 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeywords and Instances: A Hierarchical Contrastive Learning Framework Unifying Hybrid Granularities for Text Generation
May 26, 2022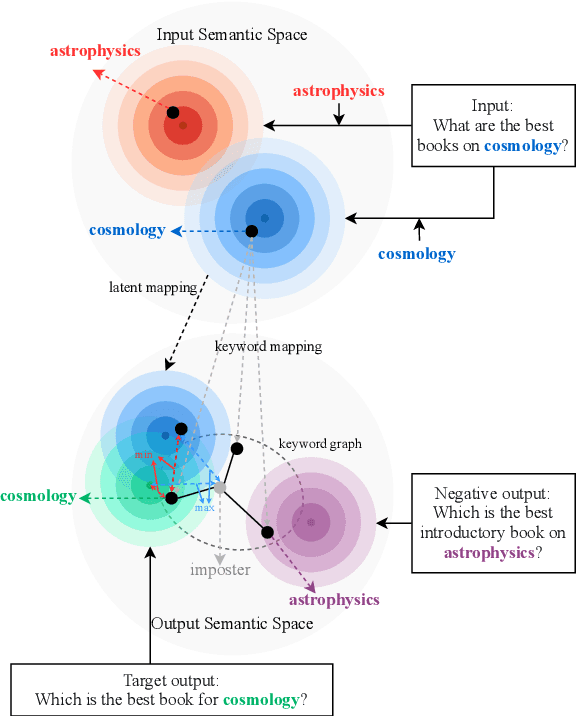
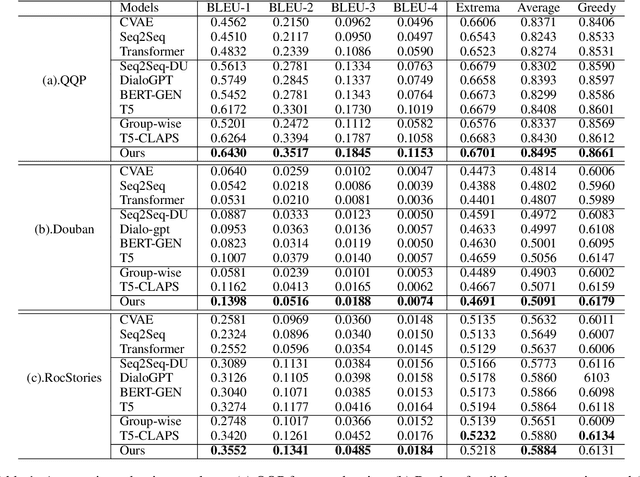
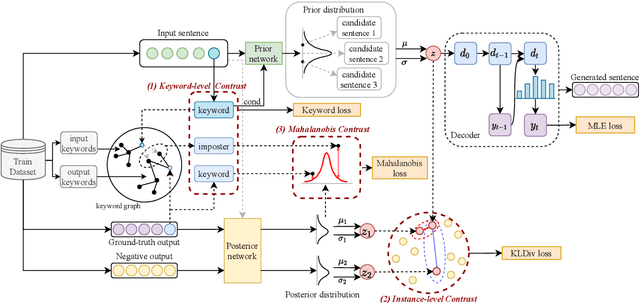

Contrastive learning has achieved impressive success in generation tasks to militate the "exposure bias" problem and discriminatively exploit the different quality of references. Existing works mostly focus on contrastive learning on the instance-level without discriminating the contribution of each word, while keywords are the gist of the text and dominant the constrained mapping relationships. Hence, in this work, we propose a hierarchical contrastive learning mechanism, which can unify hybrid granularities semantic meaning in the input text. Concretely, we first propose a keyword graph via contrastive correlations of positive-negative pairs to iteratively polish the keyword representations. Then, we construct intra-contrasts within instance-level and keyword-level, where we assume words are sampled nodes from a sentence distribution. Finally, to bridge the gap between independent contrast levels and tackle the common contrast vanishing problem, we propose an inter-contrast mechanism that measures the discrepancy between contrastive keyword nodes respectively to the instance distribution. Experiments demonstrate that our model outperforms competitive baselines on paraphrasing, dialogue generation, and storytelling tasks.
