 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence Functions for Sequence Tagging Models
Oct 25, 2022



Many language tasks (e.g., Named Entity Recognition, Part-of-Speech tagging, and Semantic Role Labeling) are naturally framed as sequence tagging problems. However, there has been comparatively little work on interpretability methods for sequence tagging models. In this paper, we extend influence functions - which aim to trace predictions back to the training points that informed them - to sequence tagging tasks. We define the influence of a training instance segment as the effect that perturbing the labels within this segment has on a test segment level prediction. We provide an efficient approximation to compute this, and show that it tracks with the true segment influence, measured empirically. We show the practical utility of segment influence by using the method to identify systematic annotation errors in two named entity recognition corpora. Code to reproduce our results is available at https://github.com/successar/Segment_Influence_Functions.
Certified Neural Network Watermarks with Randomized Smoothing
Jul 16, 2022

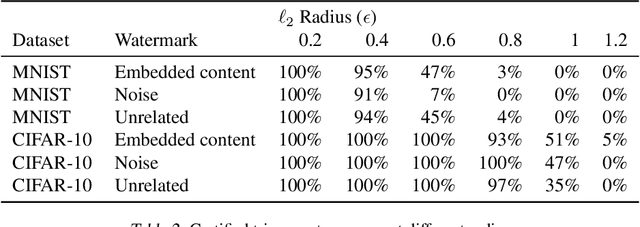

Watermarking is a commonly used strategy to protect creators' rights to digital images, videos and audio. Recently, watermarking methods have been extended to deep learning models -- in principle, the watermark should be preserved when an adversary tries to copy the model. However, in practice, watermarks can often be removed by an intelligent adversary. Several papers have proposed watermarking methods that claim to be empirically resistant to different types of removal attacks, but these new techniques often fail in the face of new or better-tuned adversaries. In this paper, we propose a certifiable watermarking method. Using the randomized smoothing technique proposed in Chiang et al., we show that our watermark is guaranteed to be unremovable unless the model parameters are changed by more than a certain l2 threshold. In addition to being certifiable, our watermark is also empirically more robust compared to previous watermarking methods. Our experiments can be reproduced with code at https://github.com/arpitbansal297/Certified_Watermarks
* ICML 2022
SelfDoc: Self-Supervised Document Representation Learning
Jun 07, 2021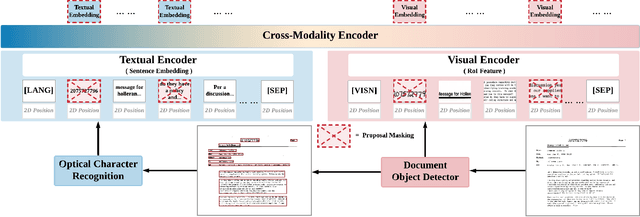
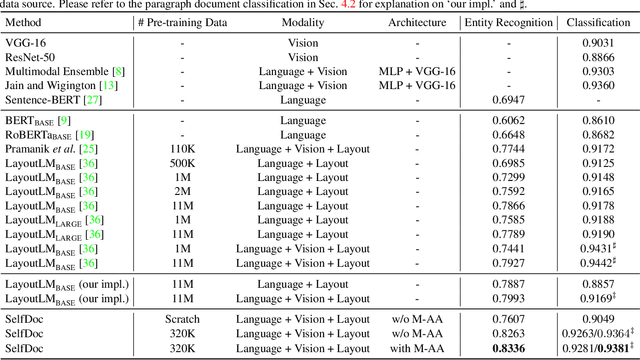
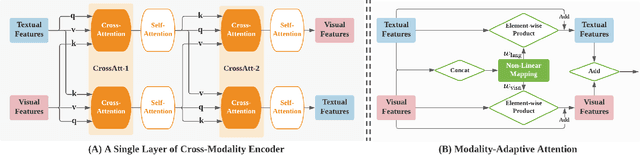

We propose SelfDoc, a task-agnostic pre-training framework for document image understanding. Because documents are multimodal and are intended for sequential reading, our framework exploits the positional, textual, and visual information of every semantically meaningful component in a document, and it models the contextualization between each block of content. Unlike existing document pre-training models, our model is coarse-grained instead of treating individual words as input, therefore avoiding an overly fine-grained with excessive contextualization. Beyond that, we introduce cross-modal learning in the model pre-training phase to fully leverage multimodal information from unlabeled documents. For downstream usage, we propose a novel modality-adaptive attention mechanism for multimodal feature fusion by adaptively emphasizing language and vision signals. Our framework benefits from self-supervised pre-training on documents without requiring annotations by a feature masking training strategy. It achieves superior performance on multiple downstream tasks with significantly fewer document images used in the pre-training stage compared to previous works.
