 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Factual Consistency of Text Summarization by Adversarially Decoupling Comprehension and Embellishment Abilities of LLMs
Nov 01, 2023



Despite the recent progress in text summarization made by large language models (LLMs), they often generate summaries that are factually inconsistent with original articles, known as "hallucinations" in text generation. Unlike previous small models (e.g., BART, T5), current LLMs make fewer silly mistakes but more sophisticated ones, such as imposing cause and effect, adding false details, and overgeneralizing, etc. These hallucinations are challenging to detect through traditional methods, which poses great challenges for improving the factual consistency of text summarization. In this paper, we propose an adversarially DEcoupling method to disentangle the Comprehension and EmbellishmeNT abilities of LLMs (DECENT). Furthermore, we adopt a probing-based parameter-efficient technique to cover the shortage of sensitivity for true and false in the training process of LLMs. In this way, LLMs are less confused about embellishing and understanding, thus can execute the instructions more accurately and have enhanced abilities to distinguish hallucinations. Experimental results show that DECENT significantly improves the reliability of text summarization based on LLMs.
Constructive Large Language Models Alignment with Diverse Feedback
Oct 11, 2023



In recent research on large language models (LLMs), there has been a growing emphasis on aligning these models with human values to reduce the impact of harmful content. However, current alignment methods often rely solely on singular forms of human feedback, such as preferences, annotated labels, or natural language critiques, overlooking the potential advantages of combining these feedback types. This limitation leads to suboptimal performance, even when ample training data is available. In this paper, we introduce Constructive and Diverse Feedback (CDF) as a novel method to enhance LLM alignment, inspired by constructivist learning theory. Our approach involves collecting three distinct types of feedback tailored to problems of varying difficulty levels within the training dataset. Specifically, we exploit critique feedback for easy problems, refinement feedback for medium problems, and preference feedback for hard problems. By training our model with this diversified feedback, we achieve enhanced alignment performance while using less training data. To assess the effectiveness of CDF, we evaluate it against previous methods in three downstream tasks: question answering, dialog generation, and text summarization. Experimental results demonstrate that CDF achieves superior performance even with a smaller training dataset.
Self-Explanation Prompting Improves Dialogue Understanding in Large Language Models
Sep 22, 2023



Task-oriented dialogue (TOD) systems facilitate users in executing various activities via multi-turn dialogues, but Large Language Models (LLMs) often struggle to comprehend these intricate contexts. In this study, we propose a novel "Self-Explanation" prompting strategy to enhance the comprehension abilities of LLMs in multi-turn dialogues. This task-agnostic approach requires the model to analyze each dialogue utterance before task execution, thereby improving performance across various dialogue-centric tasks. Experimental results from six benchmark datasets confirm that our method consistently outperforms other zero-shot prompts and matches or exceeds the efficacy of few-shot prompts, demonstrating its potential as a powerful tool in enhancing LLMs' comprehension in complex dialogue tasks.
UniSA: Unified Generative Framework for Sentiment Analysis
Sep 04, 2023



Sentiment analysis is a crucial task that aims to understand people's emotional states and predict emotional categories based on multimodal information. It consists of several subtasks, such as emotion recognition in conversation (ERC), aspect-based sentiment analysis (ABSA), and multimodal sentiment analysis (MSA). However, unifying all subtasks in sentiment analysis presents numerous challenges, including modality alignment, unified input/output forms, and dataset bias. To address these challenges, we propose a Task-Specific Prompt method to jointly model subtasks and introduce a multimodal generative framework called UniSA. Additionally, we organize the benchmark datasets of main subtasks into a new Sentiment Analysis Evaluation benchmark, SAEval. We design novel pre-training tasks and training methods to enable the model to learn generic sentiment knowledge among subtasks to improve the model's multimodal sentiment perception ability. Our experimental results show that UniSA performs comparably to the state-of-the-art on all subtasks and generalizes well to various subtasks in sentiment analysis.
SpokenWOZ: A Large-Scale Speech-Text Benchmark for Spoken Task-Oriented Dialogue in Multiple Domains
May 22, 2023



