 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
RoboReward: General-Purpose Vision-Language Reward Models for Robotics
Jan 08, 2026A well-designed reward is critical for effective reinforcement learning-based policy improvement. In real-world robotics, obtaining such rewards typically requires either labor-intensive human labeling or brittle, handcrafted objectives. Vision-language models (VLMs) have shown promise as automatic reward models, yet their effectiveness on real robot tasks is poorly understood. In this work, we aim to close this gap by introducing (1) RoboReward, a robotics reward dataset and benchmark built on large-scale real-robot corpora from Open X-Embodiment (OXE) and RoboArena, and (2) vision-language reward models trained on this dataset (RoboReward 4B/8B). Because OXE is success-heavy and lacks failure examples, we propose a negative examples data augmentation pipeline that generates calibrated negative and near-misses via counterfactual relabeling of successful episodes and temporal clipping to create partial-progress outcomes from the same videos. Using this framework, we build a large training and evaluation dataset spanning diverse tasks and embodiments to test whether state-of-the-art VLMs can reliably provide rewards for robot learning. Our evaluation of open and proprietary VLMs finds that no model excels across tasks, highlighting substantial room for improvement. We then train general-purpose 4B- and 8B-parameter models that outperform much larger VLMs in assigning rewards for short-horizon robotic tasks. Finally, we deploy the 8B model in real-robot reinforcement learning and find that it improves policy learning over Gemini Robotics-ER 1.5 while narrowing the gap to RL training with human-provided rewards. We release the full dataset, trained reward models, and evaluation suite on our website to advance the development of general-purpose reward models in robotics: https://crfm.stanford.edu/helm/robo-reward-bench (project website).
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
Semantic Retrieval at Walmart
Dec 05, 2024



In product search, the retrieval of candidate products before re-ranking is more critical and challenging than other search like web search, especially for tail queries, which have a complex and specific search intent. In this paper, we present a hybrid system for e-commerce search deployed at Walmart that combines traditional inverted index and embedding-based neural retrieval to better answer user tail queries. Our system significantly improved the relevance of the search engine, measured by both offline and online evaluations. The improvements were achieved through a combination of different approaches. We present a new technique to train the neural model at scale. and describe how the system was deployed in production with little impact on response time. We highlight multiple learnings and practical tricks that were used in the deployment of this system.
Image2Struct: Benchmarking Structure Extraction for Vision-Language Models
Oct 29, 2024



We introduce Image2Struct, a benchmark to evaluate vision-language models (VLMs) on extracting structure from images. Our benchmark 1) captures real-world use cases, 2) is fully automatic and does not require human judgment, and 3) is based on a renewable stream of fresh data. In Image2Struct, VLMs are prompted to generate the underlying structure (e.g., LaTeX code or HTML) from an input image (e.g., webpage screenshot). The structure is then rendered to produce an output image (e.g., rendered webpage), which is compared against the input image to produce a similarity score. This round-trip evaluation allows us to quantitatively evaluate VLMs on tasks with multiple valid structures. We create a pipeline that downloads fresh data from active online communities upon execution and evaluates the VLMs without human intervention. We introduce three domains (Webpages, LaTeX, and Musical Scores) and use five image metrics (pixel similarity, cosine similarity between the Inception vectors, learned perceptual image patch similarity, structural similarity index measure, and earth mover similarity) that allow efficient and automatic comparison between pairs of images. We evaluate Image2Struct on 14 prominent VLMs and find that scores vary widely, indicating that Image2Struct can differentiate between the performances of different VLMs. Additionally, the best score varies considerably across domains (e.g., 0.402 on sheet music vs. 0.830 on LaTeX equations), indicating that Image2Struct contains tasks of varying difficulty. For transparency, we release the full results at https://crfm.stanford.edu/helm/image2struct/v1.0.1/.
VHELM: A Holistic Evaluation of Vision Language Models
Oct 09, 2024



