 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOLARIS: Guiding Small Models to Write Long Stories
Jun 02, 2026Small open-weight models struggle at long-form creative writing: their generated stories either fall far short of the requested length, or their quality significantly degrades as length increases, especially when compared to frontier models. We present POLARIS (Policy Optimization with LLM-as-a-judge rewards and Anchored-Reference Injection for Storywriting), a lower-compute GRPO recipe with two key ingredients: a frontier LLM judge with a structured Story Quality rubric as the online reward, and human-reference injection (HRI), where a teacher-forced human-written story serves as a high-reward anchor within each GRPO group. By applying our training recipe to Qwen3.5-9B, using a dataset of approximately 1.4K prompt-story pairs derived from 100 short-story anthologies and 4 A100 GPUs, we obtain POLARIS-9B. Across five benchmarks spanning in-distribution and out-of-distribution prompts and rubrics, POLARIS-9B is competitive with much larger open-weight models while following length instructions more closely. A blinded human evaluation confirms that POLARIS-9B is preferred to the base Qwen3.5-9B and on par with Qwen3.5-27B. Despite training only on stories up to 4k words, POLARIS-9B preserves quality on prompts requesting stories up to 3 times the training length, a regime where most open-weight models degrade substantially in quality, length adherence, or both. More broadly, our results suggest that length generalization is a meaningful stress test for creative-writing models and a useful lens for distinguishing otherwise close models.
Argument Collapse: LLMs Flatten Long-Form Public Debate
Jun 01, 2026As LLMs are increasingly used to draft public-facing arguments, they may flatten public debate by repeatedly introducing the same polished, plausible arguments. We study argument collapse, the tendency of essays generated by different LLMs to converge to a smaller set of main arguments, sub-arguments, and paragraph-level structures. We compare 1,039 human responses from 195 New York Times (NYT) debates, 448 human responses from 61 longer-form Boston Review (BR) forums, and 23,384 LLM-generated essays. In the NYT corpus, 65.3% of human main arguments are unique within a debate, compared to 3.4% of LLM main arguments. Asking LLMs to generate diverse answers adds variation, but a typical model recovers only about half of the distinct human main arguments, with much of the added variation falling outside the observed human argument space. Collapse also appears in sub-arguments, where among essays with the same main argument, 41.0% of human sub-arguments are unique versus 9.1% from LLM responses. Qualitatively, LLMs often reuse generalized and hedged sub-arguments, while humans prefer more concrete and topic-specific ones. Structure-wise, LLM-generated essays tend to follow a more fixed arc, often opening with a direct claim and moving quickly toward proposals. The same patterns hold in longer BR essays, suggesting that argument collapse extends beyond short-form responses.
Recovering Diversity Without Losing Alignment: A DPO Recipe for Post-Trained LLMs
May 28, 2026Many open-ended instructions have multiple valid answers that users can benefit from seeing, but post-training often narrows an LLM's output space toward a small set of canonical responses. We introduce REDIPO, an offline DPO data-construction pipeline for recovering distinct valid answer modes while preserving the alignment benefits of the instruct model. For each prompt, REDIPO samples responses from both base and instruct models, rewrites base-model responses with the instruct model, filters candidates for safety and instruction-following quality, and builds preference pairs that favor marginally diverse responses among candidates with similar instruction-following reward. Across Qwen3-4B, OLMo-3-7B, and LLaMA-3.1-8B, REDIPO improves NoveltyBench distinct_k by 134%, 33%, and 44% relative to the instruct checkpoints, while DivPO changes diversity by 0%, -6%, and -4% on the same models. These gains largely maintain MTBench, IFEval, and Arena-Hard performance, and reduce direct-category HarmBench attack success rate. Ablations show that marginal-diversity pair selection and base-response rewriting drive the diversity gains, while filtering and quality-bounded pairing help maintain alignment. Overall, our results show that diverse valid answers from base-model generations can be reintroduced through carefully constructed preference data while retaining the alignment benefits of post-training. We release our code and data at https://github.com/vsamuel2003/RiDiPO.
Beyond Precision: Importance-Aware Recall for Factuality Evaluation in Long-Form LLM Generation
Apr 03, 2026Evaluating the factuality of long-form output generated by large language models (LLMs) remains challenging, particularly when responses are open-ended and contain many fine-grained factual statements. Existing evaluation methods primarily focus on precision: they decompose a response into atomic claims and verify each claim against external knowledge sources such as Wikipedia. However, this overlooks an equally important dimension of factuality: recall, whether the generated response covers the relevant facts that should be included. We propose a comprehensive factuality evaluation framework that jointly measures precision and recall. Our method leverages external knowledge sources to construct reference facts and determine whether they are captured in generated text. We further introduce an importance-aware weighting scheme based on relevance and salience. Our analysis reveals that current LLMs perform substantially better on precision than on recall, suggesting that factual incompleteness remains a major limitation of long-form generation and that models are generally better at covering highly important facts than the full set of relevant facts.
