 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-driven Semantic Segmentation
Jan 10, 2022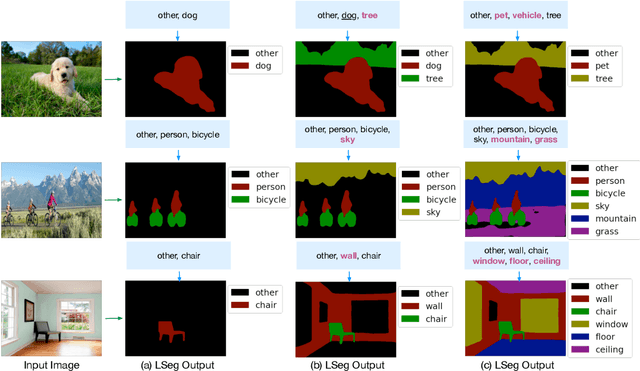
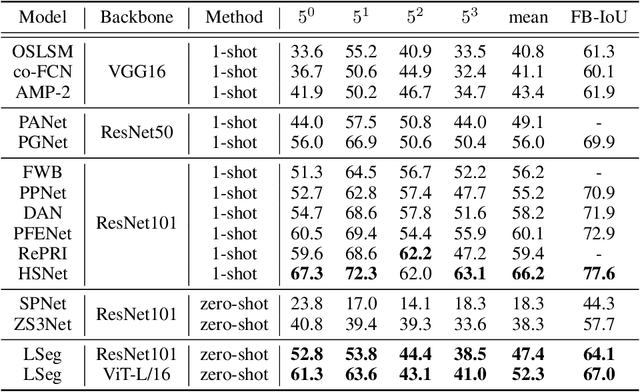
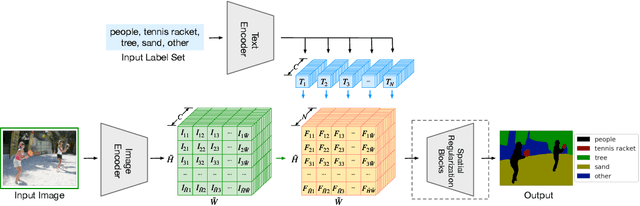
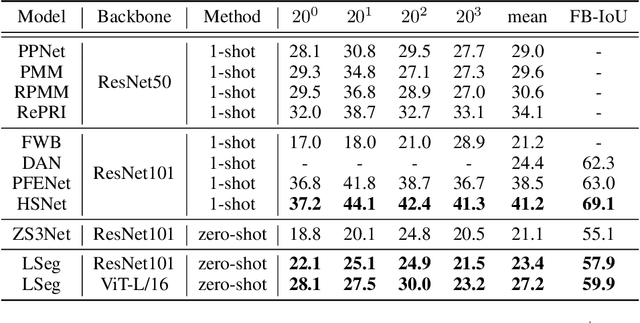
We present LSeg, a novel model for language-driven semantic image segmentation. LSeg uses a text encoder to compute embeddings of descriptive input labels (e.g., "grass" or "building") together with a transformer-based image encoder that computes dense per-pixel embeddings of the input image. The image encoder is trained with a contrastive objective to align pixel embeddings to the text embedding of the corresponding semantic class. The text embeddings provide a flexible label representation in which semantically similar labels map to similar regions in the embedding space (e.g., "cat" and "furry"). This allows LSeg to generalize to previously unseen categories at test time, without retraining or even requiring a single additional training sample. We demonstrate that our approach achieves highly competitive zero-shot performance compared to existing zero- and few-shot semantic segmentation methods, and even matches the accuracy of traditional segmentation algorithms when a fixed label set is provided. Code and demo are available at https://github.com/isl-org/lang-seg.
