 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fine-grained Human Pose Transfer with Detail Replenishing Network
May 26, 2020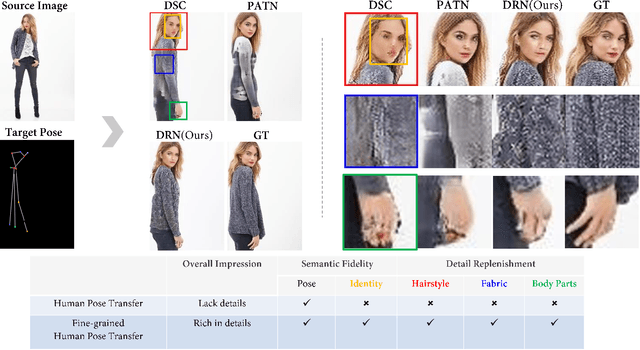
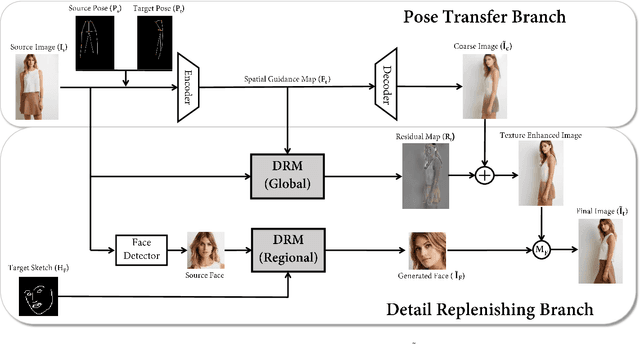
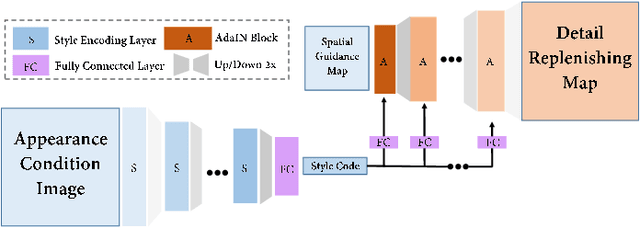

Human pose transfer (HPT) is an emerging research topic with huge potential in fashion design, media production, online advertising and virtual reality. For these applications, the visual realism of fine-grained appearance details is crucial for production quality and user engagement. However, existing HPT methods often suffer from three fundamental issues: detail deficiency, content ambiguity and style inconsistency, which severely degrade the visual quality and realism of generated images. Aiming towards real-world applications, we develop a more challenging yet practical HPT setting, termed as Fine-grained Human Pose Transfer (FHPT), with a higher focus on semantic fidelity and detail replenishment. Concretely, we analyze the potential design flaws of existing methods via an illustrative example, and establish the core FHPT methodology by combing the idea of content synthesis and feature transfer together in a mutually-guided fashion. Thereafter, we substantiate the proposed methodology with a Detail Replenishing Network (DRN) and a corresponding coarse-to-fine model training scheme. Moreover, we build up a complete suite of fine-grained evaluation protocols to address the challenges of FHPT in a comprehensive manner, including semantic analysis, structural detection and perceptual quality assessment. Extensive experiments on the DeepFashion benchmark dataset have verified the power of proposed benchmark against start-of-the-art works, with 12\%-14\% gain on top-10 retrieval recall, 5\% higher joint localization accuracy, and near 40\% gain on face identity preservation. Moreover, the evaluation results offer further insights to the subject matter, which could inspire many promising future works along this direction.