StoryScope: Investigating idiosyncrasies in AI fiction
Apr 03, 2026As AI-generated fiction becomes increasingly prevalent, questions of authorship and originality are becoming central to how written work is evaluated. While most existing work in this space focuses on identifying surface-level signatures of AI writing, we ask instead whether AI-generated stories can be distinguished from human ones without relying on stylistic signals, focusing on discourse-level narrative choices such as character agency and chronological discontinuity. We propose StoryScope, a pipeline that automatically induces a fine-grained, interpretable feature space of discourse-level narrative features across 10 dimensions. We apply StoryScope to a parallel corpus of 10,272 writing prompts, each written by a human author and five LLMs, yielding 61,608 stories, each ~5,000 words, and 304 extracted features per story. Narrative features alone achieve 93.2% macro-F1 for human vs. AI detection and 68.4% macro-F1 for six-way authorship attribution, retaining over 97% of the performance of models that include stylistic cues. A compact set of 30 core narrative features captures much of this signal: AI stories over-explain themes and favor tidy, single-track plots while human stories frame protagonist' choices as more morally ambiguous and have increased temporal complexity. Per-model fingerprint features enable six-way attribution: for example, Claude produces notably flat event escalation, GPT over-indexes on dream sequences, and Gemini defaults to external character description. We find that AI-generated stories cluster in a shared region of narrative space, while human-authored stories exhibit greater diversity. More broadly, these results suggest that differences in underlying narrative construction, not just writing style, can be used to separate human-written original works from AI-generated fiction.
Bio-Inspired Self-Supervised Learning for Wrist-worn IMU Signals
Mar 11, 2026Wearable accelerometers have enabled large-scale health and wellness monitoring, yet learning robust human-activity representations has been constrained by the scarcity of labeled data. While self-supervised learning offers a potential remedy, existing approaches treat sensor streams as unstructured time series, overlooking the underlying biological structure of human movement, a factor we argue is critical for effective Human Activity Recognition (HAR). We introduce a novel tokenization strategy grounded in the submovement theory of motor control, which posits that continuous wrist motion is composed of superposed elementary basis functions called submovements. We define our token as the movement segment, a unit of motion composed of a finite sequence of submovements that is readily extractable from wrist accelerometer signals. By treating these segments as tokens, we pretrain a Transformer encoder via masked movement-segment reconstruction to model the temporal dependencies of movement segments, shifting the learning focus beyond local waveform morphology. Pretrained on the NHANES corpus (approximately 28k hours; approximately 11k participants; approximately 10M windows), our representations outperform strong wearable SSL baselines across six subject-disjoint HAR benchmarks. Furthermore, they demonstrate stronger data efficiency in data-scarce settings. Code and pretrained weights will be made publicly available.
How2Everything: Mining the Web for How-To Procedures to Evaluate and Improve LLMs
Feb 09, 2026Generating step-by-step "how-to" procedures is a key LLM capability: how-to advice is commonly requested in chatbots, and step-by-step planning is critical for reasoning over complex tasks. Yet, measuring and improving procedural validity at scale on real-world tasks remains challenging and understudied. To address this, we introduce How2Everything, a scalable framework to evaluate and improve goal-conditioned procedure generation. Our framework includes How2Mine, which mines 351K procedures from 980K web pages across 14 topics and readily scales to larger corpora. From this pool we build How2Bench, a 7K-example evaluation set balanced across topics. To reliably score model outputs, we develop How2Score, an evaluation protocol that uses an LLM judge to detect whether a generation contains any critical failure that would prevent achieving the goal. For low-cost, reproducible evaluation, we distill a frontier model into an open 8B model, achieving 80.5% agreement with human annotators. How2Bench reveals clear scaling trends across model sizes and training stages, providing signal early in pretraining. Finally, RL using How2Score as a reward improves performance on How2Bench by >10 points across three models without systematic regressions on standard benchmarks, with gains robust to superficial source-document memorization or format compliance. Taken together, How2Everything shows how pretraining web data can support a closed loop of capability evaluation and improvement at scale.