PIE: a Parameter and Inference Efficient Solution for Large Scale Knowledge Graph Embedding Reasoning
May 05, 2022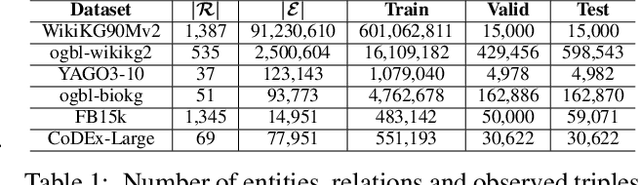
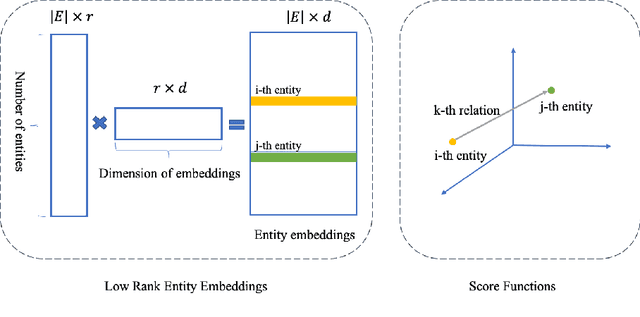

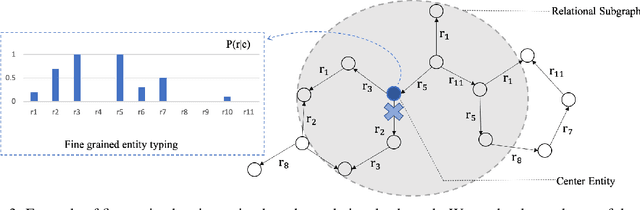
Knowledge graph (KG) embedding methods which map entities and relations to unique embeddings in the KG have shown promising results on many reasoning tasks. However, the same embedding dimension for both dense entities and sparse entities will cause either over parameterization (sparse entities) or under fitting (dense entities). Normally, a large dimension is set to get better performance. Meanwhile, the inference time grows log-linearly with the number of entities for all entities are traversed and compared. Both the parameter and inference become challenges when working with huge amounts of entities. Thus, we propose PIE, a \textbf{p}arameter and \textbf{i}nference \textbf{e}fficient solution. Inspired from tensor decomposition methods, we find that decompose entity embedding matrix into low rank matrices can reduce more than half of the parameters while maintaining comparable performance. To accelerate model inference, we propose a self-supervised auxiliary task, which can be seen as fine-grained entity typing. By randomly masking and recovering entities' connected relations, the task learns the co-occurrence of entity and relations. Utilizing the fine grained typing, we can filter unrelated entities during inference and get targets with possibly sub-linear time requirement. Experiments on link prediction benchmarks demonstrate the proposed key capabilities. Moreover, we prove effectiveness of the proposed solution on the Open Graph Benchmark large scale challenge dataset WikiKG90Mv2 and achieve the state of the art performance.