Region-adaptive Texture Enhancement for Detailed Person Image Synthesis
May 26, 2020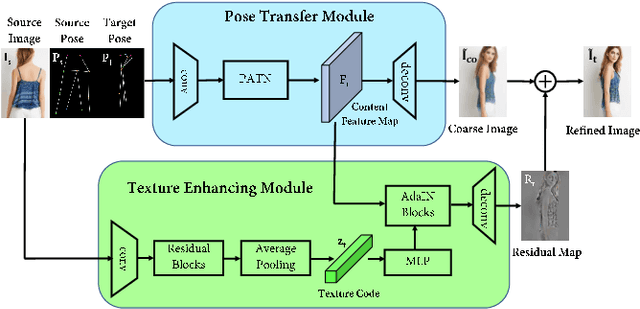
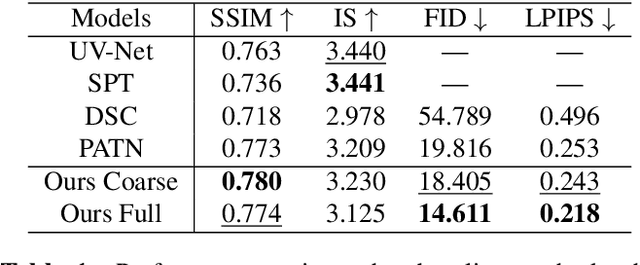

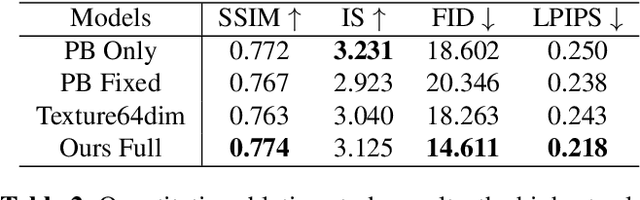
The ability to produce convincing textural details is essential for the fidelity of synthesized person images. However, existing methods typically follow a ``warping-based'' strategy that propagates appearance features through the same pathway used for pose transfer. However, most fine-grained features would be lost due to down-sampling, leading to over-smoothed clothes and missing details in the output images. In this paper we presents RATE-Net, a novel framework for synthesizing person images with sharp texture details. The proposed framework leverages an additional texture enhancing module to extract appearance information from the source image and estimate a fine-grained residual texture map, which helps to refine the coarse estimation from the pose transfer module. In addition, we design an effective alternate updating strategy to promote mutual guidance between two modules for better shape and appearance consistency. Experiments conducted on DeepFashion benchmark dataset have demonstrated the superiority of our framework compared with existing networks.
Location-Aware Feature Selection Text Detection Network
May 26, 2020



Regression-based text detection methods have already achieved promising performances with simple network structure and high efficiency. However, they are behind in accuracy comparing with recent segmentation-based text detectors. In this work, we discover that one important reason to this case is that regression-based methods usually utilize a fixed feature selection way, i.e. selecting features in a single location or in neighbor regions, to predict components of the bounding box, such as the distances to the boundaries or the rotation angle. The features selected through this way sometimes are not the best choices for predicting every component of a text bounding box and thus degrade the accuracy performance. To address this issue, we propose a novel Location-Aware feature Selection text detection Network (LASNet). LASNet selects suitable features from different locations to separately predict the five components of a bounding box and gets the final bounding box through the combination of these components. Specifically, instead of using the classification score map to select one feature for predicting the whole bounding box as most of the existing methods did, the proposed LASNet first learn five new confidence score maps to indicate the prediction accuracy of the bounding box components, respectively. Then, a Location-Aware Feature Selection mechanism (LAFS) is designed to weightily fuse the top-$K$ prediction results for each component according to their confidence score, and to combine the all five fused components into a final bounding box. As a result, LASNet predicts the more accurate bounding boxes by using a learnable feature selection way. The experimental results demonstrate that our LASNet achieves state-of-the-art performance with single-model and single-scale testing, outperforming all existing regression-based detectors.
