 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathReasoner-R1: Instilling Structured Reasoning into Pathology Vision-Language Model via Knowledge-Guided Policy Optimization
Jan 29, 2026Vision-Language Models (VLMs) are advancing computational pathology with superior visual understanding capabilities. However, current systems often reduce diagnosis to directly output conclusions without verifiable evidence-linked reasoning, which severely limits clinical trust and hinders expert error rectification. To address these barriers, we construct PathReasoner, the first large-scale dataset of whole-slide image (WSI) reasoning. Unlike previous work reliant on unverified distillation, we develop a rigorous knowledge-guided generation pipeline. By leveraging medical knowledge graphs, we explicitly align structured pathological findings and clinical reasoning with diagnoses, generating over 20K high-quality instructional samples. Based on the database, we propose PathReasoner-R1, which synergizes trajectory-masked supervised fine-tuning with reasoning-oriented reinforcement learning to instill structured chain-of-thought capabilities. To ensure medical rigor, we engineer a knowledge-aware multi-granular reward function incorporating an Entity Reward mechanism strictly aligned with knowledge graphs. This effectively guides the model to optimize for logical consistency rather than mere outcome matching, thereby enhancing robustness. Extensive experiments demonstrate that PathReasoner-R1 achieves state-of-the-art performance on both PathReasoner and public benchmarks across various image scales, equipping pathology models with transparent, clinically grounded reasoning capabilities. Dataset and code are available at https://github.com/cyclexfy/PathReasoner-R1.
PathFLIP: Fine-grained Language-Image Pretraining for Versatile Computational Pathology
Dec 19, 2025



While Vision-Language Models (VLMs) have achieved notable progress in computational pathology (CPath), the gigapixel scale and spatial heterogeneity of Whole Slide Images (WSIs) continue to pose challenges for multimodal understanding. Existing alignment methods struggle to capture fine-grained correspondences between textual descriptions and visual cues across thousands of patches from a slide, compromising their performance on downstream tasks. In this paper, we propose PathFLIP (Pathology Fine-grained Language-Image Pretraining), a novel framework for holistic WSI interpretation. PathFLIP decomposes slide-level captions into region-level subcaptions and generates text-conditioned region embeddings to facilitate precise visual-language grounding. By harnessing Large Language Models (LLMs), PathFLIP can seamlessly follow diverse clinical instructions and adapt to varied diagnostic contexts. Furthermore, it