 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHFGD: High-level Feature Guided Decoder for Semantic Segmentation
Mar 15, 2023Commonly used backbones for semantic segmentation, such as ResNet and Swin-Transformer, have multiple stages for feature encoding. Simply using high-resolution low-level feature maps from the early stages of the backbone to directly refine the low-resolution high-level feature map is a common practice of low-resolution feature map upsampling. However, the representation power of the low-level features is generally worse than high-level features, thus introducing ``noise" to the upsampling refinement. To address this issue, we proposed High-level Feature Guided Decoder (HFGD), which uses isolated high-level features to guide low-level features and upsampling process. Specifically, the guidance is realized through carefully designed stop gradient operations and class kernels. Now the class kernels co-evolve only with the high-level features and are reused in the upsampling head to guide the training process of the upsampling head. HFGD is very efficient and effective that can also upsample the feature maps to a previously unseen output stride (OS) of 2 and still obtain accuracy gain. HFGD demonstrates state-of-the-art performance on several benchmark datasets (e.g. Pascal Context, COCOStuff164k and Cityscapes) with small FLOPs. The full code will be available at https://github.com/edwardyehuang/HFGD.git.
DC-Former: Diverse and Compact Transformer for Person Re-Identification
Feb 28, 2023In person re-identification (re-ID) task, it is still challenging to learn discriminative representation by deep learning, due to limited data. Generally speaking, the model will get better performance when increasing the amount of data. The addition of similar classes strengthens the ability of the classifier to identify similar identities, thereby improving the discrimination of representation. In this paper, we propose a Diverse and Compact Transformer (DC-Former) that can achieve a similar effect by splitting embedding space into multiple diverse and compact subspaces. Compact embedding subspace helps model learn more robust and discriminative embedding to identify similar classes. And the fusion of these diverse embeddings containing more fine-grained information can further improve the effect of re-ID. Specifically, multiple class tokens are used in vision transformer to represent multiple embedding spaces. Then, a self-diverse constraint (SDC) is applied to these spaces to push them away from each other, which makes each embedding space diverse and compact. Further, a dynamic weight controller(DWC) is further designed for balancing the relative importance among them during training. The experimental results of our method are promising, which surpass previous state-of-the-art methods on several commonly used person re-ID benchmarks.
Minimizing Maximum Model Discrepancy for Transferable Black-box Targeted Attacks
Dec 18, 2022



In this work, we study the black-box targeted attack problem from the model discrepancy perspective. On the theoretical side, we present a generalization error bound for black-box targeted attacks, which gives a rigorous theoretical analysis for guaranteeing the success of the attack. We reveal that the attack error on a target model mainly depends on empirical attack error on the substitute model and the maximum model discrepancy among substitute models. On the algorithmic side, we derive a new algorithm for black-box targeted attacks based on our theoretical analysis, in which we additionally minimize the maximum model discrepancy(M3D) of the substitute models when training the generator to generate adversarial examples. In this way, our model is capable of crafting highly transferable adversarial examples that are robust to the model variation, thus improving the success rate for attacking the black-box model. We conduct extensive experiments on the ImageNet dataset with different classification models, and our proposed approach outperforms existing state-of-the-art methods by a significant margin. Our codes will be released.
Coarse-Super-Resolution-Fine Network (CoSF-Net): A Unified End-to-End Neural Network for 4D-MRI with Simultaneous Motion Estimation and Super-Resolution
Nov 21, 2022



Four-dimensional magnetic resonance imaging (4D-MRI) is an emerging technique for tumor motion management in image-guided radiation therapy (IGRT). However, current 4D-MRI suffers from low spatial resolution and strong motion artifacts owing to the long acquisition time and patients' respiratory variations; these limitations, if not managed properly, can adversely affect treatment planning and delivery in IGRT. Herein, we developed a novel deep learning framework called the coarse-super-resolution-fine network (CoSF-Net) to achieve simultaneous motion estimation and super-resolution in a unified model. We designed CoSF-Net by fully excavating the inherent properties of 4D-MRI, with consideration of limited and imperfectly matched training datasets. We conducted extensive experiments on multiple real patient datasets to verify the feasibility and robustness of the developed network. Compared with existing networks and three state-of-the-art conventional algorithms, CoSF-Net not only accurately estimated the deformable vector fields between the respiratory phases of 4D-MRI but also simultaneously improved the spatial resolution of 4D-MRI with enhanced anatomic features, yielding 4D-MR images with high spatiotemporal resolution.
