 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Alignment of Behavioral Dispositions in LLMs
Feb 11, 2026As LLMs integrate into our daily lives, understanding their behavior becomes essential. In this work, we focus on behavioral dispositions$-$the underlying tendencies that shape responses in social contexts$-$and introduce a framework to study how closely the dispositions expressed by LLMs align with those of humans. Our approach is grounded in established psychological questionnaires but adapts them for LLMs by transforming human self-report statements into Situational Judgment Tests (SJTs). These SJTs assess behavior by eliciting natural recommendations in realistic user-assistant scenarios. We generate 2,500 SJTs, each validated by three human annotators, and collect preferred actions from 10 annotators per SJT, from a large pool of 550 participants. In a comprehensive study involving 25 LLMs, we find that models often do not reflect the distribution of human preferences: (1) in scenarios with low human consensus, LLMs consistently exhibit overconfidence in a single response; (2) when human consensus is high, smaller models deviate significantly, and even some frontier models do not reflect the consensus in 15-20% of cases; (3) traits can exhibit cross-LLM patterns, e.g., LLMs may encourage emotion expression in contexts where human consensus favors composure. Lastly, mapping psychometric statements directly to behavioral scenarios presents a unique opportunity to evaluate the predictive validity of self-reports, revealing considerable gaps between LLMs' stated values and their revealed behavior.
Understanding challenges to the interpretation of disaggregated evaluations of algorithmic fairness
Jun 04, 2025Disaggregated evaluation across subgroups is critical for assessing the fairness of machine learning models, but its uncritical use can mislead practitioners. We show that equal performance across subgroups is an unreliable measure of fairness when data are representative of the relevant populations but reflective of real-world disparities. Furthermore, when data are not representative due to selection bias, both disaggregated evaluation and alternative approaches based on conditional independence testing may be invalid without explicit assumptions regarding the bias mechanism. We use causal graphical models to predict metric stability across subgroups under different data generating processes. Our framework suggests complementing disaggregated evaluations with explicit causal assumptions and analysis to control for confounding and distribution shift, including conditional independence testing and weighted performance estimation. These findings have broad implications for how practitioners design and interpret model assessments given the ubiquity of disaggregated evaluation.