TABBIE: Pretrained Representations of Tabular Data
May 06, 2021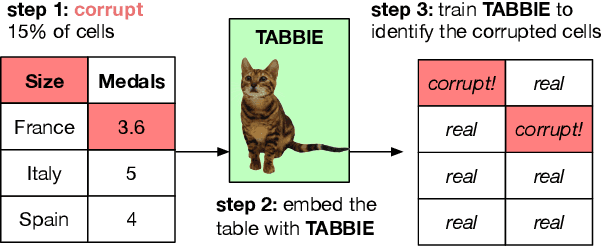
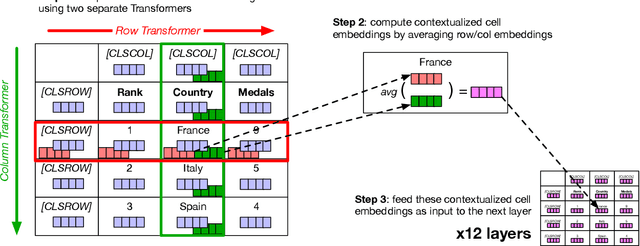
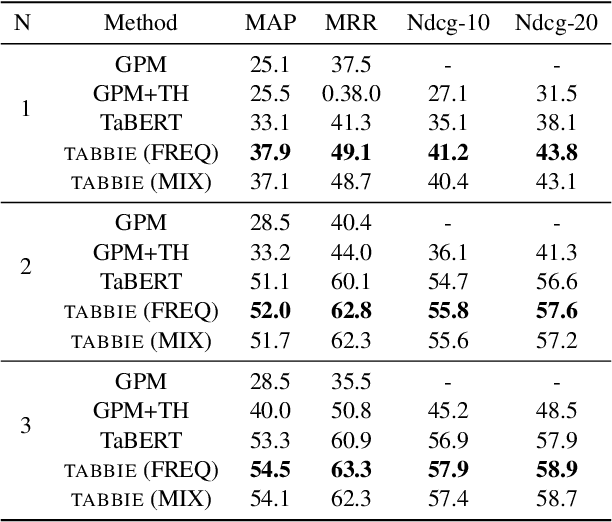
Existing work on tabular representation learning jointly models tables and associated text using self-supervised objective functions derived from pretrained language models such as BERT. While this joint pretraining improves tasks involving paired tables and text (e.g., answering questions about tables), we show that it underperforms on tasks that operate over tables without any associated text (e.g., populating missing cells). We devise a simple pretraining objective (corrupt cell detection) that learns exclusively from tabular data and reaches the state-of-the-art on a suite of table based prediction tasks. Unlike competing approaches, our model (TABBIE) provides embeddings of all table substructures (cells, rows, and columns), and it also requires far less compute to train. A qualitative analysis of our model's learned cell, column, and row representations shows that it understands complex table semantics and numerical trends.