ESCM$^2$: Entire Space Counterfactual Multi-Task Model for Post-Click Conversion Rate Estimation
Apr 03, 2022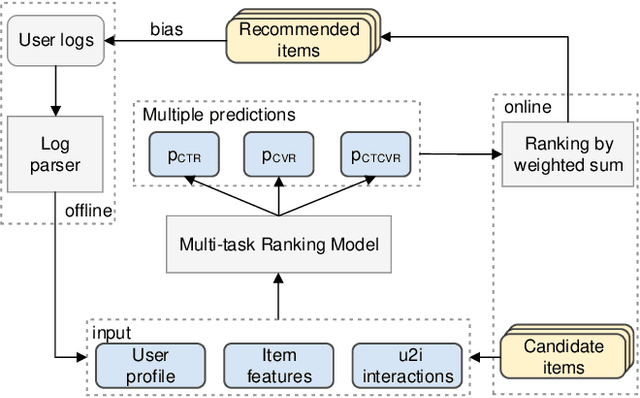

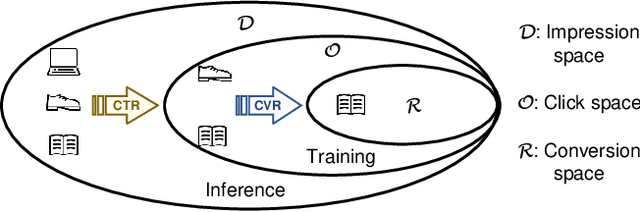
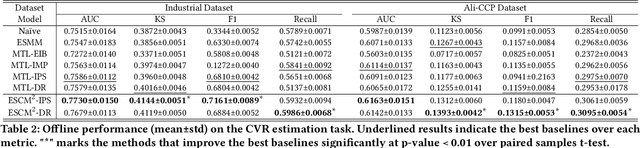
Accurate estimation of post-click conversion rate is critical for building recommender systems, which has long been confronted with sample selection bias and data sparsity issues. Methods in the Entire Space Multi-task Model (ESMM) family leverage the sequential pattern of user actions, i.e. $impression\rightarrow click \rightarrow conversion$ to address data sparsity issue. However, they still fail to ensure the unbiasedness of CVR estimates. In this paper, we theoretically demonstrate that ESMM suffers from the following two problems: (1) Inherent Estimation Bias (IEB), where the estimated CVR of ESMM is inherently higher than the ground truth; (2) Potential Independence Priority (PIP) for CTCVR estimation, where there is a risk that the ESMM overlooks the causality from click to conversion. To this end, we devise a principled approach named Entire Space Counterfactual Multi-task Modelling (ESCM$^2$), which employs a counterfactual risk miminizer as a regularizer in ESMM to address both IEB and PIP issues simultaneously. Extensive experiments on offline datasets and online environments demonstrate that our proposed ESCM$^2$ can largely mitigate the inherent IEB and PIP issues and achieve better performance than baseline models.
Training Protocol Matters: Towards Accurate Scene Text Recognition via Training Protocol Searching
Mar 17, 2022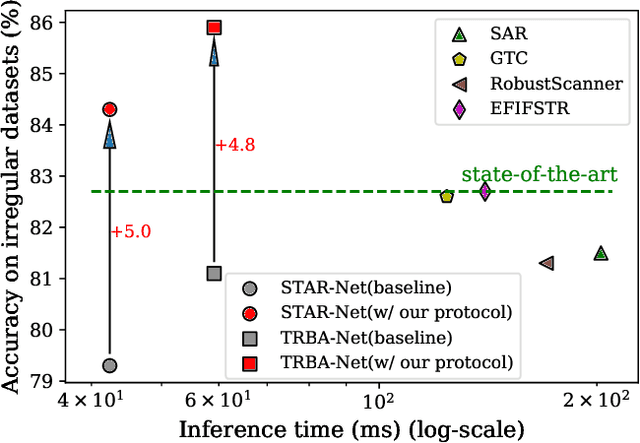
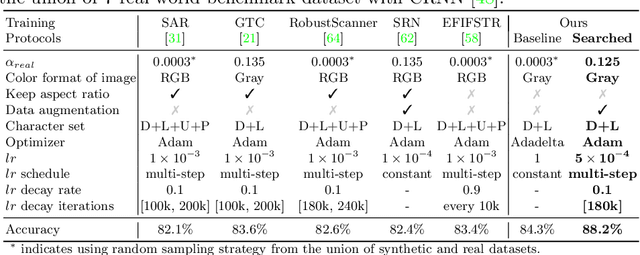

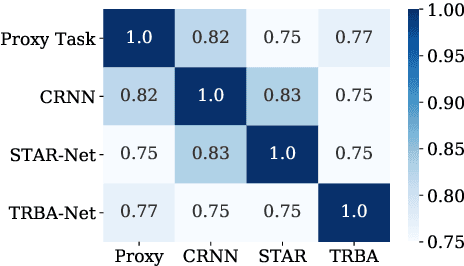
The development of scene text recognition (STR) in the era of deep learning has been mainly focused on novel architectures of STR models. However, training protocol (i.e., settings of the hyper-parameters involved in the training of STR models), which plays an equally important role in successfully training a good STR model, is under-explored for scene text recognition. In this work, we attempt to improve the accuracy of existing STR models by searching for optimal training protocol. Specifically, we develop a training protocol search algorithm, based on a newly designed search space and an efficient search algorithm using evolutionary optimization and proxy tasks. Experimental results show that our searched training protocol can improve the recognition accuracy of mainstream STR models by 2.7%~3.9%. In particular, with the searched training protocol, TRBA-Net achieves 2.1% higher accuracy than the state-of-the-art STR model (i.e., EFIFSTR), while the inference speed is 2.3x and 3.7x faster on CPU and GPU respectively. Extensive experiments are conducted to demonstrate the effectiveness of the proposed method and the generalization ability of the training protocol found by our search method. Code is available at https://github.com/VDIGPKU/STR_TPSearch.
