterparts. Theoretically, the proposed equivariant formulation is proved to be universally expressive under certain conditions. Extensive experiments support the advantages of GMN compared to the state-of-the-art GNNs in terms of prediction accuracy, constraint satisfaction and data efficiency on the simulated systems consisting of particles, sticks and hinges, as well as two real-world datasets for molecular dynamics prediction and human motion capture.
Sound Adversarial Audio-Visual Navigation
Feb 22, 2022
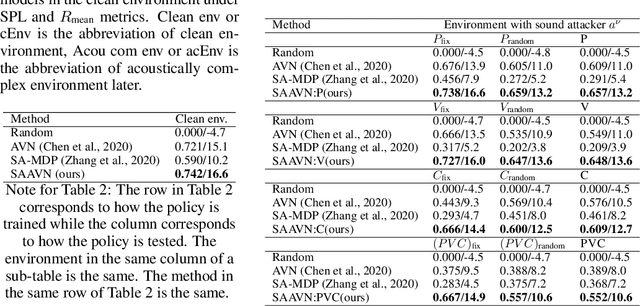
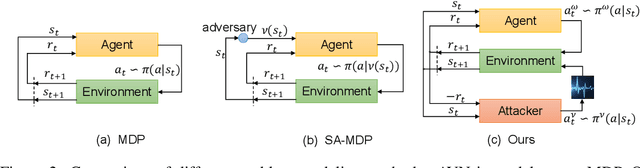
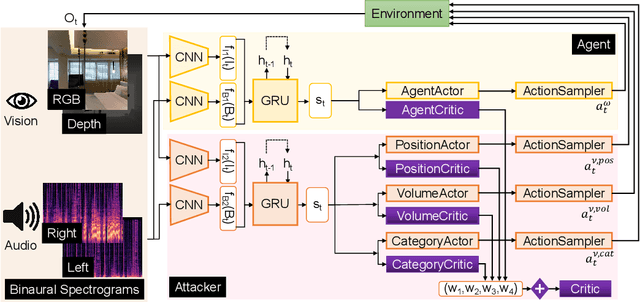
Audio-visual navigation task requires an agent to find a sound source in a realistic, unmapped 3D environment by utilizing egocentric audio-visual observations. Existing audio-visual navigation works assume a clean environment that solely contains the target sound, which, however, would not be suitable in most real-world applications due to the unexpected sound noise or intentional interference. In this work, we design an acoustically complex environment in which, besides the target sound, there exists a sound attacker playing a zero-sum game with the agent. More specifically, the attacker can move and change the volume and category of the sound to make the agent suffer from finding the sounding object while the agent tries to dodge the attack and navigate to the goal under the intervention. Under certain constraints to the attacker, we can improve the robustness of the agent towards unexpected sound attacks in audio-visual navigation. For better convergence, we develop a joint training mechanism by employing the property of a centralized critic with decentralized actors. Experiments on two real-world 3D scan datasets, Replica, and Matterport3D, verify the effectiveness and the robustness of the agent trained under our designed environment when transferred to the clean environment or the one containing sound attackers with random policy. Project: \url{https://yyf17.github.io/SAAVN}.
