 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Guided Masking for Enhanced Vision Self-Supervised Learning
Sep 16, 2024We present a novel frequency-based Self-Supervised Learning (SSL) approach that significantly enhances its efficacy for pre-training. Prior work in this direction masks out pre-defined frequencies in the input image and employs a reconstruction loss to pre-train the model. While achieving promising results, such an implementation has two fundamental limitations as identified in our paper. First, using pre-defined frequencies overlooks the variability of image frequency responses. Second, pre-trained with frequency-filtered images, the resulting model needs relatively more data to adapt to naturally looking images during fine-tuning. To address these drawbacks, we propose FOurier transform compression with seLf-Knowledge distillation (FOLK), integrating two dedicated ideas. First, inspired by image compression, we adaptively select the masked-out frequencies based on image frequency responses, creating more suitable SSL tasks for pre-training. Second, we employ a two-branch framework empowered by knowledge distillation, enabling the model to take both the filtered and original images as input, largely reducing the burden of downstream tasks. Our experimental results demonstrate the effectiveness of FOLK in achieving competitive performance to many state-of-the-art SSL methods across various downstream tasks, including image classification, few-shot learning, and semantic segmentation.
VLM4Bio: A Benchmark Dataset to Evaluate Pretrained Vision-Language Models for Trait Discovery from Biological Images
Aug 28, 2024



Images are increasingly becoming the currency for documenting biodiversity on the planet, providing novel opportunities for accelerating scientific discoveries in the field of organismal biology, especially with the advent of large vision-language models (VLMs). We ask if pre-trained VLMs can aid scientists in answering a range of biologically relevant questions without any additional fine-tuning. In this paper, we evaluate the effectiveness of 12 state-of-the-art (SOTA) VLMs in the field of organismal biology using a novel dataset, VLM4Bio, consisting of 469K question-answer pairs involving 30K images from three groups of organisms: fishes, birds, and butterflies, covering five biologically relevant tasks. We also explore the effects of applying prompting techniques and tests for reasoning hallucination on the performance of VLMs, shedding new light on the capabilities of current SOTA VLMs in answering biologically relevant questions using images. The code and datasets for running all the analyses reported in this paper can be found at https://github.com/sammarfy/VLM4Bio.
Hierarchical Conditioning of Diffusion Models Using Tree-of-Life for Studying Species Evolution
Jul 31, 2024



A central problem in biology is to understand how organisms evolve and adapt to their environment by acquiring variations in the observable characteristics or traits of species across the tree of life. With the growing availability of large-scale image repositories in biology and recent advances in generative modeling, there is an opportunity to accelerate the discovery of evolutionary traits automatically from images. Toward this goal, we introduce Phylo-Diffusion, a novel framework for conditioning diffusion models with phylogenetic knowledge represented in the form of HIERarchical Embeddings (HIER-Embeds). We also propose two new experiments for perturbing the embedding space of Phylo-Diffusion: trait masking and trait swapping, inspired by counterpart experiments of gene knockout and gene editing/swapping. Our work represents a novel methodological advance in generative modeling to structure the embedding space of diffusion models using tree-based knowledge. Our work also opens a new chapter of research in evolutionary biology by using generative models to visualize evolutionary changes directly from images. We empirically demonstrate the usefulness of Phylo-Diffusion in capturing meaningful trait variations for fishes and birds, revealing novel insights about the biological mechanisms of their evolution.
CompBench: A Comparative Reasoning Benchmark for Multimodal LLMs
Jul 23, 2024