MSeg: A Composite Dataset for Multi-domain Semantic Segmentation
Dec 27, 2021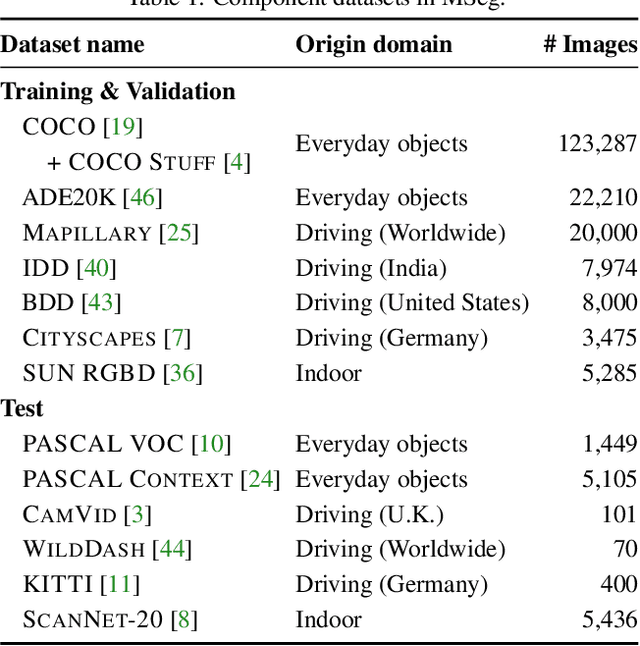
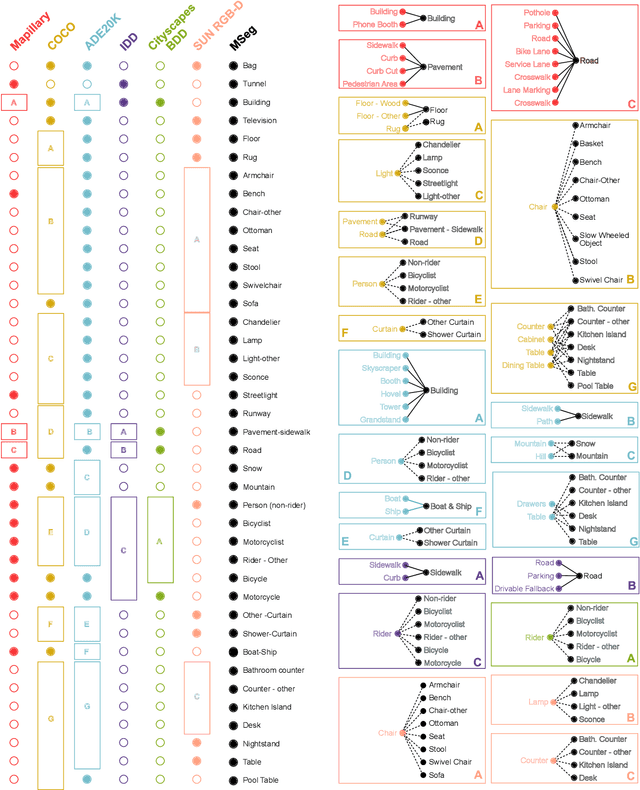
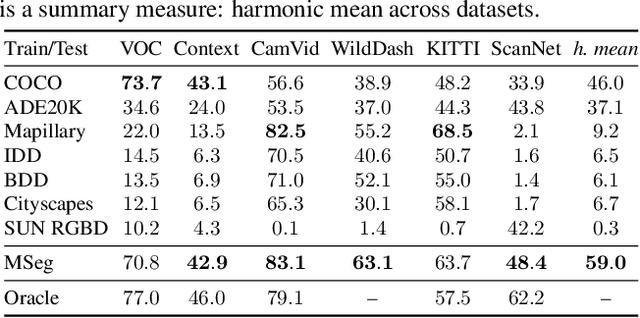
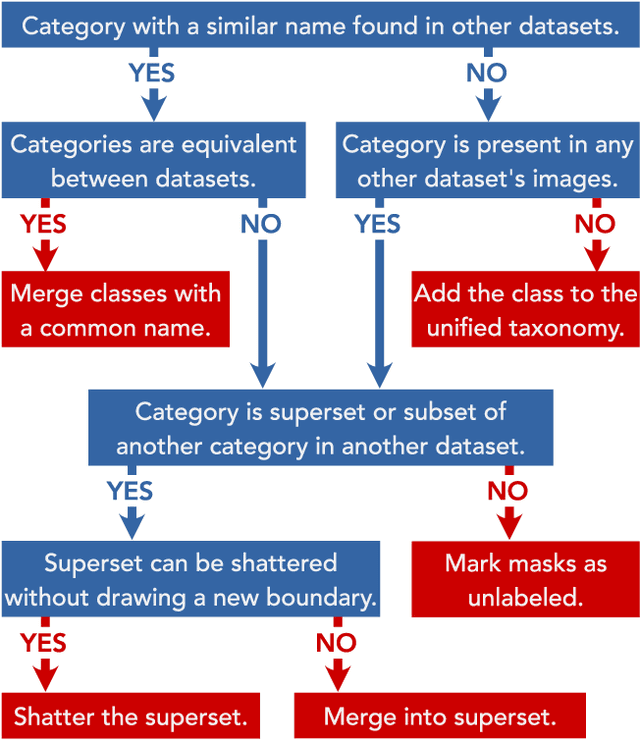
We present MSeg, a composite dataset that unifies semantic segmentation datasets from different domains. A naive merge of the constituent datasets yields poor performance due to inconsistent taxonomies and annotation practices. We reconcile the taxonomies and bring the pixel-level annotations into alignment by relabeling more than 220,000 object masks in more than 80,000 images, requiring more than 1.34 years of collective annotator effort. The resulting composite dataset enables training a single semantic segmentation model that functions effectively across domains and generalizes to datasets that were not seen during training. We adopt zero-shot cross-dataset transfer as a benchmark to systematically evaluate a model's robustness and show that MSeg training yields substantially more robust models in comparison to training on individual datasets or naive mixing of datasets without the presented contributions. A model trained on MSeg ranks first on the WildDash-v1 leaderboard for robust semantic segmentation, with no exposure to WildDash data during training. We evaluate our models in the 2020 Robust Vision Challenge (RVC) as an extreme generalization experiment. MSeg training sets include only three of the seven datasets in the RVC; more importantly, the evaluation taxonomy of RVC is different and more detailed. Surprisingly, our model shows competitive performance and ranks second. To evaluate how close we are to the grand aim of robust, efficient, and