 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Prompt vs. Image Enhancement: Boosting Object Detection With CLIP in Hazy Environments
Apr 12, 2026Object detection in hazy environments is challenging because degraded objects are nearly invisible and their semantics are weakened by environmental noise, making it difficult for detectors to identify. Common approaches involve image enhancement to boost weakened semantics, but these methods are limited by the instability of enhanced modules. This paper proposes a novel solution by employing language prompts to enhance weakened semantics without image enhancement. Specifically, we design Approximation of Mutual Exclusion (AME) to provide credible weights for Cross-Entropy Loss, resulting in CLIP-guided Cross-Entropy Loss (CLIP-CE). The provided weights assess the semantic weakening of objects. Through the backpropagation of CLIP-CE, weakened semantics are enhanced, making degraded objects easier to detect. In addition, we present Fine-tuned AME (FAME) which adaptively fine-tunes the weight of AME based on the predicted confidence. The proposed FAME compensates for the imbalanced optimization in AME. Furthermore, we present HazyCOCO, a large-scale synthetic hazy dataset comprising 61258 images. Experimental results demonstrate that our method achieves state-of-the-art performance. The code and dataset will be released.
Unbiased Semantic Decoding with Vision Foundation Models for Few-shot Segmentation
Nov 19, 2025Few-shot segmentation has garnered significant attention. Many recent approaches attempt to introduce the Segment Anything Model (SAM) to handle this task. With the strong generalization ability and rich object-specific extraction ability of the SAM model, such a solution shows great potential in few-shot segmentation. However, the decoding process of SAM highly relies on accurate and explicit prompts, making previous approaches mainly focus on extracting prompts from the support set, which is insufficient to activate the generalization ability of SAM, and this design is easy to result in a biased decoding process when adapting to the unknown classes. In this work, we propose an Unbiased Semantic Decoding (USD) strategy integrated with SAM, which extracts target information from both the support and query set simultaneously to perform consistent predictions guided by the semantics of the Contrastive Language-Image Pre-training (CLIP) model. Specifically, to enhance the unbiased semantic discrimination of SAM, we design two feature enhancement strategies that leverage the semantic alignment capability of CLIP to enrich the original SAM features, mainly including a global supplement at the image level to provide a generalize category indicate with support image and a local guidance at the pixel level to provide a useful target location with query image. Besides, to generate target-focused prompt embeddings, a learnable visual-text target prompt generator is proposed by interacting target text embeddings and clip visual features. Without requiring re-training of the vision foundation models, the features with semantic discrimination draw attention to the target region through the guidance of prompt with rich target information.
A 24-GHz CMOS Transformer-Based Three-Tline Series Doherty Power Amplifier Achieving 39% PAE
Nov 15, 2025



This paper presents a transformer-based three- transmission-line (Tline) series Doherty power amplifier (PA) implemented in 65-nm CMOS, targeting broadband K/Ka-band applications. By integrating an impedance-scaling network into the output matching structure, the design enables effective load modulation and reduced impedance transformation ratio (ITR) at power back-off when employing stacked cascode transistors. The PA demonstrates a -3-dB small-signal gain bandwidth from 22 to 32.5 GHz, a saturated output power (Psat) of 21.6 dBm, and a peak power-added efficiency (PAE) of 39%. At 6dB back-off, the PAE remains above 24%, validating its suitability for high- efficiency mm-wave phased-array transmitters in next-generation wireless systems.
