 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pre-training Framework that Encodes Noise Information for Speech Quality Assessment
Nov 07, 2024



Self-supervised learning (SSL) has grown in interest within the speech processing community, since it produces representations that are useful for many downstream tasks. SSL uses global and contextual methods to produce robust representations, where SSL even outperforms supervised models. Most self-supervised approaches, however, are limited to embedding information about, i.e., the phonemes, speaker identity, and emotion, into the extracted representations, where they become invariant to background sounds due to contrastive and auto-regressive learning. This is limiting because many downstream tasks leverage noise information to function accurately. Therefore, we propose a pre-training framework that learns information pertaining to background noise in a supervised manner, while jointly embedding speech information using a self-supervised strategy. We experiment with multiple encoders and show that our framework is useful for perceptual speech quality estimation, which relies on background cues. Our results show that the proposed approach improves performance with fewer parameters, in comparison to multiple baselines.
A contrastive-learning approach for auditory attention detection
Oct 24, 2024



Carrying conversations in multi-sound environments is one of the more challenging tasks, since the sounds overlap across time and frequency making it difficult to understand a single sound source. One proposed approach to help isolate an attended speech source is through decoding the electroencephalogram (EEG) and identifying the attended audio source using statistical or machine learning techniques. However, the limited amount of data in comparison to other machine learning problems and the distributional shift between different EEG recordings emphasizes the need for a self supervised approach that works with limited data to achieve a more robust solution. In this paper, we propose a method based on self supervised learning to minimize the difference between the latent representations of an attended speech signal and the corresponding EEG signal. This network is further finetuned for the auditory attention classification task. We compare our results with previously published methods and achieve state-of-the-art performance on the validation set.
Using RLHF to align speech enhancement approaches to mean-opinion quality scores
Oct 17, 2024



Objective speech quality measures are typically used to assess speech enhancement algorithms, but it has been shown that they are sub-optimal as learning objectives because they do not always align well with human subjective ratings. This misalignment often results in noticeable distortions and artifacts that cause speech enhancement to be ineffective. To address these issues, we propose a reinforcement learning from human feedback (RLHF) framework to fine-tune an existing speech enhancement approach by optimizing performance using a mean-opinion score (MOS)-based reward model. Our results show that the RLHF-finetuned model has the best performance across different benchmarks for both objective and MOS-based speech quality assessment metrics on the Voicebank+DEMAND dataset. Through ablation studies, we show that both policy gradient loss and supervised MSE loss are important for balanced optimization across the different metrics.
SWIM: An Attention-Only Model for Speech Quality Assessment Under Subjective Variance
Oct 16, 2024



Speech quality is best evaluated by human feedback using mean opinion scores (MOS). However, variance in ratings between listeners can introduce noise in the true quality label of an utterance. Currently, deep learning networks including convolutional, recurrent, and attention-based architectures have been explored for quality estimation. This paper proposes an exclusively attention-based model involving a Swin Transformer for MOS estimation (SWIM). Our network captures local and global dependencies that reflect the acoustic properties of an utterance. To counteract subjective variance in MOS labels, we propose a normal distance-based objective that accounts for standard deviation in each label, and we avail a multistage self-teaching strategy to improve generalization further. Our model is significantly more compact than existing attention-based networks for quality estimation. Finally, our experiments on the Samsung Open Mean Opinion Score (SOMOS) dataset show improvement over existing baseline models when trained from scratch.
MMViT: Multiscale Multiview Vision Transformers
Apr 28, 2023



We present Multiscale Multiview Vision Transformers (MMViT), which introduces multiscale feature maps and multiview encodings to transformer models. Our model encodes different views of the input signal and builds several channel-resolution feature stages to process the multiple views of the input at different resolutions in parallel. At each scale stage, we use a cross-attention block to fuse information across different views. This enables the MMViT model to acquire complex high-dimensional representations of the input at different resolutions. The proposed model can serve as a backbone model in multiple domains. We demonstrate the effectiveness of MMViT on audio and image classification tasks, achieving state-of-the-art results.
Attention-based Speech Enhancement Using Human Quality Perception Modelling
Mar 23, 2023



