 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombo of Thinking and Observing for Outside-Knowledge VQA
May 10, 2023



Outside-knowledge visual question answering is a challenging task that requires both the acquisition and the use of open-ended real-world knowledge. Some existing solutions draw external knowledge into the cross-modality space which overlooks the much vaster textual knowledge in natural-language space, while others transform the image into a text that further fuses with the textual knowledge into the natural-language space and completely abandons the use of visual features. In this paper, we are inspired to constrain the cross-modality space into the same space of natural-language space which makes the visual features preserved directly, and the model still benefits from the vast knowledge in natural-language space. To this end, we propose a novel framework consisting of a multimodal encoder, a textual encoder and an answer decoder. Such structure allows us to introduce more types of knowledge including explicit and implicit multimodal and textual knowledge. Extensive experiments validate the superiority of the proposed method which outperforms the state-of-the-art by 6.17% accuracy. We also conduct comprehensive ablations of each component, and systematically study the roles of varying types of knowledge. Codes and knowledge data can be found at https://github.com/PhoebusSi/Thinking-while-Observing.
Robust Neural Architecture Search
Apr 10, 2023



Neural Architectures Search (NAS) becomes more and more popular over these years. However, NAS-generated models tends to suffer greater vulnerability to various malicious attacks. Lots of robust NAS methods leverage adversarial training to enhance the robustness of NAS-generated models, however, they neglected the nature accuracy of NAS-generated models. In our paper, we propose a novel NAS method, Robust Neural Architecture Search (RNAS). To design a regularization term to balance accuracy and robustness, RNAS generates architectures with both high accuracy and good robustness. To reduce search cost, we further propose to use noise examples instead adversarial examples as input to search architectures. Extensive experiments show that RNAS achieves state-of-the-art (SOTA) performance on both image classification and adversarial attacks, which illustrates the proposed RNAS achieves a good tradeoff between robustness and accuracy.
Operation-level Progressive Differentiable Architecture Search
Feb 11, 2023Differentiable Neural Architecture Search (DARTS) is becoming more and more popular among Neural Architecture Search (NAS) methods because of its high search efficiency and low compute cost. However, the stability of DARTS is very inferior, especially skip connections aggregation that leads to performance collapse. Though existing methods leverage Hessian eigenvalues to alleviate skip connections aggregation, they make DARTS unable to explore architectures with better performance. In the paper, we propose operation-level progressive differentiable neural architecture search (OPP-DARTS) to avoid skip connections aggregation and explore better architectures simultaneously. We first divide the search process into several stages during the search phase and increase candidate operations into the search space progressively at the beginning of each stage. It can effectively alleviate the unfair competition between operations during the search phase of DARTS by offsetting the inherent unfair advantage of the skip connection over other operations. Besides, to keep the competition between operations relatively fair and select the operation from the candidate operations set that makes training loss of the supernet largest. The experiment results indicate that our method is effective and efficient. Our method's performance on CIFAR-10 is superior to the architecture found by standard DARTS, and the transferability of our method also surpasses standard DARTS. We further demonstrate the robustness of our method on three simple search spaces, i.e., S2, S3, S4, and the results show us that our method is more robust than standard DARTS. Our code is available at https://github.com/zxunyu/OPP-DARTS.
Improving Differentiable Architecture Search via Self-Distillation
Feb 11, 2023Differentiable Architecture Search (DARTS) is a simple yet efficient Neural Architecture Search (NAS) method. During the search stage, DARTS trains a supernet by jointly optimizing architecture parameters and network parameters. During the evaluation stage, DARTS derives the optimal architecture based on architecture parameters. However, the loss landscape of the supernet is not smooth, and it results in a performance gap between the supernet and the optimal architecture. In the paper, we propose Self-Distillation Differentiable Neural Architecture Search (SD-DARTS) by utilizing self-distillation to transfer knowledge of the supernet in previous steps to guide the training of the supernet in the current steps. SD-DARTS can minimize the loss difference for the two consecutive iterations so that minimize the sharpness of the supernet's loss to bridge the performance gap between the supernet and the optimal architecture. Furthermore, we propose voted teachers, which select multiple previous supernets as teachers and vote teacher output probabilities as the final teacher prediction. The knowledge of several teachers is more abundant than a single teacher, thus, voted teachers can be more suitable to lead the training of the supernet. Experimental results on real datasets illustrate the advantages of our novel self-distillation-based NAS method compared to state-of-the-art alternatives.
UATVR: Uncertainty-Adaptive Text-Video Retrieval
Jan 16, 2023With the explosive growth of web videos and emerging large-scale vision-language pre-training models, e.g., CLIP, retrieving videos of interest with text instructions has attracted increasing attention. A common practice is to transfer text-video pairs to the same embedding space and craft cross-modal interactions with certain entities in specific granularities for semantic correspondence. Unfortunately, the intrinsic uncertainties of optimal entity combinations in appropriate granularities for cross-modal queries are understudied, which is especially critical for modalities with hierarchical semantics, e.g., video, text, etc. In this paper, we propose an Uncertainty-Adaptive Text-Video Retrieval approach, termed UATVR, which models each look-up as a distribution matching procedure. Concretely, we add additional learnable tokens in the encoders to adaptively aggregate multi-grained semantics for flexible high-level reasoning. In the refined embedding space, we represent text-video pairs as probabilistic distributions where prototypes are sampled for matching evaluation. Comprehensive experiments on four benchmarks justify the superiority of our UATVR, which achieves new state-of-the-art results on MSR-VTT (50.8%), VATEX (64.5%), MSVD (49.7%), and DiDeMo (45.8%). The code is available in supplementary materials and will be released publicly soon.
Beyond Instance Discrimination: Relation-aware Contrastive Self-supervised Learning
Nov 02, 2022