Geometrically Equivariant Graph Neural Networks: A Survey
Feb 22, 2022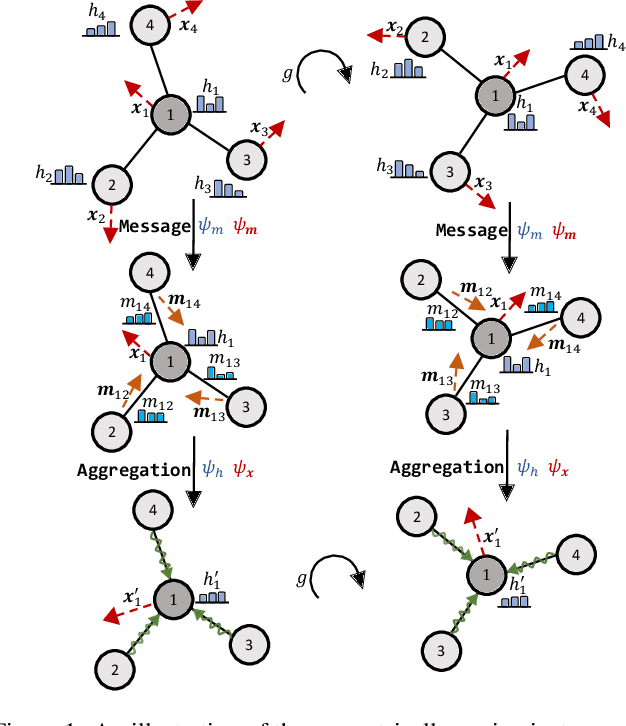
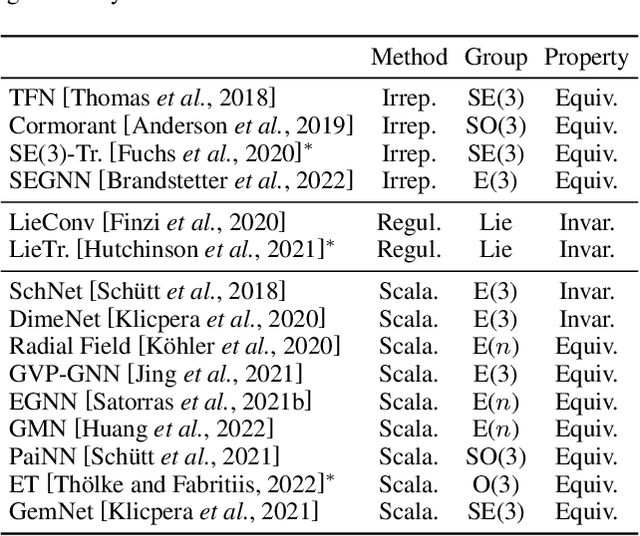
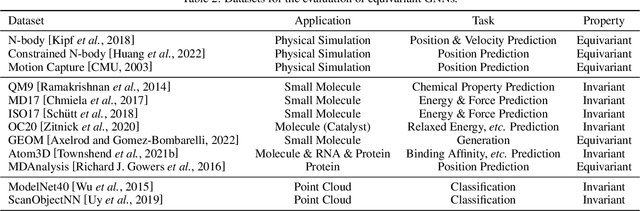
Many scientific problems require to process data in the form of geometric graphs. Unlike generic graph data, geometric graphs exhibit symmetries of translations, rotations, and/or reflections. Researchers have leveraged such inductive bias and developed geometrically equivariant Graph Neural Networks (GNNs) to better characterize the geometry and topology of geometric graphs. Despite fruitful achievements, it still lacks a survey to depict how equivariant GNNs are progressed, which in turn hinders the further development of equivariant GNNs. To this end, based on the necessary but concise mathematical preliminaries, we analyze and classify existing methods into three groups regarding how the message passing and aggregation in GNNs are represented. We also summarize the benchmarks as well as the related datasets to facilitate later researches for methodology development and experimental evaluation. The prospect for future potential directions is also provided.
Equivariant Graph Hierarchy-Based Neural Networks
Feb 22, 2022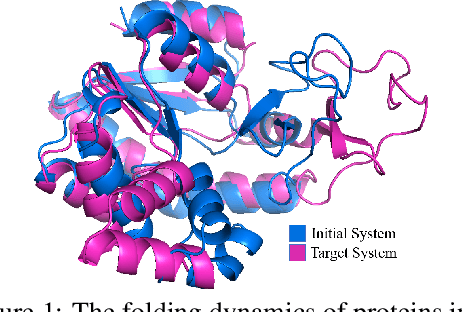

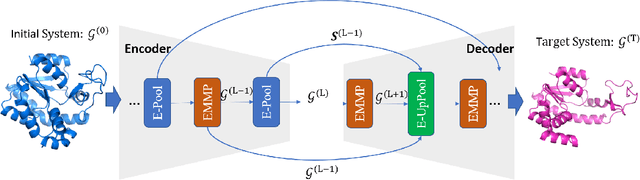
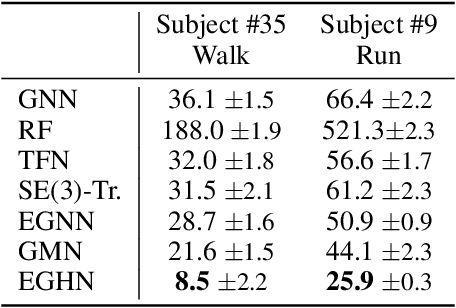
Equivariant Graph neural Networks (EGNs) are powerful in characterizing the dynamics of multi-body physical systems. Existing EGNs conduct flat message passing, which, yet, is unable to capture the spatial/dynamical hierarchy for complex systems particularly, limiting substructure discovery and global information fusion. In this paper, we propose Equivariant Hierarchy-based Graph Networks (EGHNs) which consist of the three key components: generalized Equivariant Matrix Message Passing (EMMP) , E-Pool and E-UpPool. In particular, EMMP is able to improve the expressivity of conventional equivariant message passing, E-Pool assigns the quantities of the low-level nodes into high-level clusters, while E-UpPool leverages the high-level information to update the dynamics of the low-level nodes. As their names imply, both E-Pool and E-UpPool are guaranteed to be equivariant to meet physic symmetry. Considerable experimental evaluations verify the effectiveness of our EGHN on several applications including multi-object dynamics simulation, motion capture, and protein dynamics modeling.