Motion and Appearance Adaptation for Cross-Domain Motion Transfer
Oct 06, 2022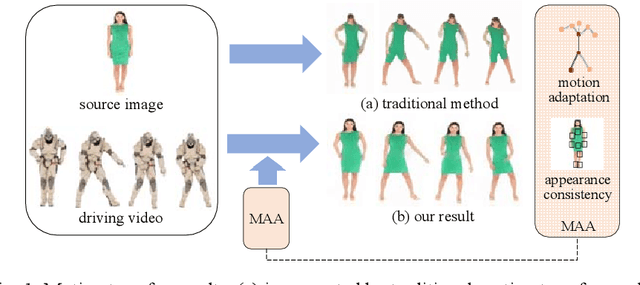
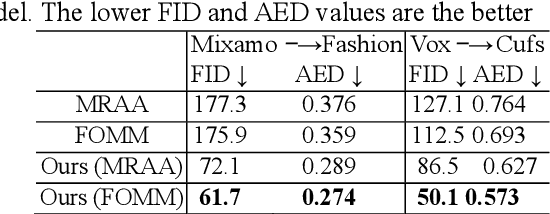
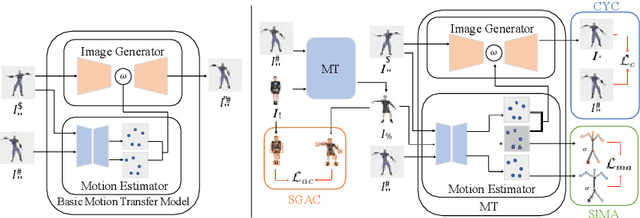
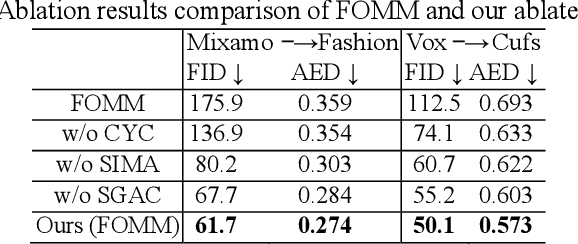
Motion transfer aims to transfer the motion of a driving video to a source image. When there are considerable differences between object in the driving video and that in the source image, traditional single domain motion transfer approaches often produce notable artifacts; for example, the synthesized image may fail to preserve the human shape of the source image (cf . Fig. 1 (a)). To address this issue, in this work, we propose a Motion and Appearance Adaptation (MAA) approach for cross-domain motion transfer, in which we regularize the object in the synthesized image to capture the motion of the object in the driving frame, while still preserving the shape and appearance of the object in the source image. On one hand, considering the object shapes of the synthesized image and the driving frame might be different, we design a shape-invariant motion adaptation module that enforces the consistency of the angles of object parts in two images to capture the motion information. On the other hand, we introduce a structure-guided appearance consistency module designed to regularize the similarity between the corresponding patches of the synthesized image and the source image without affecting the learned motion in the synthesized image. Our proposed MAA model can be trained in an end-to-end manner with a cyclic reconstruction loss, and ultimately produces a satisfactory motion transfer result (cf . Fig. 1 (b)). We conduct extensive experiments on human dancing dataset Mixamo-Video to Fashion-Video and human face dataset Vox-Celeb to Cufs; on both of these, our MAA model outperforms existing methods both quantitatively and qualitatively.