Contrastive self-supervised learning (CSL) based on instance discrimination typically attracts positive samples while repelling negatives to learn representations with pre-defined binary self-supervision. However, vanilla CSL is inadequate in modeling sophisticated instance relations, limiting the learned model to retain fine semantic structure. On the one hand, samples with the same semantic category are inevitably pushed away as negatives. On the other hand, differences among samples cannot be captured. In this paper, we present relation-aware contrastive self-supervised learning (ReCo) to integrate instance relations, i.e., global distribution relation and local interpolation relation, into the CSL framework in a plug-and-play fashion. Specifically, we align similarity distributions calculated between the positive anchor views and the negatives at the global level to exploit diverse similarity relations among instances. Local-level interpolation consistency between the pixel space and the feature space is applied to quantitatively model the feature differences of samples with distinct apparent similarities. Through explicitly instance relation modeling, our ReCo avoids irrationally pushing away semantically identical samples and carves a well-structured feature space. Extensive experiments conducted on commonly used benchmarks justify that our ReCo consistently gains remarkable performance improvements.
COST-EFF: Collaborative Optimization of Spatial and Temporal Efficiency with Slenderized Multi-exit Language Models
Oct 27, 2022Transformer-based pre-trained language models (PLMs) mostly suffer from excessive overhead despite their advanced capacity. For resource-constrained devices, there is an urgent need for a spatially and temporally efficient model which retains the major capacity of PLMs. However, existing statically compressed models are unaware of the diverse complexities between input instances, potentially resulting in redundancy and inadequacy for simple and complex inputs. Also, miniature models with early exiting encounter challenges in the trade-off between making predictions and serving the deeper layers. Motivated by such considerations, we propose a collaborative optimization for PLMs that integrates static model compression and dynamic inference acceleration. Specifically, the PLM is slenderized in width while the depth remains intact, complementing layer-wise early exiting to speed up inference dynamically. To address the trade-off of early exiting, we propose a joint training approach that calibrates slenderization and preserves contributive structures to each exit instead of only the final layer. Experiments are conducted on GLUE benchmark and the results verify the Pareto optimality of our approach at high compression and acceleration rate with 1/8 parameters and 1/19 FLOPs of BERT.
Question-Interlocutor Scope Realized Graph Modeling over Key Utterances for Dialogue Reading Comprehension
Oct 26, 2022



