 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Capability of Large Language Models to Measure Psychiatric Functioning
Aug 03, 2023
The current work investigates the capability of Large language models (LLMs) that are explicitly trained on large corpuses of medical knowledge (Med-PaLM 2) to predict psychiatric functioning from patient interviews and clinical descriptions without being trained to do so. To assess this, n = 145 depression and n =115 PTSD assessments and n = 46 clinical case studies across high prevalence/high comorbidity disorders (Depressive, Anxiety, Psychotic, trauma and stress, Addictive disorders) were analyzed using prompts to extract estimated clinical scores and diagnoses. Results demonstrate that Med-PaLM 2 is capable of assessing psychiatric functioning across a range of psychiatric conditions with the strongest performance being the prediction of depression scores based on standardized assessments (Accuracy range= 0.80 - 0.84) which were statistically indistinguishable from human clinical raters t(1,144) = 1.20; p = 0.23. Results show the potential for general clinical language models to flexibly predict psychiatric risk based on free descriptions of functioning from both patients and clinicians.
Towards Generalist Biomedical AI
Jul 26, 2023



Medicine is inherently multimodal, with rich data modalities spanning text, imaging, genomics, and more. Generalist biomedical artificial intelligence (AI) systems that flexibly encode, integrate, and interpret this data at scale can potentially enable impactful applications ranging from scientific discovery to care delivery. To enable the development of these models, we first curate MultiMedBench, a new multimodal biomedical benchmark. MultiMedBench encompasses 14 diverse tasks such as medical question answering, mammography and dermatology image interpretation, radiology report generation and summarization, and genomic variant calling. We then introduce Med-PaLM Multimodal (Med-PaLM M), our proof of concept for a generalist biomedical AI system. Med-PaLM M is a large multimodal generative model that flexibly encodes and interprets biomedical data including clinical language, imaging, and genomics with the same set of model weights. Med-PaLM M reaches performance competitive with or exceeding the state of the art on all MultiMedBench tasks, often surpassing specialist models by a wide margin. We also report examples of zero-shot generalization to novel medical concepts and tasks, positive transfer learning across tasks, and emergent zero-shot medical reasoning. To further probe the capabilities and limitations of Med-PaLM M, we conduct a radiologist evaluation of model-generated (and human) chest X-ray reports and observe encouraging performance across model scales. In a side-by-side ranking on 246 retrospective chest X-rays, clinicians express a pairwise preference for Med-PaLM M reports over those produced by radiologists in up to 40.50% of cases, suggesting potential clinical utility. While considerable work is needed to validate these models in real-world use cases, our results represent a milestone towards the development of generalist biomedical AI systems.
Towards Expert-Level Medical Question Answering with Large Language Models
May 16, 2023



Recent artificial intelligence (AI) systems have reached milestones in "grand challenges" ranging from Go to protein-folding. The capability to retrieve medical knowledge, reason over it, and answer medical questions comparably to physicians has long been viewed as one such grand challenge. Large language models (LLMs) have catalyzed significant progress in medical question answering; Med-PaLM was the first model to exceed a "passing" score in US Medical Licensing Examination (USMLE) style questions with a score of 67.2% on the MedQA dataset. However, this and other prior work suggested significant room for improvement, especially when models' answers were compared to clinicians' answers. Here we present Med-PaLM 2, which bridges these gaps by leveraging a combination of base LLM improvements (PaLM 2), medical domain finetuning, and prompting strategies including a novel ensemble refinement approach. Med-PaLM 2 scored up to 86.5% on the MedQA dataset, improving upon Med-PaLM by over 19% and setting a new state-of-the-art. We also observed performance approaching or exceeding state-of-the-art across MedMCQA, PubMedQA, and MMLU clinical topics datasets. We performed detailed human evaluations on long-form questions along multiple axes relevant to clinical applications. In pairwise comparative ranking of 1066 consumer medical questions, physicians preferred Med-PaLM 2 answers to those produced by physicians on eight of nine axes pertaining to clinical utility (p < 0.001). We also observed significant improvements compared to Med-PaLM on every evaluation axis (p < 0.001) on newly introduced datasets of 240 long-form "adversarial" questions to probe LLM limitations. While further studies are necessary to validate the efficacy of these models in real-world settings, these results highlight rapid progress towards physician-level performance in medical question answering.