Current benchmarks for assessing vision-language models (VLMs) often focus on their perception or problem-solving capabilities and neglect other critical aspects such as fairness, multilinguality, or toxicity. Furthermore, they differ in their evaluation procedures and the scope of the evaluation, making it difficult to compare models. To address these issues, we extend the HELM framework to VLMs to present the Holistic Evaluation of Vision Language Models (VHELM). VHELM aggregates various datasets to cover one or more of the 9 aspects: visual perception, knowledge, reasoning, bias, fairness, multilinguality, robustness, toxicity, and safety. In doing so, we produce a comprehensive, multi-dimensional view of the capabilities of the VLMs across these important factors. In addition, we standardize the standard inference parameters, methods of prompting, and evaluation metrics to enable fair comparisons across models. Our framework is designed to be lightweight and automatic so that evaluation runs are cheap and fast. Our initial run evaluates 22 VLMs on 21 existing datasets to provide a holistic snapshot of the models. We uncover new key findings, such as the fact that efficiency-focused models (e.g., Claude 3 Haiku or Gemini 1.5 Flash) perform significantly worse than their full models (e.g., Claude 3 Opus or Gemini 1.5 Pro) on the bias benchmark but not when evaluated on the other aspects. For transparency, we release the raw model generations and complete results on our website (https://crfm.stanford.edu/helm/vhelm/v2.0.1). VHELM is intended to be a living benchmark, and we hope to continue adding new datasets and models over time.
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making
Oct 09, 2024



We aim to evaluate Large Language Models (LLMs) for embodied decision making. While a significant body of work has been leveraging LLMs for decision making in embodied environments, we still lack a systematic understanding of their performance because they are usually applied in different domains, for different purposes, and built based on different inputs and outputs. Furthermore, existing evaluations tend to rely solely on a final success rate, making it difficult to pinpoint what ability is missing in LLMs and where the problem lies, which in turn blocks embodied agents from leveraging LLMs effectively and selectively. To address these limitations, we propose a generalized interface (Embodied Agent Interface) that supports the formalization of various types of tasks and input-output specifications of LLM-based modules. Specifically, it allows us to unify 1) a broad set of embodied decision-making tasks involving both state and temporally extended goals, 2) four commonly-used LLM-based modules for decision making: goal interpretation, subgoal decomposition, action sequencing, and transition modeling, and 3) a collection of fine-grained metrics which break down evaluation into various types of errors, such as hallucination errors, affordance errors, various types of planning errors, etc. Overall, our benchmark offers a comprehensive assessment of LLMs' performance for different subtasks, pinpointing the strengths and weaknesses in LLM-powered embodied AI systems, and providing insights for effective and selective use of LLMs in embodied decision making.
Relevance Filtering for Embedding-based Retrieval
Aug 09, 2024



In embedding-based retrieval, Approximate Nearest Neighbor (ANN) search enables efficient retrieval of similar items from large-scale datasets. While maximizing recall of relevant items is usually the goal of retrieval systems, a low precision may lead to a poor search experience. Unlike lexical retrieval, which inherently limits the size of the retrieved set through keyword matching, dense retrieval via ANN search has no natural cutoff. Moreover, the cosine similarity scores of embedding vectors are often optimized via contrastive or ranking losses, which make them difficult to interpret. Consequently, relying on top-K or cosine-similarity cutoff is often insufficient to filter out irrelevant results effectively. This issue is prominent in product search, where the number of relevant products is often small. This paper introduces a novel relevance filtering component (called "Cosine Adapter") for embedding-based retrieval to address this challenge. Our approach maps raw cosine similarity scores to interpretable scores using a query-dependent mapping function. We then apply a global threshold on the mapped scores to filter out irrelevant results. We are able to significantly increase the precision of the retrieved set, at the expense of a small loss of recall. The effectiveness of our approach is demonstrated through experiments on both public MS MARCO dataset and internal Walmart product search data. Furthermore, online A/B testing on the Walmart site validates the practical value of our approach in real-world e-commerce settings.
Enhancing Relevance of Embedding-based Retrieval at Walmart
Aug 09, 2024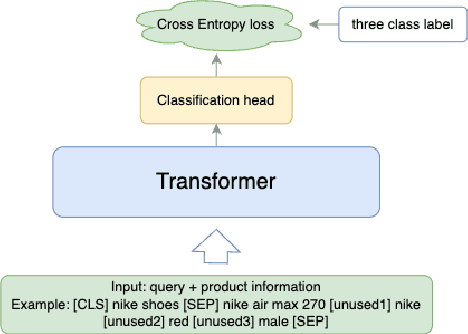