Iterative Network for Image Super-Resolution
May 20, 2020
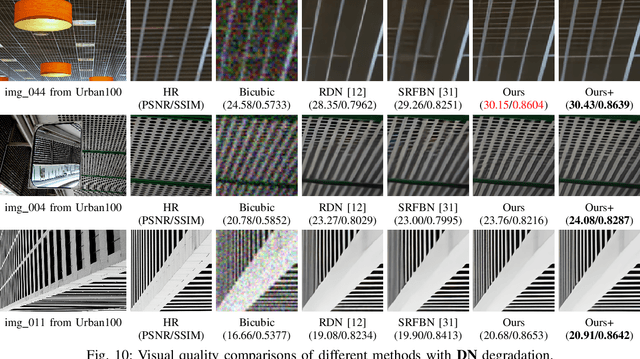
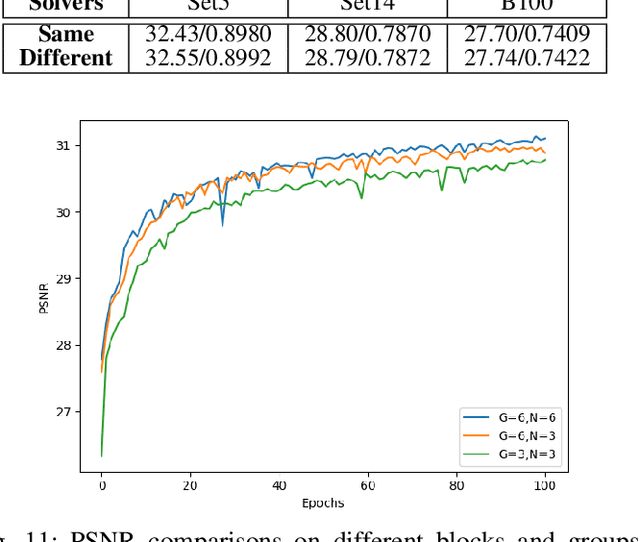
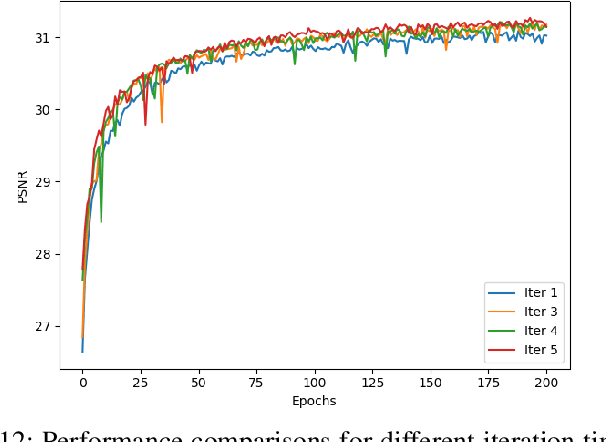
Single image super-resolution (SISR), as a traditional ill-conditioned inverse problem, has been greatly revitalized by the recent development of convolutional neural networks (CNN). These CNN-based methods generally map a low-resolution image to its corresponding high-resolution version with sophisticated network structures and loss functions, showing impressive performances. This paper proposes a substantially different approach relying on the iterative optimization on HR space with an iterative super-resolution network (ISRN). We first analyze the observation model of image SR problem, inspiring a feasible solution by mimicking and fusing each iteration in a more general and efficient manner. Considering the drawbacks of batch normalization, we propose a feature normalization (FNorm) method to regulate the features in network. Furthermore, a novel block with F-Norm is developed to improve the network representation, termed as FNB. Residual-in-residual structure is proposed to form a very deep network, which groups FNBs with a long skip connection for better information delivery and stabling the training phase. Extensive experimental results on testing benchmarks with bicubic (BI) degradation show our ISRN can not only recover more structural information, but also achieve competitive or better PSNR/SSIM results with much fewer parameters compared to other works. Besides BI, we simulate the real-world degradation with blur-downscale (BD) and downscalenoise (DN). ISRN and its extension ISRN+ both achieve better performance than others with BD and DN degradation models.