CBNetV2: A Composite Backbone Network Architecture for Object Detection
Jul 29, 2021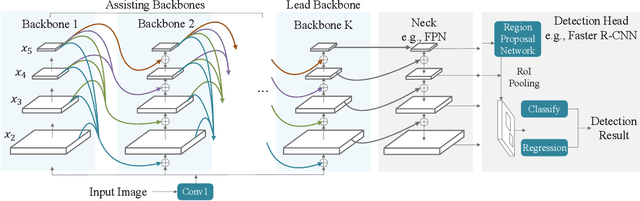
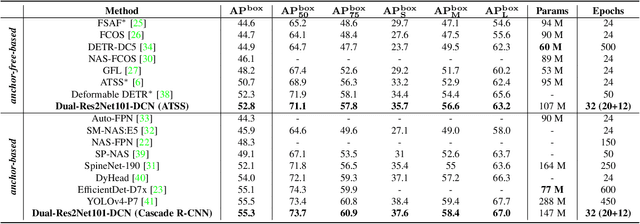
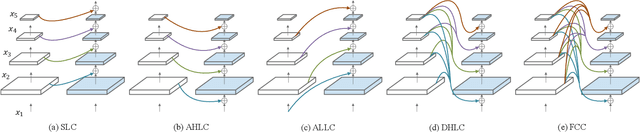
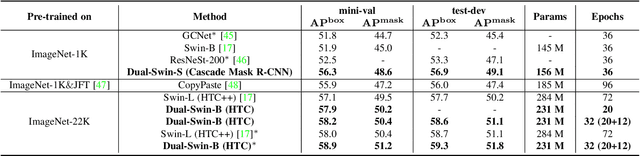
Modern top-performing object detectors depend heavily on backbone networks, whose advances bring consistent performance gains through exploring more effective network structures. In this paper, we propose a novel and flexible backbone framework, namely CBNetV2, to construct high-performance detectors using existing open-sourced pre-trained backbones under the pre-training fine-tuning paradigm. In particular, CBNetV2 architecture groups multiple identical backbones, which are connected through composite connections. Specifically, it integrates the high- and low-level features of multiple backbone networks and gradually expands the receptive field to more efficiently perform object detection. We also propose a better training strategy with assistant supervision for CBNet-based detectors. Without additional pre-training of the composite backbone, CBNetV2 can be adapted to various backbones (CNN-based vs. Transformer-based) and head designs of most mainstream detectors (one-stage vs. two-stage, anchor-based vs. anchor-free-based). Experiments provide strong evidence that, compared with simply increasing the depth and width of the network, CBNetV2 introduces a more efficient, effective, and resource-friendly way to build high-performance backbone networks. Particularly, our Dual-Swin-L achieves 59.4% box AP and 51.6% mask AP on COCO test-dev under the single-model and single-scale testing protocol, which is significantly better than the state-of-the-art result (57.7% box AP and 50.2% mask AP) achieved by Swin-L, while the training schedule is reduced by 6$\times$. With multi-scale testing, we push the current best single model result to a new record of 60.1% box AP and 52.3% mask AP without using extra training data. Code is available at https://github.com/VDIGPKU/CBNetV2.
