 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucinations in Video Large Language Models via Spatiotemporal-Semantic Contrastive Decoding
Jan 30, 2026Although Video Large Language Models perform remarkably well across tasks such as video understanding, question answering, and reasoning, they still suffer from the problem of hallucination, which refers to generating outputs that are inconsistent with explicit video content or factual evidence. However, existing decoding methods for mitigating video hallucinations, while considering the spatiotemporal characteristics of videos, mostly rely on heuristic designs. As a result, they fail to precisely capture the root causes of hallucinations and their fine-grained temporal and semantic correlations, leading to limited robustness and generalization in complex scenarios. To more effectively mitigate video hallucinations, we propose a novel decoding strategy termed Spatiotemporal-Semantic Contrastive Decoding. This strategy constructs negative features by deliberately disrupting the spatiotemporal consistency and semantic associations of video features, and suppresses video hallucinations through contrastive decoding against the original video features during inference. Extensive experiments demonstrate that our method not only effectively mitigates the occurrence of hallucinations, but also preserves the general video understanding and reasoning capabilities of the model.
PhysProver: Advancing Automatic Theorem Proving for Physics
Jan 22, 2026The combination of verifiable languages and LLMs has significantly influenced both the mathematical and computer science communities because it provides a rigorous foundation for theorem proving. Recent advancements in the field provide foundation models and sophisticated agentic systems pushing the boundaries of formal mathematical reasoning to approach the natural language capability of LLMs. However, little attention has been given to the formal physics reasoning, which also heavily relies on similar problem-solving and theorem-proving frameworks. To solve this problem, this paper presents, to the best of our knowledge, the first approach to enhance formal theorem proving in the physics domain. We compose a dedicated dataset PhysLeanData for the task. It is composed of theorems sampled from PhysLean and data generated by a conjecture-based formal data generation pipeline. In the training pipeline, we leverage DeepSeek-Prover-V2-7B, a strong open-source mathematical theorem prover, and apply Reinforcement Learning with Verifiable Rewards (RLVR) to train our model PhysProver. Comprehensive experiments demonstrate that, using only $\sim$5K training samples, PhysProver achieves an overall 2.4\% improvement in multiple sub-domains. Furthermore, after formal physics training, we observe 1.3\% gains on the MiniF2F-Test benchmark, which indicates non-trivial generalization beyond physics domains and enhancement for formal math capability as well. The results highlight the effectiveness and efficiency of our approach, which provides a paradigm for extending formal provers outside mathematical domains. To foster further research, we will release both our dataset and model to the community.
A Training-Free Guess What Vision Language Model from Snippets to Open-Vocabulary Object Detection
Jan 21, 2026Open-Vocabulary Object Detection (OVOD) aims to develop the capability to detect anything. Although myriads of large-scale pre-training efforts have built versatile foundation models that exhibit impressive zero-shot capabilities to facilitate OVOD, the necessity of creating a universal understanding for any object cognition according to already pretrained foundation models is usually overlooked. Therefore, in this paper, a training-free Guess What Vision Language Model, called GW-VLM, is proposed to form a universal understanding paradigm based on our carefully designed Multi-Scale Visual Language Searching (MS-VLS) coupled with Contextual Concept Prompt (CCP) for OVOD. This approach can engage a pre-trained Vision Language Model (VLM) and a Large Language Model (LLM) in the game of "guess what". Wherein, MS-VLS leverages multi-scale visual-language soft-alignment for VLM to generate snippets from the results of class-agnostic object detection, while CCP can form the concept of flow referring to MS-VLS and then make LLM understand snippets for OVOD. Finally, the extensive experiments are carried out on natural and remote sensing datasets, including COCO val, Pascal VOC, DIOR, and NWPU-10, and the results indicate that our proposed GW-VLM can achieve superior OVOD performance compared to the-state-of-the-art methods without any training step.