Transformer for Graphs: An Overview from Architecture Perspective
Feb 17, 2022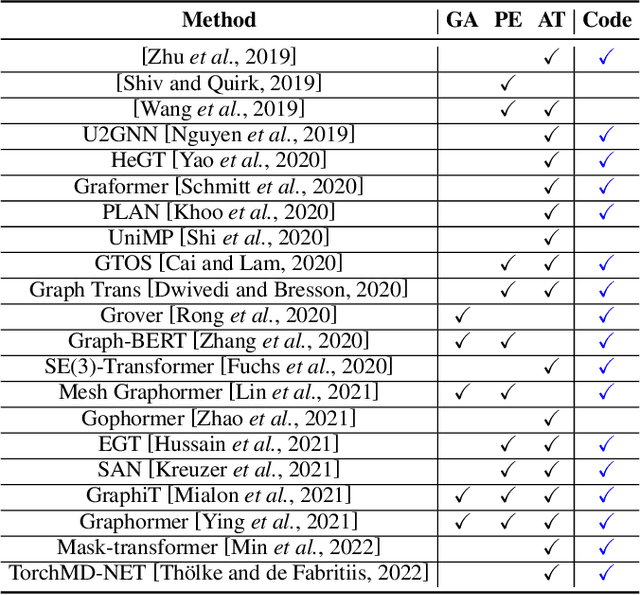
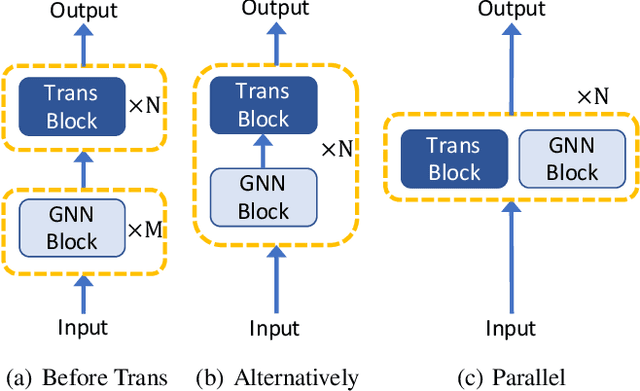
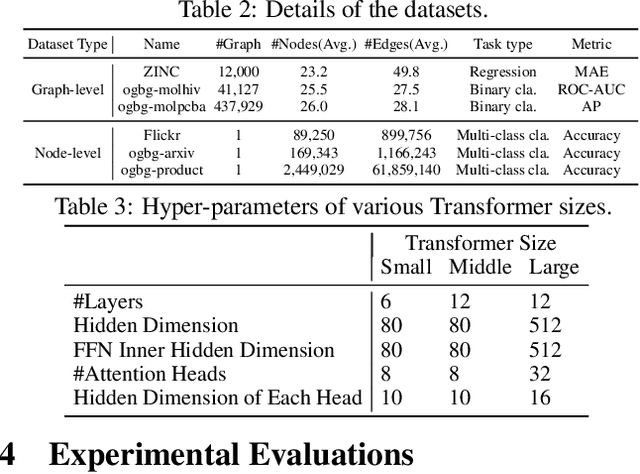
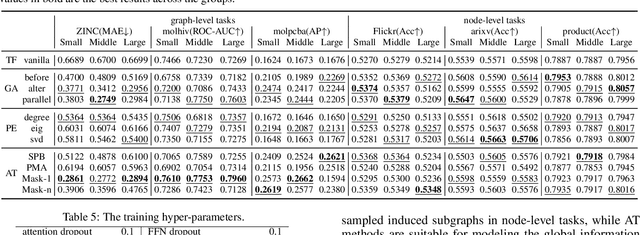
Recently, Transformer model, which has achieved great success in many artificial intelligence fields, has demonstrated its great potential in modeling graph-structured data. Till now, a great variety of Transformers has been proposed to adapt to the graph-structured data. However, a comprehensive literature review and systematical evaluation of these Transformer variants for graphs are still unavailable. It's imperative to sort out the existing Transformer models for graphs and systematically investigate their effectiveness on various graph tasks. In this survey, we provide a comprehensive review of various Graph Transformer models from the architectural design perspective. We first disassemble the existing models and conclude three typical ways to incorporate the graph information into the vanilla Transformer: 1) GNNs as Auxiliary Modules, 2) Improved Positional Embedding from Graphs, and 3) Improved Attention Matrix from Graphs. Furthermore, we implement the representative components in three groups and conduct a comprehensive comparison on various kinds of famous graph data benchmarks to investigate the real performance gain of each component. Our experiments confirm the benefits of current graph-specific modules on Transformer and reveal their advantages on different kinds of graph tasks.