An Improved Single Step Non-autoregressive Transformer for Automatic Speech Recognition
Jul 22, 2021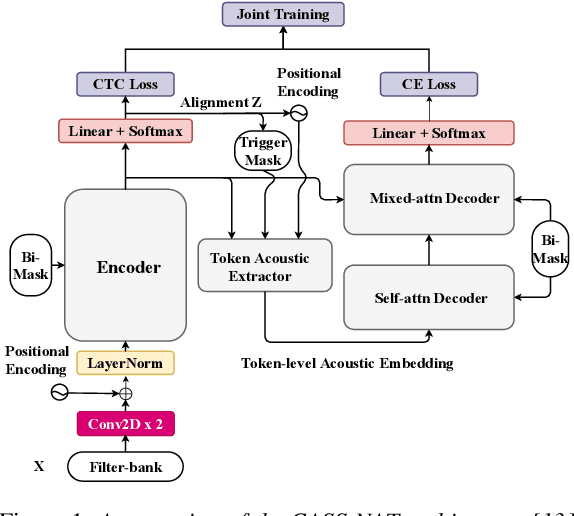
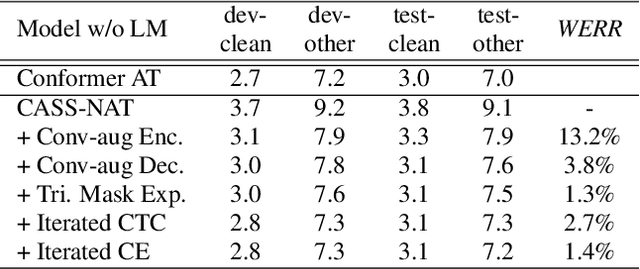
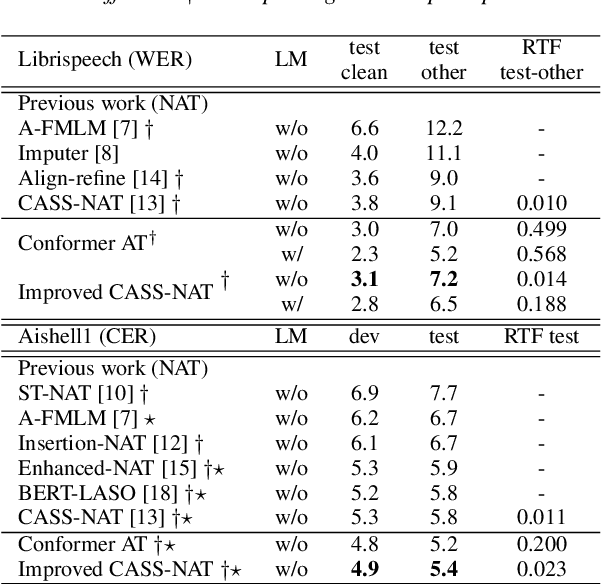
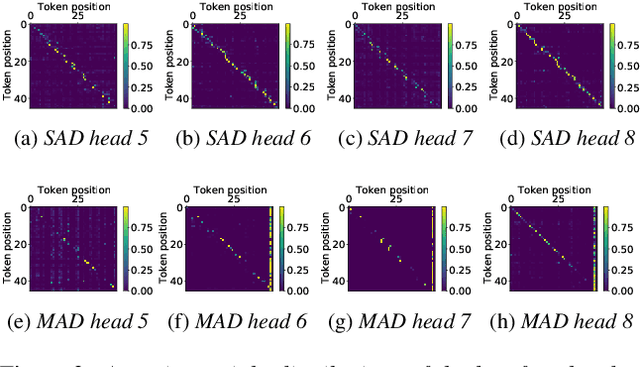
Non-autoregressive mechanisms can significantly decrease inference time for speech transformers, especially when the single step variant is applied. Previous work on CTC alignment-based single step non-autoregressive transformer (CASS-NAT) has shown a large real time factor (RTF) improvement over autoregressive transformers (AT). In this work, we propose several methods to improve the accuracy of the end-to-end CASS-NAT, followed by performance analyses. First, convolution augmented self-attention blocks are applied to both the encoder and decoder modules. Second, we propose to expand the trigger mask (acoustic boundary) for each token to increase the robustness of CTC alignments. In addition, iterated loss functions are used to enhance the gradient update of low-layer parameters. Without using an external language model, the WERs of the improved CASS-NAT, when using the three methods, are 3.1%/7.2% on Librispeech test clean/other sets and the CER is 5.4% on the Aishell1 test set, achieving a 7%~21% relative WER/CER improvement. For the analyses, we plot attention weight distributions in the decoders to visualize the relationships between token-level acoustic embeddings. When the acoustic embeddings are visualized, we find that they have a similar behavior to word embeddings, which explains why the improved CASS-NAT performs similarly to AT.
