 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIF2Net: Innately Forgetting-Free Networks for Continual Learning
Jun 18, 2023Continual learning can incrementally absorb new concepts without interfering with previously learned knowledge. Motivated by the characteristics of neural networks, in which information is stored in weights on connections, we investigated how to design an Innately Forgetting-Free Network (IF2Net) for continual learning context. This study proposed a straightforward yet effective learning paradigm by ingeniously keeping the weights relative to each seen task untouched before and after learning a new task. We first presented the novel representation-level learning on task sequences with random weights. This technique refers to tweaking the drifted representations caused by randomization back to their separate task-optimal working states, but the involved weights are frozen and reused (opposite to well-known layer-wise updates of weights). Then, sequential decision-making without forgetting can be achieved by projecting the output weight updates into the parsimonious orthogonal space, making the adaptations not disturb old knowledge while maintaining model plasticity. IF2Net allows a single network to inherently learn unlimited mapping rules without telling task identities at test time by integrating the respective strengths of randomization and orthogonalization. We validated the effectiveness of our approach in the extensive theoretical analysis and empirical study.
Multi-View Class Incremental Learning
Jun 16, 2023



Multi-view learning (MVL) has gained great success in integrating information from multiple perspectives of a dataset to improve downstream task performance. To make MVL methods more practical in an open-ended environment, this paper investigates a novel paradigm called multi-view class incremental learning (MVCIL), where a single model incrementally classifies new classes from a continual stream of views, requiring no access to earlier views of data. However, MVCIL is challenged by the catastrophic forgetting of old information and the interference with learning new concepts. To address this, we first develop a randomization-based representation learning technique serving for feature extraction to guarantee their separate view-optimal working states, during which multiple views belonging to a class are presented sequentially; Then, we integrate them one by one in the orthogonality fusion subspace spanned by the extracted features; Finally, we introduce selective weight consolidation for learning-without-forgetting decision-making while encountering new classes. Extensive experiments on synthetic and real-world datasets validate the effectiveness of our approach.
DeepAccident: A Motion and Accident Prediction Benchmark for V2X Autonomous Driving
Apr 10, 2023



Safety is the primary priority of autonomous driving. Nevertheless, no published dataset currently supports the direct and explainable safety evaluation for autonomous driving. In this work, we propose DeepAccident, a large-scale dataset generated via a realistic simulator containing diverse accident scenarios that frequently occur in real-world driving. The proposed DeepAccident dataset contains 57K annotated frames and 285K annotated samples, approximately 7 times more than the large-scale nuScenes dataset with 40k annotated samples. In addition, we propose a new task, end-to-end motion and accident prediction, based on the proposed dataset, which can be used to directly evaluate the accident prediction ability for different autonomous driving algorithms. Furthermore, for each scenario, we set four vehicles along with one infrastructure to record data, thus providing diverse viewpoints for accident scenarios and enabling V2X (vehicle-to-everything) research on perception and prediction tasks. Finally, we present a baseline V2X model named V2XFormer that demonstrates superior performance for motion and accident prediction and 3D object detection compared to the single-vehicle model.
Fast-BEV: Towards Real-time On-vehicle Bird's-Eye View Perception
Jan 19, 2023