Boosting the interpretability of clinical risk scores with intervention predictions
Jul 06, 2022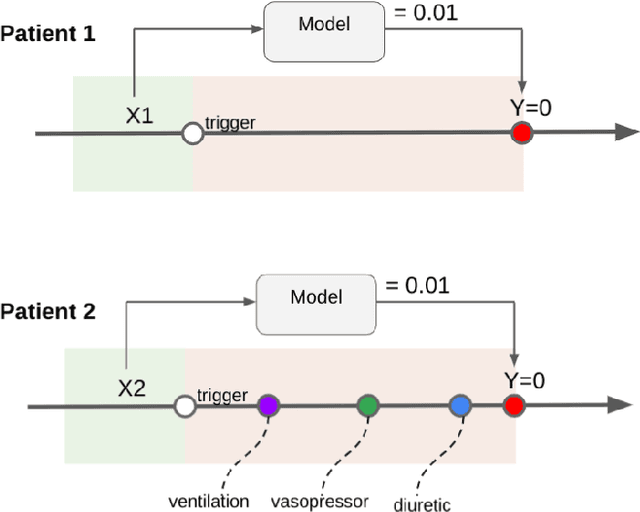
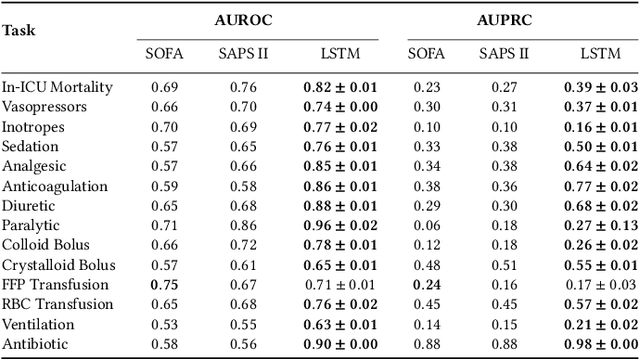
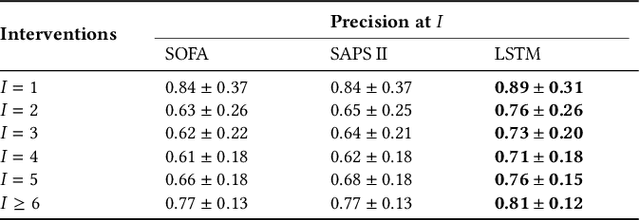
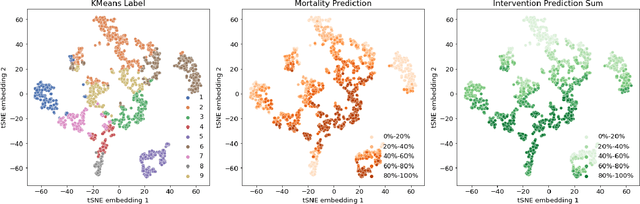
Machine learning systems show significant promise for forecasting patient adverse events via risk scores. However, these risk scores implicitly encode assumptions about future interventions that the patient is likely to receive, based on the intervention policy present in the training data. Without this important context, predictions from such systems are less interpretable for clinicians. We propose a joint model of intervention policy and adverse event risk as a means to explicitly communicate the model's assumptions about future interventions. We develop such an intervention policy model on MIMIC-III, a real world de-identified ICU dataset, and discuss some use cases that highlight the utility of this approach. We show how combining typical risk scores, such as the likelihood of mortality, with future intervention probability scores leads to more interpretable clinical predictions.
Disability prediction in multiple sclerosis using performance outcome measures and demographic data
Apr 08, 2022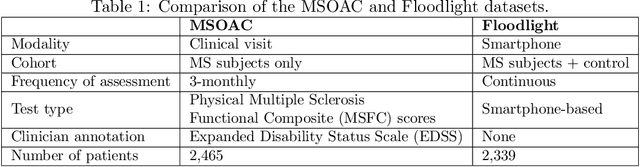
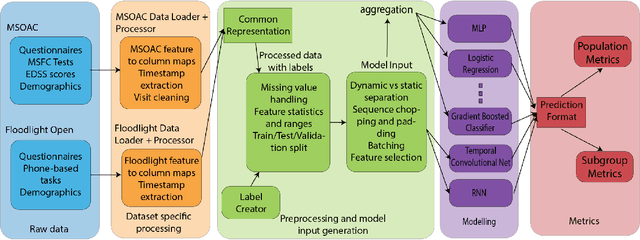
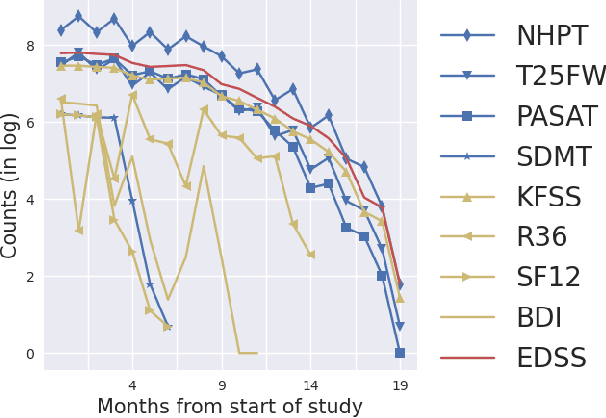
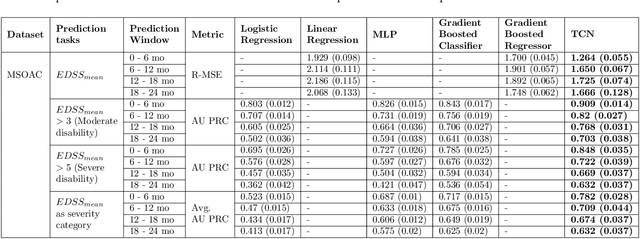
Literature on machine learning for multiple sclerosis has primarily focused on the use of neuroimaging data such as magnetic resonance imaging and clinical laboratory tests for disease identification. However, studies have shown that these modalities are not consistent with disease activity such as symptoms or disease progression. Furthermore, the cost of collecting data from these modalities is high, leading to scarce evaluations. In this work, we used multi-dimensional, affordable, physical and smartphone-based performance outcome measures (POM) in conjunction with demographic data to predict multiple sclerosis disease progression. We performed a rigorous benchmarking exercise on two datasets and present results across 13 clinically actionable prediction endpoints and 6 machine learning models. To the best of our knowledge, our results are the first to show that it is possible to predict disease progression using POMs and demographic data in the context of both clinical trials and smartphone-base studies by using two datasets. Moreover, we investigate our models to understand the impact of different POMs and demographics on model performance through feature ablation studies. We also show that model performance is similar across different demographic subgroups (based on age and sex). To enable this work, we developed an end-to-end reusable pre-processing and machine learning framework which allows quicker experimentation over disparate MS datasets.