Low Resource German ASR with Untranscribed Data Spoken by Non-native Children -- INTERSPEECH 2021 Shared Task SPAPL System
Jun 18, 2021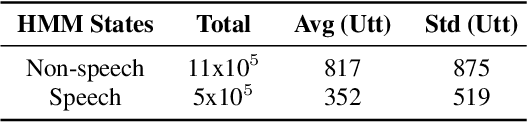
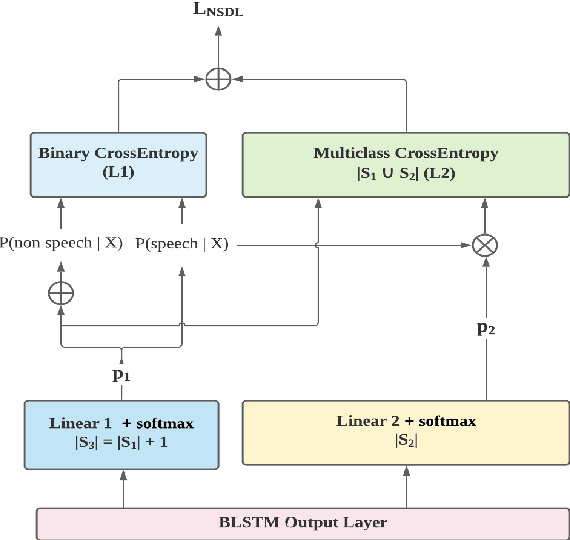
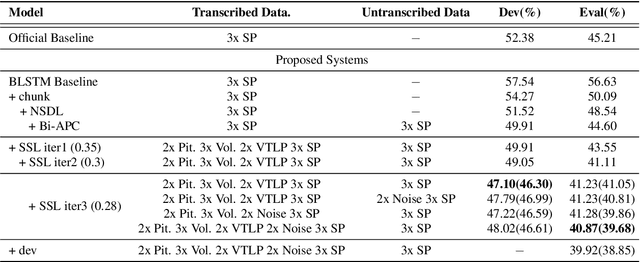
This paper describes the SPAPL system for the INTERSPEECH 2021 Challenge: Shared Task on Automatic Speech Recognition for Non-Native Children's Speech in German. ~ 5 hours of transcribed data and ~ 60 hours of untranscribed data are provided to develop a German ASR system for children. For the training of the transcribed data, we propose a non-speech state discriminative loss (NSDL) to mitigate the influence of long-duration non-speech segments within speech utterances. In order to explore the use of the untranscribed data, various approaches are implemented and combined together to incrementally improve the system performance. First, bidirectional autoregressive predictive coding (Bi-APC) is used to learn initial parameters for acoustic modelling using the provided untranscribed data. Second, incremental semi-supervised learning is further used to iteratively generate pseudo-transcribed data. Third, different data augmentation schemes are used at different training stages to increase the variability and size of the training data. Finally, a recurrent neural network language model (RNNLM) is used for rescoring. Our system achieves a word error rate (WER) of 39.68% on the evaluation data, an approximately 12% relative improvement over the official baseline (45.21%).