PRL: Process Reward Learning Improves LLMs' Reasoning Ability and Broadens the Reasoning Boundary
Jan 15, 2026Improving the reasoning abilities of Large Language Models (LLMs) has been a continuous topic recently. But most relevant works are based on outcome rewards at the trajectory level, missing fine-grained supervision during the reasoning process. Other existing training frameworks that try to combine process signals together to optimize LLMs also rely heavily on tedious additional steps like MCTS, training a separate reward model, etc., doing harm to the training efficiency. Moreover, the intuition behind the process signals design lacks rigorous theoretical support, leaving the understanding of the optimization mechanism opaque. In this paper, we propose Process Reward Learning (PRL), which decomposes the entropy regularized reinforcement learning objective into intermediate steps, with rigorous process rewards that could be assigned to models accordingly. Starting from theoretical motivation, we derive the formulation of PRL that is essentially equivalent to the objective of reward maximization plus a KL-divergence penalty term between the policy model and a reference model. However, PRL could turn the outcome reward into process supervision signals, which helps better guide the exploration during RL optimization. From our experiment results, we demonstrate that PRL not only improves the average performance for LLMs' reasoning ability measured by average @ n, but also broadens the reasoning boundary by improving the pass @ n metric. Extensive experiments show the effectiveness of PRL could be verified and generalized.
Test-time Adaptive Hierarchical Co-enhanced Denoising Network for Reliable Multimodal Classification
Jan 12, 2026Reliable learning on low-quality multimodal data is a widely concerning issue, especially in safety-critical applications. However, multimodal noise poses a major challenge in this domain and leads existing methods to suffer from two key limitations. First, they struggle to reliably remove heterogeneous data noise, hindering robust multimodal representation learning. Second, they exhibit limited adaptability and generalization when encountering previously unseen noise. To address these issues, we propose Test-time Adaptive Hierarchical Co-enhanced Denoising Network (TAHCD). On one hand, TAHCD introduces the Adaptive Stable Subspace Alignment and Sample-Adaptive Confidence Alignment to reliably remove heterogeneous noise. They account for noise at both global and instance levels and enable jointly removal of modality-specific and cross-modality noise, achieving robust learning. On the other hand, TAHCD introduces test-time cooperative enhancement, which adaptively updates the model in response to input noise in a label-free manner, improving adaptability and generalization. This is achieved by collaboratively enhancing the joint removal process of modality-specific and cross-modality noise across global and instance levels according to sample noise. Experiments on multiple benchmarks demonstrate that the proposed method achieves superior classification performance, robustness, and generalization compared with state-of-the-art reliable multimodal learning approaches.
WebGym: Scaling Training Environments for Visual Web Agents with Realistic Tasks
Jan 07, 2026We present WebGym, the largest-to-date open-source environment for training realistic visual web agents. Real websites are non-stationary and diverse, making artificial or small-scale task sets insufficient for robust policy learning. WebGym contains nearly 300,000 tasks with rubric-based evaluations across diverse, real-world websites and difficulty levels. We train agents with a simple reinforcement learning (RL) recipe, which trains on the agent's own interaction traces (rollouts), using task rewards as feedback to guide learning. To enable scaling RL, we speed up sampling of trajectories in WebGym by developing a high-throughput asynchronous rollout system, designed specifically for web agents. Our system achieves a 4-5x rollout speedup compared to naive implementations. Second, we scale the task set breadth, depth, and size, which results in continued performance improvement. Fine-tuning a strong base vision-language model, Qwen-3-VL-8B-Instruct, on WebGym results in an improvement in success rate on an out-of-distribution test set from 26.2% to 42.9%, significantly outperforming agents based on proprietary models such as GPT-4o and GPT-5-Thinking that achieve 27.1% and 29.8%, respectively. This improvement is substantial because our test set consists only of tasks on websites never seen during training, unlike many other prior works on training visual web agents.
