 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptively Distilled ControlNet: Accelerated Training and Superior Sampling for Medical Image Synthesis
Jul 31, 2025Medical image annotation is constrained by privacy concerns and labor-intensive labeling, significantly limiting the performance and generalization of segmentation models. While mask-controllable diffusion models excel in synthesis, they struggle with precise lesion-mask alignment. We propose \textbf{Adaptively Distilled ControlNet}, a task-agnostic framework that accelerates training and optimization through dual-model distillation. Specifically, during training, a teacher model, conditioned on mask-image pairs, regularizes a mask-only student model via predicted noise alignment in parameter space, further enhanced by adaptive regularization based on lesion-background ratios. During sampling, only the student model is used, enabling privacy-preserving medical image generation. Comprehensive evaluations on two distinct medical datasets demonstrate state-of-the-art performance: TransUNet improves mDice/mIoU by 2.4%/4.2% on KiTS19, while SANet achieves 2.6%/3.5% gains on Polyps, highlighting its effectiveness and superiority. Code is available at GitHub.
Noise-Consistent Siamese-Diffusion for Medical Image Synthesis and Segmentation
May 09, 2025Deep learning has revolutionized medical image segmentation, yet its full potential remains constrained by the paucity of annotated datasets. While diffusion models have emerged as a promising approach for generating synthetic image-mask pairs to augment these datasets, they paradoxically suffer from the same data scarcity challenges they aim to mitigate. Traditional mask-only models frequently yield low-fidelity images due to their inability to adequately capture morphological intricacies, which can critically compromise the robustness and reliability of segmentation models. To alleviate this limitation, we introduce Siamese-Diffusion, a novel dual-component model comprising Mask-Diffusion and Image-Diffusion. During training, a Noise Consistency Loss is introduced between these components to enhance the morphological fidelity of Mask-Diffusion in the parameter space. During sampling, only Mask-Diffusion is used, ensuring diversity and scalability. Comprehensive experiments demonstrate the superiority of our method. Siamese-Diffusion boosts SANet's mDice and mIoU by 3.6% and 4.4% on the Polyps, while UNet improves by 1.52% and 1.64% on the ISIC2018. Code is available at GitHub.
Learn From Zoom: Decoupled Supervised Contrastive Learning For WCE Image Classification
Jan 11, 2024



Accurate lesion classification in Wireless Capsule Endoscopy (WCE) images is vital for early diagnosis and treatment of gastrointestinal (GI) cancers. However, this task is confronted with challenges like tiny lesions and background interference. Additionally, WCE images exhibit higher intra-class variance and inter-class similarities, adding complexity. To tackle these challenges, we propose Decoupled Supervised Contrastive Learning for WCE image classification, learning robust representations from zoomed-in WCE images generated by Saliency Augmentor. Specifically, We use uniformly down-sampled WCE images as anchors and WCE images from the same class, especially their zoomed-in images, as positives. This approach empowers the Feature Extractor to capture rich representations from various views of the same image, facilitated by Decoupled Supervised Contrastive Learning. Training a linear Classifier on these representations within 10 epochs yields an impressive 92.01% overall accuracy, surpassing the prior state-of-the-art (SOTA) by 0.72% on a blend of two publicly accessible WCE datasets. Code is available at: https://github.com/Qiukunpeng/DSCL.
InvNorm: Domain Generalization for Object Detection in Gastrointestinal Endoscopy
May 05, 2022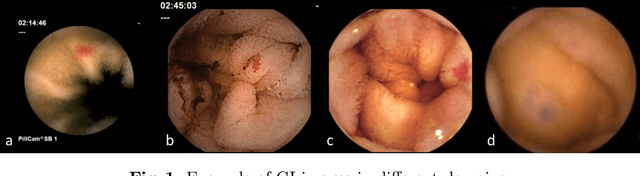
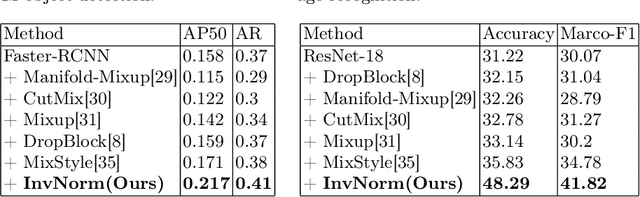
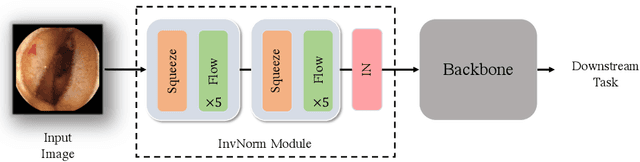
Domain Generalization is a challenging topic in computer vision, especially in Gastrointestinal Endoscopy image analysis. Due to several device limitations and ethical reasons, current open-source datasets are typically collected on a limited number of patients using the same brand of sensors. Different brands of devices and individual differences will significantly affect the model's generalizability. Therefore, to address the generalization problem in GI(Gastrointestinal) endoscopy, we propose a multi-domain GI dataset and a light, plug-in block called InvNorm(Invertible Normalization), which could achieve a better generalization performance in any structure. Previous DG(Domain Generalization) methods fail to achieve invertible transformation, which would lead to some misleading augmentation. Moreover, these models would be more likely to lead to medical ethics issues. Our method utilizes normalizing flow to achieve invertible and explainable style normalization to address the problem. The effectiveness of InvNorm is demonstrated on a wide range of tasks, including GI recognition, GI object detection, and natural image recognition.