Large Language Models Encode Clinical Knowledge
Dec 26, 2022Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but the quality bar for medical and clinical applications is high. Today, attempts to assess models' clinical knowledge typically rely on automated evaluations on limited benchmarks. There is no standard to evaluate model predictions and reasoning across a breadth of tasks. To address this, we present MultiMedQA, a benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries; and HealthSearchQA, a new free-response dataset of medical questions searched online. We propose a framework for human evaluation of model answers along multiple axes including factuality, precision, possible harm, and bias. In addition, we evaluate PaLM (a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM, on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA, MedMCQA, PubMedQA, MMLU clinical topics), including 67.6% accuracy on MedQA (US Medical License Exam questions), surpassing prior state-of-the-art by over 17%. However, human evaluation reveals key gaps in Flan-PaLM responses. To resolve this we introduce instruction prompt tuning, a parameter-efficient approach for aligning LLMs to new domains using a few exemplars. The resulting model, Med-PaLM, performs encouragingly, but remains inferior to clinicians. We show that comprehension, recall of knowledge, and medical reasoning improve with model scale and instruction prompt tuning, suggesting the potential utility of LLMs in medicine. Our human evaluations reveal important limitations of today's models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLM models for clinical applications.
Robust and Efficient Medical Imaging with Self-Supervision
May 19, 2022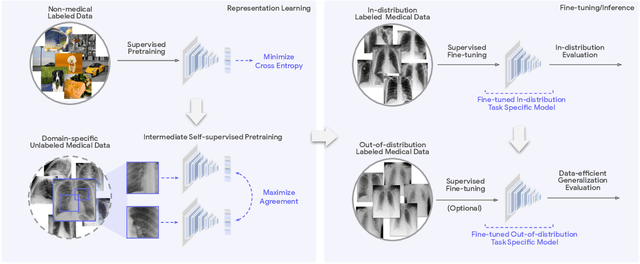
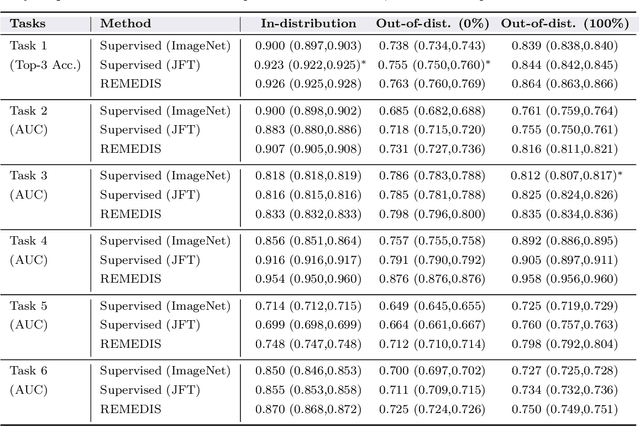
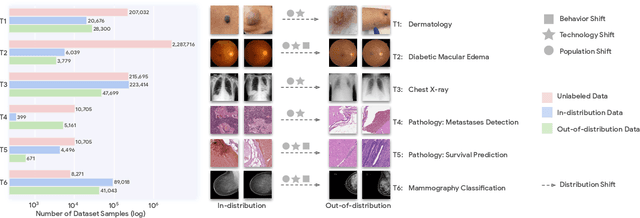

Recent progress in Medical Artificial Intelligence (AI) has delivered systems that can reach clinical expert level performance. However, such systems tend to demonstrate sub-optimal "out-of-distribution" performance when evaluated in clinical settings different from the training environment. A common mitigation strategy is to develop separate systems for each clinical setting using site-specific data [1]. However, this quickly becomes impractical as medical data is time-consuming to acquire and expensive to annotate [2]. Thus, the problem of "data-efficient generalization" presents an ongoing difficulty for Medical AI development. Although progress in representation learning shows promise, their benefits have not been rigorously studied, specifically for out-of-distribution settings. To meet these challenges, we present REMEDIS, a unified representation learning strategy to improve robustness and data-efficiency of medical imaging AI. REMEDIS uses a generic combination of large-scale supervised transfer learning with self-supervised learning and requires little task-specific customization. We study a diverse range of medical imaging tasks and simulate three realistic application scenarios using retrospective data. REMEDIS exhibits significantly improved in-distribution performance with up to 11.5% relative improvement in diagnostic accuracy over a strong supervised baseline. More importantly, our strategy leads to strong data-efficient generalization of medical imaging AI, matching strong supervised baselines using between 1% to 33% of retraining data across tasks. These results suggest that REMEDIS can significantly accelerate the life-cycle of medical imaging AI development thereby presenting an important step forward for medical imaging AI to deliver broad impact.