AlignDrive: Aligned Lateral-Longitudinal Planning for End-to-End Autonomous Driving
Jan 05, 2026End-to-end autonomous driving has rapidly progressed, enabling joint perception and planning in complex environments. In the planning stage, state-of-the-art (SOTA) end-to-end autonomous driving models decouple planning into parallel lateral and longitudinal predictions. While effective, this parallel design can lead to i) coordination failures between the planned path and speed, and ii) underutilization of the drive path as a prior for longitudinal planning, thus redundantly encoding static information. To address this, we propose a novel cascaded framework that explicitly conditions longitudinal planning on the drive path, enabling coordinated and collision-aware lateral and longitudinal planning. Specifically, we introduce a path-conditioned formulation that explicitly incorporates the drive path into longitudinal planning. Building on this, the model predicts longitudinal displacements along the drive path rather than full 2D trajectory waypoints. This design simplifies longitudinal reasoning and more tightly couples it with lateral planning. Additionally, we introduce a planning-oriented data augmentation strategy that simulates rare safety-critical events, such as vehicle cut-ins, by adding agents and relabeling longitudinal targets to avoid collision. Evaluated on the challenging Bench2Drive benchmark, our method sets a new SOTA, achieving a driving score of 89.07 and a success rate of 73.18%, demonstrating significantly improved coordination and safety
From Indoor to Open World: Revealing the Spatial Reasoning Gap in MLLMs
Dec 22, 2025



While Multimodal Large Language Models (MLLMs) have achieved impressive performance on semantic tasks, their spatial intelligence--crucial for robust and grounded AI systems--remains underdeveloped. Existing benchmarks fall short of diagnosing this limitation: they either focus on overly simplified qualitative reasoning or rely on domain-specific indoor data, constrained by the lack of outdoor datasets with verifiable metric ground truth. To bridge this gap, we introduce a large-scale benchmark built from pedestrian-perspective videos captured with synchronized stereo cameras, LiDAR, and IMU/GPS sensors. This dataset provides metrically precise 3D information, enabling the automatic generation of spatial reasoning questions that span a hierarchical spectrum--from qualitative relational reasoning to quantitative metric and kinematic understanding. Evaluations reveal that the performance gains observed in structured indoor benchmarks vanish in open-world settings. Further analysis using synthetic abnormal scenes and blinding tests confirms that current MLLMs depend heavily on linguistic priors instead of grounded visual reasoning. Our benchmark thus provides a principled platform for diagnosing these limitations and advancing physically grounded spatial intelligence.
StarCraft+: Benchmarking Multi-agent Algorithms in Adversary Paradigm
Dec 18, 2025



Deep multi-agent reinforcement learning (MARL) algorithms are booming in the field of collaborative intelligence, and StarCraft multi-agent challenge (SMAC) is widely-used as the benchmark therein. However, imaginary opponents of MARL algorithms are practically configured and controlled in a fixed built-in AI mode, which causes less diversity and versatility in algorithm evaluation. To address this issue, in this work, we establish a multi-agent algorithm-vs-algorithm environment, named StarCraft II battle arena (SC2BA), to refresh the benchmarking of MARL algorithms in an adversary paradigm. Taking StarCraft as infrastructure, the SC2BA environment is specifically created for inter-algorithm adversary with the consideration of fairness, usability and customizability, and meantime an adversarial PyMARL (APyMARL) library is developed with easy-to-use interfaces/modules. Grounding in SC2BA, we benchmark those classic MARL algorithms in two types of adversarial modes: dual-algorithm paired adversary and multi-algorithm mixed adversary, where the former conducts the adversary of pairwise algorithms while the latter focuses on the adversary to multiple behaviors from a group of algorithms. The extensive benchmark experiments exhibit some thought-provoking observations/problems in the effectivity, sensibility and scalability of these completed algorithms. The SC2BA environment as well as reproduced experiments are released in \href{https://github.com/dooliu/SC2BA}{Github}, and we believe that this work could mark a new step for the MARL field in the coming years.