exhibits versatile capabilities across multiple paradigms, efficiently handling slide-level classification and retrieval, fine-grained lesion localization, and instruction following. Extensive experiments demonstrate that PathFLIP outperforms existing large-scale pathological VLMs on four representative benchmarks while requiring significantly less training data, paving the way for fine-grained, instruction-aware WSI interpretation in clinical practice.
STCL:Curriculum learning Strategies for deep learning image steganography models
Apr 24, 2025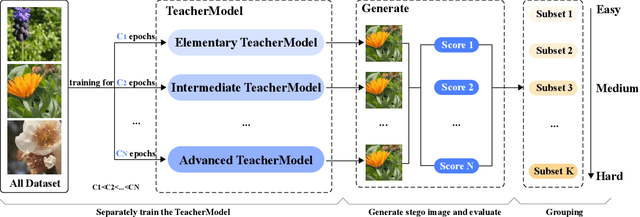
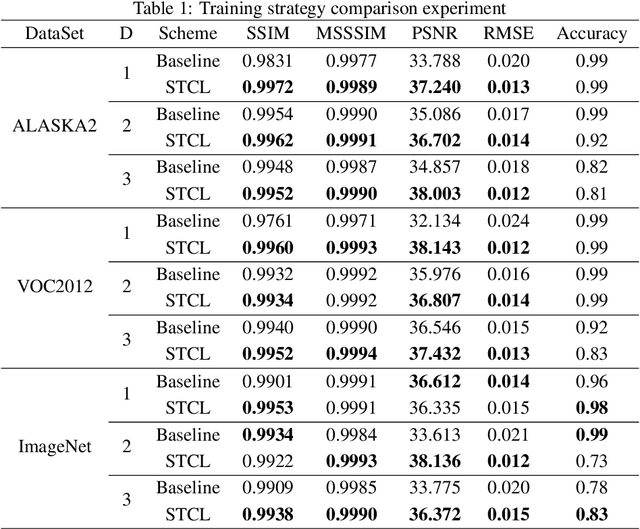


Aiming at the problems of poor quality of steganographic images and slow network convergence of image steganography models based on deep learning, this paper proposes a Steganography Curriculum Learning training strategy (STCL) for deep learning image steganography models. So that only easy images are selected for training when the model has poor fitting ability at the initial stage, and gradually expand to more difficult images, the strategy includes a difficulty evaluation strategy based on the teacher model and an knee point-based training scheduling strategy. Firstly, multiple teacher models are trained, and the consistency of the quality of steganographic images under multiple teacher models is used as the difficulty score to construct the training subsets from easy to difficult. Secondly, a training control strategy based on knee points is proposed to reduce the possibility of overfitting on small training sets and accelerate the training process. Experimental results on three large public datasets, ALASKA2, VOC2012 and ImageNet, show that the proposed image steganography scheme is able to improve the model performance under multiple algorithmic frameworks, which not only has a high PSNR, SSIM score, and decoding accuracy, but also the steganographic images generated by the model under the training of the STCL strategy have a low steganography analysis scores. You can find our code at \href{https://github.com/chaos-boops/STCL}{https://github.com/chaos-boops/STCL}.
CLPSTNet: A Progressive Multi-Scale Convolutional Steganography Model Integrating Curriculum Learning
Apr 23, 2025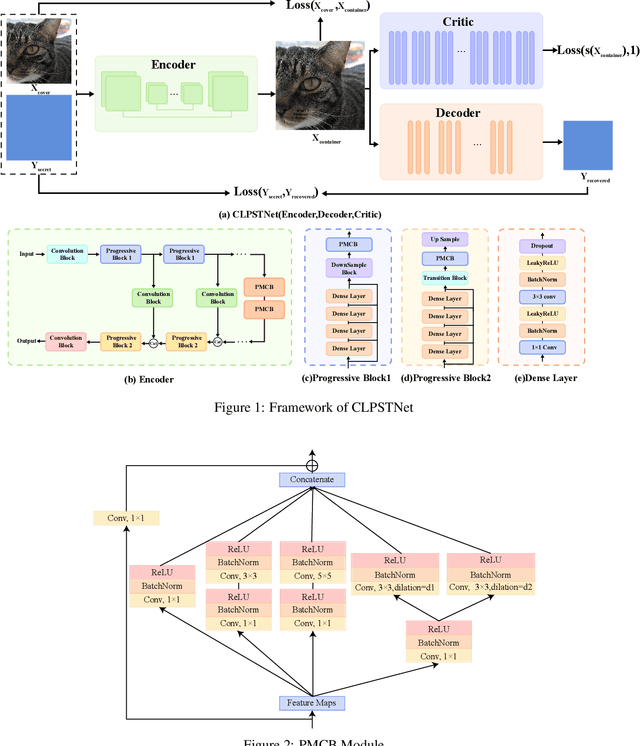
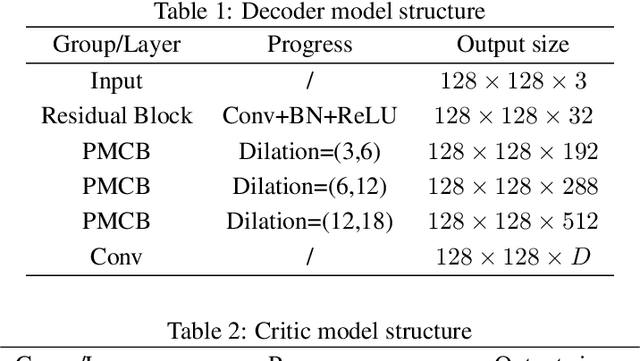
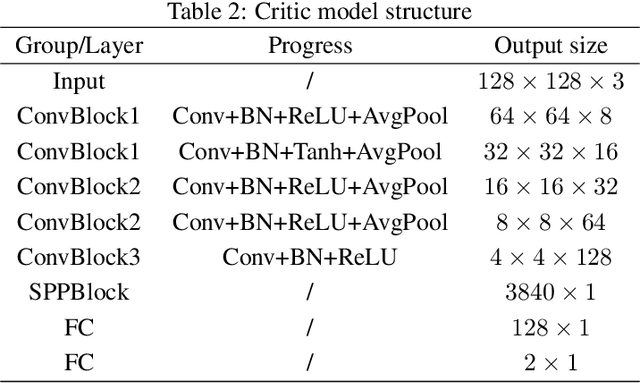
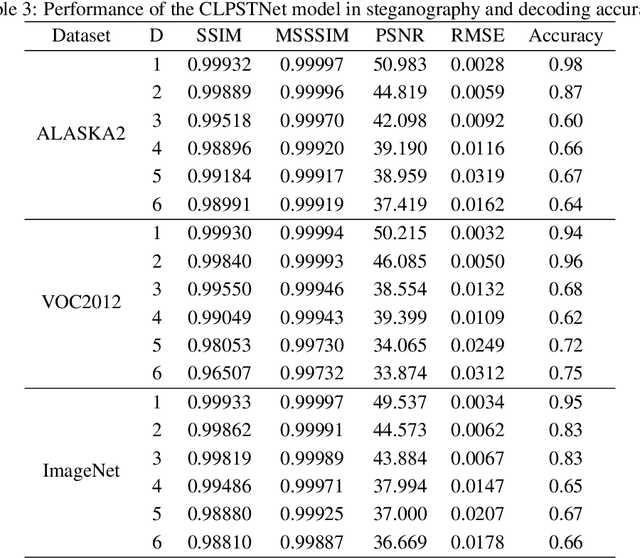
