 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Complementarity between Pre-Training and Random-Initialization for Resource-Rich Machine Translation
Sep 15, 2022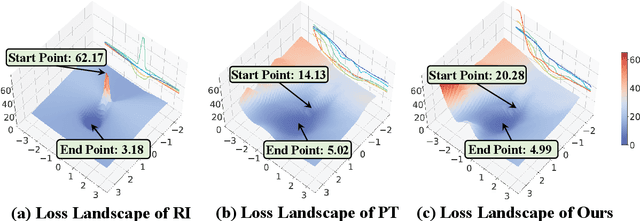
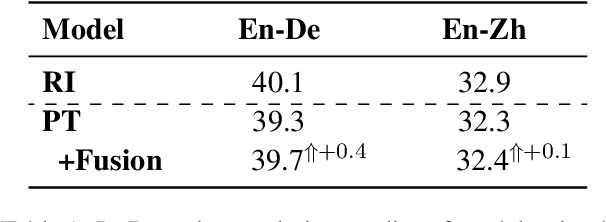
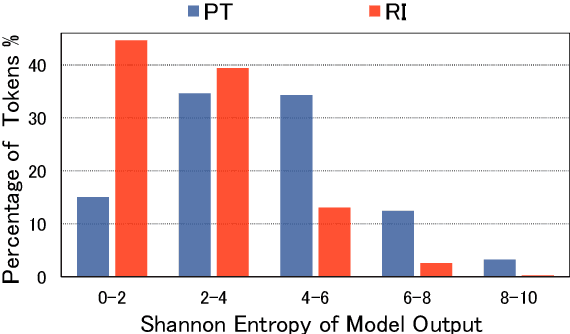
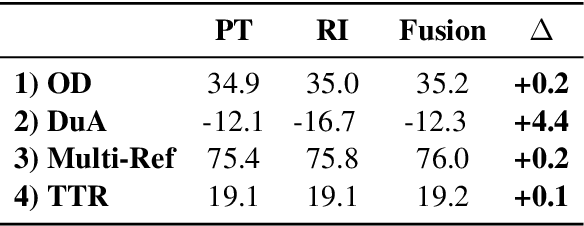
Pre-Training (PT) of text representations has been successfully applied to low-resource Neural Machine Translation (NMT). However, it usually fails to achieve notable gains (sometimes, even worse) on resource-rich NMT on par with its Random-Initialization (RI) counterpart. We take the first step to investigate the complementarity between PT and RI in resource-rich scenarios via two probing analyses, and find that: 1) PT improves NOT the accuracy, but the generalization by achieving flatter loss landscapes than that of RI; 2) PT improves NOT the confidence of lexical choice, but the negative diversity by assigning smoother lexical probability distributions than that of RI. Based on these insights, we propose to combine their complementarities with a model fusion algorithm that utilizes optimal transport to align neurons between PT and RI. Experiments on two resource-rich translation benchmarks, WMT'17 English-Chinese (20M) and WMT'19 English-German (36M), show that PT and RI could be nicely complementary to each other, achieving substantial improvements considering both translation accuracy, generalization, and negative diversity. Probing tools and code are released at: https://github.com/zanchangtong/PTvsRI.
