 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Practice of Scaling Search Conversion Rate Prediction
May 28, 2026Scaling a Search Conversion Rate (CVR) prediction model, especially in high-traffic environments, presents a challenge: superior model quality needs to be balanced with strict constraints on training cost and serving latency. This paper details an effective approach for scaling modern search CVR prediction models. We begin with an empirical study to understand the scaling performance of search CVR models, analyzing how quality improves as we scale three key factors of model backbone computation, the size of embedding parameters, and the volume of training data. We use a large-scale production dataset, comprising over a year of customer interaction logs from a high-traffic e-commerce platform, to evaluate the scalability of several state-of-the-art architectures and their ensembles. Our key findings are: (1) selecting the right backbone and scaling factors is crucial; (2) the impact of scaling backbone, embedding, and data is largely independent and additive, which has implications for more efficient scaling exploration; (3) a streamlined warmstart strategy can accelerate training iterations while simplifying new updates; (4) inference optimization strategies such as decoupled graph execution and dynamic batching can enable low-latency GPU serving even for high-capacity models. Compared to a baseline of a pre-scaling production model, we ultimately deployed a model trained on 2.5x larger training data with 8x more inference compute while having minimal latency impact. Online A/B tests also demonstrate that our launches achieved a combined +2.6% gain in a key metric of search conversion rate.
Relevance Filtering for Embedding-based Retrieval
Aug 09, 2024



In embedding-based retrieval, Approximate Nearest Neighbor (ANN) search enables efficient retrieval of similar items from large-scale datasets. While maximizing recall of relevant items is usually the goal of retrieval systems, a low precision may lead to a poor search experience. Unlike lexical retrieval, which inherently limits the size of the retrieved set through keyword matching, dense retrieval via ANN search has no natural cutoff. Moreover, the cosine similarity scores of embedding vectors are often optimized via contrastive or ranking losses, which make them difficult to interpret. Consequently, relying on top-K or cosine-similarity cutoff is often insufficient to filter out irrelevant results effectively. This issue is prominent in product search, where the number of relevant products is often small. This paper introduces a novel relevance filtering component (called "Cosine Adapter") for embedding-based retrieval to address this challenge. Our approach maps raw cosine similarity scores to interpretable scores using a query-dependent mapping function. We then apply a global threshold on the mapped scores to filter out irrelevant results. We are able to significantly increase the precision of the retrieved set, at the expense of a small loss of recall. The effectiveness of our approach is demonstrated through experiments on both public MS MARCO dataset and internal Walmart product search data. Furthermore, online A/B testing on the Walmart site validates the practical value of our approach in real-world e-commerce settings.
Enhancing Relevance of Embedding-based Retrieval at Walmart
Aug 09, 2024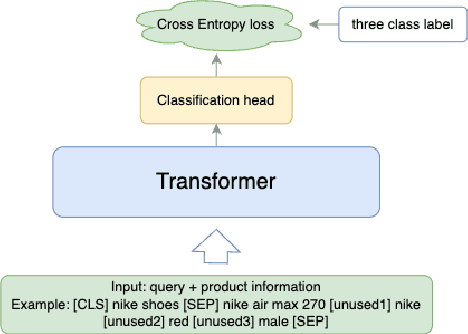

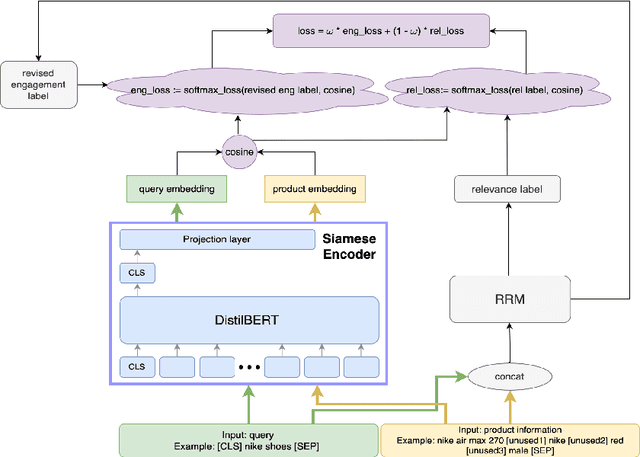
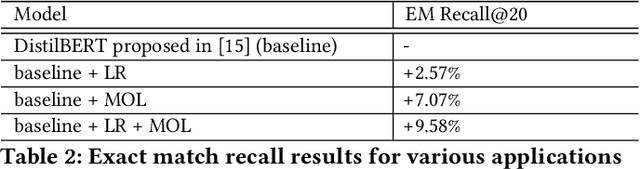
Embedding-based neural retrieval (EBR) is an effective search retrieval method in product search for tackling the vocabulary gap between customer search queries and products. The initial launch of our EBR system at Walmart yielded significant gains in relevance and add-to-cart rates [1]. However, despite EBR generally retrieving more relevant products for reranking, we have observed numerous instances of relevance degradation. Enhancing retrieval performance is crucial, as it directly influences product reranking and affects the customer shopping experience. Factors contributing to these degradations include false positives/negatives in the training data and the inability to handle query misspellings. To address these issues, we present several approaches to further strengthen the capabilities of our EBR model in terms of retrieval relevance. We introduce a Relevance Reward Model (RRM) based on human relevance feedback. We utilize RRM to remove noise from the training data and distill it into our EBR model through a multi-objective loss. In addition, we present the techniques to increase the performance of our EBR model, such as typo-aware training, and semi-positive generation. The effectiveness of our EBR is demonstrated through offline relevance evaluation, online AB tests, and successful deployments to live production. [1] Alessandro Magnani, Feng Liu, Suthee Chaidaroon, Sachin Yadav, Praveen Reddy Suram, Ajit Puthenputhussery, Sijie Chen, Min Xie, Anirudh Kashi, Tony Lee, et al. 2022. Semantic retrieval at walmart. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3495-3503.
Doc2Token: Bridging Vocabulary Gap by Predicting Missing Tokens for E-commerce Search
Jun 28, 2024



Addressing the "vocabulary mismatch" issue in information retrieval is a central challenge for e-commerce search engines, because product pages often miss important keywords that customers search for. Doc2Query[1] is a popular document-expansion technique that predicts search queries for a document and includes the predicted queries with the document for retrieval. However, this approach can be inefficient for e-commerce search, because the predicted query tokens are often already present in the document. In this paper, we propose Doc2Token, a technique that predicts relevant tokens (instead of queries) that are missing from the document and includes these tokens in the document for retrieval. For the task of predicting missing tokens, we introduce a new metric, "novel ROUGE score". Doc2Token is demonstrated to be superior to Doc2Query in terms of novel ROUGE score and diversity of predictions. Doc2Token also exhibits efficiency gains by reducing both training and inference times. We deployed the feature to production and observed significant revenue gain in an online A/B test, and launched the feature to full traffic on Walmart.com. [1] R. Nogueira, W. Yang, J. Lin, K. Cho, Document expansion by query prediction, arXiv preprint arXiv:1904.08375 (2019)