HiFaceGAN: Face Renovation via Collaborative Suppression and Replenishment
May 11, 2020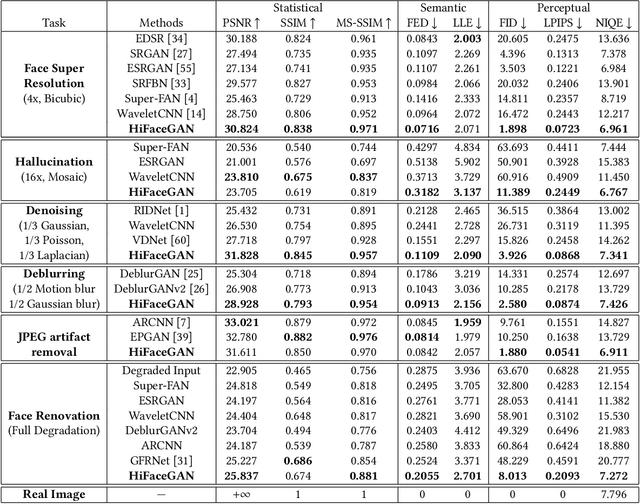

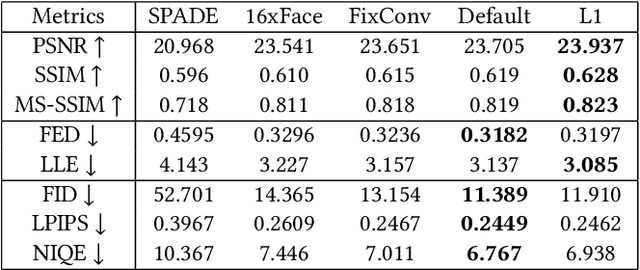
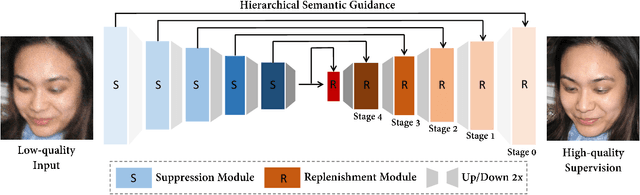
Existing face restoration researches typically relies on either the degradation prior or explicit guidance labels for training, which often results in limited generalization ability over real-world images with heterogeneous degradations and rich background contents. In this paper, we investigate the more challenging and practical "dual-blind" version of the problem by lifting the requirements on both types of prior, termed as "Face Renovation"(FR). Specifically, we formulated FR as a semantic-guided generation problem and tackle it with a collaborative suppression and replenishment (CSR) approach. This leads to HiFaceGAN, a multi-stage framework containing several nested CSR units that progressively replenish facial details based on the hierarchical semantic guidance extracted from the front-end content-adaptive suppression modules. Extensive experiments on both synthetic and real face images have verified the superior performance of HiFaceGAN over a wide range of challenging restoration subtasks, demonstrating its versatility, robustness and generalization ability towards real-world face processing applications.
SegaBERT: Pre-training of Segment-aware BERT for Language Understanding
Apr 30, 2020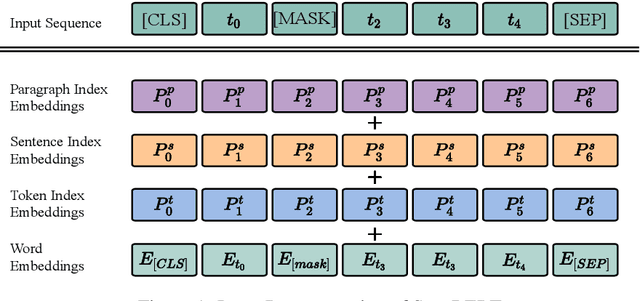
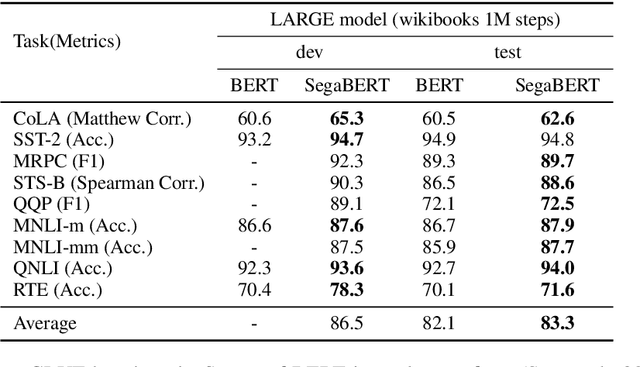
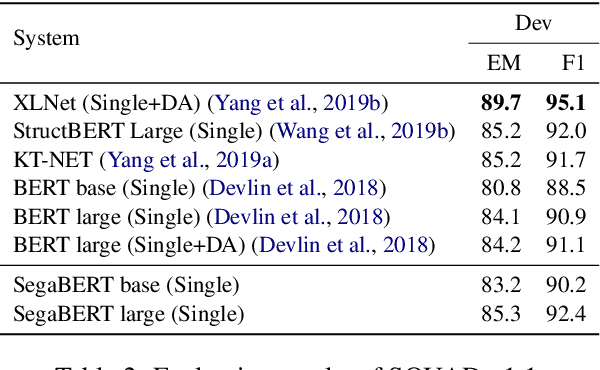
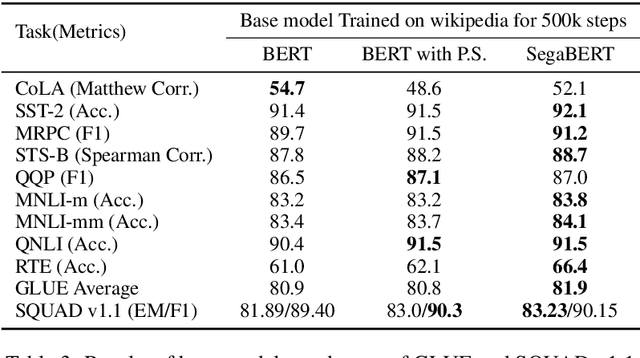
Pre-trained language models have achieved state-of-the-art results in various natural language processing tasks. Most of them are based on the Transformer architecture, which distinguishes tokens with the token position index of the input sequence. However, sentence index and paragraph index are also important to indicate the token position in a document. We hypothesize that better contextual representations can be generated from the text encoder with richer positional information. To verify this, we propose a segment-aware BERT, by replacing the token position embedding of Transformer with a combination of paragraph index, sentence index, and token index embeddings. We pre-trained the SegaBERT on the masked language modeling task in BERT but without any affiliated tasks. Experimental results show that our pre-trained model can outperform the original BERT model on various NLP tasks.