Maintaining fairness across distribution shift: do we have viable solutions for real-world applications?
Feb 02, 2022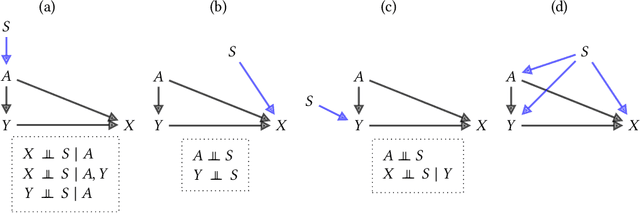
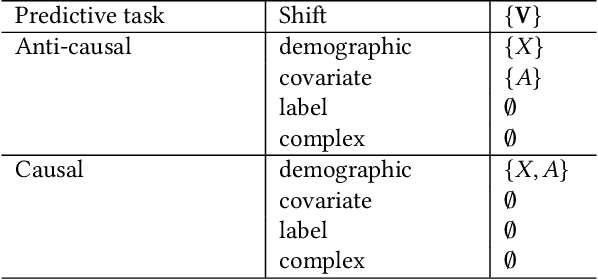
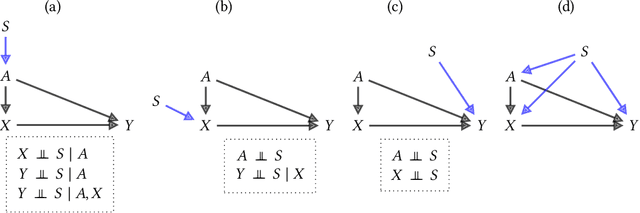
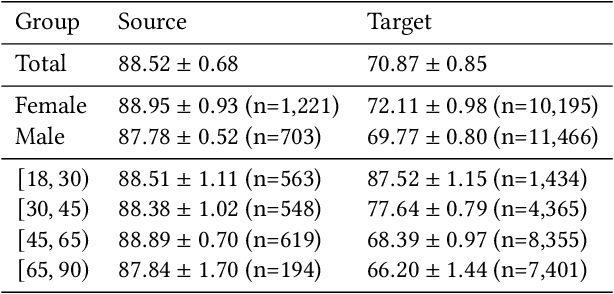
Fairness and robustness are often considered as orthogonal dimensions when evaluating machine learning models. However, recent work has revealed interactions between fairness and robustness, showing that fairness properties are not necessarily maintained under distribution shift. In healthcare settings, this can result in e.g. a model that performs fairly according to a selected metric in "hospital A" showing unfairness when deployed in "hospital B". While a nascent field has emerged to develop provable fair and robust models, it typically relies on strong assumptions about the shift, limiting its impact for real-world applications. In this work, we explore the settings in which recently proposed mitigation strategies are applicable by referring to a causal framing. Using examples of predictive models in dermatology and electronic health records, we show that real-world applications are complex and often invalidate the assumptions of such methods. Our work hence highlights technical, practical, and engineering gaps that prevent the development of robustly fair machine learning models for real-world applications. Finally, we discuss potential remedies at each step of the machine learning pipeline.
