 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRareBench: Can LLMs Serve as Rare Diseases Specialists?
Feb 09, 2024



Generalist Large Language Models (LLMs), such as GPT-4, have shown considerable promise in various domains, including medical diagnosis. Rare diseases, affecting approximately 300 million people worldwide, often have unsatisfactory clinical diagnosis rates primarily due to a lack of experienced physicians and the complexity of differentiating among many rare diseases. In this context, recent news such as "ChatGPT correctly diagnosed a 4-year-old's rare disease after 17 doctors failed" underscore LLMs' potential, yet underexplored, role in clinically diagnosing rare diseases. To bridge this research gap, we introduce RareBench, a pioneering benchmark designed to systematically evaluate the capabilities of LLMs on 4 critical dimensions within the realm of rare diseases. Meanwhile, we have compiled the largest open-source dataset on rare disease patients, establishing a benchmark for future studies in this domain. To facilitate differential diagnosis of rare diseases, we develop a dynamic few-shot prompt methodology, leveraging a comprehensive rare disease knowledge graph synthesized from multiple knowledge bases, significantly enhancing LLMs' diagnostic performance. Moreover, we present an exhaustive comparative study of GPT-4's diagnostic capabilities against those of specialist physicians. Our experimental findings underscore the promising potential of integrating LLMs into the clinical diagnostic process for rare diseases. This paves the way for exciting possibilities in future advancements in this field.
Automating Sound Change Prediction for Phylogenetic Inference: A Tukanoan Case Study
Feb 02, 2024



We describe a set of new methods to partially automate linguistic phylogenetic inference given (1) cognate sets with their respective protoforms and sound laws, (2) a mapping from phones to their articulatory features and (3) a typological database of sound changes. We train a neural network on these sound change data to weight articulatory distances between phones and predict intermediate sound change steps between historical protoforms and their modern descendants, replacing a linguistic expert in part of a parsimony-based phylogenetic inference algorithm. In our best experiments on Tukanoan languages, this method produces trees with a Generalized Quartet Distance of 0.12 from a tree that used expert annotations, a significant improvement over other semi-automated baselines. We discuss potential benefits and drawbacks to our neural approach and parsimony-based tree prediction. We also experiment with a minimal generalization learner for automatic sound law induction, finding it comparably effective to sound laws from expert annotation. Our code is publicly available at https://github.com/cmu-llab/aiscp.
Encoder-minimal and Decoder-minimal Framework for Remote Sensing Image Dehazing
Dec 13, 2023