Motion Transformer for Unsupervised Image Animation
Sep 28, 2022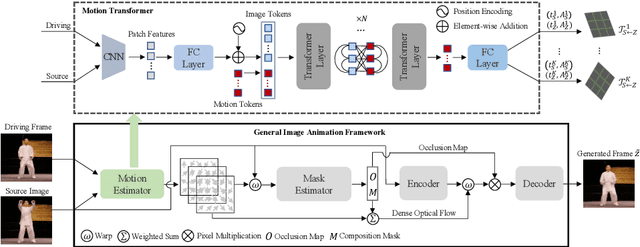
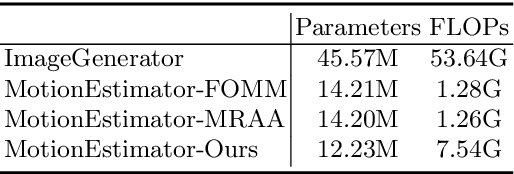


Image animation aims to animate a source image by using motion learned from a driving video. Current state-of-the-art methods typically use convolutional neural networks (CNNs) to predict motion information, such as motion keypoints and corresponding local transformations. However, these CNN based methods do not explicitly model the interactions between motions; as a result, the important underlying motion relationship may be neglected, which can potentially lead to noticeable artifacts being produced in the generated animation video. To this end, we propose a new method, the motion transformer, which is the first attempt to build a motion estimator based on a vision transformer. More specifically, we introduce two types of tokens in our proposed method: i) image tokens formed from patch features and corresponding position encoding; and ii) motion tokens encoded with motion information. Both types of tokens are sent into vision transformers to promote underlying interactions between them through multi-head self attention blocks. By adopting this process, the motion information can be better learned to boost the model performance. The final embedded motion tokens are then used to predict the corresponding motion keypoints and local transformations. Extensive experiments on benchmark datasets show that our proposed method achieves promising results to the state-of-the-art baselines. Our source code will be public available.
Revisiting AP Loss for Dense Object Detection: Adaptive Ranking Pair Selection
Jul 25, 2022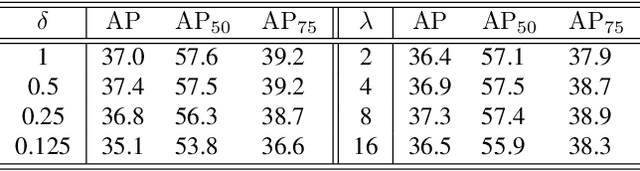
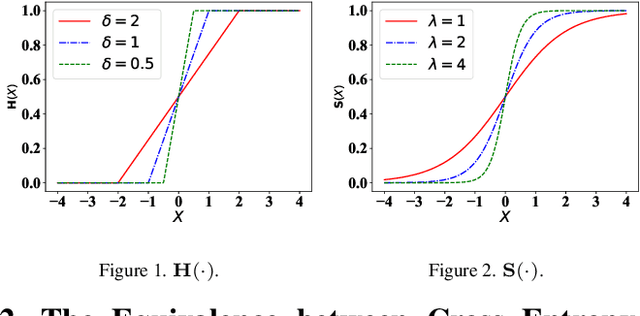
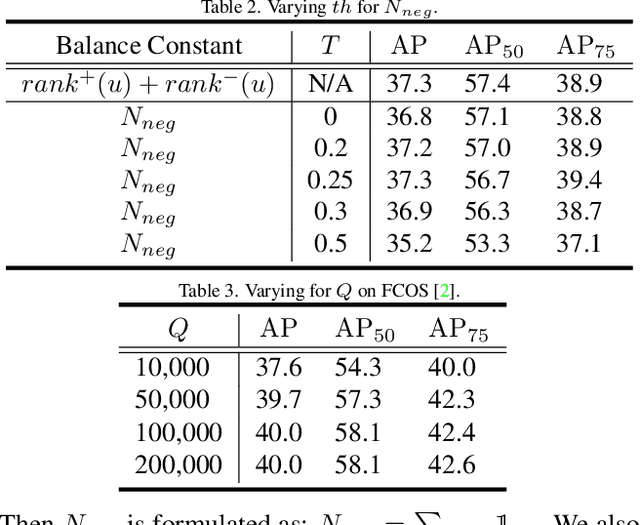
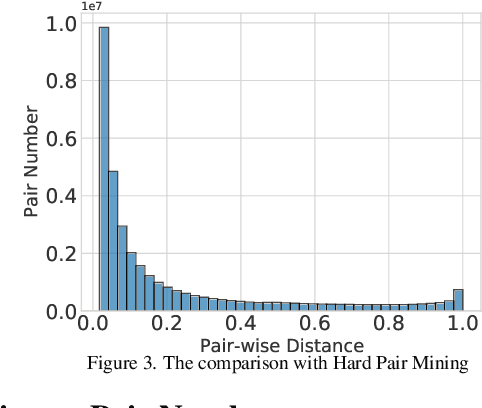
Average precision (AP) loss has recently shown promising performance on the dense object detection task. However,a deep understanding of how AP loss affects the detector from a pairwise ranking perspective has not yet been developed.In this work, we revisit the average precision (AP)loss and reveal that the crucial element is that of selecting the ranking pairs between positive and negative samples.Based on this observation, we propose two strategies to improve the AP loss. The first of these is a novel Adaptive Pairwise Error (APE) loss that focusing on ranking pairs in both positive and negative samples. Moreover,we select more accurate ranking pairs by exploiting the normalized ranking scores and localization scores with a clustering algorithm. Experiments conducted on the MSCOCO dataset support our analysis and demonstrate the superiority of our proposed method compared with current classification and ranking loss. The code is available at https://github.com/Xudangliatiger/APE-Loss.