Sim2Real Object-Centric Keypoint Detection and Description
Feb 03, 2022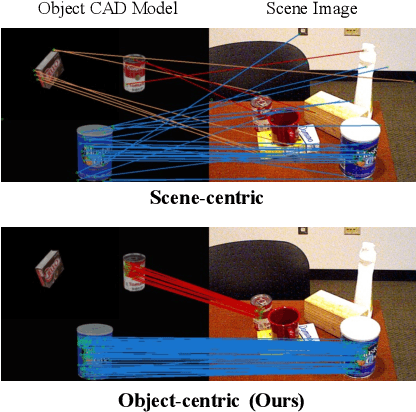

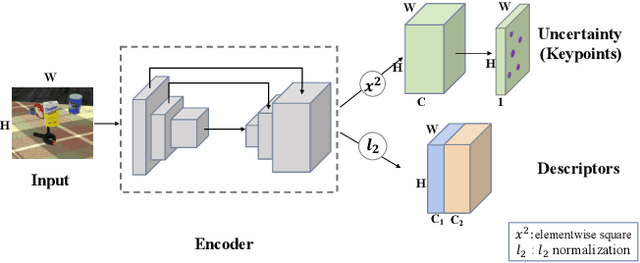
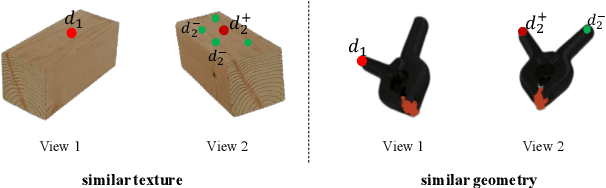
Keypoint detection and description play a central role in computer vision. Most existing methods are in the form of scene-level prediction, without returning the object classes of different keypoints. In this paper, we propose the object-centric formulation, which, beyond the conventional setting, requires further identifying which object each interest point belongs to. With such fine-grained information, our framework enables more downstream potentials, such as object-level matching and pose estimation in a clustered environment. To get around the difficulty of label collection in the real world, we develop a sim2real contrastive learning mechanism that can generalize the model trained in simulation to real-world applications. The novelties of our training method are three-fold: (i) we integrate the uncertainty into the learning framework to improve feature description of hard cases, e.g., less-textured or symmetric patches; (ii) we decouple the object descriptor into two output branches -- intra-object salience and inter-object distinctness, resulting in a better pixel-wise description; (iii) we enforce cross-view semantic consistency for enhanced robustness in representation learning. Comprehensive experiments on image matching and 6D pose estimation verify the encouraging generalization ability of our method from simulation to reality. Particularly for 6D pose estimation, our method significantly outperforms typical unsupervised/sim2real methods, achieving a closer gap with the fully supervised counterpart. Additional results and videos can be found at https://zhongcl-thu.github.io/rock/