The ability to compare objects, scenes, or situations is crucial for effective decision-making and problem-solving in everyday life. For instance, comparing the freshness of apples enables better choices during grocery shopping, while comparing sofa designs helps optimize the aesthetics of our living space. Despite its significance, the comparative capability is largely unexplored in artificial general intelligence (AGI). In this paper, we introduce CompBench, a benchmark designed to evaluate the comparative reasoning capability of multimodal large language models (MLLMs). CompBench mines and pairs images through visually oriented questions covering eight dimensions of relative comparison: visual attribute, existence, state, emotion, temporality, spatiality, quantity, and quality. We curate a collection of around 40K image pairs using metadata from diverse vision datasets and CLIP similarity scores. These image pairs span a broad array of visual domains, including animals, fashion, sports, and both outdoor and indoor scenes. The questions are carefully crafted to discern relative characteristics between two images and are labeled by human annotators for accuracy and relevance. We use CompBench to evaluate recent MLLMs, including GPT-4V(ision), Gemini-Pro, and LLaVA-1.6. Our results reveal notable shortcomings in their comparative abilities. We believe CompBench not only sheds light on these limitations but also establishes a solid foundation for future enhancements in the comparative capability of MLLMs.
Jigsaw Game: Federated Clustering
Jul 17, 2024



Federated learning has recently garnered significant attention, especially within the domain of supervised learning. However, despite the abundance of unlabeled data on end-users, unsupervised learning problems such as clustering in the federated setting remain underexplored. In this paper, we investigate the federated clustering problem, with a focus on federated k-means. We outline the challenge posed by its non-convex objective and data heterogeneity in the federated framework. To tackle these challenges, we adopt a new perspective by studying the structures of local solutions in k-means and propose a one-shot algorithm called FeCA (Federated Centroid Aggregation). FeCA adaptively refines local solutions on clients, then aggregates these refined solutions to recover the global solution of the entire dataset in a single round. We empirically demonstrate the robustness of FeCA under various federated scenarios on both synthetic and real-world data. Additionally, we extend FeCA to representation learning and present DeepFeCA, which combines DeepCluster and FeCA for unsupervised feature learning in the federated setting.
Fish-Vista: A Multi-Purpose Dataset for Understanding & Identification of Traits from Images
Jul 10, 2024



Fishes are integral to both ecological systems and economic sectors, and studying fish traits is crucial for understanding biodiversity patterns and macro-evolution trends. To enable the analysis of visual traits from fish images, we introduce the Fish-Visual Trait Analysis (Fish-Vista) dataset - a large, annotated collection of about 60K fish images spanning 1900 different species, supporting several challenging and biologically relevant tasks including species classification, trait identification, and trait segmentation. These images have been curated through a sophisticated data processing pipeline applied to a cumulative set of images obtained from various museum collections. Fish-Vista provides fine-grained labels of various visual traits present in each image. It also offers pixel-level annotations of 9 different traits for 2427 fish images, facilitating additional trait segmentation and localization tasks. The ultimate goal of Fish-Vista is to provide a clean, carefully curated, high-resolution dataset that can serve as a foundation for accelerating biological discoveries using advances in AI. Finally, we provide a comprehensive analysis of state-of-the-art deep learning techniques on Fish-Vista.
DiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024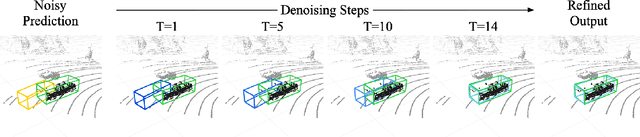
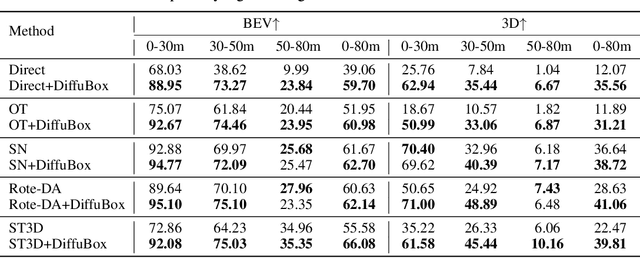
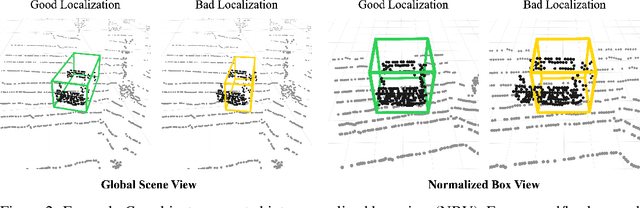
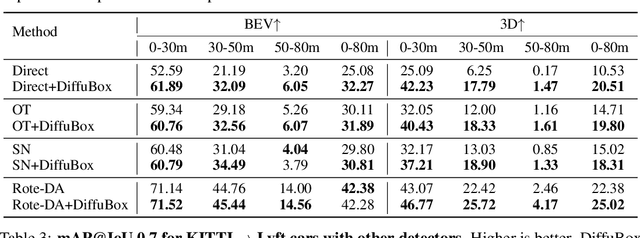
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
Better Monocular 3D Detectors with LiDAR from the Past
Apr 09, 2024