Solutions for Fine-grained and Long-tailed Snake Species Recognition in SnakeCLEF 2022
Jul 04, 2022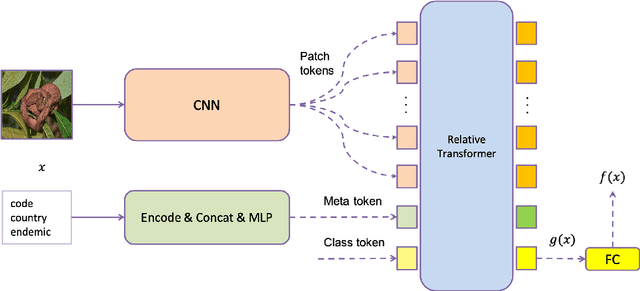
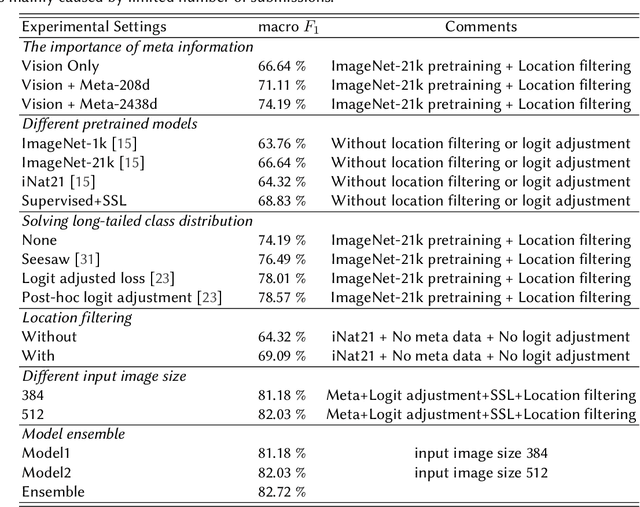

Automatic snake species recognition is important because it has vast potential to help lower deaths and disabilities caused by snakebites. We introduce our solution in SnakeCLEF 2022 for fine-grained snake species recognition on a heavy long-tailed class distribution. First, a network architecture is designed to extract and fuse features from multiple modalities, i.e. photograph from visual modality and geographic locality information from language modality. Then, logit adjustment based methods are studied to relieve the impact caused by the severe class imbalance. Next, a combination of supervised and self-supervised learning method is proposed to make full use of the dataset, including both labeled training data and unlabeled testing data. Finally, post processing strategies, such as multi-scale and multi-crop test-time-augmentation, location filtering and model ensemble, are employed for better performance. With an ensemble of several different models, a private score 82.65%, ranking the 3rd, is achieved on the final leaderboard.