An Area-Efficient 20-100-GHz Phase-Invariant Switch-Type Attenuator Achieving 0.1-dB Tuning Step in 65-nm CMOS
Nov 06, 2025This paper presents a switch-type attenuator working from 20 to 100 GHz. The attenuator adopts a capacitive compensation technique to reduce phase error. The small resistors in this work are implemented with metal lines to reduce the intrinsic parasitic capacitance, which helps minimize the amplitude and phase errors over a wide frequency range. Moreover, the utilization of metal lines also reduces the chip area. In addition, a continuous tuning attenuation unit is employed to improve the overall attenuation accuracy of the attenuator. The passive attenuator is designed and fabricated in a standard 65nm CMOS. The measurement results reveal a relative attenuation range of 7.5 dB with a continuous tuning step within 20-100 GHz. The insertion loss is 1.6-3.8 dB within the operation band, while the return losses of all states are better than 11.5 dB. The RMS amplitude and phase errors are below 0.15 dB and 1.6{\deg}, respectively.
A Training-free Synthetic Data Selection Method for Semantic Segmentation
Jan 25, 2025



Training semantic segmenter with synthetic data has been attracting great attention due to its easy accessibility and huge quantities. Most previous methods focused on producing large-scale synthetic image-annotation samples and then training the segmenter with all of them. However, such a solution remains a main challenge in that the poor-quality samples are unavoidable, and using them to train the model will damage the training process. In this paper, we propose a training-free Synthetic Data Selection (SDS) strategy with CLIP to select high-quality samples for building a reliable synthetic dataset. Specifically, given massive synthetic image-annotation pairs, we first design a Perturbation-based CLIP Similarity (PCS) to measure the reliability of synthetic image, thus removing samples with low-quality images. Then we propose a class-balance Annotation Similarity Filter (ASF) by comparing the synthetic annotation with the response of CLIP to remove the samples related to low-quality annotations. The experimental results show that using our method significantly reduces the data size by half, while the trained segmenter achieves higher performance. The code is released at https://github.com/tanghao2000/SDS.
Rethinking Prior Information Generation with CLIP for Few-Shot Segmentation
May 14, 2024Few-shot segmentation remains challenging due to the limitations of its labeling information for unseen classes. Most previous approaches rely on extracting high-level feature maps from the frozen visual encoder to compute the pixel-wise similarity as a key prior guidance for the decoder. However, such a prior representation suffers from coarse granularity and poor generalization to new classes since these high-level feature maps have obvious category bias. In this work, we propose to replace the visual prior representation with the visual-text alignment capacity to capture more reliable guidance and enhance the model generalization. Specifically, we design two kinds of training-free prior information generation strategy that attempts to utilize the semantic alignment capability of the Contrastive Language-Image Pre-training model (CLIP) to locate the target class. Besides, to acquire more accurate prior guidance, we build a high-order relationship of attention maps and utilize it to refine the initial prior information. Experiments on both the PASCAL-5{i} and COCO-20{i} datasets show that our method obtains a clearly substantial improvement and reaches the new state-of-the-art performance.
Adaptive Bidirectional Displacement for Semi-Supervised Medical Image Segmentation
May 01, 2024



Consistency learning is a central strategy to tackle unlabeled data in semi-supervised medical image segmentation (SSMIS), which enforces the model to produce consistent predictions under the perturbation. However, most current approaches solely focus on utilizing a specific single perturbation, which can only cope with limited cases, while employing multiple perturbations simultaneously is hard to guarantee the quality of consistency learning. In this paper, we propose an Adaptive Bidirectional Displacement (ABD) approach to solve the above challenge. Specifically, we first design a bidirectional patch displacement based on reliable prediction confidence for unlabeled data to generate new samples, which can effectively suppress uncontrollable regions and still retain the influence of input perturbations. Meanwhile, to enforce the model to learn the potentially uncontrollable content, a bidirectional displacement operation with inverse confidence is proposed for the labeled images, which generates samples with more unreliable information to facilitate model learning. Extensive experiments show that ABD achieves new state-of-the-art performances for SSMIS, significantly improving different baselines. Source code is available at https://github.com/chy-upc/ABD.
