 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeDiffuser: Safe Planning with Diffusion Probabilistic Models
May 31, 2023Diffusion model-based approaches have shown promise in data-driven planning, but there are no safety guarantees, thus making it hard to be applied for safety-critical applications. To address these challenges, we propose a new method, called SafeDiffuser, to ensure diffusion probabilistic models satisfy specifications by using a class of control barrier functions. The key idea of our approach is to embed the proposed finite-time diffusion invariance into the denoising diffusion procedure, which enables trustworthy diffusion data generation. Moreover, we demonstrate that our finite-time diffusion invariance method through generative models not only maintains generalization performance but also creates robustness in safe data generation. We test our method on a series of safe planning tasks, including maze path generation, legged robot locomotion, and 3D space manipulation, with results showing the advantages of robustness and guarantees over vanilla diffusion models.
Learning Robust and Correct Controllers from Signal Temporal Logic Specifications Using BarrierNet
Apr 12, 2023


In this paper, we consider the problem of learning a neural network controller for a system required to satisfy a Signal Temporal Logic (STL) specification. We exploit STL quantitative semantics to define a notion of robust satisfaction. Guaranteeing the correctness of a neural network controller, i.e., ensuring the satisfaction of the specification by the controlled system, is a difficult problem that received a lot of attention recently. We provide a general procedure to construct a set of trainable High Order Control Barrier Functions (HOCBFs) enforcing the satisfaction of formulas in a fragment of STL. We use the BarrierNet, implemented by a differentiable Quadratic Program (dQP) with HOCBF constraints, as the last layer of the neural network controller, to guarantee the satisfaction of the STL formulas. We train the HOCBFs together with other neural network parameters to further improve the robustness of the controller. Simulation results demonstrate that our approach ensures satisfaction and outperforms existing algorithms.
Vehicle Trajectory Prediction based Predictive Collision Risk Assessment for Autonomous Driving in Highway Scenarios
Apr 12, 2023For driving safely and efficiently in highway scenarios, autonomous vehicles (AVs) must be able to predict future behaviors of surrounding object vehicles (OVs), and assess collision risk accurately for reasonable decision-making. Aiming at autonomous driving in highway scenarios, a predictive collision risk assessment method based on trajectory prediction of OVs is proposed in this paper. Firstly, the vehicle trajectory prediction is formulated as a sequence generation task with long short-term memory (LSTM) encoder-decoder framework. Convolutional social pooling (CSP) and graph attention network (GAN) are adopted for extracting local spatial vehicle interactions and distant spatial vehicle interactions, respectively. Then, two basic risk metrics, time-to-collision (TTC) and minimal distance margin (MDM), are calculated between the predicted trajectory of OV and the candidate trajectory of AV. Consequently, a time-continuous risk function is constructed with temporal and spatial risk metrics. Finally, the vehicle trajectory prediction model CSP-GAN-LSTM is evaluated on two public highway datasets. The quantitative results indicate that the proposed CSP-GAN-LSTM model outperforms the existing state-of-the-art (SOTA) methods in terms of position prediction accuracy. Besides, simulation results in typical highway scenarios further validate the feasibility and effectiveness of the proposed predictive collision risk assessment method.
Learning Stability Attention in Vision-based End-to-end Driving Policies
Apr 05, 2023Modern end-to-end learning systems can learn to explicitly infer control from perception. However, it is difficult to guarantee stability and robustness for these systems since they are often exposed to unstructured, high-dimensional, and complex observation spaces (e.g., autonomous driving from a stream of pixel inputs). We propose to leverage control Lyapunov functions (CLFs) to equip end-to-end vision-based policies with stability properties and introduce stability attention in CLFs (att-CLFs) to tackle environmental changes and improve learning flexibility. We also present an uncertainty propagation technique that is tightly integrated into att-CLFs. We demonstrate the effectiveness of att-CLFs via comparison with classical CLFs, model predictive control, and vanilla end-to-end learning in a photo-realistic simulator and on a real full-scale autonomous vehicle.
Auxiliary-Adaptive Control Barrier Functions for Safety Critical Systems
Apr 01, 2023



This paper studies safety guarantees for systems with time-varying control bounds. It has been shown that optimizing quadratic costs subject to state and control constraints can be reduced to a sequence of Quadratic Programs (QPs) using Control Barrier Functions (CBFs). One of the main challenges in this method is that the CBF-based QP could easily become infeasible under tight control bounds, especially when the control bounds are time-varying. The recently proposed adaptive CBFs have addressed such infeasibility issues, but require extensive and non-trivial hyperparameter tuning for the CBF-based QP and may introduce overshooting control near the boundaries of safe sets. To address these issues, we propose a new type of adaptive CBFs called Auxiliary Variable CBFs (AVCBFs). Specifically, we introduce an auxiliary variable that multiplies each CBF itself, and define dynamics for the auxiliary variable to adapt it in constructing the corresponding CBF constraint. In this way, we can improve the feasibility of the CBF-based QP while avoiding extensive parameter tuning with non-overshooting control since the formulation is identical to classical CBF methods. We demonstrate the advantages of using AVCBFs and compare them with existing techniques on an Adaptive Cruise Control (ACC) problem with time-varying control bounds.
Learning Feasibility Constraints for Control Barrier Functions
Mar 10, 2023