Perceptually-inspired objective functions such as the perceptual evaluation of speech quality (PESQ), signal-to-distortion ratio (SDR), and short-time objective intelligibility (STOI), have recently been used to optimize performance of deep-learning-based speech enhancement algorithms. These objective functions, however, do not always strongly correlate with a listener's assessment of perceptual quality, so optimizing with these measures often results in poorer performance in real-world scenarios. In this work, we propose an attention-based enhancement approach that uses learned speech embedding vectors from a mean-opinion score (MOS) prediction model and a speech enhancement module to jointly enhance noisy speech. The MOS prediction model estimates the perceptual MOS of speech quality, as assessed by human listeners, directly from the audio signal. The enhancement module also employs a quantized language model that enforces spectral constraints for better speech realism and performance. We train the model using real-world noisy speech data that has been captured in everyday environments and test it using unseen corpora. The results show that our proposed approach significantly outperforms other approaches that are optimized with objective measures, where the predicted quality scores strongly correlate with human judgments.
A Composite T60 Regression and Classification Approach for Speech Dereverberation
Feb 09, 2023



Dereverberation is often performed directly on the reverberant audio signal, without knowledge of the acoustic environment. Reverberation time, T60, however, is an essential acoustic factor that reflects how reverberation may impact a signal. In this work, we propose to perform dereverberation while leveraging key acoustic information from the environment. More specifically, we develop a joint learning approach that uses a composite T60 module and a separate dereverberation module to simultaneously perform reverberation time estimation and dereverberation. The reverberation time module provides key features to the dereverberation module during fine tuning. We evaluate our approach in simulated and real environments, and compare against several approaches. The results show that this composite framework improves performance in environments.
ConferencingSpeech 2022 Challenge: Non-intrusive Objective Speech Quality Assessment (NISQA) Challenge for Online Conferencing Applications
Apr 01, 2022
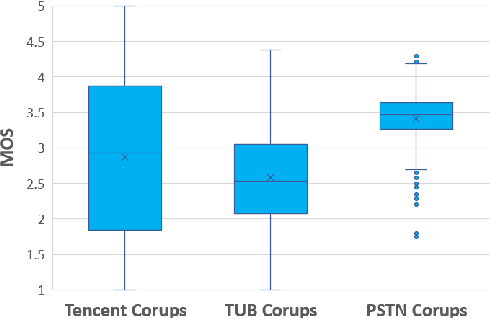