RPCL: A Framework for Improving Cross-Domain Detection with Auxiliary Tasks
Apr 18, 2021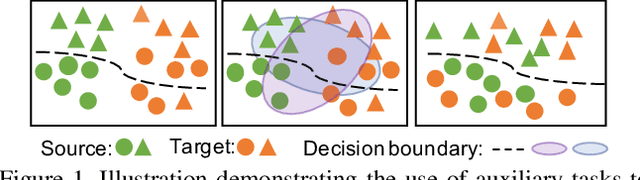
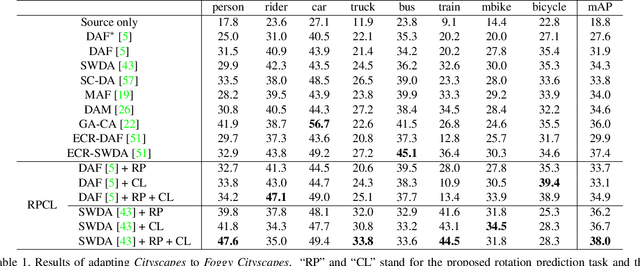
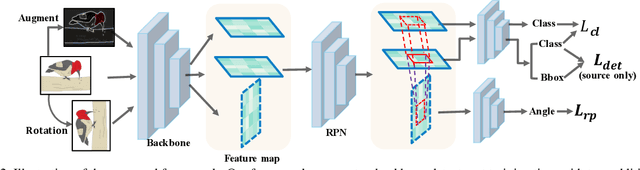
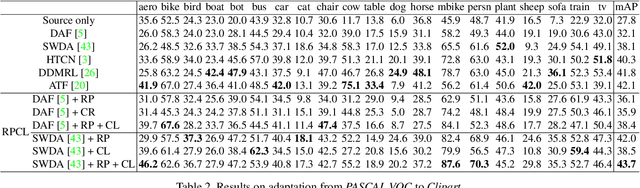
Cross-Domain Detection (XDD) aims to train an object detector using labeled image from a source domain but have good performance in the target domain with only unlabeled images. Existing approaches achieve this either by aligning the feature maps or the region proposals from the two domains, or by transferring the style of source images to that of target image. Contrasted with prior work, this paper provides a complementary solution to align domains by learning the same auxiliary tasks in both domains simultaneously. These auxiliary tasks push image from both domains towards shared spaces, which bridges the domain gap. Specifically, this paper proposes Rotation Prediction and Consistency Learning (PRCL), a framework complementing existing XDD methods for domain alignment by leveraging the two auxiliary tasks. The first one encourages the model to extract region proposals from foreground regions by rotating an image and predicting the rotation angle from the extracted region proposals. The second task encourages the model to be robust to changes in the image space by optimizing the model to make consistent class predictions for region proposals regardless of image perturbations. Experiments show the detection performance can be consistently and significantly enhanced by applying the two proposed tasks to existing XDD methods.
IGA : An Intent-Guided Authoring Assistant
Apr 14, 2021


While large-scale pretrained language models have significantly improved writing assistance functionalities such as autocomplete, more complex and controllable writing assistants have yet to be explored. We leverage advances in language modeling to build an interactive writing assistant that generates and rephrases text according to fine-grained author specifications. Users provide input to our Intent-Guided Assistant (IGA) in the form of text interspersed with tags that correspond to specific rhetorical directives (e.g., adding description or contrast, or rephrasing a particular sentence). We fine-tune a language model on a dataset heuristically-labeled with author intent, which allows IGA to fill in these tags with generated text that users can subsequently edit to their liking. A series of automatic and crowdsourced evaluations confirm the quality of IGA's generated outputs, while a small-scale user study demonstrates author preference for IGA over baseline methods in a creative writing task. We release our dataset, code, and demo to spur further research into AI-assisted writing.
