 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Framework for Open-World Compositional Zero-shot Learning
Dec 05, 2024



Open-World Compositional Zero-Shot Learning (OW-CZSL) addresses the challenge of recognizing novel compositions of known primitives and entities. Even though prior works utilize language knowledge for recognition, such approaches exhibit limited interactions between language-image modalities. Our approach primarily focuses on enhancing the inter-modality interactions through fostering richer interactions between image and textual data. Additionally, we introduce a novel module aimed at alleviating the computational burden associated with exhaustive exploration of all possible compositions during the inference stage. While previous methods exclusively learn compositions jointly or independently, we introduce an advanced hybrid procedure that leverages both learning mechanisms to generate final predictions. Our proposed model, achieves state-of-the-art in OW-CZSL in three datasets, while surpassing Large Vision Language Models (LLVM) in two datasets.
WayEx: Waypoint Exploration using a Single Demonstration
Jul 22, 2024We propose WayEx, a new method for learning complex goal-conditioned robotics tasks from a single demonstration. Our approach distinguishes itself from existing imitation learning methods by demanding fewer expert examples and eliminating the need for information about the actions taken during the demonstration. This is accomplished by introducing a new reward function and employing a knowledge expansion technique. We demonstrate the effectiveness of WayEx, our waypoint exploration strategy, across six diverse tasks, showcasing its applicability in various environments. Notably, our method significantly reduces training time by 50% as compared to traditional reinforcement learning methods. WayEx obtains a higher reward than existing imitation learning methods given only a single demonstration. Furthermore, we demonstrate its success in tackling complex environments where standard approaches fall short. More information is available at: https://waypoint-ex.github.io.
InVi: Object Insertion In Videos Using Off-the-Shelf Diffusion Models
Jul 15, 2024



We introduce InVi, an approach for inserting or replacing objects within videos (referred to as inpainting) using off-the-shelf, text-to-image latent diffusion models. InVi targets controlled manipulation of objects and blending them seamlessly into a background video unlike existing video editing methods that focus on comprehensive re-styling or entire scene alterations. To achieve this goal, we tackle two key challenges. Firstly, for high quality control and blending, we employ a two-step process involving inpainting and matching. This process begins with inserting the object into a single frame using a ControlNet-based inpainting diffusion model, and then generating subsequent frames conditioned on features from an inpainted frame as an anchor to minimize the domain gap between the background and the object. Secondly, to ensure temporal coherence, we replace the diffusion model's self-attention layers with extended-attention layers. The anchor frame features serve as the keys and values for these layers, enhancing consistency across frames. Our approach removes the need for video-specific fine-tuning, presenting an efficient and adaptable solution. Experimental results demonstrate that InVi achieves realistic object insertion with consistent blending and coherence across frames, outperforming existing methods.
Chop & Learn: Recognizing and Generating Object-State Compositions
Sep 25, 2023