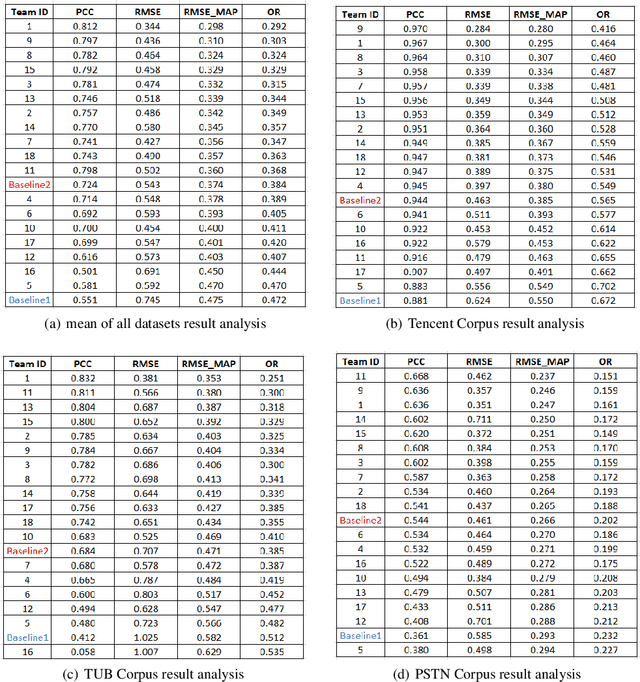
With the advances in speech communication systems such as online conferencing applications, we can seamlessly work with people regardless of where they are. However, during online meetings, speech quality can be significantly affected by background noise, reverberation, packet loss, network jitter, etc. Because of its nature, speech quality is traditionally assessed in subjective tests in laboratories and lately also in crowdsourcing following the international standards from ITU-T Rec. P.800 series. However, those approaches are costly and cannot be applied to customer data. Therefore, an effective objective assessment approach is needed to evaluate or monitor the speech quality of the ongoing conversation. The ConferencingSpeech 2022 challenge targets the non-intrusive deep neural network models for the speech quality assessment task. We open-sourced a training corpus with more than 86K speech clips in different languages, with a wide range of synthesized and live degradations and their corresponding subjective quality scores through crowdsourcing. 18 teams submitted their models for evaluation in this challenge. The blind test sets included about 4300 clips from wide ranges of degradations. This paper describes the challenge, the datasets, and the evaluation methods and reports the final results.
Multi-channel Multi-frame ADL-MVDR for Target Speech Separation
Dec 24, 2020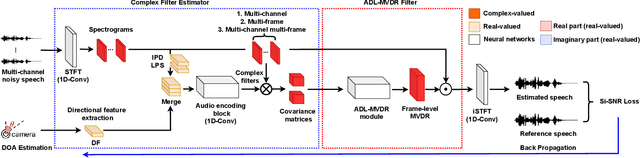
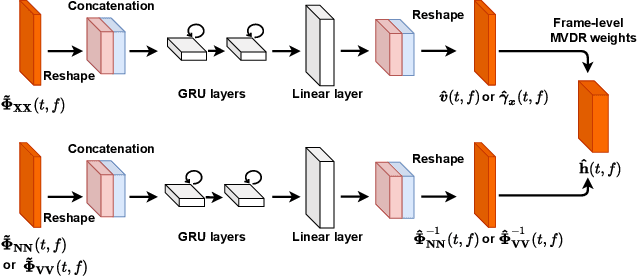
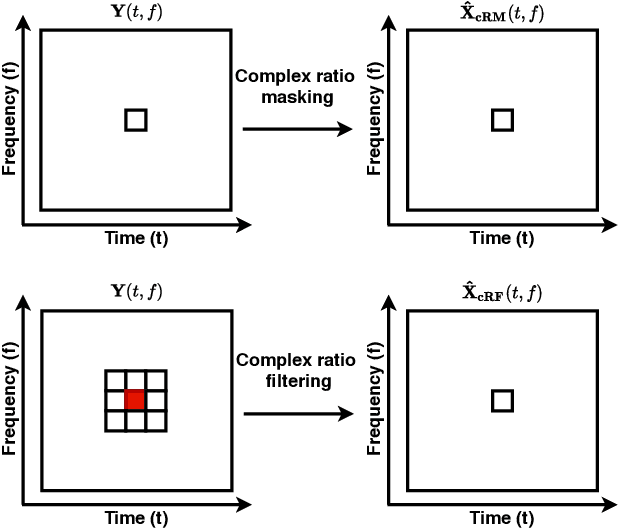
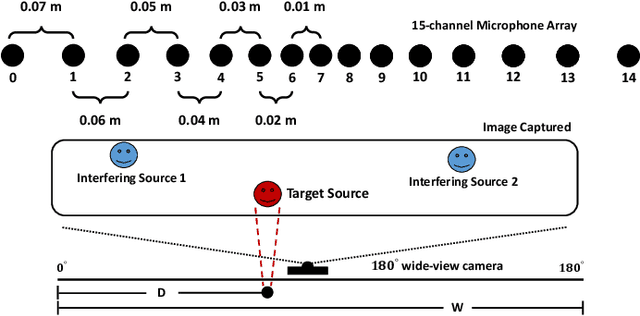
Many purely neural network based speech separation approaches have been proposed that greatly improve objective assessment scores, but they often introduce nonlinear distortions that are harmful to automatic speech recognition (ASR). Minimum variance distortionless response (MVDR) filters strive to remove nonlinear distortions, however, these approaches either are not optimal for removing residual (linear) noise, or they are unstable when used jointly with neural