It has been shown that optimizing quadratic costs while stabilizing affine control systems to desired (sets of) states subject to state and control constraints can be reduced to a sequence of Quadratic Programs (QPs) by using Control Barrier Functions (CBFs) and Control Lyapunov Functions (CLFs). In this paper, we employ machine learning techniques to ensure the feasibility of these QPs, which is a challenging problem, especially for high relative degree constraints where High Order CBFs (HOCBFs) are required. To this end, we propose a sampling-based learning approach to learn a new feasibility constraint for CBFs; this constraint is then enforced by another HOCBF added to the QPs. The accuracy of the learned feasibility constraint is recursively improved by a recurrent training algorithm. We demonstrate the advantages of the proposed learning approach to constrained optimal control problems with specific focus on a robot control problem and on autonomous driving in an unknown environment.
Learned Risk Metric Maps for Kinodynamic Systems
Feb 28, 2023



We present Learned Risk Metric Maps (LRMM) for real-time estimation of coherent risk metrics of high dimensional dynamical systems operating in unstructured, partially observed environments. LRMM models are simple to design and train -- requiring only procedural generation of obstacle sets, state and control sampling, and supervised training of a function approximator -- which makes them broadly applicable to arbitrary system dynamics and obstacle sets. In a parallel autonomy setting, we demonstrate the model's ability to rapidly infer collision probabilities of a fast-moving car-like robot driving recklessly in an obstructed environment; allowing the LRMM agent to intervene, take control of the vehicle, and avoid collisions. In this time-critical scenario, we show that LRMMs can evaluate risk metrics 20-100x times faster than alternative safety algorithms based on control barrier functions (CBFs) and Hamilton-Jacobi reachability (HJ-reach), leading to 5-15\% fewer obstacle collisions by the LRMM agent than CBFs and HJ-reach. This performance improvement comes in spite of the fact that the LRMM model only has access to local/partial observation of obstacles, whereas the CBF and HJ-reach agents are granted privileged/global information. We also show that our model can be equally well trained on a 12-dimensional quadrotor system operating in an obstructed indoor environment. The LRMM codebase is provided at https://github.com/mit-drl/pyrmm.
SWING: Balancing Coverage and Faithfulness for Dialogue Summarization
Jan 25, 2023Missing information is a common issue of dialogue summarization where some information in the reference summaries is not covered in the generated summaries. To address this issue, we propose to utilize natural language inference (NLI) models to improve coverage while avoiding introducing factual inconsistencies. Specifically, we use NLI to compute fine-grained training signals to encourage the model to generate content in the reference summaries that have not been covered, as well as to distinguish between factually consistent and inconsistent generated sentences. Experiments on the DialogSum and SAMSum datasets confirm the effectiveness of the proposed approach in balancing coverage and faithfulness, validated with automatic metrics and human evaluations. Additionally, we compute the correlation between commonly used automatic metrics with human judgments in terms of three different dimensions regarding coverage and factual consistency to provide insight into the most suitable metric for evaluating dialogue summaries.
Interpreting Neural Policies with Disentangled Tree Representations
Oct 13, 2022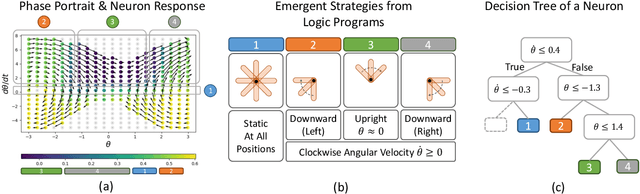
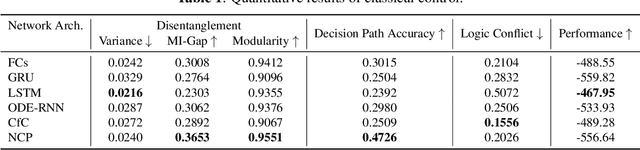
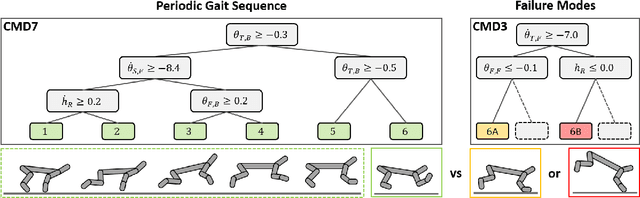
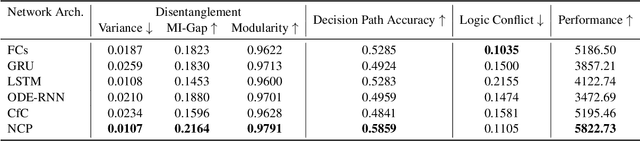
Compact neural networks used in policy learning and closed-loop end-to-end control learn representations from data that encapsulate agent dynamics and potentially the agent-environment's factors of variation. A formal and quantitative understanding and interpretation of these explanatory factors in neural representations is difficult to achieve due to the complex and intertwined correspondence of neural activities with emergent behaviors. In this paper, we design a new algorithm that programmatically extracts tree representations from compact neural policies, in the form of a set of logic programs grounded by the world state. To assess how well networks uncover the dynamics of the task and their factors of variation, we introduce interpretability metrics that measure the disentanglement of learned neural dynamics from a concentration of decisions, mutual information, and modularity perspectives. Moreover, our method allows us to quantify how accurate the extracted decision paths (explanations) are and computes cross-neuron logic conflict. We demonstrate the effectiveness of our approach with several types of compact network architectures on a series of end-to-end learning to control tasks.
On the Forward Invariance of Neural ODEs
Oct 10, 2022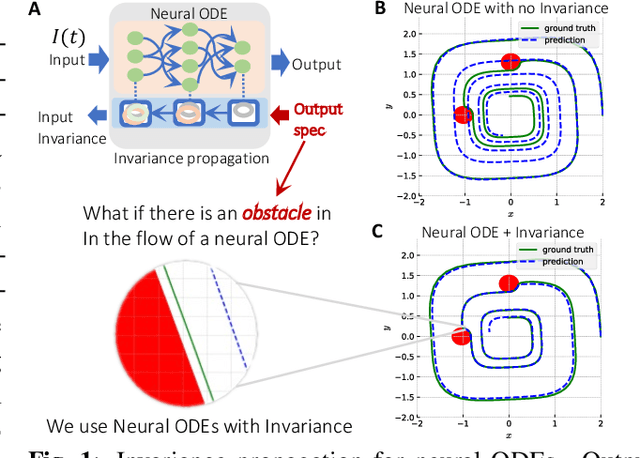

