 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadioLLM: Introducing Large Language Model into Cognitive Radio via Hybrid Prompt and Token Reprogrammings
Jan 28, 2025



The increasing scarcity of spectrum resources and the rapid growth of wireless device have made efficient management of radio networks a critical challenge. Cognitive Radio Technology (CRT), when integrated with deep learning (DL), offers promising solutions for tasks such as radio signal classification (RSC), signal denoising, and spectrum allocation. However, existing DL-based CRT frameworks are often task-specific and lack scalability to diverse real-world scenarios. Meanwhile, Large Language Models (LLMs) have demonstrated exceptional generalization capabilities across multiple domains, making them a potential candidate for advancing CRT technologies. In this paper, we introduce RadioLLM, a novel framework that incorporates Hybrid Prompt and Token Reprogramming (HPTR) and a Frequency Attuned Fusion (FAF) module to enhance LLMs for CRT tasks. HPTR enables the integration of radio signal features with expert knowledge, while FAF improves the modeling of high-frequency features critical for precise signal processing. These innovations allow RadioLLM to handle diverse CRT tasks, bridging the gap between LLMs and traditional signal processing methods. Extensive empirical studies on multiple benchmark datasets demonstrate that the proposed RadioLLM achieves superior performance over current baselines.
Peri-midFormer: Periodic Pyramid Transformer for Time Series Analysis
Nov 07, 2024