In recent years, a large number of works have introduced Convolutional Neural Networks (CNNs) into image steganography, which transform traditional steganography methods such as hand-crafted features and prior knowledge design into steganography methods that neural networks autonomically learn information embedding. However, due to the inherent complexity of digital images, issues of invisibility and security persist when using CNN models for information embedding. In this paper, we propose Curriculum Learning Progressive Steganophy Network (CLPSTNet). The network consists of multiple progressive multi-scale convolutional modules that integrate Inception structures and dilated convolutions. The module contains multiple branching pathways, starting from a smaller convolutional kernel and dilatation rate, extracting the basic, local feature information from the feature map, and gradually expanding to the convolution with a larger convolutional kernel and dilatation rate for perceiving the feature information of a larger receptive field, so as to realize the multi-scale feature extraction from shallow to deep, and from fine to coarse, allowing the shallow secret information features to be refined in different fusion stages. The experimental results show that the proposed CLPSTNet not only has high PSNR , SSIM metrics and decoding accuracy on three large public datasets, ALASKA2, VOC2012 and ImageNet, but also the steganographic images generated by CLPSTNet have low steganalysis scores.You can find our code at \href{https://github.com/chaos-boops/CLPSTNet}{https://github.com/chaos-boops/CLPSTNet}.
Prototype-Guided Cross-Modal Knowledge Enhancement for Adaptive Survival Prediction
Mar 13, 2025



Histo-genomic multimodal survival prediction has garnered growing attention for its remarkable model performance and potential contributions to precision medicine. However, a significant challenge in clinical practice arises when only unimodal data is available, limiting the usability of these advanced multimodal methods. To address this issue, this study proposes a prototype-guided cross-modal knowledge enhancement (ProSurv) framework, which eliminates the dependency on paired data and enables robust learning and adaptive survival prediction. Specifically, we first introduce an intra-modal updating mechanism to construct modality-specific prototype banks that encapsulate the statistics of the whole training set and preserve the modality-specific risk-relevant features/prototypes across intervals. Subsequently, the proposed cross-modal translation module utilizes the learned prototypes to enhance knowledge representation for multimodal inputs and generate features for missing modalities, ensuring robust and adaptive survival prediction across diverse scenarios. Extensive experiments on four public datasets demonstrate the superiority of ProSurv over state-of-the-art methods using either unimodal or multimodal input, and the ablation study underscores its feasibility for broad applicability. Overall, this study addresses a critical practical challenge in computational pathology, offering substantial significance and potential impact in the field.