In this work, we focus on dialogue reading comprehension (DRC), a task extracting answer spans for questions from dialogues. Dialogue context modeling in DRC is tricky due to complex speaker information and noisy dialogue context. To solve the two problems, previous research proposes two self-supervised tasks respectively: guessing who a randomly masked speaker is according to the dialogue and predicting which utterance in the dialogue contains the answer. Although these tasks are effective, there are still urging problems: (1) randomly masking speakers regardless of the question cannot map the speaker mentioned in the question to the corresponding speaker in the dialogue, and ignores the speaker-centric nature of utterances. This leads to wrong answer extraction from utterances in unrelated interlocutors' scopes; (2) the single utterance prediction, preferring utterances similar to the question, is limited in finding answer-contained utterances not similar to the question. To alleviate these problems, we first propose a new key utterances extracting method. It performs prediction on the unit formed by several contiguous utterances, which can realize more answer-contained utterances. Based on utterances in the extracted units, we then propose Question-Interlocutor Scope Realized Graph (QuISG) modeling. As a graph constructed on the text of utterances, QuISG additionally involves the question and question-mentioning speaker names as nodes. To realize interlocutor scopes, speakers in the dialogue are connected with the words in their corresponding utterances. Experiments on the benchmarks show that our method can achieve better and competitive results against previous works.
Compressing And Debiasing Vision-Language Pre-Trained Models for Visual Question Answering
Oct 26, 2022Despite the excellent performance of large-scale vision-language pre-trained models (VLPs) on conventional visual question answering task, they still suffer from two problems: First, VLPs tend to rely on language biases in datasets and fail to generalize to out-of-distribution (OOD) data. Second, they are inefficient in terms of memory footprint and computation. Although promising progress has been made in both problems, most existing works tackle them independently. To facilitate the application of VLP to VQA tasks, it is imperative to jointly study VLP compression and OOD robustness, which, however, has not yet been explored. In this paper, we investigate whether a VLP can be compressed and debiased simultaneously by searching sparse and robust subnetworks. To this end, we conduct extensive experiments with LXMERT, a representative VLP, on the OOD dataset VQA-CP v2. We systematically study the design of a training and compression pipeline to search the subnetworks, as well as the assignment of sparsity to different modality-specific modules. Our results show that there indeed exist sparse and robust LXMERT subnetworks, which significantly outperform the full model (without debiasing) with much fewer parameters. These subnetworks also exceed the current SoTA debiasing models with comparable or fewer parameters. We will release the codes on publication.
Joint Plasticity Learning for Camera Incremental Person Re-Identification
Oct 18, 2022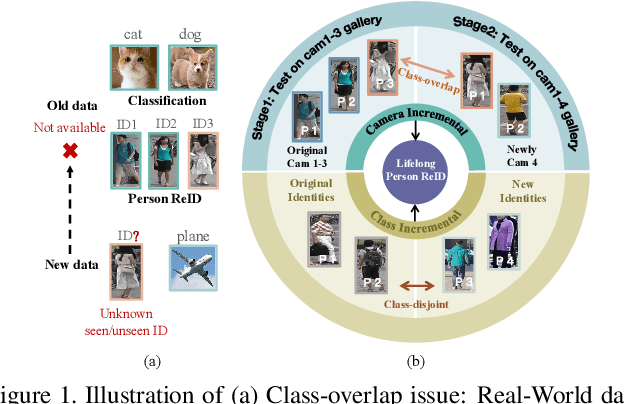

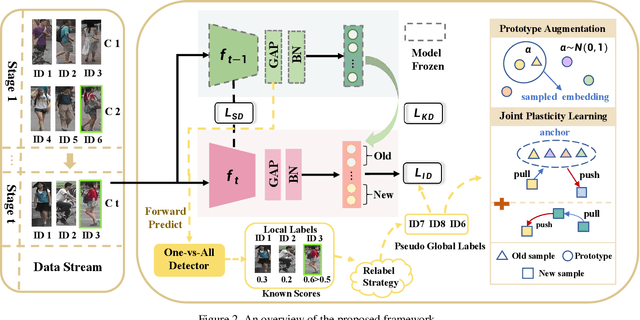
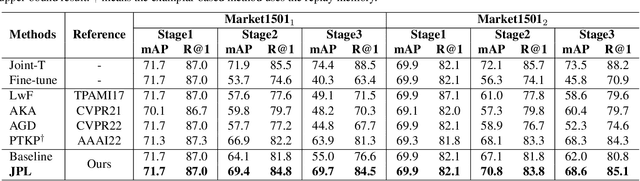
Recently, incremental learning for person re-identification receives increasing attention, which is considered a more practical setting in real-world applications. However, the existing works make the strong assumption that the cameras are fixed and the new-emerging data is class-disjoint from previous classes. In this paper, we focus on a new and more practical task, namely Camera Incremental person ReID (CIP-ReID). CIP-ReID requires ReID models to continuously learn informative representations without forgetting the previously learned ones only through the data from newly installed cameras. This is challenging as the new data only have local supervision in new cameras with no access to the old data due to privacy issues, and they may also contain persons seen by previous cameras. To address this problem, we propose a non-exemplar-based framework, named JPL-ReID. JPL-ReID first adopts a one-vs-all detector to discover persons who have been presented in previous cameras. To maintain learned representations, JPL-ReID utilizes a similarity distillation strategy with no previous training data available. Simultaneously, JPL-ReID is capable of learning new knowledge to improve the generalization ability using a Joint Plasticity Learning objective. The comprehensive experimental results on two datasets demonstrate that our proposed method significantly outperforms the comparative methods and can achieve state-of-the-art results with remarkable advantages.