networks. In this study, we propose a multi-channel multi-frame (MCMF) all deep learning (ADL)-MVDR approach for target speech separation, which extends our preliminary multi-channel ADL-MVDR approach. The MCMF ADL-MVDR handles different numbers of microphone channels in one framework, where it addresses linear and nonlinear distortions. Spatio-temporal cross correlations are also fully utilized in the proposed approach. The proposed system is evaluated using a Mandarin audio-visual corpora and is compared with several state-of-the-art approaches. Experimental results demonstrate the superiority of our proposed framework under different scenarios and across several objective evaluation metrics, including ASR performance.
A Pyramid Recurrent Network for Predicting Crowdsourced Speech-Quality Ratings of Real-World Signals
Jul 31, 2020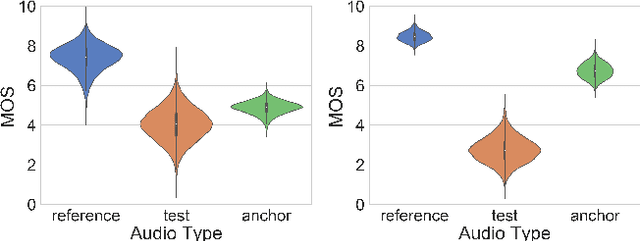
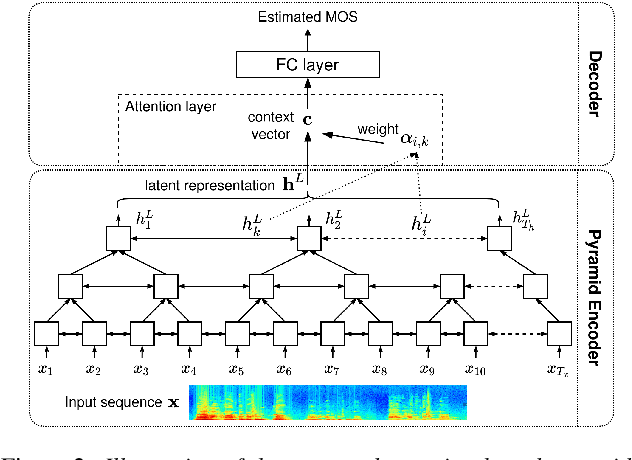
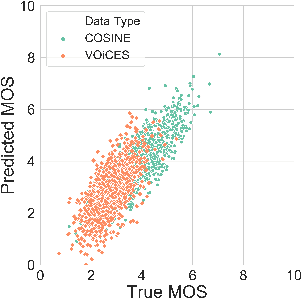
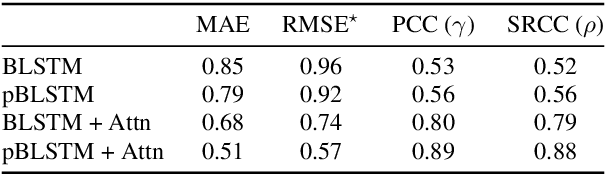
The real-world capabilities of objective speech quality measures are limited since current measures (1) are developed from simulated data that does not adequately model real environments; or they (2) predict objective scores that are not always strongly correlated with subjective ratings. Additionally, a large dataset of real-world signals with listener quality ratings does not currently exist, which would help facilitate real-world assessment. In this paper, we collect and predict the perceptual quality of real-world speech signals that are evaluated by human listeners. We first collect a large quality rating dataset by conducting crowdsourced listening studies on two real-world corpora. We further develop a novel approach that predicts human quality ratings using a pyramid bidirectional long short term memory (pBLSTM) network with an attention mechanism. The results show that the proposed model achieves statistically lower estimation errors than prior assessment approaches, where the predicted scores strongly correlate with human judgments.