Bridging Cross-Lingual Gaps During Leveraging the Multilingual Sequence-to-Sequence Pretraining for Text Generation
Apr 16, 2022
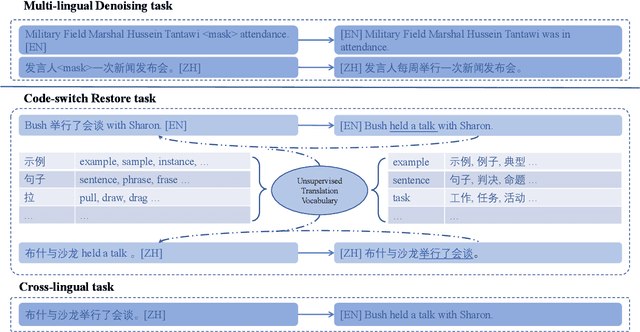
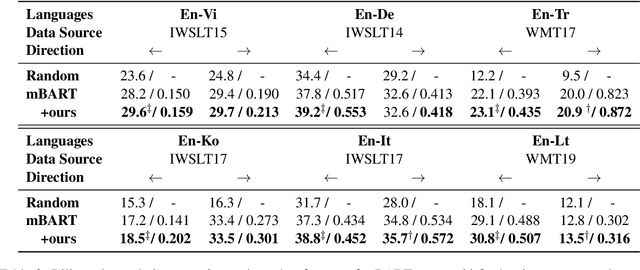
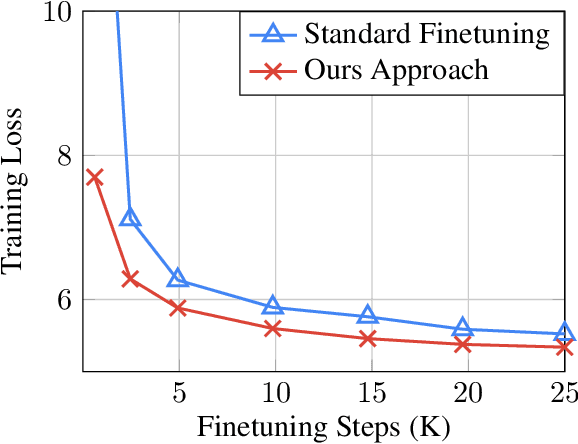
For multilingual sequence-to-sequence pretrained language models (multilingual Seq2Seq PLMs), e.g. mBART, the self-supervised pretraining task is trained on a wide range of monolingual languages, e.g. 25 languages from commoncrawl, while the downstream cross-lingual tasks generally progress on a bilingual language subset, e.g. English-German, making there exists the cross-lingual data discrepancy, namely \textit{domain discrepancy}, and cross-lingual learning objective discrepancy, namely \textit{task discrepancy}, between the pretrain and finetune stages. To bridge the above cross-lingual domain and task gaps, we extend the vanilla pretrain-finetune pipeline with extra code-switching restore task. Specifically, the first stage employs the self-supervised code-switching restore task as a pretext task, allowing the multilingual Seq2Seq PLM to acquire some in-domain alignment information. And for the second stage, we continuously fine-tune the model on labeled data normally. Experiments on a variety of cross-lingual NLG tasks, including 12 bilingual translation tasks, 36 zero-shot translation tasks, and cross-lingual summarization tasks show our model outperforms the strong baseline mBART consistently. Comprehensive analyses indicate our approach could narrow the cross-lingual sentence representation distance and improve low-frequency word translation with trivial computational cost.
Selecting task with optimal transport self-supervised learning for few-shot classification
Apr 01, 2022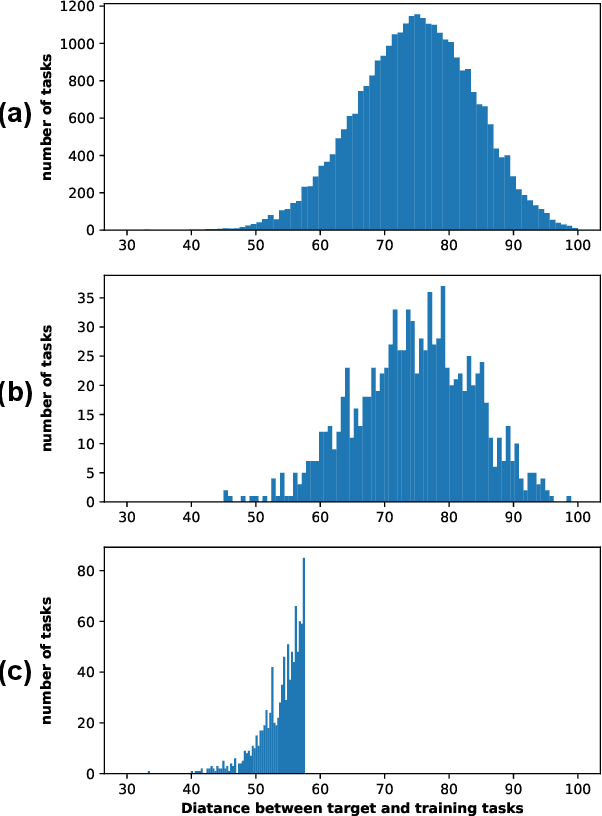
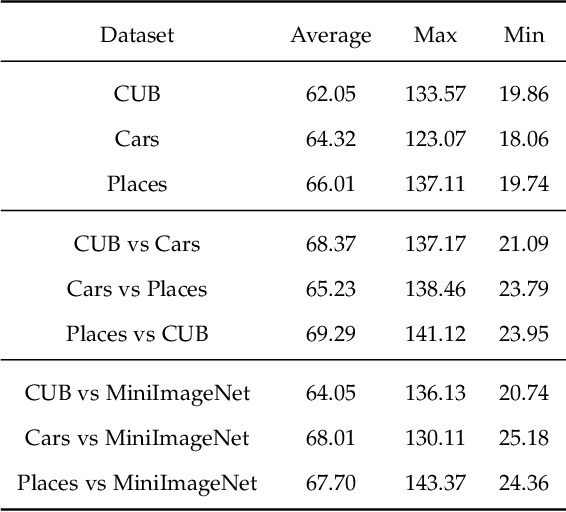


Few-Shot classification aims at solving problems that only a few samples are available in the training process. Due to the lack of samples, researchers generally employ a set of training tasks from other domains to assist the target task, where the distribution between assistant tasks and the target task is usually different. To reduce the distribution gap, several lines of methods have been proposed, such as data augmentation and domain alignment. However, one common drawback of these algorithms is that they ignore the similarity task selection before training. The fundamental problem is to push the auxiliary tasks close to the target task. In this paper, we propose a novel task