Channel Exchanging Networks for Multimodal and Multitask Dense Image Prediction
Dec 04, 2021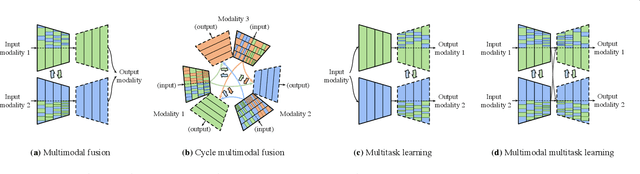
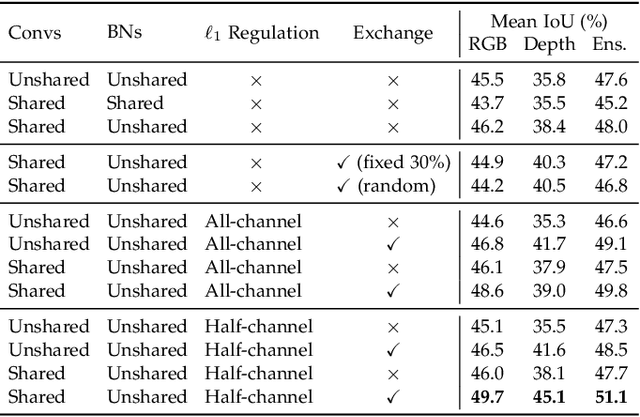
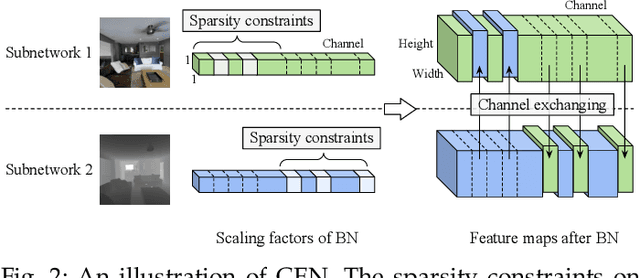
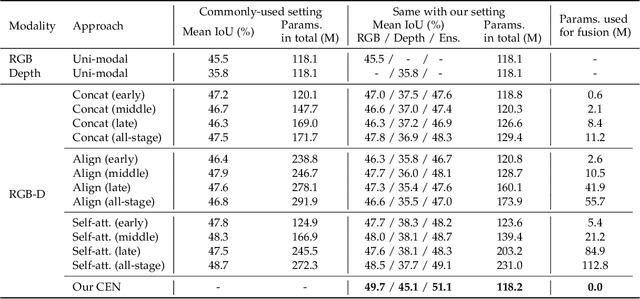
Multimodal fusion and multitask learning are two vital topics in machine learning. Despite the fruitful progress, existing methods for both problems are still brittle to the same challenge -- it remains dilemmatic to integrate the common information across modalities (resp. tasks) meanwhile preserving the specific patterns of each modality (resp. task). Besides, while they are actually closely related to each other, multimodal fusion and multitask learning are rarely explored within the same methodological framework before. In this paper, we propose Channel-Exchanging-Network (CEN) which is self-adaptive, parameter-free, and more importantly, applicable for both multimodal fusion and multitask learning. At its core, CEN dynamically exchanges channels between subnetworks of different modalities. Specifically, the channel exchanging process is self-guided by individual channel importance that is measured by the magnitude of Batch-Normalization (BN) scaling factor during training. For the application of dense image prediction, the validity of CEN is tested by four different scenarios: multimodal fusion, cycle multimodal fusion, multitask learning, and multimodal multitask learning. Extensive experiments on semantic segmentation via RGB-D data and image translation through multi-domain input verify the effectiveness of our CEN compared to current state-of-the-art methods. Detailed ablation studies have also been carried out, which provably affirm the advantage of each component we propose.