Cross-domain Detection Transformer based on Spatial-aware and Semantic-aware Token Alignment
Jun 01, 2022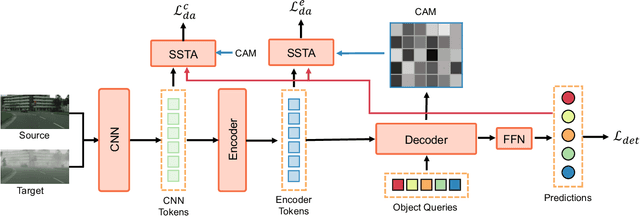
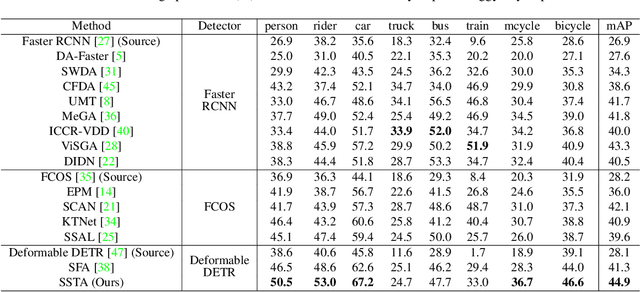
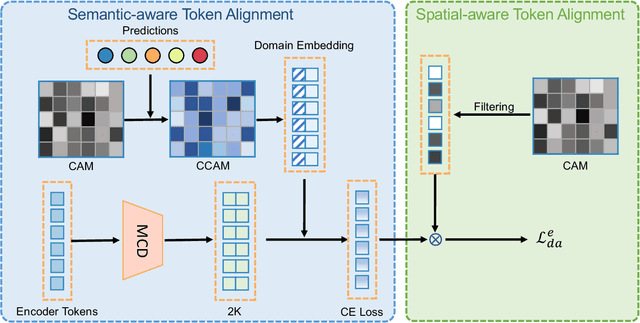
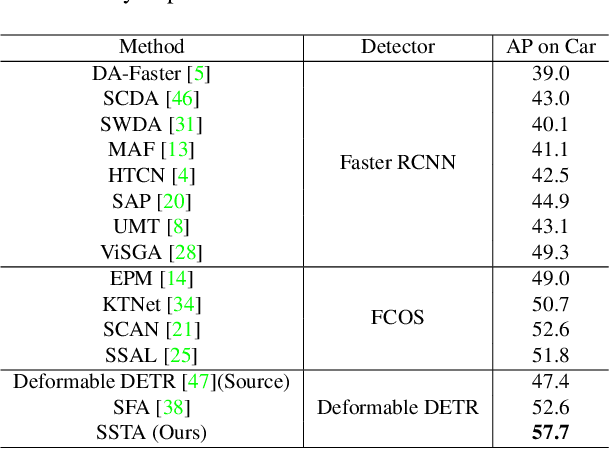
Detection transformers like DETR have recently shown promising performance on many object detection tasks, but the generalization ability of those methods is still quite challenging for cross-domain adaptation scenarios. To address the cross-domain issue, a straightforward way is to perform token alignment with adversarial training in transformers. However, its performance is often unsatisfactory as the tokens in detection transformers are quite diverse and represent different spatial and semantic information. In this paper, we propose a new method called Spatial-aware and Semantic-aware Token Alignment (SSTA) for cross-domain detection transformers. In particular, we take advantage of the characteristics of cross-attention as used in detection transformer and propose the spatial-aware token alignment (SpaTA) and the semantic-aware token alignment (SemTA) strategies to guide the token alignment across domains. For spatial-aware token alignment, we can extract the information from the cross-attention map (CAM) to align the distribution of tokens according to their attention to object queries. For semantic-aware token alignment, we inject the category information into the cross-attention map and construct domain embedding to guide the learning of a multi-class discriminator so as to model the category relationship and achieve category-level token alignment during the entire adaptation process. We conduct extensive experiments on several widely-used benchmarks, and the results clearly show the effectiveness of our proposed method over existing state-of-the-art baselines.