selecting algorithm, named Optimal Transport Task Selecting (OTTS), to construct a training set by selecting similar tasks for Few-Shot learning. Specifically, the OTTS measures the task similarity by calculating the optimal transport distance and completes the model training via a self-supervised strategy. By utilizing the selected tasks with OTTS, the training process of Few-Shot learning become more stable and effective. Other proposed methods including data augmentation and domain alignment can be used in the meantime with OTTS. We conduct extensive experiments on a variety of datasets, including MiniImageNet, CIFAR, CUB, Cars, and Places, to evaluate the effectiveness of OTTS. Experimental results validate that our OTTS outperforms the typical baselines, i.e., MAML, matchingnet, protonet, by a large margin (averagely 1.72\% accuracy improvement).
CSN: Component-Supervised Network for Few-Shot Classification
Mar 15, 2022
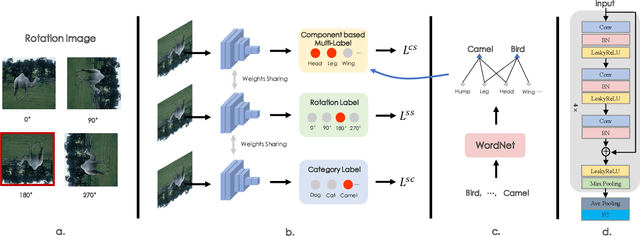

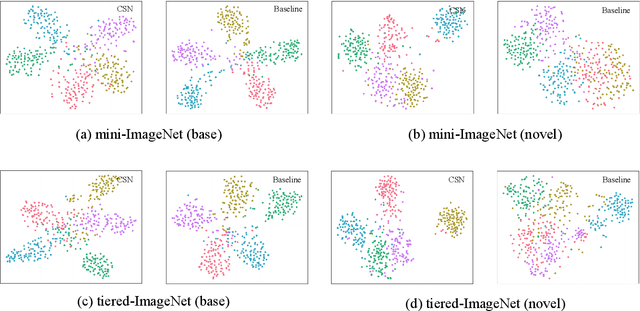
The few-shot classification (FSC) task has been a hot research topic in recent years. It aims to address the classification problem with insufficient labeled data on a cross-category basis. Typically, researchers pre-train a feature extractor with base data, then use it to extract the features of novel data and recognize them. Notably, the novel set only has a few annotated samples and has entirely different categories from the base set, which leads to that the pre-trained feature extractor can not adapt to the novel data flawlessly. We dub this problem as Feature-Extractor-Maladaptive (FEM) problem. Starting from the root cause of this problem, this paper presents a new scheme, Component-Supervised Network (CSN), to improve the performance of FSC. We believe that although the categories of base and novel sets are different, the composition of the sample's components is similar. For example, both cat and dog contain leg and head components. Actually, such entity components are intra-class stable. They have fine cross-category versatility and new category generalization. Therefore, we refer to WordNet, a dictionary commonly used in natural language processing, to collect component information of samples and construct a component-based auxiliary task to improve the adaptability of the feature extractor. We conduct experiments on two benchmark datasets (mini-ImageNet and tiered-ImageNet), the improvements of $0.9\%$-$5.8\%$ compared with state-of-the-arts have evaluated the efficiency of our CSN.