MedPerf: Open Benchmarking Platform for Medical Artificial Intelligence using Federated Evaluation
Oct 08, 2021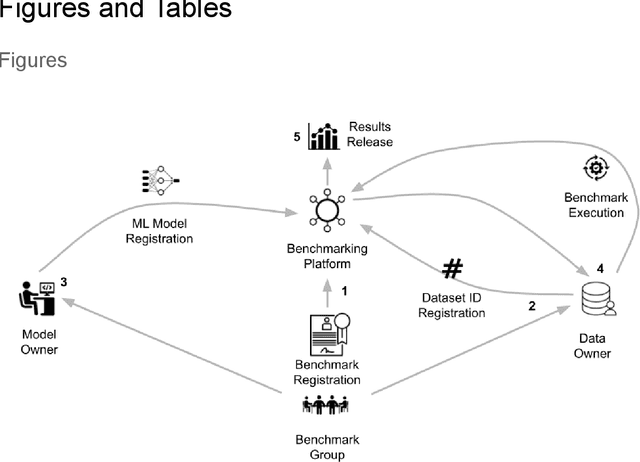
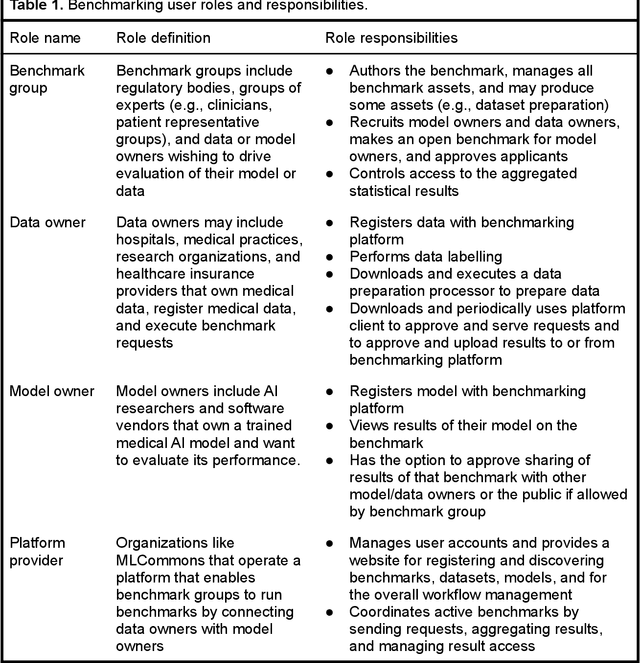
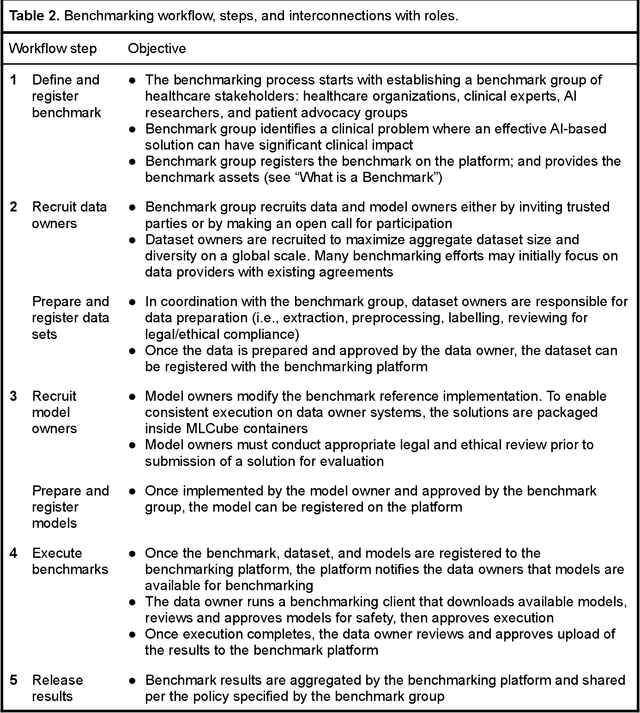
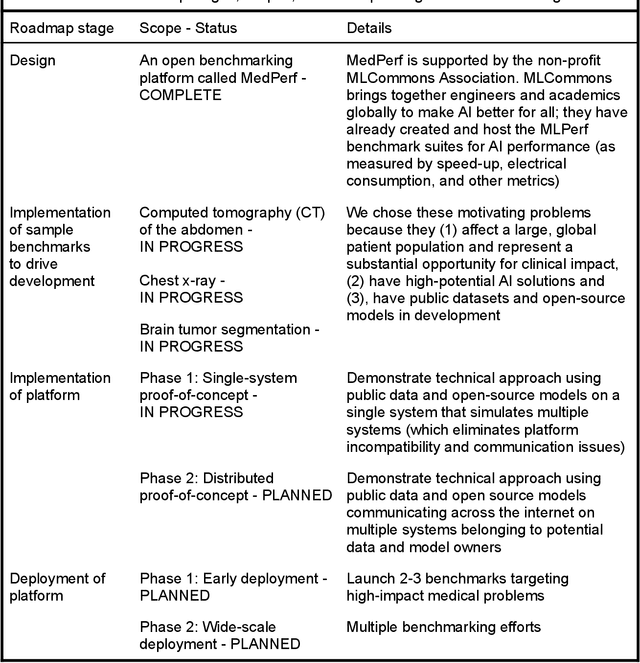
Medical AI has tremendous potential to advance healthcare by supporting the evidence-based practice of medicine, personalizing patient treatment, reducing costs, and improving provider and patient experience. We argue that unlocking this potential requires a systematic way to measure the performance of medical AI models on large-scale heterogeneous data. To meet this need, we are building MedPerf, an open framework for benchmarking machine learning in the medical domain. MedPerf will enable federated evaluation in which models are securely distributed to different facilities for evaluation, thereby empowering healthcare organizations to assess and verify the performance of AI models in an efficient and human-supervised process, while prioritizing privacy. We describe the current challenges healthcare and AI communities face, the need for an open platform, the design philosophy of MedPerf, its current implementation status, and our roadmap. We call for researchers and organizations to join us in creating the MedPerf open benchmarking platform.
Does Your Dermatology Classifier Know What It Doesn't Know? Detecting the Long-Tail of Unseen Conditions