Revisiting Random Channel Pruning for Neural Network Compression
May 11, 2022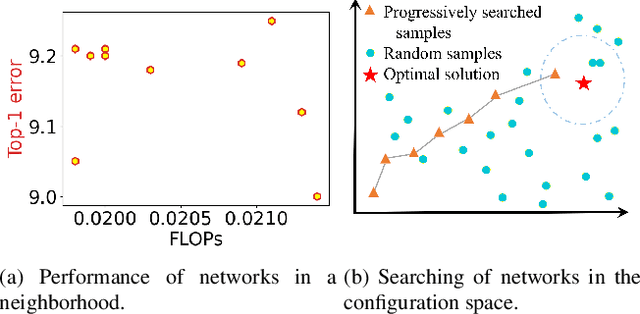
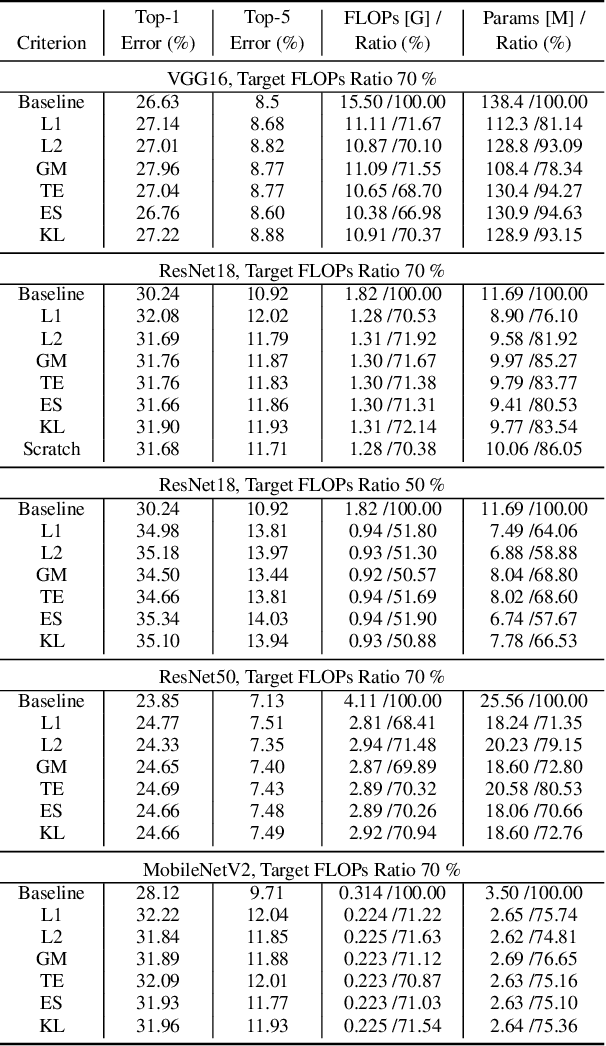
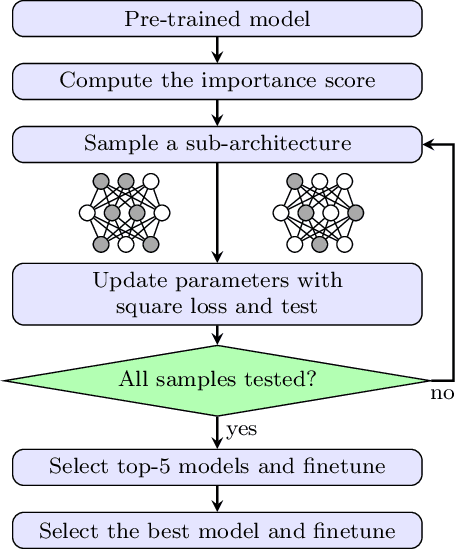
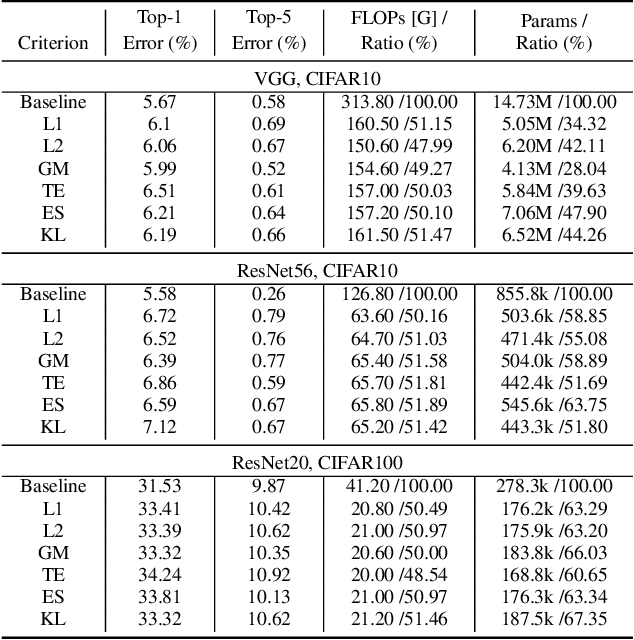
Channel (or 3D filter) pruning serves as an effective way to accelerate the inference of neural networks. There has been a flurry of algorithms that try to solve this practical problem, each being claimed effective in some ways. Yet, a benchmark to compare those algorithms directly is lacking, mainly due to the complexity of the algorithms and some custom settings such as the particular network configuration or training procedure. A fair benchmark is important for the further development of channel pruning. Meanwhile, recent investigations reveal that the channel configurations discovered by pruning algorithms are at least as important as the pre-trained weights. This gives channel pruning a new role, namely searching the optimal channel configuration. In this paper, we try to determine the channel configuration of the pruned models by random search. The proposed approach provides a new way to compare different methods, namely how well they behave compared with random pruning. We show that this simple strategy works quite well compared with other channel pruning methods. We also show that under this setting, there are surprisingly no clear winners among different channel importance evaluation methods, which then may tilt the research efforts into advanced channel configuration searching methods.