CMUA-Watermark: A Cross-Model Universal Adversarial Watermark for Combating Deepfakes
May 23, 2021

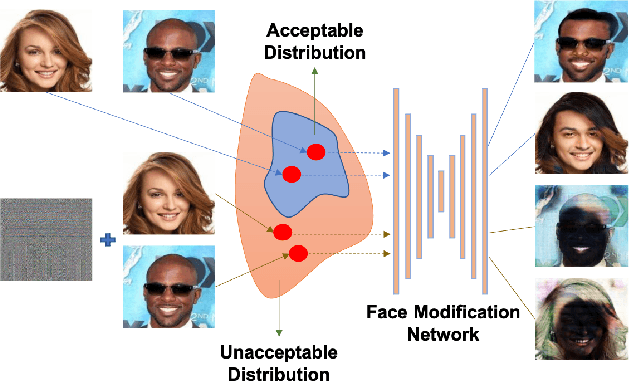

Malicious application of deepfakes (i.e., technologies can generate target faces or face attributes) has posed a huge threat to our society. The fake multimedia content generated by deepfake models can harm the reputation and even threaten the property of the person who has been impersonated. Fortunately, the adversarial watermark could be used for combating deepfake models, leading them to generate distorted images. The existing methods require an individual training process for every facial image, to generate the adversarial watermark against a specific deepfake model, which are extremely inefficient. To address this problem, we propose a universal adversarial attack method on deepfake models, to generate a Cross-Model Universal Adversarial Watermark (CMUA-Watermark) that can protect thousands of facial images from multiple deepfake models. Specifically, we first propose a cross-model universal attack pipeline by attacking multiple deepfake models and combining gradients from these models iteratively. Then we introduce a batch-based method to alleviate the conflict of adversarial watermarks generated by different facial images. Finally, we design a more reasonable and comprehensive evaluation method for evaluating the effectiveness of the adversarial watermark. Experimental results demonstrate that the proposed CMUA-Watermark can effectively distort the fake facial images generated by deepfake models and successfully protect facial images from deepfakes in real scenes.
PairRE: Knowledge Graph Embeddings via Paired Relation Vectors
Nov 07, 2020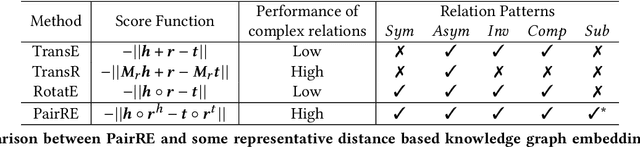
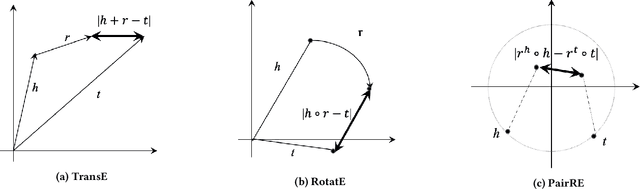
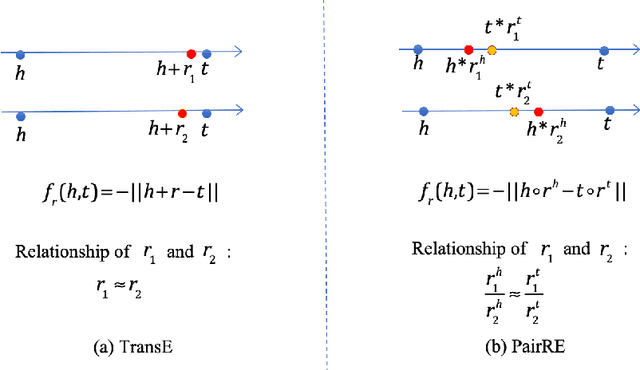
Distance based knowledge graph embedding methods show promising results on link prediction task, on which two topics have been widely studied: one is the ability to handle complex relations, such as N-to-1, 1-to-N and N-to-N, the other is to encode various relation patterns, such as symmetry/antisymmetry. However, the existing methods fail to solve these two problems at the same time, which leads to unsatisfactory results. To mitigate this problem, we propose PairRE, a model with improved expressiveness and low computational requirement. PairRE represents each relation with paired vectors, where these paired vectors project connected two entities to relation specific locations. Beyond its ability to solve the aforementioned two problems, PairRE is advantageous to represent subrelation as it can capture both the similarities and differences of subrelations effectively. Given simple constraints on relation representations, PairRE can be the first model that is capable of encoding symmetry/antisymmetry, inverse, composition and subrelation relations. Experiments on link prediction benchmarks show PairRE can achieve either state-of-the-art or highly competitive performances. In addition, PairRE has shown encouraging results for encoding subrelation.