Recognizing and generating object-state compositions has been a challenging task, especially when generalizing to unseen compositions. In this paper, we study the task of cutting objects in different styles and the resulting object state changes. We propose a new benchmark suite Chop & Learn, to accommodate the needs of learning objects and different cut styles using multiple viewpoints. We also propose a new task of Compositional Image Generation, which can transfer learned cut styles to different objects, by generating novel object-state images. Moreover, we also use the videos for Compositional Action Recognition, and show valuable uses of this dataset for multiple video tasks. Project website: https://chopnlearn.github.io.
Disentangling Visual Embeddings for Attributes and Objects
May 17, 2022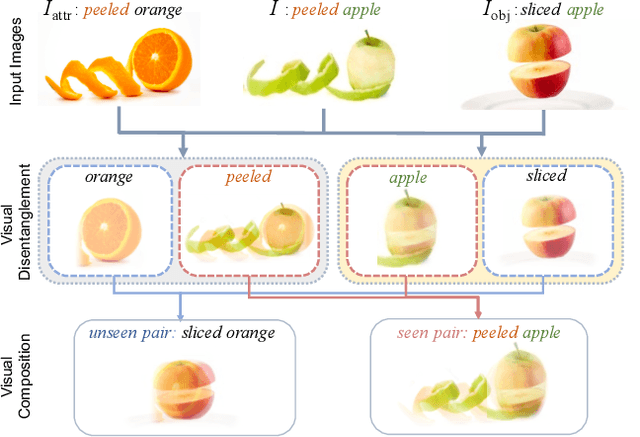
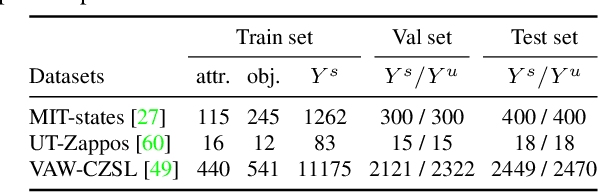
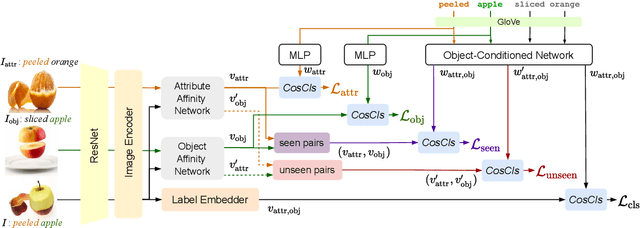
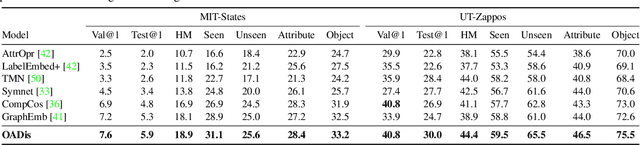
We study the problem of compositional zero-shot learning for object-attribute recognition. Prior works use visual features extracted with a backbone network, pre-trained for object classification and thus do not capture the subtly distinct features associated with attributes. To overcome this challenge, these studies employ supervision from the linguistic space, and use pre-trained word embeddings to better separate and compose attribute-object pairs for recognition. Analogous to linguistic embedding space, which already has unique and agnostic embeddings for object and attribute, we shift the focus back to the visual space and propose a novel architecture that can disentangle attribute and object features in the visual space. We use visual decomposed features to hallucinate embeddings that are representative for the seen and novel compositions to better regularize the learning of our model. Extensive experiments show that our method outperforms existing work with significant margin on three datasets: MIT-States, UT-Zappos, and a new benchmark created based on VAW. The code, models, and dataset splits are publicly available at https://github.com/nirat1606/OADis.
All About Knowledge Graphs for Actions
Aug 28, 2020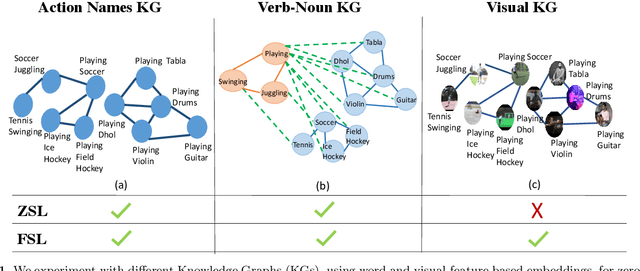
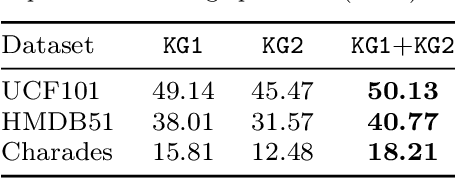
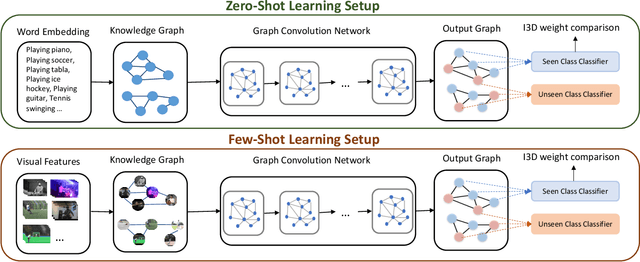
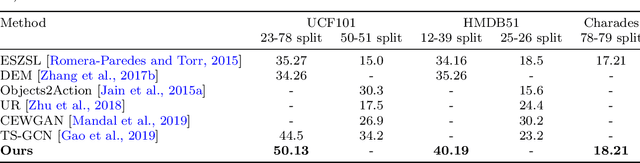
Current action recognition systems require large amounts of training data for recognizing an action. Recent works have explored the paradigm of zero-shot and few-shot learning to learn classifiers for unseen categories or categories with few labels. Following similar paradigms in object recognition, these approaches utilize external sources of knowledge (eg. knowledge graphs from language domains). However, unlike objects, it is unclear what is the best knowledge representation for actions. In this paper, we intend to gain a better understanding of knowledge graphs (KGs) that can be utilized for zero-shot and few-shot action recognition. In particular, we study three different construction mechanisms for KGs: action embeddings, action-object embeddings, visual embeddings. We present extensive analysis of the impact of different KGs in different experimental setups. Finally, to enable a systematic study of zero-shot and few-shot approaches, we propose an improved evaluation paradigm based on UCF101, HMDB51, and Charades datasets for knowledge transfer from models trained on Kinetics.
Explicit Bias Discovery in Visual Question Answering Models
Nov 19, 2018

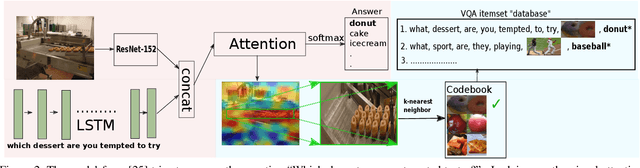

Researchers have observed that Visual Question Answering (VQA) models tend to answer questions by learning statistical biases in the data. For example, their answer to the question "What is the color of the grass?" is usually "Green", whereas a question like "What is the title of the book?" cannot be answered by inferring statistical biases. It is of interest to the community to explicitly discover such biases, both for understanding the behavior of such models, and towards debugging them. Our work address this problem. In a database, we store the words of the question, answer and visual words corresponding to regions of interest in attention maps. By running simple rule mining algorithms on this database, we discover human-interpretable rules which give us unique insight into the behavior of such models. Our results also show examples of unusual behaviors learned by models in attempting VQA tasks.