Towards Analysis-friendly Face Representation with Scalable Feature and Texture Compression
Apr 21, 2020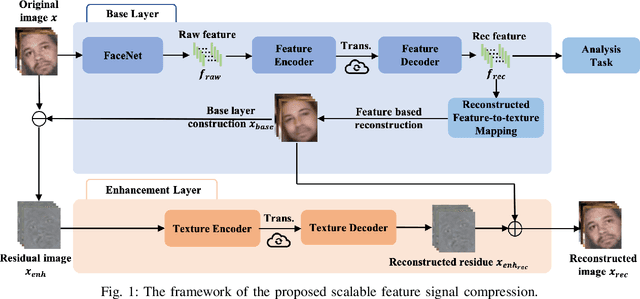
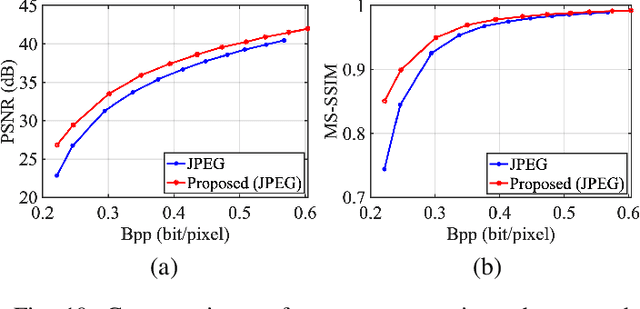
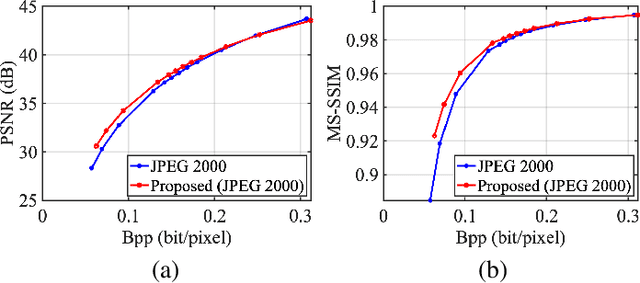
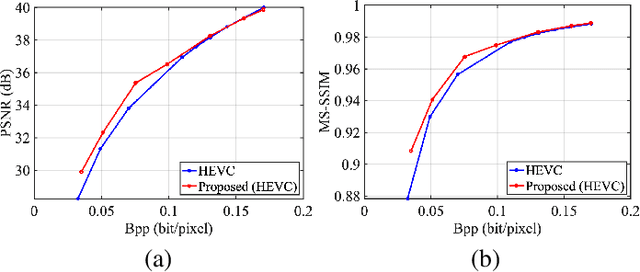
It plays a fundamental role to compactly represent the visual information towards the optimization of the ultimate utility in myriad visual data centered applications. With numerous approaches proposed to efficiently compress the texture and visual features serving human visual perception and machine intelligence respectively, much less work has been dedicated to studying the interactions between them. Here we investigate the integration of feature and texture compression, and show that a universal and collaborative visual information representation can be achieved in a hierarchical way. In particular, we study the feature and texture compression in a scalable coding framework, where the base layer serves as the deep learning feature and enhancement layer targets to perfectly reconstruct the texture. Based on the strong generative capability of deep neural networks, the gap between the base feature layer and enhancement layer is further filled with the feature level texture reconstruction, aiming to further construct texture representation from feature. As such, the residuals between the original and reconstructed texture could be further conveyed in the enhancement layer. To improve the efficiency of the proposed framework, the base layer neural network is trained in a multi-task manner such that the learned features enjoy both high quality reconstruction and high accuracy analysis. We further demonstrate the framework and optimization strategies in face image compression, and promising coding performance has been achieved in terms of both rate-fidelity and rate-accuracy.