Haze obscures remote sensing images, hindering valuable information extraction. To this end, we propose RSHazeNet, an encoder-minimal and decoder-minimal framework for efficient remote sensing image dehazing. Specifically, regarding the process of merging features within the same level, we develop an innovative module called intra-level transposed fusion module (ITFM). This module employs adaptive transposed self-attention to capture comprehensive context-aware information, facilitating the robust context-aware feature fusion. Meanwhile, we present a cross-level multi-view interaction module (CMIM) to enable effective interactions between features from various levels, mitigating the loss of information due to the repeated sampling operations. In addition, we propose a multi-view progressive extraction block (MPEB) that partitions the features into four distinct components and employs convolution with varying kernel sizes, groups, and dilation factors to facilitate view-progressive feature learning. Extensive experiments demonstrate the superiority of our proposed RSHazeNet. We release the source code and all pre-trained models at \url{https://github.com/chdwyb/RSHazeNet}.
Pre-trained Universal Medical Image Transformer
Dec 12, 2023Self-supervised learning has emerged as a viable method to leverage the abundance of unlabeled medical imaging data, addressing the challenge of labeled data scarcity in medical image analysis. In particular, masked image modeling (MIM) with visual token reconstruction has shown promising results in the general computer vision (CV) domain and serves as a candidate for medical image analysis. However, the presence of heterogeneous 2D and 3D medical images often limits the volume and diversity of training data that can be effectively used for a single model structure. In this work, we propose a spatially adaptive convolution (SAC) module, which adaptively adjusts convolution parameters based on the voxel spacing of the input images. Employing this SAC module, we build a universal visual tokenizer and a universal Vision Transformer (ViT) capable of effectively processing a wide range of medical images with various imaging modalities and spatial properties. Moreover, in order to enhance the robustness of the visual tokenizer's reconstruction objective for MIM, we suggest to generalize the discrete token output of the visual tokenizer to a probabilistic soft token. We show that the generalized soft token representation can be effectively integrated with the prior distribution regularization through a constructive interpretation. As a result, we pre-train a universal visual tokenizer followed by a universal ViT via visual token reconstruction on 55 public medical image datasets, comprising over 9 million 2D slices (including over 48,000 3D images). This represents the largest, most comprehensive, and diverse dataset for pre-training 3D medical image models to our knowledge. Experimental results on downstream medical image classification and segmentation tasks demonstrate the superior performance of our model and improved label efficiency.
Perceptual Group Tokenizer: Building Perception with Iterative Grouping
Nov 30, 2023
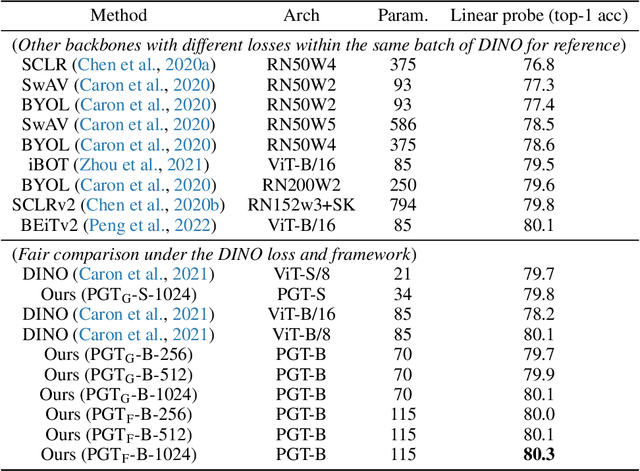
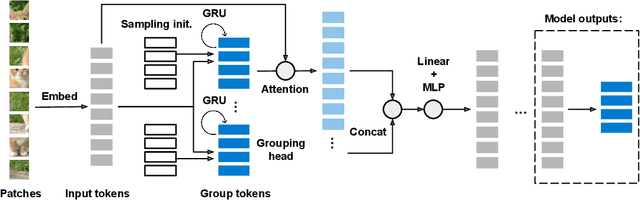
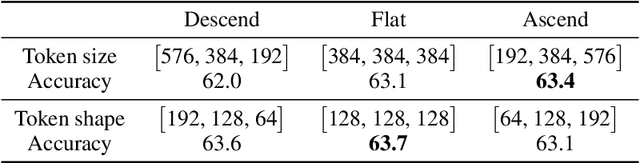
Human visual recognition system shows astonishing capability of compressing visual information into a set of tokens containing rich representations without label supervision. One critical driving principle behind it is perceptual grouping. Despite being widely used in computer vision in the early 2010s, it remains a mystery whether perceptual grouping can be leveraged to derive a neural visual recognition backbone that generates as powerful representations. In this paper, we propose the Perceptual Group Tokenizer, a model that entirely relies on grouping operations to extract visual features and perform self-supervised representation learning, where a series of grouping operations are used to iteratively hypothesize the context for pixels or superpixels to refine feature representations. We show that the proposed model can achieve competitive performance compared to state-of-the-art vision architectures, and inherits desirable properties including adaptive computation without re-training, and interpretability. Specifically, Perceptual Group Tokenizer achieves 80.3% on ImageNet-1K self-supervised learning benchmark with linear probe evaluation, marking a new progress under this paradigm.
Towards A Unified Neural Architecture for Visual Recognition and Reasoning
Nov 10, 2023