CASS-NAT: CTC Alignment-based Single Step Non-autoregressive Transformer for Speech Recognition
Oct 28, 2020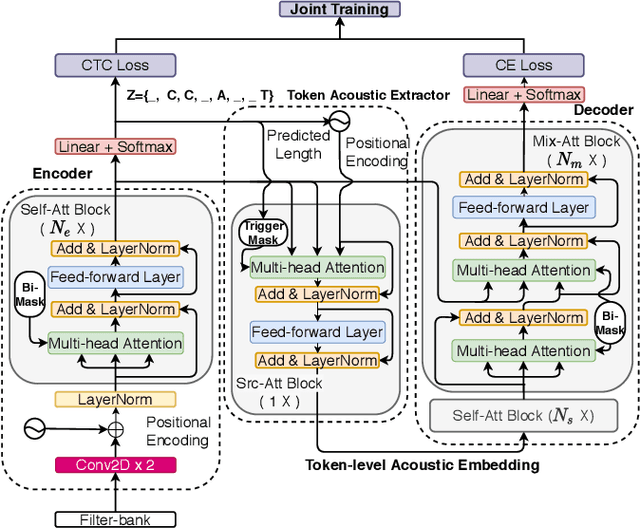
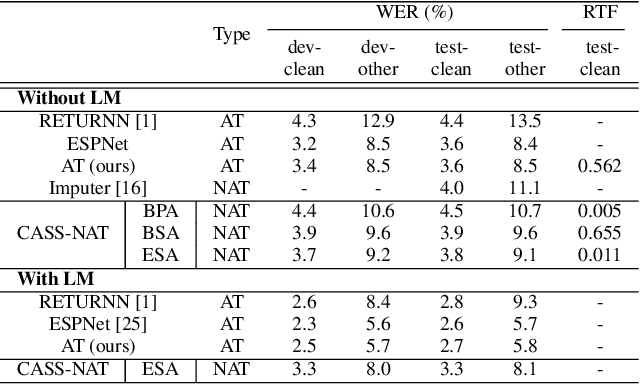


We propose a CTC alignment-based single step non-autoregressive transformer (CASS-NAT) for speech recognition. Specifically, the CTC alignment contains the information of (a) the number of tokens for decoder input, and (b) the time span of acoustics for each token. The information are used to extract acoustic representation for each token in parallel, referred to as token-level acoustic embedding which substitutes the word embedding in autoregressive transformer (AT) to achieve parallel generation in decoder. During inference, an error-based alignment sampling method is proposed to be applied to the CTC output space, reducing the WER and retaining the parallelism as well. Experimental results show that the proposed method achieves WERs of 3.8%/9.1% on Librispeech test clean/other dataset without an external LM, and a CER of 5.8% on Aishell1 Mandarin corpus, respectively1. Compared to the AT baseline, the CASS-NAT has a performance reduction on WER, but is 51.2x faster in terms of RTF. When decoding with an oracle CTC alignment, the lower bound of WER without LM reaches 2.3% on the test-clean set, indicating the potential of the proposed method.