Apr 08, 2021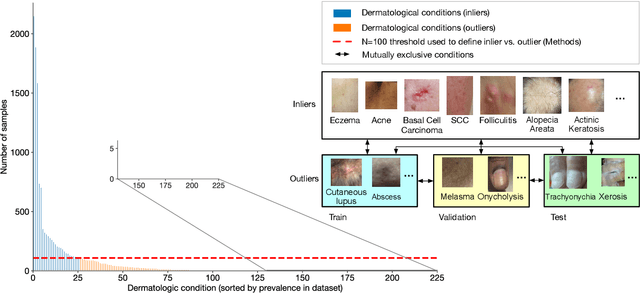
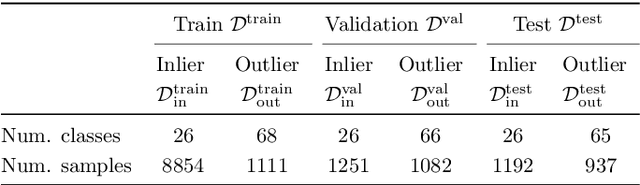
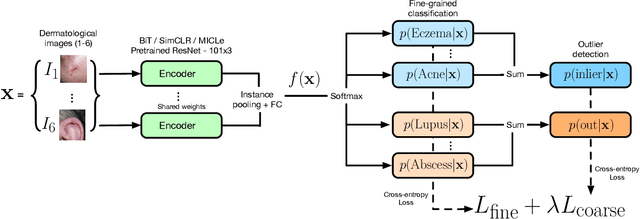
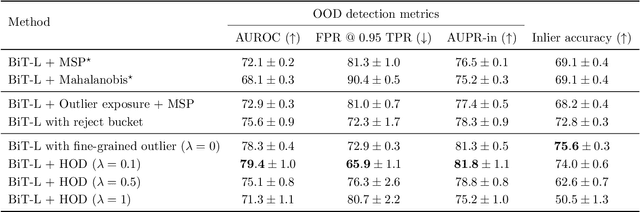
We develop and rigorously evaluate a deep learning based system that can accurately classify skin conditions while detecting rare conditions for which there is not enough data available for training a confident classifier. We frame this task as an out-of-distribution (OOD) detection problem. Our novel approach, hierarchical outlier detection (HOD) assigns multiple abstention classes for each training outlier class and jointly performs a coarse classification of inliers vs. outliers, along with fine-grained classification of the individual classes. We demonstrate the effectiveness of the HOD loss in conjunction with modern representation learning approaches (BiT, SimCLR, MICLe) and explore different ensembling strategies for further improving the results. We perform an extensive subgroup analysis over conditions of varying risk levels and different skin types to investigate how the OOD detection performance changes over each subgroup and demonstrate the gains of our framework in comparison to baselines. Finally, we introduce a cost metric to approximate downstream clinical impact. We use this cost metric to compare the proposed method against a baseline system, thereby making a stronger case for the overall system effectiveness in a real-world deployment scenario.