Where Does the Performance Improvement Come From? - A Reproducibility Concern about Image-Text Retrieval
Mar 08, 2022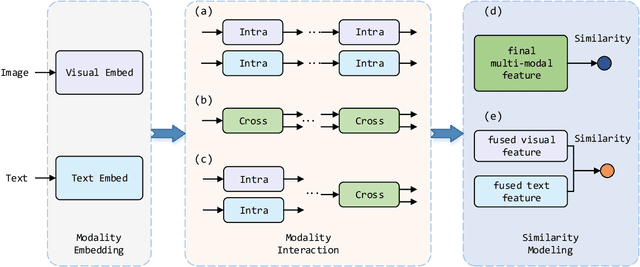
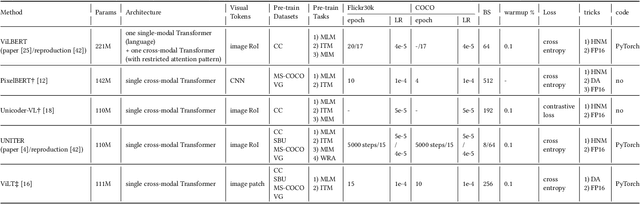
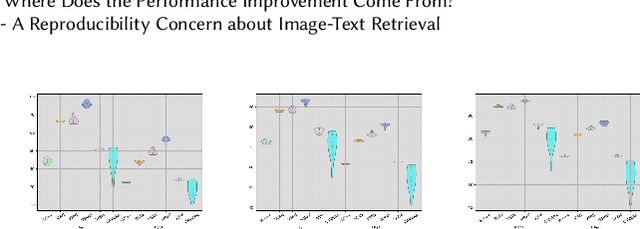
This paper seeks to provide the information retrieval community with some reflections on the current improvements of retrieval learning through the analysis of the reproducibility aspects of image-text retrieval models. For the latter part of the past decade, image-text retrieval has gradually become a major research direction in the field of information retrieval because of the growth of multi-modal data. Many researchers use benchmark datasets like MS-COCO and Flickr30k to train and assess the performance of image-text retrieval algorithms. Research in the past has mostly focused on performance, with several state-of-the-art methods being proposed in various ways. According to their claims, these approaches achieve better modal interactions and thus better multimodal representations with greater precision. In contrast to those previous works, we focus on the repeatability of the approaches and the overall examination of the elements that lead to improved performance by pretrained and nonpretrained models in retrieving images and text. To be more specific, we first examine the related reproducibility concerns and why the focus is on image-text retrieval tasks, and then we systematically summarize the current paradigm of image-text retrieval models and the stated contributions of those approaches. Second, we analyze various aspects of the reproduction of pretrained and nonpretrained retrieval models. Based on this, we conducted ablation experiments and obtained some influencing factors that affect retrieval recall more than the improvement claimed in the original paper. Finally, we also present some reflections and issues that should be considered by the retrieval community in the future. Our code is freely available at https://github.com/WangFei-2019/Image-text-Retrieval.
MDFM: Multi-Decision Fusing Model for Few-Shot Learning
Dec 03, 2021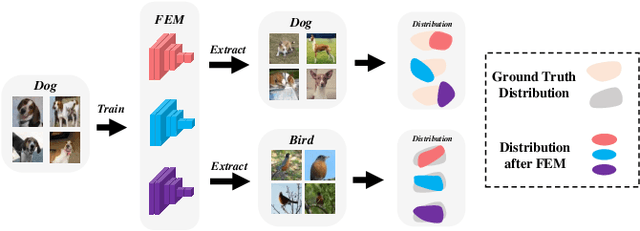
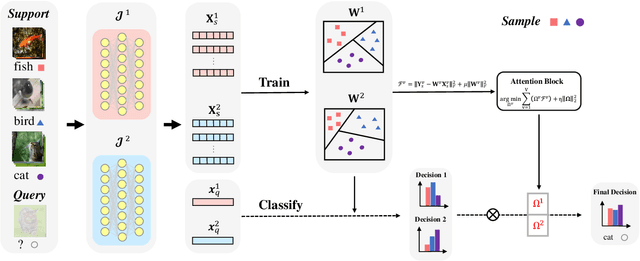
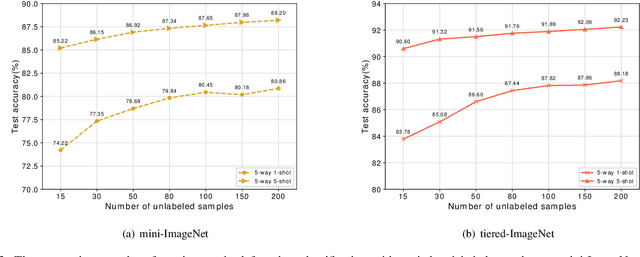
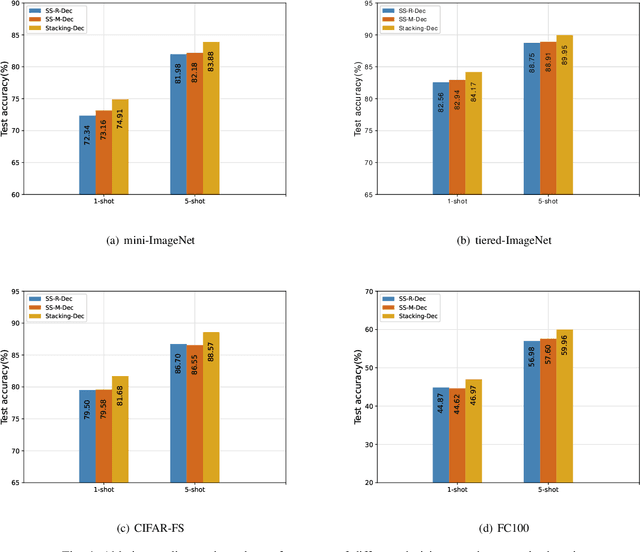
In recent years, researchers pay growing attention to the few-shot learning (FSL) task to address the data-scarce problem. A standard FSL framework is composed of two components: i) Pre-train. Employ the base data to generate a CNN-based feature extraction model (FEM). ii) Meta-test. Apply the trained FEM to the novel data (category is different from base data) to acquire the feature embeddings and recognize them. Although researchers have made remarkable breakthroughs in FSL, there still exists a fundamental problem. Since the trained FEM