Towards Interpreting and Mitigating Shortcut Learning Behavior of NLU models
Mar 18, 2021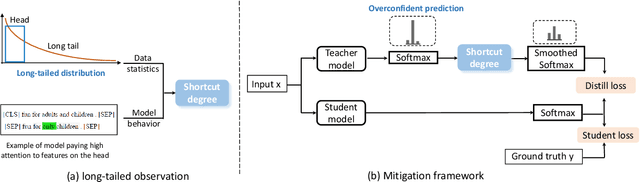
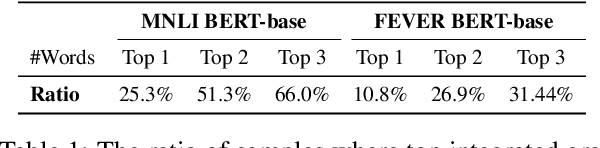
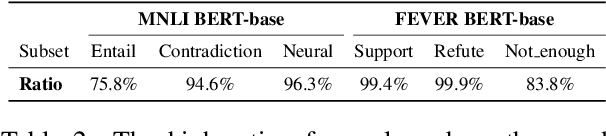
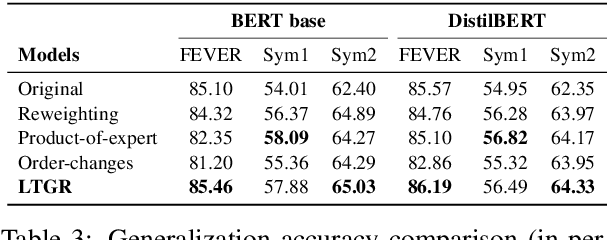
Recent studies indicate that NLU models are prone to rely on shortcut features for prediction, without achieving true language understanding. As a result, these models fail to generalize to real-world out-of-distribution data. In this work, we show that the words in the NLU training set can be modeled as a long-tailed distribution. There are two findings: 1) NLU models have strong preference for features located at the head of the long-tailed distribution, and 2) Shortcut features are picked up during very early few iterations of the model training. These two observations are further employed to formulate a measurement which can quantify the shortcut degree of each training sample. Based on this shortcut measurement, we propose a shortcut mitigation framework LGTR, to suppress the model from making overconfident predictions for samples with large shortcut degree. Experimental results on three NLU benchmarks demonstrate that our long-tailed distribution explanation accurately reflects the shortcut learning behavior of NLU models. Experimental analysis further indicates that LGTR can improve the generalization accuracy on OOD data, while preserving the accuracy on in-distribution data.
Black-box Explanation of Object Detectors via Saliency Maps
Jun 05, 2020
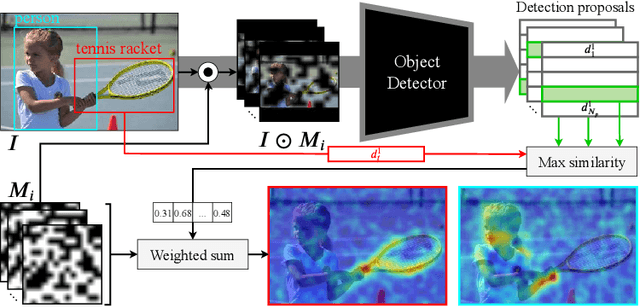
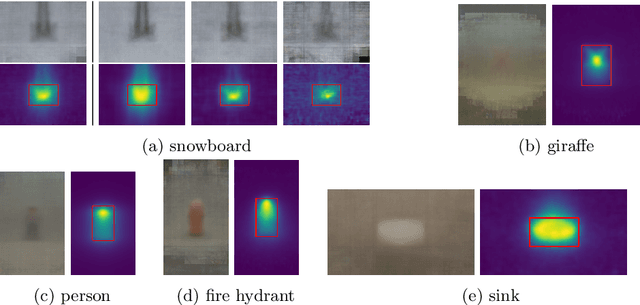
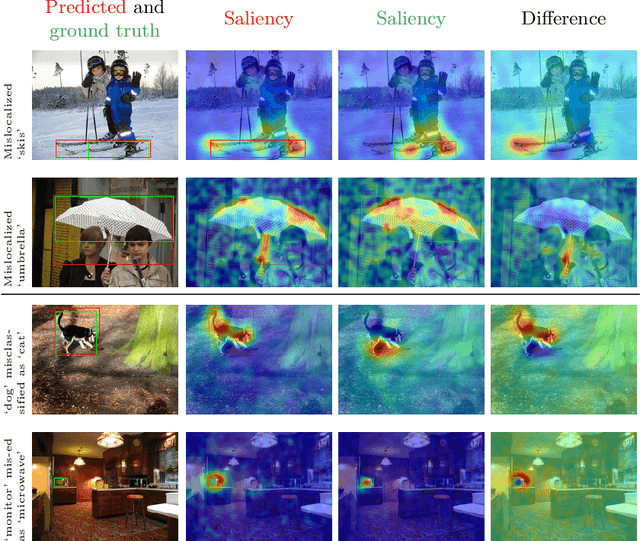
We propose D-RISE, a method for generating visual explanations for the predictions of object detectors. D-RISE can be considered "black-box" in the software testing sense, it only needs access to the inputs and outputs of an object detector. Compared to gradient-based methods, D-RISE is more general and agnostic to the particular type of object detector being tested as it does not need to know about the inner workings of the model. We show that D-RISE can be easily applied to different object detectors including one-stage detectors such as YOLOv3 and two-stage detectors such as Faster-RCNN. We present a detailed analysis of the generated visual explanations to highlight the utilization of context and the possible biases learned by object detectors.