Supervised Transfer Learning at Scale for Medical Imaging
Jan 21, 2021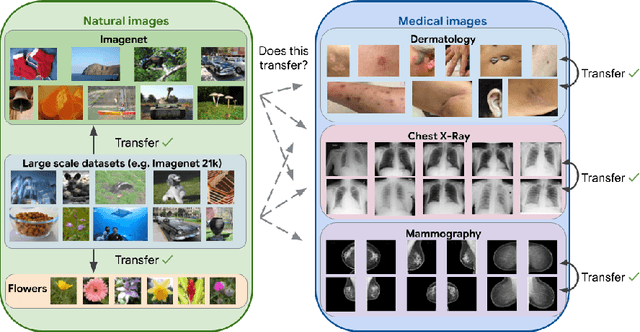
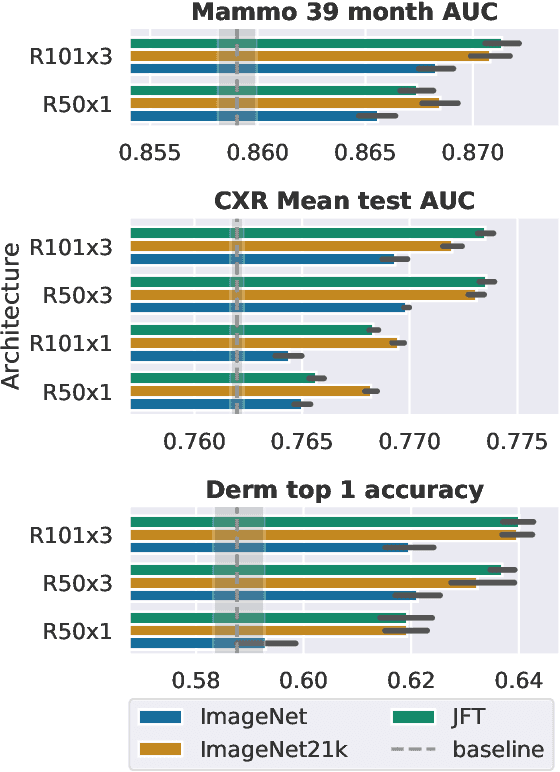
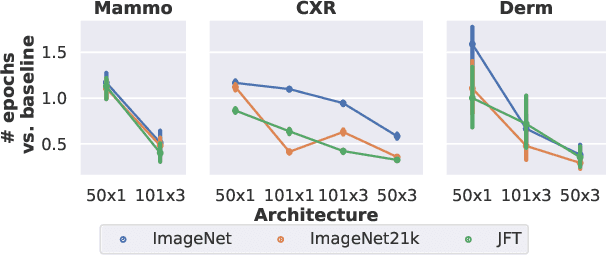
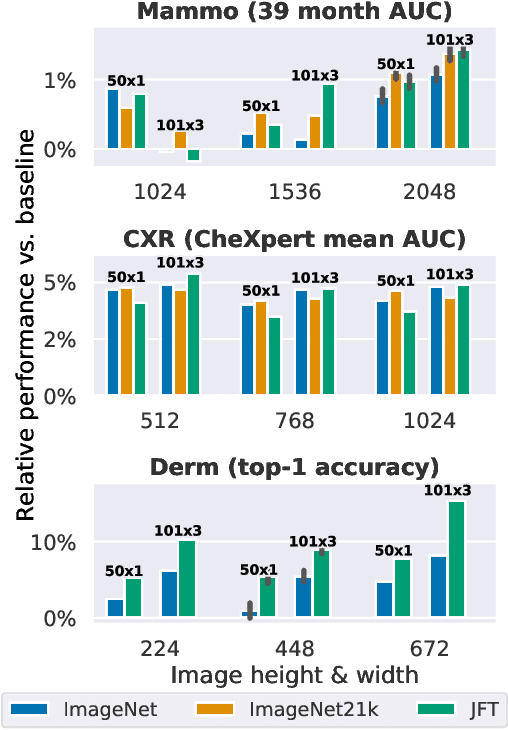
Transfer learning is a standard technique to improve performance on tasks with limited data. However, for medical imaging, the value of transfer learning is less clear. This is likely due to the large domain mismatch between the usual natural-image pre-training (e.g. ImageNet) and medical images. However, recent advances in transfer learning have shown substantial improvements from scale. We investigate whether modern methods can change the fortune of transfer learning for medical imaging. For this, we study the class of large-scale pre-trained networks presented by Kolesnikov et al. on three diverse imaging tasks: chest radiography, mammography, and dermatology. We study both transfer performance and critical properties for the deployment in the medical domain, including: out-of-distribution generalization, data-efficiency, sub-group fairness, and uncertainty estimation. Interestingly, we find that for some of these properties transfer from natural to medical images is indeed extremely effective, but only when performed at sufficient scale.