with base data usually cannot adapt to the novel class flawlessly, the novel data's feature may lead to the distribution shift problem. To address this challenge, we hypothesize that even if most of the decisions based on different FEMs are viewed as weak decisions, which are not available for all classes, they still perform decently in some specific categories. Inspired by this assumption, we propose a novel method Multi-Decision Fusing Model (MDFM), which comprehensively considers the decisions based on multiple FEMs to enhance the efficacy and robustness of the model. MDFM is a simple, flexible, non-parametric method that can directly apply to the existing FEMs. Besides, we extend the proposed MDFM to two FSL settings (i.e., supervised and semi-supervised settings). We evaluate the proposed method on five benchmark datasets and achieve significant improvements of 3.4%-7.3% compared with state-of-the-arts.
Semantic-Preserving Adversarial Text Attacks
Aug 23, 2021
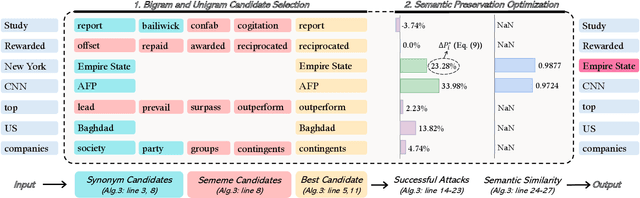
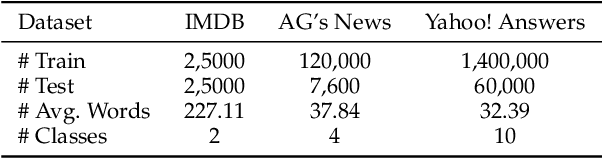
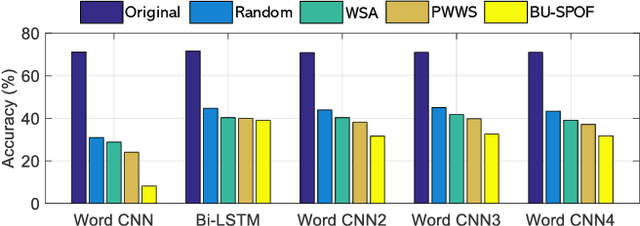
Deep neural networks (DNNs) are known to be vulnerable to adversarial images, while their robustness in text classification is rarely studied. Several lines of text attack methods have been proposed in the literature, including character-level, word-level, and sentence-level attacks. However, it is still a challenge to minimize the number of word changes necessary to induce misclassification, while simultaneously ensuring lexical correctness, syntactic soundness, and semantic similarity. In this paper, we propose a Bigram and Unigram based adaptive Semantic Preservation Optimization (BU-SPO) method to examine the vulnerability of deep models. Our method has four major merits. Firstly, we propose to attack text documents not only at the unigram word level but also at the bigram level which better keeps semantics and avoids producing meaningless outputs. Secondly, we propose a hybrid method to replace the input words with options among both their synonyms candidates and sememe candidates, which greatly enriches the potential substitutions compared to only using synonyms. Thirdly, we design an optimization algorithm, i.e., Semantic Preservation Optimization (SPO), to determine the priority of word replacements, aiming to reduce the modification cost. Finally, we further improve the SPO with a semantic Filter (named SPOF) to find the adversarial example with the highest semantic similarity. We evaluate the effectiveness of our BU-SPO and BU-SPOF on IMDB, AG's News, and Yahoo! Answers text datasets by attacking four popular DNNs models. Results show that our methods achieve the highest attack success rates and semantics rates by changing the smallest number of words compared with existing methods.