Task-oriented dialogue (TOD) models have great progress in the past few years. However, these studies primarily focus on datasets written by annotators, which has resulted in a gap between academic research and more realistic spoken conversation scenarios. While a few small-scale spoken TOD datasets are proposed to address robustness issues, e.g., ASR errors, they fail to identify the unique challenges in spoken conversation. To tackle the limitations, we introduce SpokenWOZ, a large-scale speech-text dataset for spoken TOD, which consists of 8 domains, 203k turns, 5.7k dialogues and 249 hours of audios from human-to-human spoken conversations. SpokenWOZ incorporates common spoken characteristics such as word-by-word processing and commonsense reasoning. We also present cross-turn slot and reasoning slot detection as new challenges based on the spoken linguistic phenomena. We conduct comprehensive experiments on various models, including text-modal baselines, newly proposed dual-modal baselines and LLMs. The results show the current models still has substantial areas for improvement in spoken conversation, including fine-tuned models and LLMs, i.e., ChatGPT.
Speech-Text Dialog Pre-training for Spoken Dialog Understanding with Explicit Cross-Modal Alignment
May 19, 2023Recently, speech-text pre-training methods have shown remarkable success in many speech and natural language processing tasks. However, most previous pre-trained models are usually tailored for one or two specific tasks, but fail to conquer a wide range of speech-text tasks. In addition, existing speech-text pre-training methods fail to explore the contextual information within a dialogue to enrich utterance representations. In this paper, we propose Speech-text dialog Pre-training for spoken dialog understanding with ExpliCiT cRoss-Modal Alignment (SPECTRA), which is the first-ever speech-text dialog pre-training model. Concretely, to consider the temporality of speech modality, we design a novel temporal position prediction task to capture the speech-text alignment. This pre-training task aims to predict the start and end time of each textual word in the corresponding speech waveform. In addition, to learn the characteristics of spoken dialogs, we generalize a response selection task from textual dialog pre-training to speech-text dialog pre-training scenarios. Experimental results on four different downstream speech-text tasks demonstrate the superiority of SPECTRA in learning speech-text alignment and multi-turn dialog context.
Unsupervised Dialogue Topic Segmentation with Topic-aware Utterance Representation
May 04, 2023Dialogue Topic Segmentation (DTS) plays an essential role in a variety of dialogue modeling tasks. Previous DTS methods either focus on semantic similarity or dialogue coherence to assess topic similarity for unsupervised dialogue segmentation. However, the topic similarity cannot be fully identified via semantic similarity or dialogue coherence. In addition, the unlabeled dialogue data, which contains useful clues of utterance relationships, remains underexploited. In this paper, we propose a novel unsupervised DTS framework, which learns topic-aware utterance representations from unlabeled dialogue data through neighboring utterance matching and pseudo-segmentation. Extensive experiments on two benchmark datasets (i.e., DialSeg711 and Doc2Dial) demonstrate that our method significantly outperforms the strong baseline methods. For reproducibility, we provide our code and data at:https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/dial-start.
Empathetic Response Generation via Emotion Cause Transition Graph
Feb 23, 2023



Empathetic dialogue is a human-like behavior that requires the perception of both affective factors (e.g., emotion status) and cognitive factors (e.g., cause of the emotion). Besides concerning emotion status in early work, the latest approaches study emotion causes in empathetic dialogue. These approaches focus on understanding and duplicating emotion causes in the context to show empathy for the speaker. However, instead of only repeating the contextual causes, the real empathic response often demonstrate a logical and emotion-centered transition from the causes in the context to those in the responses. In this work, we propose an emotion cause transition graph to explicitly model the natural transition of emotion causes between two adjacent turns in empathetic dialogue. With this graph, the concept words of the emotion causes in the next turn can be predicted and used by a specifically designed concept-aware decoder to generate the empathic response. Automatic and human experimental results on the benchmark dataset demonstrate that our method produces more empathetic, coherent, informative, and specific responses than existing models.
UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition
Nov 21, 2022



Multimodal sentiment analysis (MSA) and emotion recognition in conversation (ERC) are key research topics for computers to understand human behaviors. From a psychological perspective, emotions are the expression of affect or feelings during a short period, while sentiments are formed and held for a longer period. However, most existing works study sentiment and emotion separately and do not fully exploit the complementary knowledge behind the two. In this paper, we propose a multimodal sentiment knowledge-sharing framework (UniMSE) that unifies MSA and ERC tasks from features, labels, and models. We perform modality fusion at the syntactic and semantic levels and introduce contrastive learning between modalities and samples to better capture the difference and consistency between sentiments and emotions. Experiments on four public benchmark datasets, MOSI, MOSEI, MELD, and IEMOCAP, demonstrate the effectiveness of the proposed method and achieve consistent improvements compared with state-of-the-art methods.
Duplex Conversation: Towards Human-like Interaction in Spoken Dialogue Systems
Jun 09, 2022

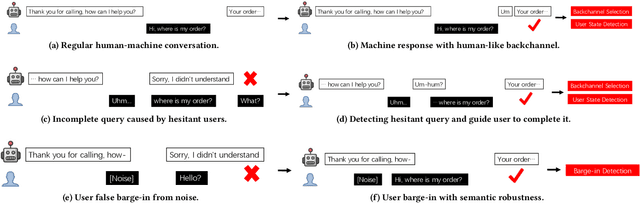
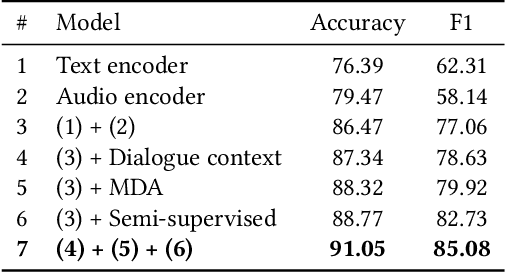
In this paper, we present Duplex Conversation, a multi-turn, multimodal spoken dialogue system that enables telephone-based agents to interact with customers like a human. We use the concept of full-duplex in telecommunication to demonstrate what a human-like interactive experience should be and how to achieve smooth turn-taking through three subtasks: user state detection, backchannel selection, and barge-in detection. Besides, we propose semi-supervised learning with multimodal data augmentation to leverage unlabeled data to increase model generalization. Experimental results on three sub-tasks show that the proposed method achieves consistent improvements compared with baselines. We deploy the Duplex Conversation to Alibaba intelligent customer service and share lessons learned in production. Online A/B experiments show that the proposed system can significantly reduce response latency by 50%.