Memo2496: Expert-Annotated Dataset and Dual-View Adaptive Framework for Music Emotion Recognition
Dec 17, 2025
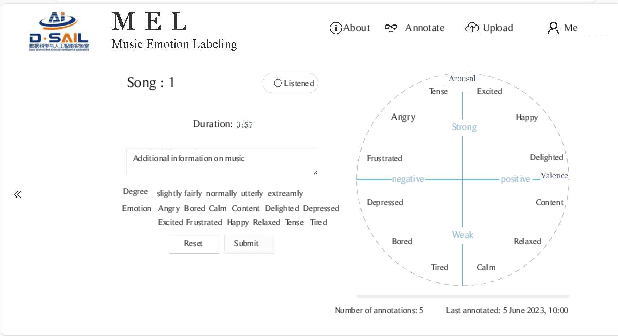
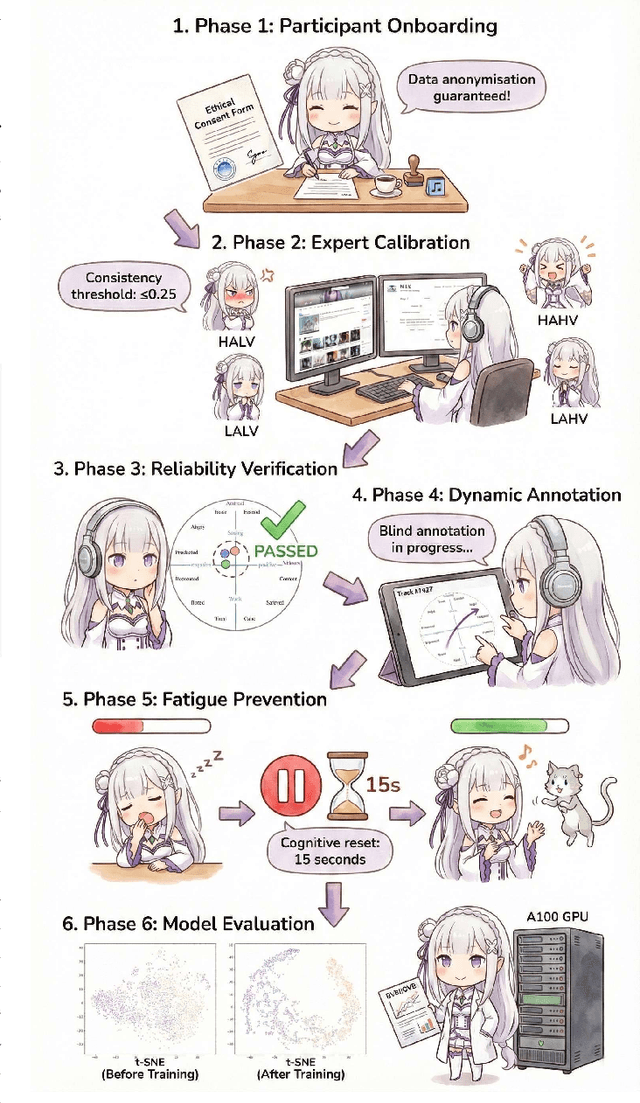
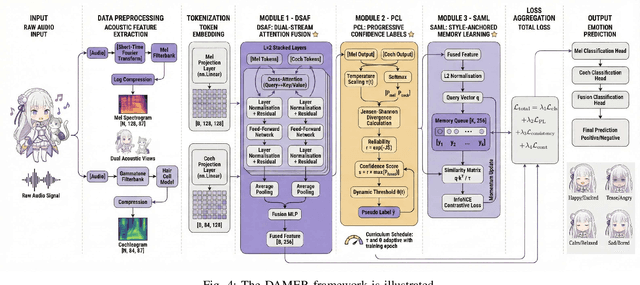
Music Emotion Recogniser (MER) research faces challenges due to limited high-quality annotated datasets and difficulties in addressing cross-track feature drift. This work presents two primary contributions to address these issues. Memo2496, a large-scale dataset, offers 2496 instrumental music tracks with continuous valence arousal labels, annotated by 30 certified music specialists. Annotation quality is ensured through calibration with extreme emotion exemplars and a consistency threshold of 0.25, measured by Euclidean distance in the valence arousal space. Furthermore, the Dual-view Adaptive Music Emotion Recogniser (DAMER) is introduced. DAMER integrates three synergistic modules: Dual Stream Attention Fusion (DSAF) facilitates token-level bidirectional interaction between Mel spectrograms and cochleagrams via cross attention mechanisms; Progressive Confidence Labelling (PCL) generates reliable pseudo labels employing curriculum-based temperature scheduling and consistency quantification using Jensen Shannon divergence; and Style Anchored Memory Learning (SAML) maintains a contrastive memory queue to mitigate cross-track feature drift. Extensive experiments on the Memo2496, 1000songs, and PMEmo datasets demonstrate DAMER's state-of-the-art performance, improving arousal dimension accuracy by 3.43%, 2.25%, and 0.17%, respectively. Ablation studies and visualisation analyses validate each module's contribution. Both the dataset and source code are publicly available.