Time series analysis finds wide applications in fields such as weather forecasting, anomaly detection, and behavior recognition. Previous methods attempted to model temporal variations directly using 1D time series. However, this has been quite challenging due to the discrete nature of data points in time series and the complexity of periodic variation. In terms of periodicity, taking weather and traffic data as an example, there are multi-periodic variations such as yearly, monthly, weekly, and daily, etc. In order to break through the limitations of the previous methods, we decouple the implied complex periodic variations into inclusion and overlap relationships among different level periodic components based on the observation of the multi-periodicity therein and its inclusion relationships. This explicitly represents the naturally occurring pyramid-like properties in time series, where the top level is the original time series and lower levels consist of periodic components with gradually shorter periods, which we call the periodic pyramid. To further extract complex temporal variations, we introduce self-attention mechanism into the periodic pyramid, capturing complex periodic relationships by computing attention between periodic components based on their inclusion, overlap, and adjacency relationships. Our proposed Peri-midFormer demonstrates outstanding performance in five mainstream time series analysis tasks, including short- and long-term forecasting, imputation, classification, and anomaly detection.
Meta-Learning Guided Label Noise Distillation for Robust Signal Modulation Classification
Aug 09, 2024
Automatic modulation classification (AMC) is an effective way to deal with physical layer threats of the internet of things (IoT). However, there is often label mislabeling in practice, which significantly impacts the performance and robustness of deep neural networks (DNNs). In this paper, we propose a meta-learning guided label noise distillation method for robust AMC. Specifically, a teacher-student heterogeneous network (TSHN) framework is proposed to distill and reuse label noise. Based on the idea that labels are representations, the teacher network with trusted meta-learning divides and conquers untrusted label samples and then guides the student network to learn better by reassessing and correcting labels. Furthermore, we propose a multi-view signal (MVS) method to further improve the performance of hard-to-classify categories with few-shot trusted label samples. Extensive experimental results show that our methods can significantly improve the performance and robustness of signal AMC in various and complex label noise scenarios, which is crucial for securing IoT applications.
Heterogeneous Network Based Contrastive Learning Method for PolSAR Land Cover Classification
Mar 29, 2024Polarimetric synthetic aperture radar (PolSAR) image interpretation is widely used in various fields. Recently, deep learning has made significant progress in PolSAR image classification. Supervised learning (SL) requires a large amount of labeled PolSAR data with high quality to achieve better performance, however, manually labeled data is insufficient. This causes the SL to fail into overfitting and degrades its generalization performance. Furthermore, the scattering confusion problem is also a significant challenge that attracts more attention. To solve these problems, this article proposes a Heterogeneous Network based Contrastive Learning method(HCLNet). It aims to learn high-level representation from unlabeled PolSAR data for few-shot classification according to multi-features and superpixels. Beyond the conventional CL, HCLNet introduces the heterogeneous architecture for the first time to utilize heterogeneous PolSAR features better. And it develops two easy-to-use plugins to narrow the domain gap between optics and PolSAR, including feature filter and superpixel-based instance discrimination, which the former is used to enhance the complementarity of multi-features, and the latter is used to increase the diversity of negative samples. Experiments demonstrate the superiority of HCLNet on three widely used PolSAR benchmark datasets compared with state-of-the-art methods. Ablation studies also verify the importance of each component. Besides, this work has implications for how to efficiently utilize the multi-features of PolSAR data to learn better high-level representation in CL and how to construct networks suitable for PolSAR data better.
AMC-Net: An Effective Network for Automatic Modulation Classification
Apr 02, 2023Automatic modulation classification (AMC) is a crucial stage in the spectrum management, signal monitoring, and control of wireless communication systems. The accurate classification of the modulation format plays a vital role in the subsequent decoding of the transmitted data. End-to-end deep learning methods have been recently applied to AMC, outperforming traditional feature engineering techniques. However, AMC still has limitations in low signal-to-noise ratio (SNR) environments. To address the drawback, we propose a novel AMC-Net that improves recognition by denoising the input signal in the frequency domain while performing multi-scale and effective feature extraction. Experiments on two representative datasets demonstrate that our model performs better in efficiency and effectiveness than the most current methods.
Transformers Meet Visual Learning Understanding: A Comprehensive Review
Mar 24, 2022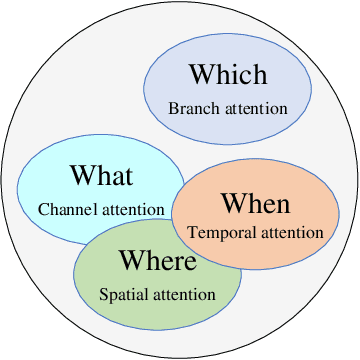
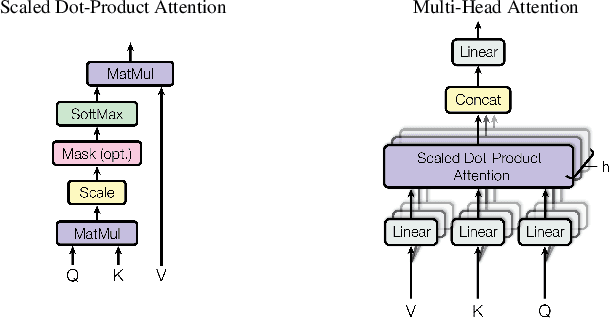
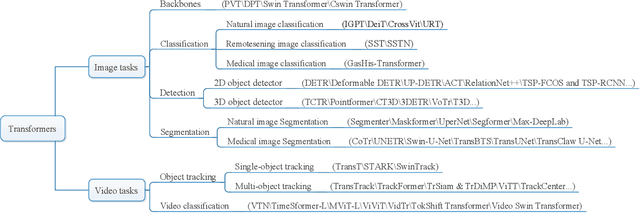
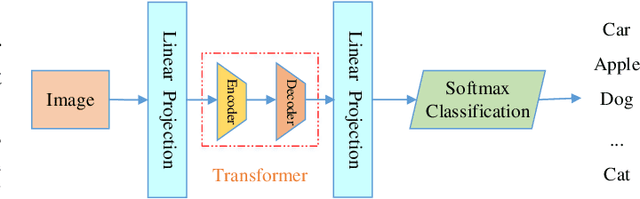
Dynamic attention mechanism and global modeling ability make Transformer show strong feature learning ability. In recent years, Transformer has become comparable to CNNs methods in computer vision. This review mainly investigates the current research progress of Transformer in image and video applications, which makes a comprehensive overview of Transformer in visual learning understanding. First, the attention mechanism is reviewed, which plays an essential part in Transformer. And then, the visual Transformer model and the principle of each module are introduced. Thirdly, the existing Transformer-based models are investigated, and their performance is compared in visual learning understanding applications. Three image tasks and two video tasks of computer vision are investigated. The former mainly includes image classification, object detection, and image segmentation. The latter contains object tracking and video classification. It is significant for comparing different models' performance in various tasks on several public benchmark data sets. Finally, ten general problems are summarized, and the developing prospects of the visual Transformer are given in this review.
A Survey of Deep Learning-based Object Detection
Jul 11, 2019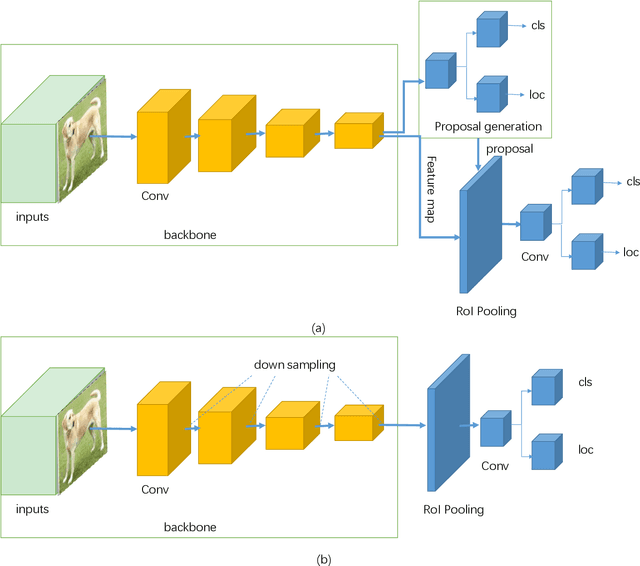



Object detection is one of the most important and challenging branches of computer vision, which has been widely applied in peoples life, such as monitoring security, autonomous driving and so on, with the purpose of locating instances of semantic objects of a certain class. With the rapid development of deep learning networks for detection tasks, the performance of object detectors has been greatly improved. In order to understand the main development status of object detection pipeline, thoroughly and deeply, in this survey, we first analyze the methods of existing typical detection models and describe the benchmark datasets. Afterwards and primarily, we provide a comprehensive overview of a variety of object detection methods in a systematic manner, covering the one-stage and two-stage detectors. Moreover, we list the traditional and new applications. Some representative branches of object detection are analyzed as well. Finally, we discuss the architecture of exploiting these object detection methods to build an effective and efficient system and point out a set of development trends to better follow the state-of-the-art algorithms and further research.