Big Self-Supervised Models Advance Medical Image Classification
Jan 13, 2021
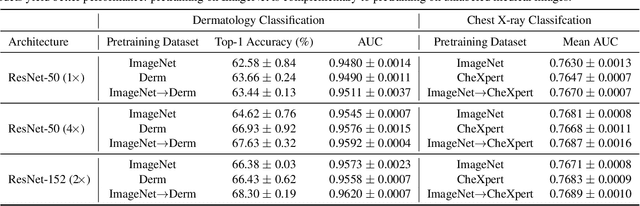
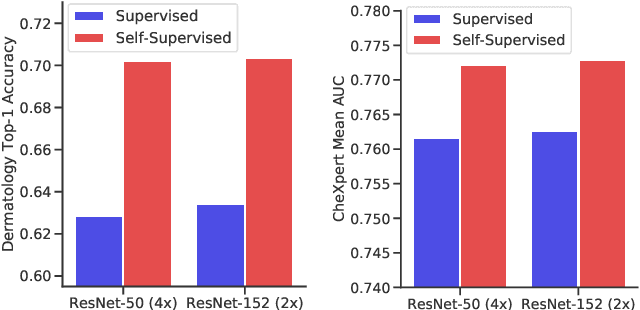
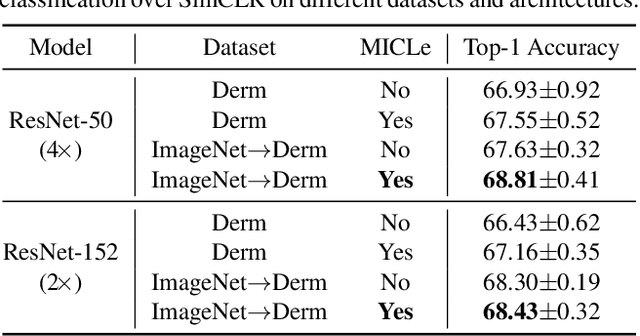
Self-supervised pretraining followed by supervised fine-tuning has seen success in image recognition, especially when labeled examples are scarce, but has received limited attention in medical image analysis. This paper studies the effectiveness of self-supervised learning as a pretraining strategy for medical image classification. We conduct experiments on two distinct tasks: dermatology skin condition classification from digital camera images and multi-label chest X-ray classification, and demonstrate that self-supervised learning on ImageNet, followed by additional self-supervised learning on unlabeled domain-specific medical images significantly improves the accuracy of medical image classifiers. We introduce a novel Multi-Instance Contrastive Learning (MICLe) method that uses multiple images of the underlying pathology per patient case, when available, to construct more informative positive pairs for self-supervised learning. Combining our contributions, we achieve an improvement of 6.7% in top-1 accuracy and an improvement of 1.1% in mean AUC on dermatology and chest X-ray classification respectively, outperforming strong supervised baselines pretrained on ImageNet. In addition, we show that big self-supervised models are robust to distribution shift and can learn efficiently with a small number of labeled medical images.