OWL: Probing Cross-Lingual Recall of Memorized Texts via World Literature
May 28, 2025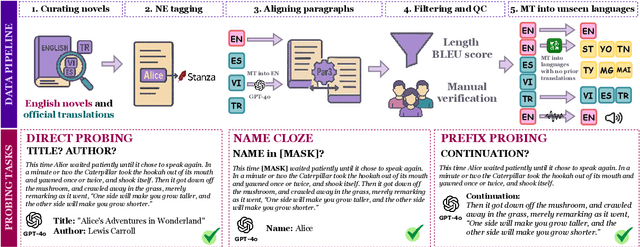


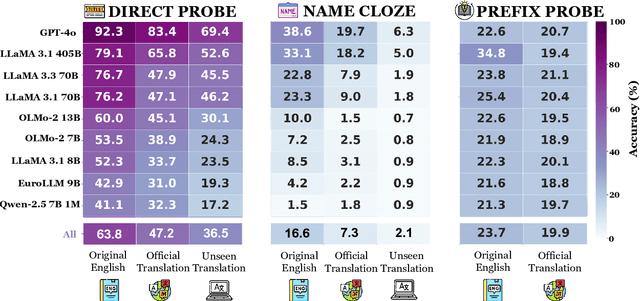
Large language models (LLMs) are known to memorize and recall English text from their pretraining data. However, the extent to which this ability generalizes to non-English languages or transfers across languages remains unclear. This paper investigates multilingual and cross-lingual memorization in LLMs, probing if memorized content in one language (e.g., English) can be recalled when presented in translation. To do so, we introduce OWL, a dataset of 31.5K aligned excerpts from 20 books in ten languages, including English originals, official translations (Vietnamese, Spanish, Turkish), and new translations in six low-resource languages (Sesotho, Yoruba, Maithili, Malagasy, Setswana, Tahitian). We evaluate memorization across model families and sizes through three tasks: (1) direct probing, which asks the model to identify a book's title and author; (2) name cloze, which requires predicting masked character names; and (3) prefix probing, which involves generating continuations. We find that LLMs consistently recall content across languages, even for texts without direct translation in pretraining data. GPT-4o, for example, identifies authors and titles 69% of the time and masked entities 6% of the time in newly translated excerpts. Perturbations (e.g., masking characters, shuffling words) modestly reduce direct probing accuracy (7% drop for shuffled official translations). Our results highlight the extent of cross-lingual memorization and provide insights on the differences between the models.
Does quantization affect models' performance on long-context tasks?
May 27, 2025



Large language models (LLMs) now support context windows exceeding 128K tokens, but this comes with significant memory requirements and high inference latency. Quantization can mitigate these costs, but may degrade performance. In this work, we present the first systematic evaluation of quantized LLMs on tasks with long-inputs (>64K tokens) and long-form outputs. Our evaluation spans 9.7K test examples, five quantization methods (FP8, GPTQ-int8, AWQ-int4, GPTQ-int4, BNB-nf4), and five models (Llama-3.1 8B and 70B; Qwen-2.5 7B, 32B, and 72B). We find that, on average, 8-bit quantization preserves accuracy (~0.8% drop), whereas 4-bit methods lead to substantial losses, especially for tasks involving long context inputs (drops of up to 59%). This degradation tends to worsen when the input is in a language other than English. Crucially, the effects of quantization depend heavily on the quantization method, model, and task. For instance, while Qwen-2.5 72B remains robust under BNB-nf4, Llama-3.1 70B experiences a 32% performance drop on the same task. These findings highlight the importance of a careful, task-specific evaluation before deploying quantized LLMs, particularly in long-context scenarios and with languages other than English.
Frankentext: Stitching random text fragments into long-form narratives
May 23, 2025

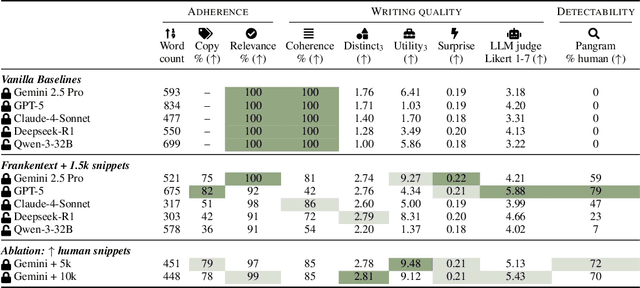
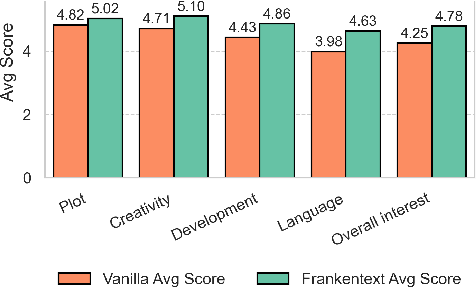
We introduce Frankentexts, a new type of long-form narratives produced by LLMs under the extreme constraint that most tokens (e.g., 90%) must be copied verbatim from human writings. This task presents a challenging test of controllable generation, requiring models to satisfy a writing prompt, integrate disparate text fragments, and still produce a coherent narrative. To generate Frankentexts, we instruct the model to produce a draft by selecting and combining human-written passages, then iteratively revise the draft while maintaining a user-specified copy ratio. We evaluate the resulting Frankentexts along three axes: writing quality, instruction adherence, and detectability. Gemini-2.5-Pro performs surprisingly well on this task: 81% of its Frankentexts are coherent and 100% relevant to the prompt. Notably, up to 59% of these outputs are misclassified as human-written by detectors like Pangram, revealing limitations in AI text detectors. Human annotators can sometimes identify Frankentexts through their abrupt tone shifts and inconsistent grammar between segments, especially in longer generations. Beyond presenting a challenging generation task, Frankentexts invite discussion on building effective detectors for this new grey zone of authorship, provide training data for mixed authorship detection, and serve as a sandbox for studying human-AI co-writing processes.