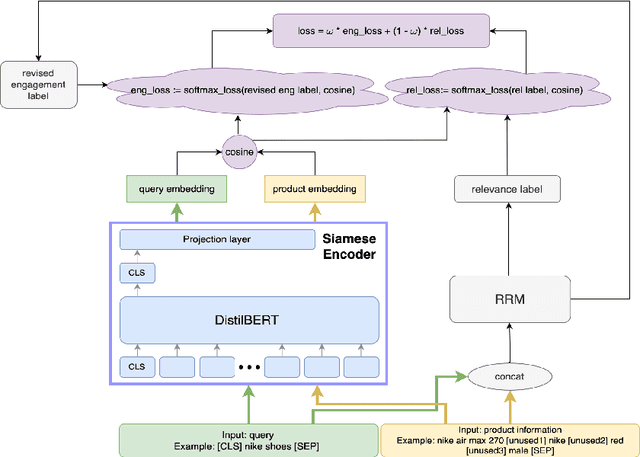
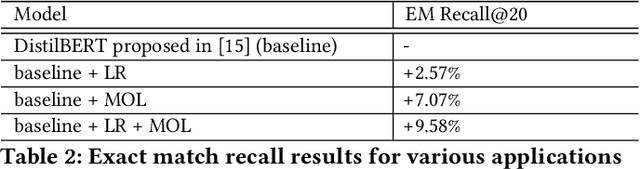
Embedding-based neural retrieval (EBR) is an effective search retrieval method in product search for tackling the vocabulary gap between customer search queries and products. The initial launch of our EBR system at Walmart yielded significant gains in relevance and add-to-cart rates [1]. However, despite EBR generally retrieving more relevant products for reranking, we have observed numerous instances of relevance degradation. Enhancing retrieval performance is crucial, as it directly influences product reranking and affects the customer shopping experience. Factors contributing to these degradations include false positives/negatives in the training data and the inability to handle query misspellings. To address these issues, we present several approaches to further strengthen the capabilities of our EBR model in terms of retrieval relevance. We introduce a Relevance Reward Model (RRM) based on human relevance feedback. We utilize RRM to remove noise from the training data and distill it into our EBR model through a multi-objective loss. In addition, we present the techniques to increase the performance of our EBR model, such as typo-aware training, and semi-positive generation. The effectiveness of our EBR is demonstrated through offline relevance evaluation, online AB tests, and successful deployments to live production. [1] Alessandro Magnani, Feng Liu, Suthee Chaidaroon, Sachin Yadav, Praveen Reddy Suram, Ajit Puthenputhussery, Sijie Chen, Min Xie, Anirudh Kashi, Tony Lee, et al. 2022. Semantic retrieval at walmart. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3495-3503.
Doc2Token: Bridging Vocabulary Gap by Predicting Missing Tokens for E-commerce Search
Jun 28, 2024



Addressing the "vocabulary mismatch" issue in information retrieval is a central challenge for e-commerce search engines, because product pages often miss important keywords that customers search for. Doc2Query[1] is a popular document-expansion technique that predicts search queries for a document and includes the predicted queries with the document for retrieval. However, this approach can be inefficient for e-commerce search, because the predicted query tokens are often already present in the document. In this paper, we propose Doc2Token, a technique that predicts relevant tokens (instead of queries) that are missing from the document and includes these tokens in the document for retrieval. For the task of predicting missing tokens, we introduce a new metric, "novel ROUGE score". Doc2Token is demonstrated to be superior to Doc2Query in terms of novel ROUGE score and diversity of predictions. Doc2Token also exhibits efficiency gains by reducing both training and inference times. We deployed the feature to production and observed significant revenue gain in an online A/B test, and launched the feature to full traffic on Walmart.com. [1] R. Nogueira, W. Yang, J. Lin, K. Cho, Document expansion by query prediction, arXiv preprint arXiv:1904.08375 (2019)