Cross-Domain Document Object Detection: Benchmark Suite and Method
Mar 30, 2020
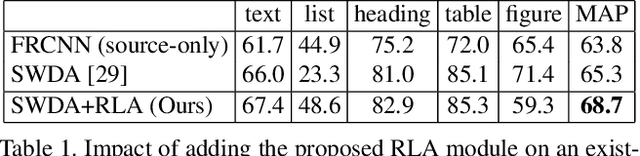
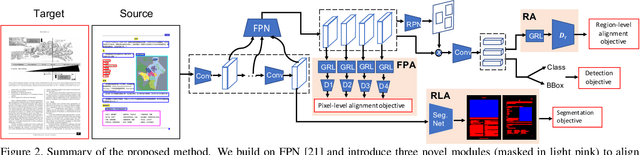
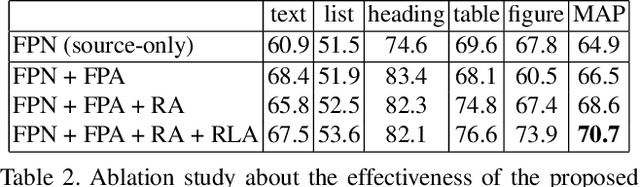
Decomposing images of document pages into high-level semantic regions (e.g., figures, tables, paragraphs), document object detection (DOD) is fundamental for downstream tasks like intelligent document editing and understanding. DOD remains a challenging problem as document objects vary significantly in layout, size, aspect ratio, texture, etc. An additional challenge arises in practice because large labeled training datasets are only available for domains that differ from the target domain. We investigate cross-domain DOD, where the goal is to learn a detector for the target domain using labeled data from the source domain and only unlabeled data from the target domain. Documents from the two domains may vary significantly in layout, language, and genre. We establish a benchmark suite consisting of different types of PDF document datasets that can be utilized for cross-domain DOD model training and evaluation. For each dataset, we provide the page images, bounding box annotations, PDF files, and the rendering layers extracted from the PDF files. Moreover, we propose a novel cross-domain DOD model which builds upon the standard detection model and addresses domain shifts by incorporating three novel alignment modules: Feature Pyramid Alignment (FPA) module, Region Alignment (RA) module and Rendering Layer alignment (RLA) module. Extensive experiments on the benchmark suite substantiate the efficacy of the three proposed modules and the proposed method significantly outperforms the baseline methods. The project page is at \url{https://github.com/kailigo/cddod}.
Explicit Bias Discovery in Visual Question Answering Models
Nov 19, 2018

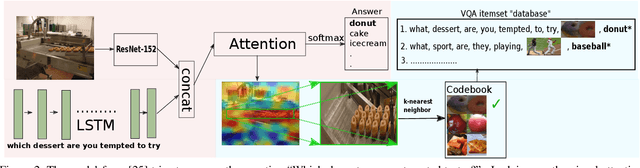

Researchers have observed that Visual Question Answering (VQA) models tend to answer questions by learning statistical biases in the data. For example, their answer to the question "What is the color of the grass?" is usually "Green", whereas a question like "What is the title of the book?" cannot be answered by inferring statistical biases. It is of interest to the community to explicitly discover such biases, both for understanding the behavior of such models, and towards debugging them. Our work address this problem. In a database, we store the words of the question, answer and visual words corresponding to regions of interest in attention maps. By running simple rule mining algorithms on this database, we discover human-interpretable rules which give us unique insight into the behavior of such models. Our results also show examples of unusual behaviors learned by models in attempting VQA tasks.