Accurate 3D object detection is crucial to autonomous driving. Though LiDAR-based detectors have achieved impressive performance, the high cost of LiDAR sensors precludes their widespread adoption in affordable vehicles. Camera-based detectors are cheaper alternatives but often suffer inferior performance compared to their LiDAR-based counterparts due to inherent depth ambiguities in images. In this work, we seek to improve monocular 3D detectors by leveraging unlabeled historical LiDAR data. Specifically, at inference time, we assume that the camera-based detectors have access to multiple unlabeled LiDAR scans from past traversals at locations of interest (potentially from other high-end vehicles equipped with LiDAR sensors). Under this setup, we proposed a novel, simple, and end-to-end trainable framework, termed AsyncDepth, to effectively extract relevant features from asynchronous LiDAR traversals of the same location for monocular 3D detectors. We show consistent and significant performance gain (up to 9 AP) across multiple state-of-the-art models and datasets with a negligible additional latency of 9.66 ms and a small storage cost.
Dual-View Visual Contextualization for Web Navigation
Feb 06, 2024



Automatic web navigation aims to build a web agent that can follow language instructions to execute complex and diverse tasks on real-world websites. Existing work primarily takes HTML documents as input, which define the contents and action spaces (i.e., actionable elements and operations) of webpages. Nevertheless, HTML documents may not provide a clear task-related context for each element, making it hard to select the right (sequence of) actions. In this paper, we propose to contextualize HTML elements through their "dual views" in webpage screenshots: each HTML element has its corresponding bounding box and visual content in the screenshot. We build upon the insight -- web developers tend to arrange task-related elements nearby on webpages to enhance user experiences -- and propose to contextualize each element with its neighbor elements, using both textual and visual features. The resulting representations of HTML elements are more informative for the agent to take action. We validate our method on the recently released Mind2Web dataset, which features diverse navigation domains and tasks on real-world websites. Our method consistently outperforms the baseline in all the scenarios, including cross-task, cross-website, and cross-domain ones.
Bringing Back the Context: Camera Trap Species Identification as Link Prediction on Multimodal Knowledge Graphs
Jan 08, 2024



Camera traps are valuable tools in animal ecology for biodiversity monitoring and conservation. However, challenges like poor generalization to deployment at new unseen locations limit their practical application. Images are naturally associated with heterogeneous forms of context possibly in different modalities. In this work, we leverage the structured context associated with the camera trap images to improve out-of-distribution generalization for the task of species identification in camera traps. For example, a photo of a wild animal may be associated with information about where and when it was taken, as well as structured biology knowledge about the animal species. While typically overlooked by existing work, bringing back such context offers several potential benefits for better image understanding, such as addressing data scarcity and enhancing generalization. However, effectively integrating such heterogeneous context into the visual domain is a challenging problem. To address this, we propose a novel framework that reformulates species classification as link prediction in a multimodal knowledge graph (KG). This framework seamlessly integrates various forms of multimodal context for visual recognition. We apply this framework for out-of-distribution species classification on the iWildCam2020-WILDS and Snapshot Mountain Zebra datasets and achieve competitive performance with state-of-the-art approaches. Furthermore, our framework successfully incorporates biological taxonomy for improved generalization and enhances sample efficiency for recognizing under-represented species.