complete scene understanding, we go beyond semantic segmentation by training instance segmentation and panoptic segmentation models using our dataset. Moreover, we also evaluate various engineering design decisions and metrics, including resolution and computational efficiency. Although our models are far from this grand aim, our comprehensive evaluation is crucial for progress. We share all the models and code with the community.
Shape from Polarization for Complex Scenes in the Wild
Dec 21, 2021
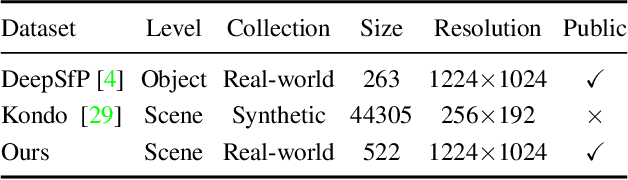

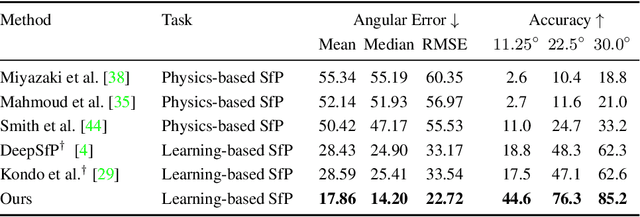
We present a new data-driven approach with physics-based priors to scene-level normal estimation from a single polarization image. Existing shape from polarization (SfP) works mainly focus on estimating the normal of a single object rather than complex scenes in the wild. A key barrier to high-quality scene-level SfP is the lack of real-world SfP data in complex scenes. Hence, we contribute the first real-world scene-level SfP dataset with paired input polarization images and ground-truth normal maps. Then we propose a learning-based framework with a multi-head self-attention module and viewing encoding, which is designed to handle increasing polarization ambiguities caused by complex materials and non-orthographic projection in scene-level SfP. Our trained model can be generalized to far-field outdoor scenes as the relationship between polarized light and surface normals is not affected by distance. Experimental results demonstrate that our approach significantly outperforms existing SfP models on two datasets. Our dataset and source code will be publicly available at \url{https://github.com/ChenyangLEI/sfp-wild}.