Graph Convolutional Module for Temporal Action Localization in Videos
Dec 01, 2021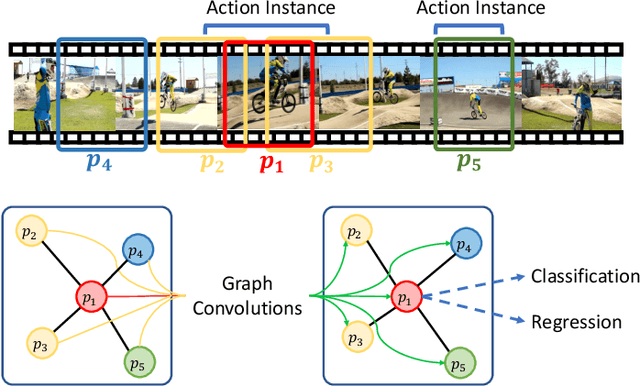
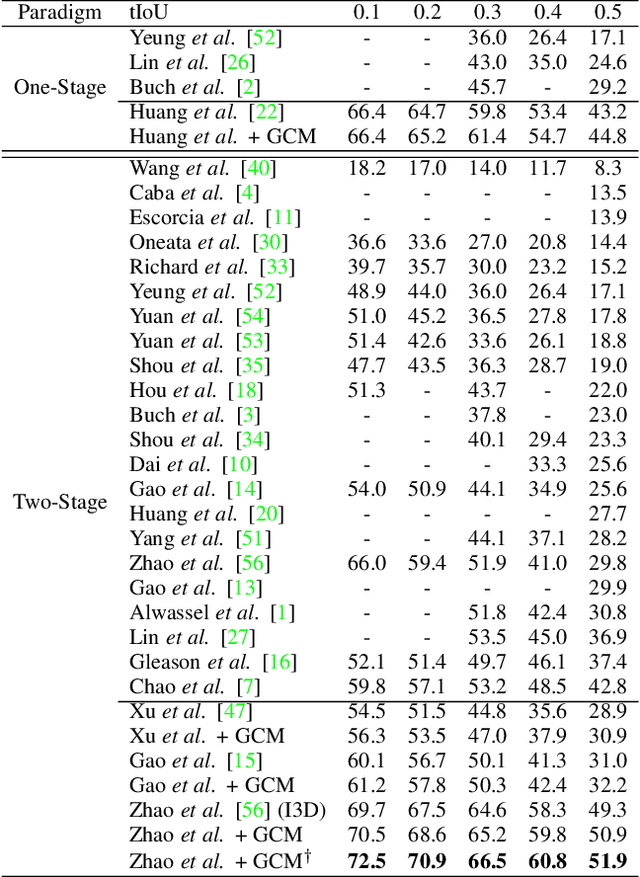
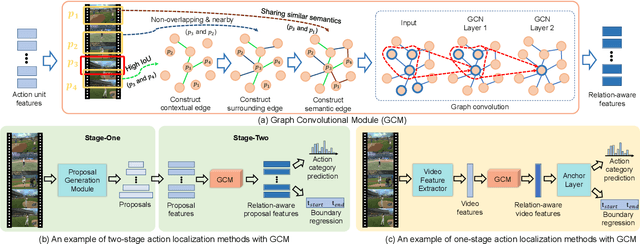
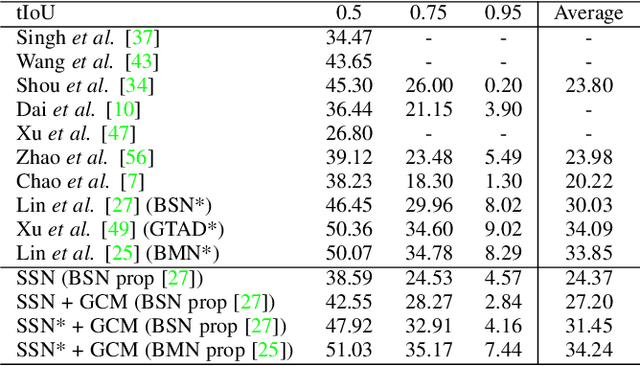
Temporal action localization has long been researched in computer vision. Existing state-of-the-art action localization methods divide each video into multiple action units (i.e., proposals in two-stage methods and segments in one-stage methods) and then perform action recognition/regression on each of them individually, without explicitly exploiting their relations during learning. In this paper, we claim that the relations between action units play an important role in action localization, and a more powerful action detector should not only capture the local content of each action unit but also allow a wider field of view on the context related to it. To this end, we propose a general graph convolutional module (GCM) that can be easily plugged into existing action localization methods, including two-stage and one-stage paradigms. To be specific, we first construct a graph, where each action unit is represented as a node and their relations between two action units as an edge. Here, we use two types of relations, one for capturing the temporal connections between different action units, and the other one for characterizing their semantic relationship. Particularly for the temporal connections in two-stage methods, we further explore two different kinds of edges, one connecting the overlapping action units and the other one connecting surrounding but disjointed units. Upon the graph we built, we then apply graph convolutional networks (GCNs) to model the relations among different action units, which is able to learn more informative representations to enhance action localization. Experimental results show that our GCM consistently improves the performance of existing action localization methods, including two-stage methods (e.g., CBR and R-C3D) and one-stage methods (e.g., D-SSAD), verifying the generality and effectiveness of our GCM.