Hazy Re-ID: An Interference Suppression Model For Domain Adaptation Person Re-identification Under Inclement Weather Condition
Apr 22, 2021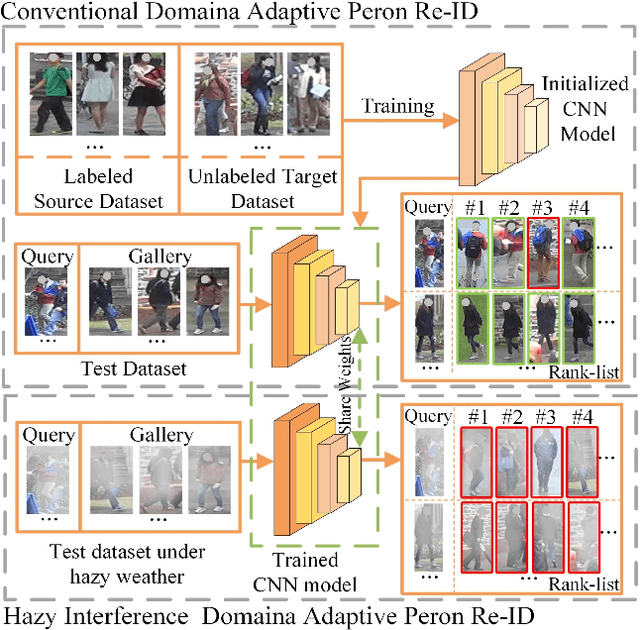
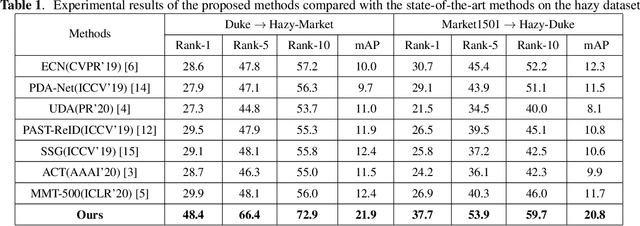
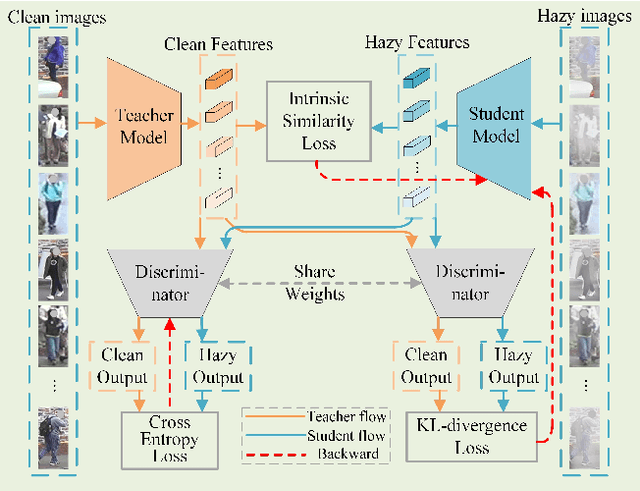
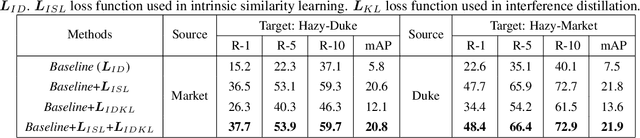
In a conventional domain adaptation person Re-identification (Re-ID) task, both the training and test images in target domain are collected under the sunny weather. However, in reality, the pedestrians to be retrieved may be obtained under severe weather conditions such as hazy, dusty and snowing, etc. This paper proposes a novel Interference Suppression Model (ISM) to deal with the interference caused by the hazy weather in domain adaptation person Re-ID. A teacherstudent model is used in the ISM to distill the interference information at the feature level by reducing the discrepancy between the clear and the hazy intrinsic similarity matrix. Furthermore, in the distribution level, the extra discriminator is introduced to assist the student model make the interference feature distribution more clear. The experimental results show that the proposed method achieves the superior performance on two synthetic datasets than the stateof-the-art methods. The related code will be released online https://github.com/pangjian123/ISM-ReID.