Non-deep Networks
Oct 14, 2021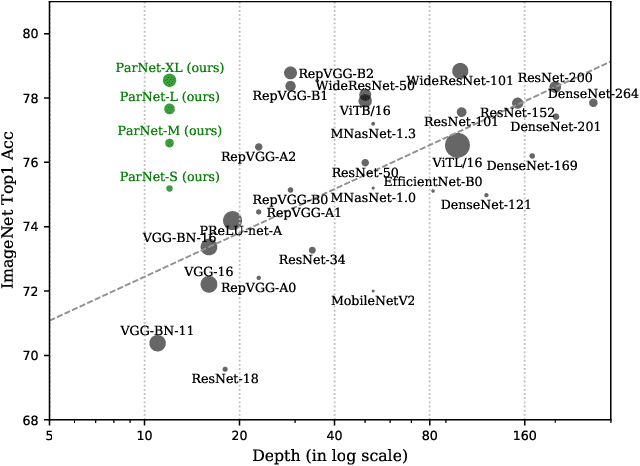
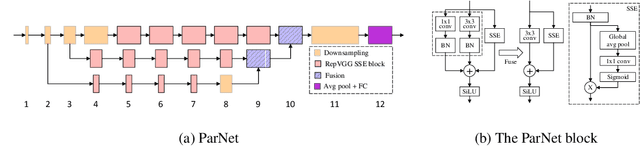
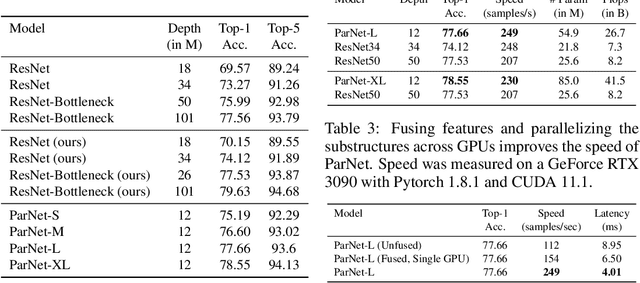

Depth is the hallmark of deep neural networks. But more depth means more sequential computation and higher latency. This begs the question -- is it possible to build high-performing "non-deep" neural networks? We show that it is. To do so, we use parallel subnetworks instead of stacking one layer after another. This helps effectively reduce depth while maintaining high performance. By utilizing parallel substructures, we show, for the first time, that a network with a depth of just 12 can achieve top-1 accuracy over 80% on ImageNet, 96% on CIFAR10, and 81% on CIFAR100. We also show that a network with a low-depth (12) backbone can achieve an AP of 48% on MS-COCO. We analyze the scaling rules for our design and show how to increase performance without changing the network's depth. Finally, we provide a proof of concept for how non-deep networks could be used to build low-latency recognition systems. Code is available at https://github.com/imankgoyal/NonDeepNetworks.
Learning High-Speed Flight in the Wild
Oct 11, 2021Quadrotors are agile. Unlike most other machines, they can traverse extremely complex environments at high speeds. To date, only expert human pilots have been able to fully exploit their capabilities. Autonomous operation with on-board sensing and computation has been limited to low speeds. State-of-the-art methods generally separate the navigation problem into subtasks: sensing, mapping, and planning. While this approach has proven successful at low speeds, the separation it builds upon can be problematic for high-speed navigation in cluttered environments. Indeed, the subtasks are executed sequentially, leading to increased processing latency and a compounding of errors through the pipeline. Here we propose an end-to-end approach that can autonomously fly quadrotors through complex natural and man-made environments at high speeds, with purely onboard sensing and computation. The key principle is to directly map noisy sensory observations to collision-free trajectories in a receding-horizon fashion. This direct mapping drastically reduces processing latency and increases robustness to noisy and incomplete perception. The sensorimotor mapping is performed by a convolutional network that is trained exclusively in simulation via privileged learning: imitating an expert with access to privileged information. By simulating realistic sensor noise, our approach achieves zero-shot transfer from simulation to challenging real-world environments that were never experienced during training: dense forests, snow-covered terrain, derailed trains, and collapsed buildings. Our work demonstrates that end-to-end policies trained in simulation enable high-speed autonomous flight through challenging environments, outperforming traditional obstacle avoidance pipelines.