Semantics of the Unwritten
Apr 05, 2020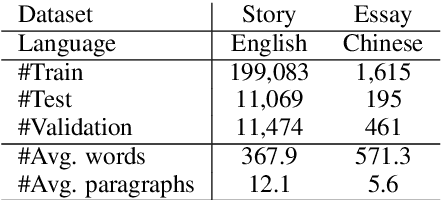
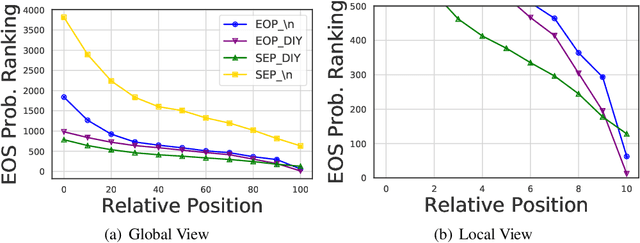
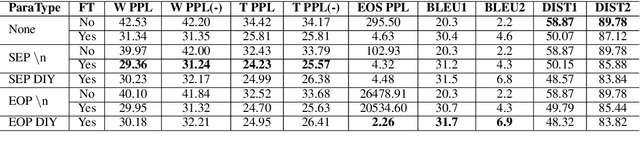

The semantics of a text is manifested not only by what is read, but also by what is not read. In this article, we will study how those implicit "not read" information such as end-of-paragraph (EOP) and end-of-sequence (EOS) affect the quality of text generation. Transformer-based pretrained language models (LMs) have demonstrated the ability to generate long continuations with good quality. This model gives us a platform for the first time to demonstrate that paragraph layouts and text endings are also important components of human writing. Specifically, we find that pretrained LMs can generate better continuations by learning to generate the end of the paragraph (EOP) in the fine-tuning stage. Experimental results on English story generation show that EOP can lead to higher BLEU score and lower EOS perplexity. To further investigate the relationship between text ending and EOP, we conduct experiments with a self-collected Chinese essay dataset on Chinese-GPT2, a character level LM without paragraph breaker or EOS during pre-training. Experimental results show that the Chinese GPT2 can generate better essay endings with paragraph information. Experiments on both English stories and Chinese essays demonstrate that learning to end paragraphs can benefit the continuation generation with pretrained LMs.
Rectified Meta-Learning from Noisy Labels for Robust Image-based Plant Disease Diagnosis
Mar 18, 2020
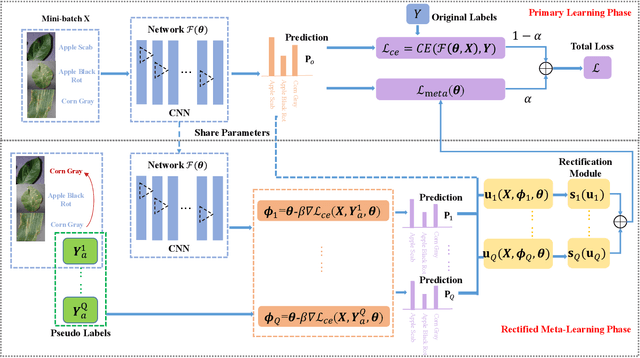

Plant diseases serve as one of main threats to food security and crop production. It is thus valuable to exploit recent advances of artificial intelligence to assist plant disease diagnosis. One popular approach is to transform this problem as a leaf image classification task, which can be then addressed by the powerful convolutional neural networks (CNNs). However, the performance of CNN-based classification approach depends on a large amount of high-quality manually labeled training data, which are inevitably introduced noise on labels in practice, leading to model overfitting and performance degradation. To overcome this problem, we propose a novel framework that incorporates rectified meta-learning module into common CNN paradigm to train a noise-robust deep network without using extra supervision information. The proposed method enjoys the following merits: i) A rectified meta-learning is designed to pay more attention to unbiased samples, leading to accelerated convergence and improved classification accuracy. ii) Our method is free on assumption of label noise distribution, which works well on various kinds of noise. iii) Our method serves as a plug-and-play module, which can be embedded into any deep models optimized by gradient descent based method. Extensive experiments are conducted to demonstrate the superior performance of our algorithm over the state-of-the-arts.