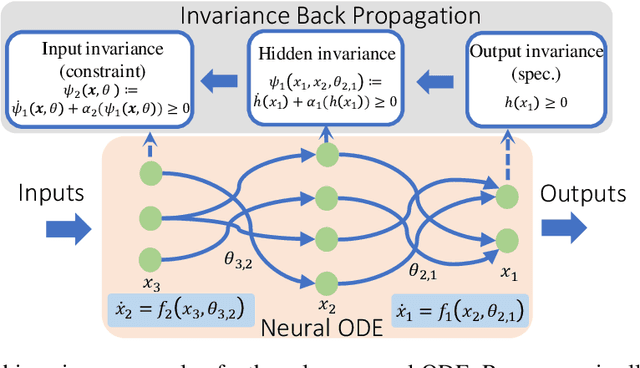
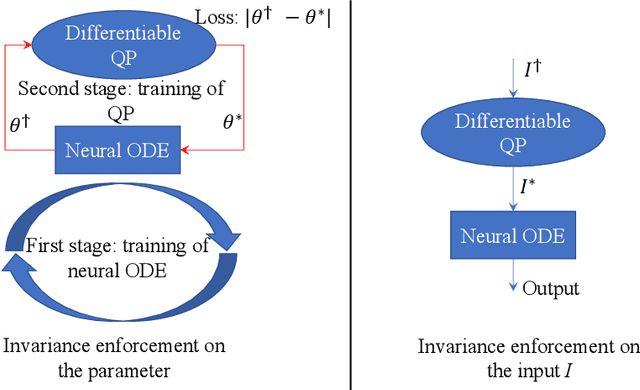
To ensure robust and trustworthy decision-making, it is highly desirable to enforce constraints over a neural network's parameters and its inputs automatically by back-propagating output specifications. This way, we can guarantee that the network makes reliable decisions under perturbations. Here, we propose a new method for achieving a class of specification guarantees for neural Ordinary Differentiable Equations (ODEs) by using invariance set propagation. An invariance of a neural ODE is defined as an output specification, such as to satisfy mathematical formulae, physical laws, and system safety. We use control barrier functions to specify the invariance of a neural ODE on the output layer and propagate it back to the input layer. Through the invariance backpropagation, we map output specifications onto constraints on the neural ODE parameters or its input. The satisfaction of the corresponding constraints implies the satisfaction of output specifications. This allows us to achieve output specification guarantees by changing the input or parameters while maximally preserving the model performance. We demonstrate the invariance propagation on a comprehensive series of representation learning tasks, including spiral curve regression, autoregressive modeling of joint physical dynamics, convexity portrait of a function, and safe neural control of collision avoidance for autonomous vehicles.