* 16 pages (+7 supplementary)
ASH: A Modern Framework for Parallel Spatial Hashing in 3D Perception
Oct 01, 2021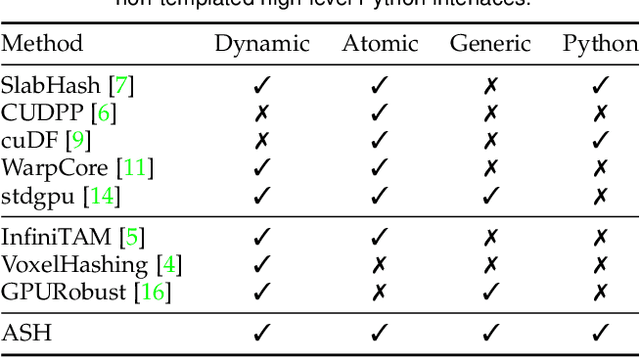
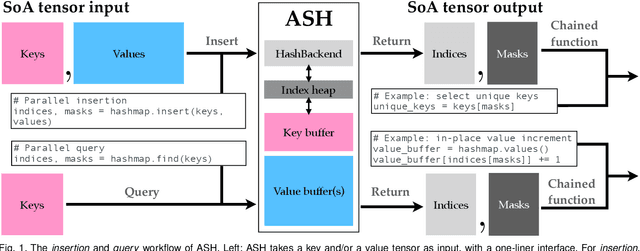
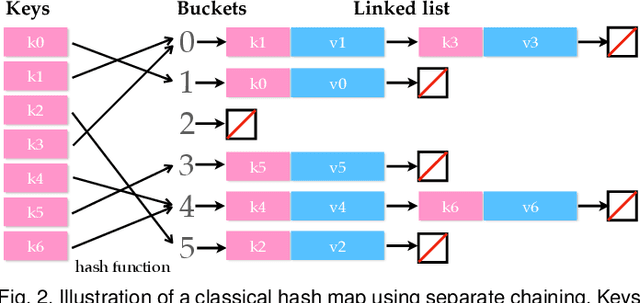

We present ASH, a modern and high-performance framework for parallel spatial hashing on GPU. Compared to existing GPU hash map implementations, ASH achieves higher performance, supports richer functionality, and requires fewer lines of code (LoC) when used for implementing spatially varying operations from volumetric geometry reconstruction to differentiable appearance reconstruction. Unlike existing GPU hash maps, the ASH framework provides a versatile tensor interface, hiding low-level details from the users. In addition, by decoupling the internal hashing data structures and key-value data in buffers, we offer direct access to spatially varying data via indices, enabling seamless integration to modern libraries such as PyTorch. To achieve this, we 1) detach stored key-value data from the low-level hash map implementation; 2) bridge the pointer-first low level data structures to index-first high-level tensor interfaces via an index heap; 3) adapt both generic and non-generic integer-only hash map implementations as backends to operate on multi-dimensional keys. We first profile our hash map against state-of-the-art hash maps on synthetic data to show the performance gain from this architecture. We then show that ASH can consistently achieve higher performance on various large-scale 3D perception tasks with fewer LoC by showcasing several applications, including 1) point cloud voxelization, 2) dense volumetric SLAM, 3) non-rigid point cloud registration and volumetric deformation, and 4) spatially varying geometry and appearance refinement. ASH and its example applications are open sourced in Open3D (http://www.open3d.org).