Hazy Re-ID: An Interference Suppression Model For Domain Adaptation Person Re-identification Under Inclement Weather Condition
Apr 22, 2021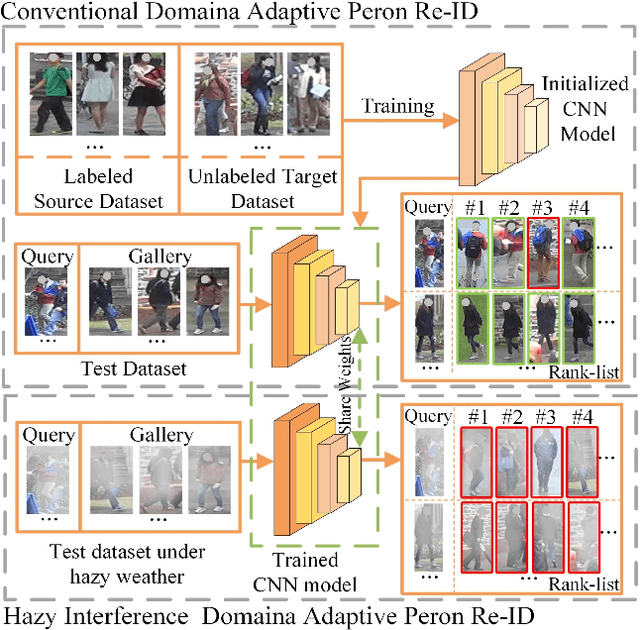
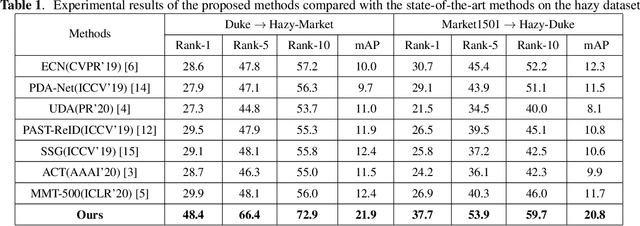
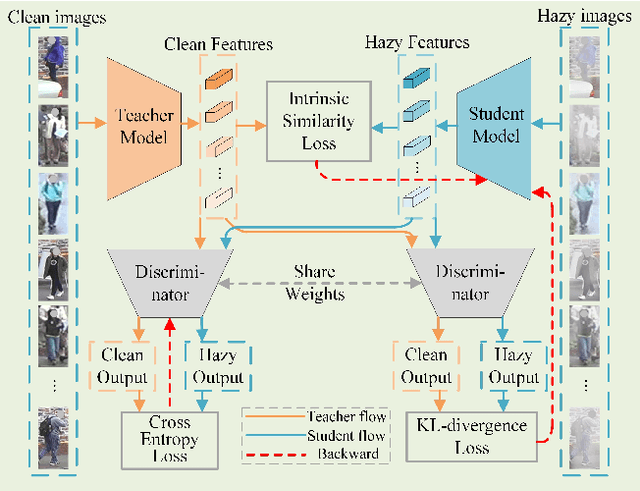
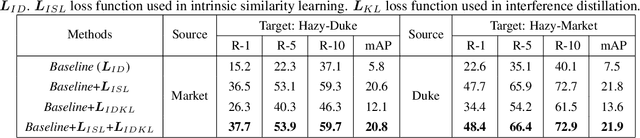
In a conventional domain adaptation person Re-identification (Re-ID) task, both the training and test images in target domain are collected under the sunny weather. However, in reality, the pedestrians to be retrieved may be obtained under severe weather conditions such as hazy, dusty and snowing, etc. This paper proposes a novel Interference Suppression Model (ISM) to deal with the interference caused by the hazy weather in domain adaptation person Re-ID. A teacherstudent model is used in the ISM to distill the interference information at the feature level by reducing the discrepancy between the clear and the hazy intrinsic similarity matrix. Furthermore, in the distribution level, the extra discriminator is introduced to assist the student model make the interference feature distribution more clear. The experimental results show that the proposed method achieves the superior performance on two synthetic datasets than the stateof-the-art methods. The related code will be released online https://github.com/pangjian123/ISM-ReID.