Video Coding for Machines: A Paradigm of Collaborative Compression and Intelligent Analytics
Jan 13, 2020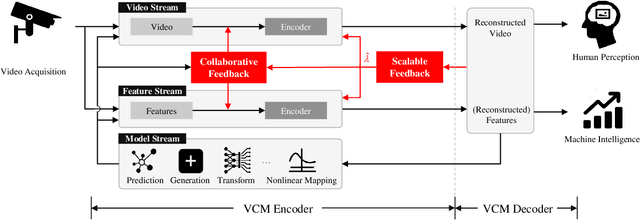
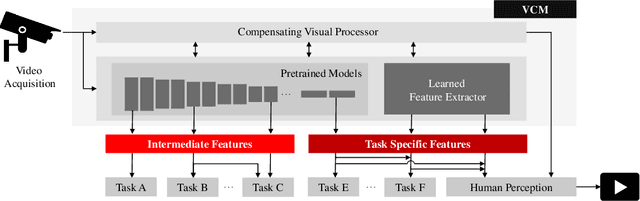
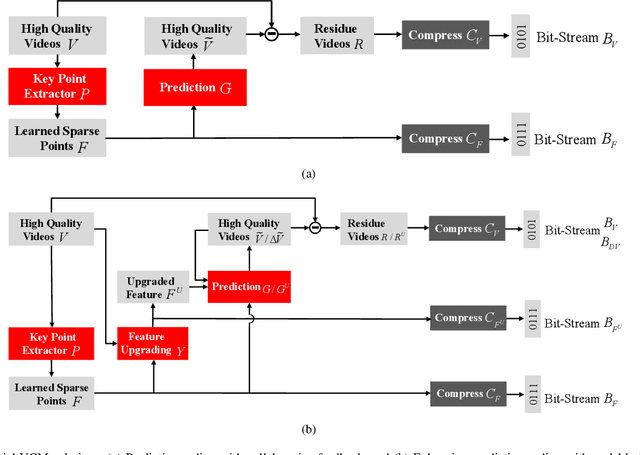

Video coding, which targets to compress and reconstruct the whole frame, and feature compression, which only preserves and transmits the most critical information, stand at two ends of the scale. That is, one is with compactness and efficiency to serve for machine vision, and the other is with full fidelity, bowing to human perception. The recent endeavors in imminent trends of video compression, e.g. deep learning based coding tools and end-to-end image/video coding, and MPEG-7 compact feature descriptor standards, i.e. Compact Descriptors for Visual Search and Compact Descriptors for Video Analysis, promote the sustainable and fast development in their own directions, respectively. In this paper, thanks to booming AI technology, e.g. prediction and generation models, we carry out exploration in the new area, Video Coding for Machines (VCM), arising from the emerging MPEG standardization efforts1. Towards collaborative compression and intelligent analytics, VCM attempts to bridge the gap between feature coding for machine vision and video coding for human vision. Aligning with the rising Analyze then Compress instance Digital Retina, the definition, formulation, and paradigm of VCM are given first. Meanwhile, we systematically review state-of-the-art techniques in video compression and feature compression from the unique perspective of MPEG standardization, which provides the academic and industrial evidence to realize the collaborative compression of video and feature streams in a broad range of AI applications. Finally, we come up with potential VCM solutions, and the preliminary results have demonstrated the performance and efficiency gains. Further direction is discussed as well.