Physical Gradients for Deep Learning
Oct 01, 2021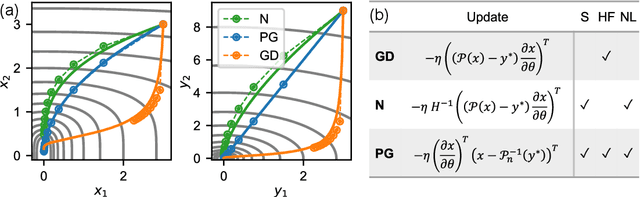
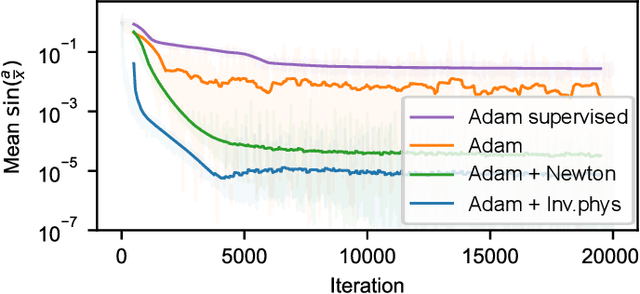
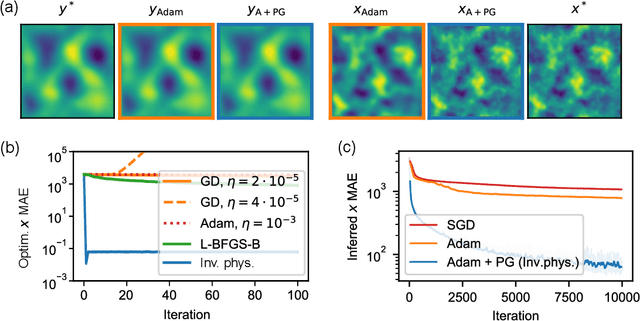
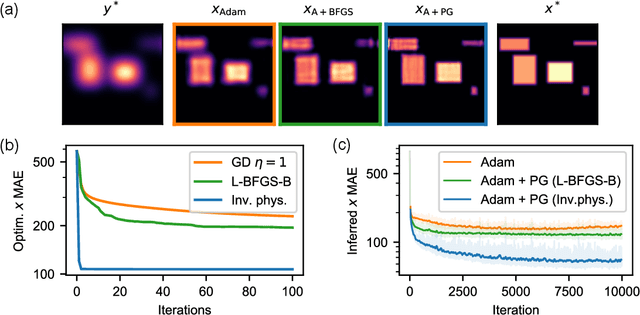
Solving inverse problems, such as parameter estimation and optimal control, is a vital part of science. Many experiments repeatedly collect data and employ machine learning algorithms to quickly infer solutions to the associated inverse problems. We find that state-of-the-art training techniques are not well-suited to many problems that involve physical processes since the magnitude and direction of the gradients can vary strongly. We propose a novel hybrid training approach that combines higher-order optimization methods with machine learning techniques. We replace the gradient of the physical process by a new construct, referred to as the physical gradient. This also allows us to introduce domain knowledge into training by incorporating priors about the solution space into the gradients. We demonstrate the capabilities of our method on a variety of canonical physical systems, showing that physical gradients yield significant improvements on a wide range of optimization and learning problems.
Efficient Differentiable Simulation of Articulated Bodies
Sep 16, 2021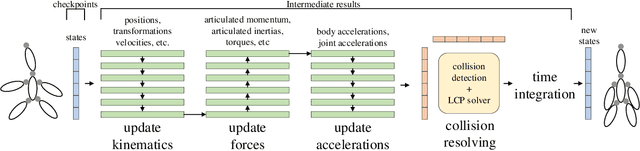
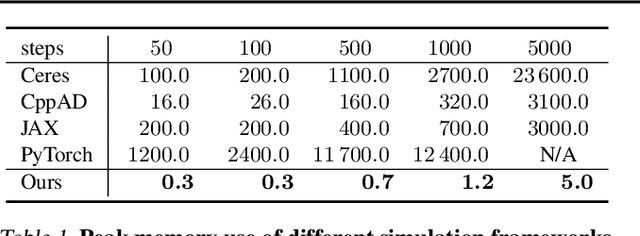
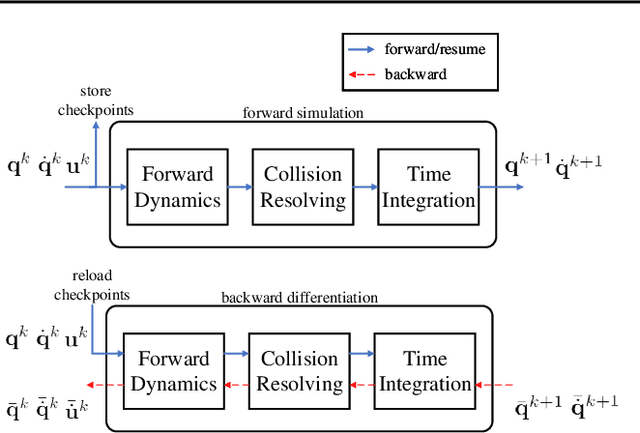
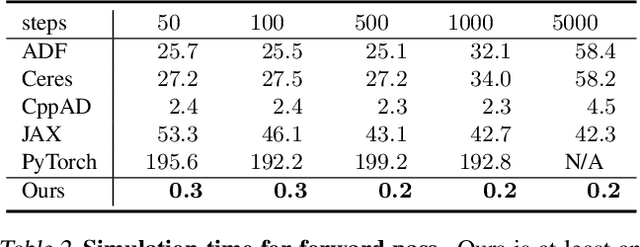
We present a method for efficient differentiable simulation of articulated bodies. This enables integration of articulated body dynamics into deep learning frameworks, and gradient-based optimization of neural networks that operate on articulated bodies. We derive the gradients of the forward dynamics using spatial algebra and the adjoint method. Our approach is an order of magnitude faster than autodiff tools. By only saving the initial states throughout the simulation process, our method reduces memory requirements by two orders of magnitude. We demonstrate