Answer Questions with Right Image Regions: A Visual Attention Regularization Approach
Feb 03, 2021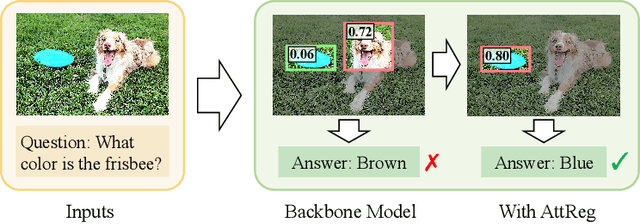
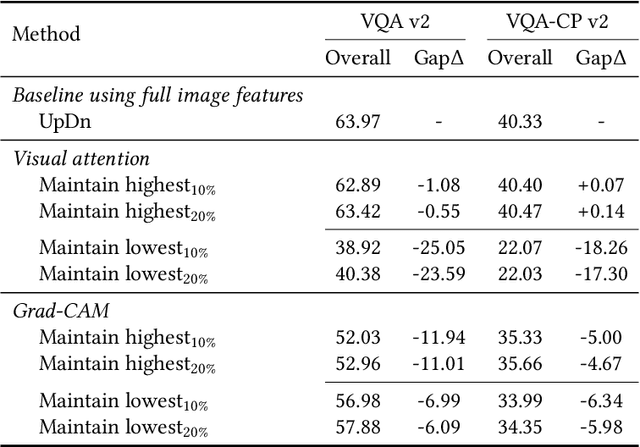
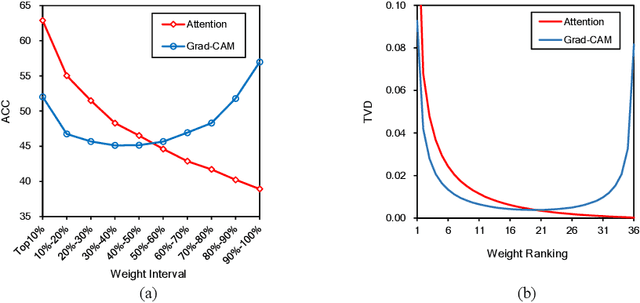
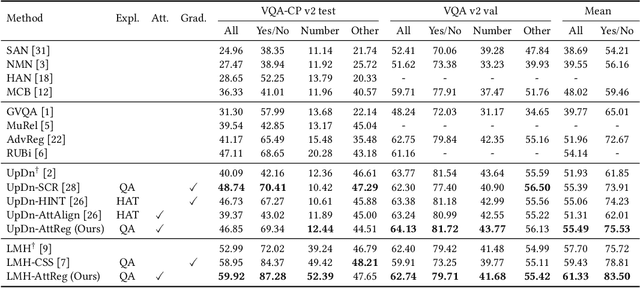
Visual attention in Visual Question Answering (VQA) targets at locating the right image regions regarding the answer prediction. However, recent studies have pointed out that the highlighted image regions from the visual attention are often irrelevant to the given question and answer, leading to model confusion for correct visual reasoning. To tackle this problem, existing methods mostly resort to aligning the visual attention weights with human attentions. Nevertheless, gathering such human data is laborious and expensive, making it burdensome to adapt well-developed models across datasets. To address this issue, in this paper, we devise a novel visual attention regularization approach, namely AttReg, for better visual grounding in VQA. Specifically, AttReg firstly identifies the image regions which are essential for question answering yet unexpectedly ignored (i.e., assigned with low attention weights) by the backbone model. And then a mask-guided learning scheme is leveraged to regularize the visual attention to focus more on these ignored key regions. The proposed method is very flexible and model-agnostic, which can be integrated into most visual attention-based VQA models and require no human attention supervision. Extensive experiments over three benchmark datasets, i.e., VQA-CP v2, VQA-CP v1, and VQA v2, have been conducted to evaluate the effectiveness of AttReg. As a by-product, when incorporating AttReg into the strong baseline LMH, our approach can achieve a new state-of-the-art accuracy of 59.92% with an absolute performance gain of 6.93% on the VQA-CP v2 benchmark dataset. In addition to the effectiveness validation, we recognize that the faithfulness of the visual attention in VQA has not been well explored in literature. In the light of this, we propose to empirically validate such property of visual attention and compare it with the prevalent gradient-based approaches.