Recognition and reasoning are two pillars of visual understanding. However, these tasks have an imbalance in focus; whereas recent advances in neural networks have shown strong empirical performance in visual recognition, there has been comparably much less success in solving visual reasoning. Intuitively, unifying these two tasks under a singular framework is desirable, as they are mutually dependent and beneficial. Motivated by the recent success of multi-task transformers for visual recognition and language understanding, we propose a unified neural architecture for visual recognition and reasoning with a generic interface (e.g., tokens) for both. Our framework enables the principled investigation of how different visual recognition tasks, datasets, and inductive biases can help enable spatiotemporal reasoning capabilities. Noticeably, we find that object detection, which requires spatial localization of individual objects, is the most beneficial recognition task for reasoning. We further demonstrate via probing that implicit object-centric representations emerge automatically inside our framework. Intriguingly, we discover that certain architectural choices such as the backbone model of the visual encoder have a significant impact on visual reasoning, but little on object detection. Given the results of our experiments, we believe that visual reasoning should be considered as a first-class citizen alongside visual recognition, as they are strongly correlated but benefit from potentially different design choices.
Multi-dimension Queried and Interacting Network for Stereo Image Deraining
Sep 19, 2023Eliminating the rain degradation in stereo images poses a formidable challenge, which necessitates the efficient exploitation of mutual information present between the dual views. To this end, we devise MQINet, which employs multi-dimension queries and interactions for stereo image deraining. More specifically, our approach incorporates a context-aware dimension-wise queried block (CDQB). This module leverages dimension-wise queries that are independent of the input features and employs global context-aware attention (GCA) to capture essential features while avoiding the entanglement of redundant or irrelevant information. Meanwhile, we introduce an intra-view physics-aware attention (IPA) based on the inverse physical model of rainy images. IPA extracts shallow features that are sensitive to the physics of rain degradation, facilitating the reduction of rain-related artifacts during the early learning period. Furthermore, we integrate a cross-view multi-dimension interacting attention mechanism (CMIA) to foster comprehensive feature interaction between the two views across multiple dimensions. Extensive experimental evaluations demonstrate the superiority of our model over EPRRNet and StereoIRR, achieving respective improvements of 4.18 dB and 0.45 dB in PSNR. Code and models are available at \url{https://github.com/chdwyb/MQINet}.
HyperFormer: Learning Expressive Sparse Feature Representations via Hypergraph Transformer
May 27, 2023Learning expressive representations for high-dimensional yet sparse features has been a longstanding problem in information retrieval. Though recent deep learning methods can partially solve the problem, they often fail to handle the numerous sparse features, particularly those tail feature values with infrequent occurrences in the training data. Worse still, existing methods cannot explicitly leverage the correlations among different instances to help further improve the representation learning on sparse features since such relational prior knowledge is not provided. To address these challenges, in this paper, we tackle the problem of representation learning on feature-sparse data from a graph learning perspective. Specifically, we propose to model the sparse features of different instances using hypergraphs where each node represents a data instance and each hyperedge denotes a distinct feature value. By passing messages on the constructed hypergraphs based on our Hypergraph Transformer (HyperFormer), the learned feature representations capture not only the correlations among different instances but also the correlations among features. Our experiments demonstrate that the proposed approach can effectively improve feature representation learning on sparse features.
FIT: Far-reaching Interleaved Transformers
May 25, 2023



We present FIT: a transformer-based architecture with efficient self-attention and adaptive computation. Unlike original transformers, which operate on a single sequence of data tokens, we divide the data tokens into groups, with each group being a shorter sequence of tokens. We employ two types of transformer layers: local layers operate on data tokens within each group, while global layers operate on a smaller set of introduced latent tokens. These layers, comprising the same set of self-attention and feed-forward layers as standard transformers, are interleaved, and cross-attention is used to facilitate information exchange between data and latent tokens within the same group. The attention complexity is $O(n^2)$ locally within each group of size $n$, but can reach $O(L^{{4}/{3}})$ globally for sequence length of $L$. The efficiency can be further enhanced by relying more on global layers that perform adaptive computation using a smaller set of latent tokens. FIT is a versatile architecture and can function as an encoder, diffusion decoder, or autoregressive decoder. We provide initial evidence demonstrating its effectiveness in high-resolution image understanding and generation tasks. Notably, FIT exhibits potential in performing end-to-end training on gigabit-scale data, such as 6400$\times$6400 images, or 160K tokens (after patch tokenization), within a memory capacity of 16GB, without requiring specific optimizations or model parallelism.
Towards an Effective and Efficient Transformer for Rain-by-snow Weather Removal
Apr 06, 2023



Rain-by-snow weather removal is a specialized task in weather-degraded image restoration aiming to eliminate coexisting rain streaks and snow particles. In this paper, we propose RSFormer, an efficient and effective Transformer that addresses this challenge. Initially, we explore the proximity of convolution networks (ConvNets) and vision Transformers (ViTs) in hierarchical architectures and experimentally find they perform approximately at intra-stage feature learning. On this basis, we utilize a Transformer-like convolution block (TCB) that replaces the computationally expensive self-attention while preserving attention characteristics for adapting to input content. We also demonstrate that cross-stage progression is critical for performance improvement, and propose a global-local self-attention sampling mechanism (GLASM) that down-/up-samples features while capturing both global and local dependencies. Finally, we synthesize two novel rain-by-snow datasets, RSCityScape and RS100K, to evaluate our proposed RSFormer. Extensive experiments verify that RSFormer achieves the best trade-off between performance and time-consumption compared to other restoration methods. For instance, it outperforms Restormer with a 1.53% reduction in the number of parameters and a 15.6% reduction in inference time. Datasets, source code and pre-trained models are available at \url{https://github.com/chdwyb/RSFormer}.