the utility of efficient differentiable dynamics for articulated bodies in a variety of applications. We show that reinforcement learning with articulated systems can be accelerated using gradients provided by our method. In applications to control and inverse problems, gradient-based optimization enabled by our work accelerates convergence by more than an order of magnitude.
Online Continual Learning with Natural Distribution Shifts: An Empirical Study with Visual Data
Aug 20, 2021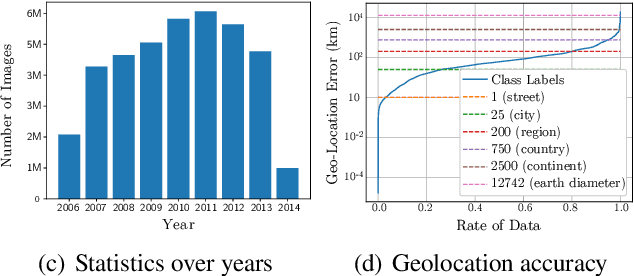
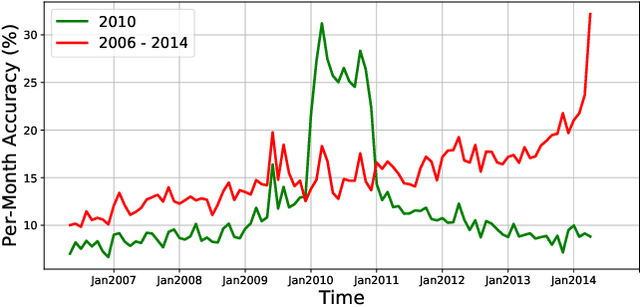
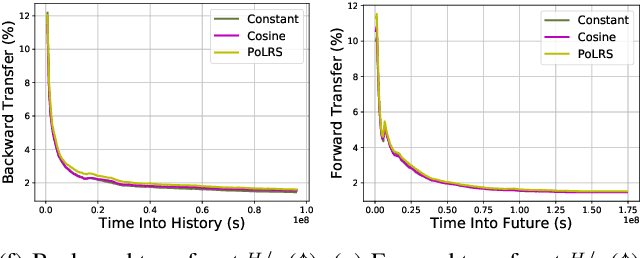
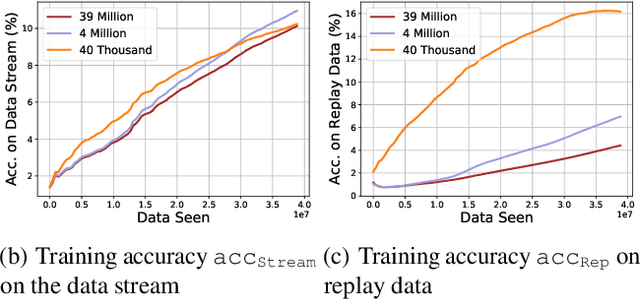
Continual learning is the problem of learning and retaining knowledge through time over multiple tasks and environments. Research has primarily focused on the incremental classification setting, where new tasks/classes are added at discrete time intervals. Such an "offline" setting does not evaluate the ability of agents to learn effectively and efficiently, since an agent can perform multiple learning epochs without any time limitation when a task is added. We argue that "online" continual learning, where data is a single continuous stream without task boundaries, enables evaluating both information retention and online learning efficacy. In online continual learning, each incoming small batch of data is first used for testing and then added to the training set, making the problem truly online. Trained models are later evaluated on historical data to assess information retention. We introduce a new benchmark for online continual visual learning that exhibits large scale and natural distribution shifts. Through a large-scale analysis, we identify critical and previously unobserved phenomena of gradient-based optimization in continual learning, and propose effective strategies for improving gradient-based online continual learning with real data. The source code and dataset are available in: https://github.com/IntelLabs/continuallearning.