SAHDL: Sparse Attention Hypergraph Regularized Dictionary Learning
Oct 23, 2020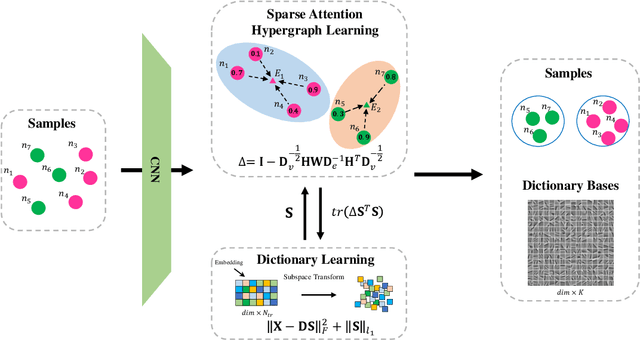
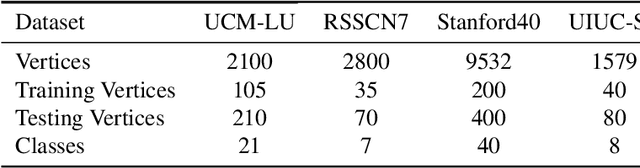
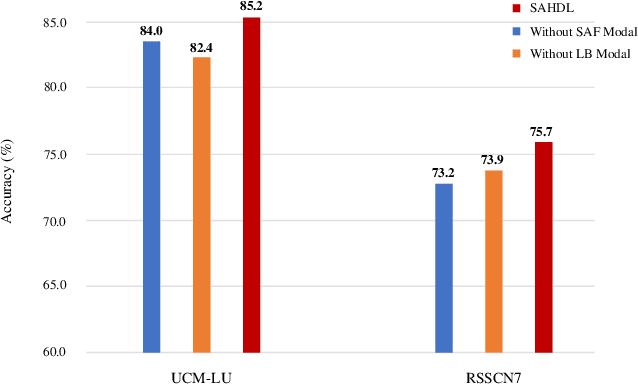
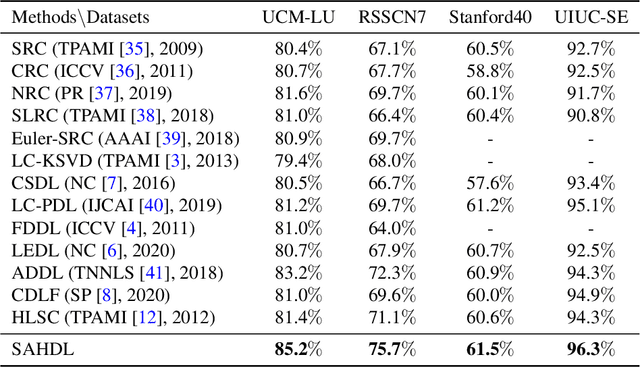
In recent years, the attention mechanism contributes significantly to hypergraph based neural networks. However, these methods update the attention weights with the network propagating. That is to say, this type of attention mechanism is only suitable for deep learning-based methods while not applicable to the traditional machine learning approaches. In this paper, we propose a hypergraph based sparse attention mechanism to tackle this issue and embed it into dictionary learning. More specifically, we first construct a sparse attention hypergraph, asset attention weights to samples by employing the $\ell_1$-norm sparse regularization to mine the high-order relationship among sample features. Then, we introduce the hypergraph Laplacian operator to preserve the local structure for subspace transformation in dictionary learning. Besides, we incorporate the discriminative information into the hypergraph as the guidance to aggregate samples. Unlike previous works, our method updates attention weights independently, does not rely on the deep network. We demonstrate the efficacy of our approach on four benchmark datasets.