Maintaining fairness across distribution shift: do we have viable solutions for real-world applications?
Feb 02, 2022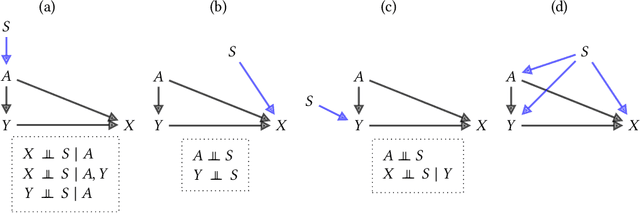
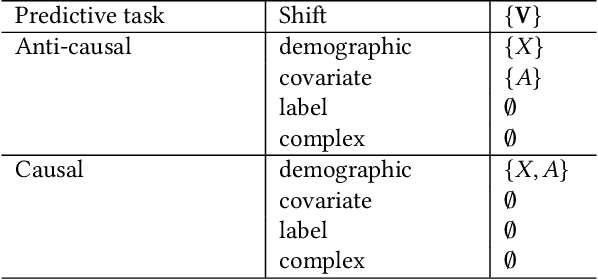
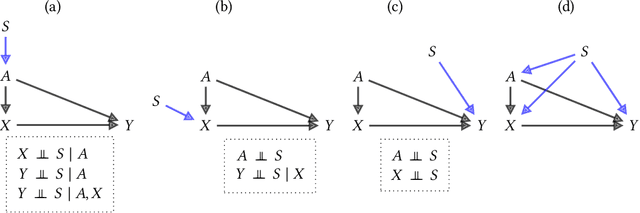
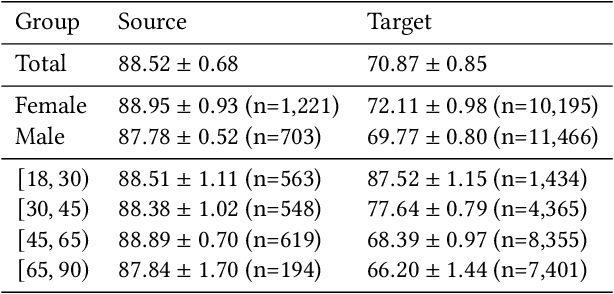
Fairness and robustness are often considered as orthogonal dimensions when evaluating machine learning models. However, recent work has revealed interactions between fairness and robustness, showing that fairness properties are not necessarily maintained under distribution shift. In healthcare settings, this can result in e.g. a model that performs fairly according to a selected metric in "hospital A" showing unfairness when deployed in "hospital B". While a nascent field has emerged to develop provable fair and robust models, it typically relies on strong assumptions about the shift, limiting its impact for real-world applications. In this work, we explore the settings in which recently proposed mitigation strategies are applicable by referring to a causal framing. Using examples of predictive models in dermatology and electronic health records, we show that real-world applications are complex and often invalidate the assumptions of such methods. Our work hence highlights technical, practical, and engineering gaps that prevent the development of robustly fair machine learning models for real-world applications. Finally, we discuss potential remedies at each step of the machine learning pipeline.