Megaverse: Simulating Embodied Agents at One Million Experiences per Second
Jul 21, 2021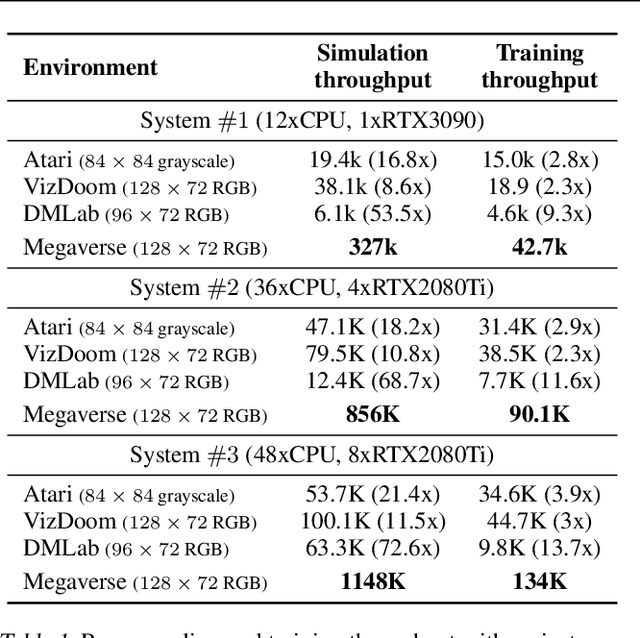
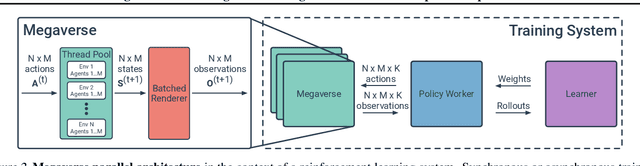
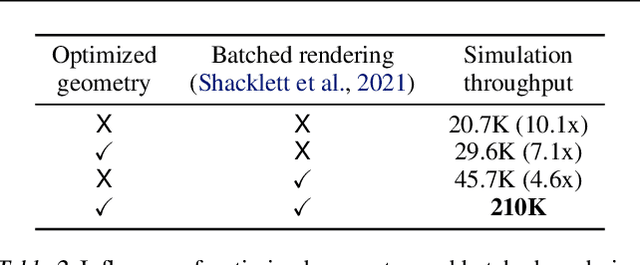
We present Megaverse, a new 3D simulation platform for reinforcement learning and embodied AI research. The efficient design of our engine enables physics-based simulation with high-dimensional egocentric observations at more than 1,000,000 actions per second on a single 8-GPU node. Megaverse is up to 70x faster than DeepMind Lab in fully-shaded 3D scenes with interactive objects. We achieve this high simulation performance by leveraging batched simulation, thereby taking full advantage of the massive parallelism of modern GPUs. We use Megaverse to build a new benchmark that consists of several single-agent and multi-agent tasks covering a variety of cognitive challenges. We evaluate model-free RL on this benchmark to provide baselines and facilitate future research. The source code is available at https://www.megaverse.info