Recently, the pure camera-based Bird's-Eye-View (BEV) perception removes expensive Lidar sensors, making it a feasible solution for economical autonomous driving. However, most existing BEV solutions either suffer from modest performance or require considerable resources to execute on-vehicle inference. This paper proposes a simple yet effective framework, termed Fast-BEV, which is capable of performing real-time BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive view transformation or depth representation. Starting from M2BEV baseline, we further introduce (1) a strong data augmentation strategy for both image and BEV space to avoid over-fitting (2) a multi-frame feature fusion mechanism to leverage the temporal information (3) an optimized deployment-friendly view transformation to speed up the inference. Through experiments, we show Fast-BEV model family achieves considerable accuracy and efficiency on edge. In particular, our M1 model (R18@256x704) can run over 50FPS on the Tesla T4 platform, with 47.0% NDS on the nuScenes validation set. Our largest model (R101@900x1600) establishes a new state-of-the-art 53.5% NDS on the nuScenes validation set. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
* Accepted by NeurIPS2022_ML4AD on October 22, 2022
Scale-Equivalent Distillation for Semi-Supervised Object Detection
Mar 26, 2022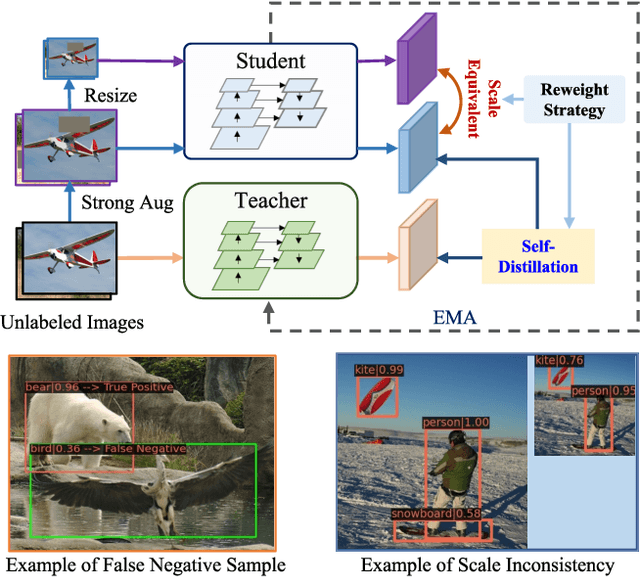
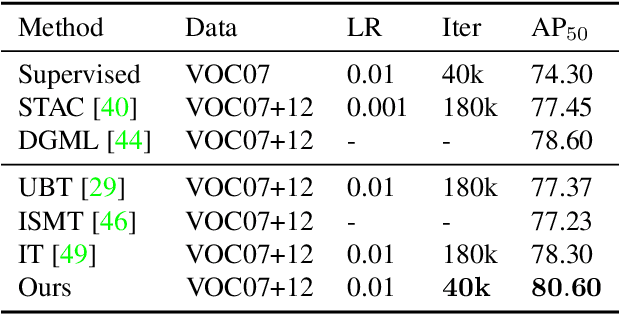
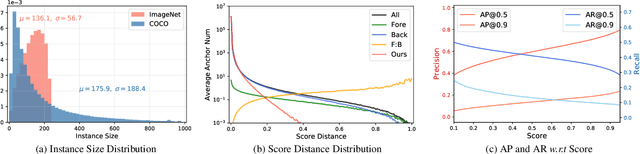
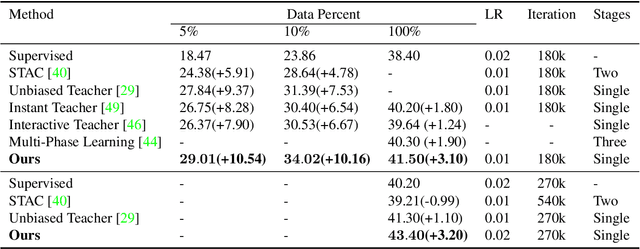
Recent Semi-Supervised Object Detection (SS-OD) methods are mainly based on self-training, i.e., generating hard pseudo-labels by a teacher model on unlabeled data as supervisory signals. Although they achieved certain success, the limited labeled data in semi-supervised learning scales up the challenges of object detection. We analyze the challenges these methods meet with the empirical experiment results. We find that the massive False Negative samples and inferior localization precision lack consideration. Besides, the large variance of object sizes and class imbalance (i.e., the extreme ratio between background and object) hinder the performance of prior arts. Further, we overcome these challenges by introducing a novel approach, Scale-Equivalent Distillation (SED), which is a simple yet effective end-to-end knowledge distillation framework robust to large object size variance and class imbalance. SED has several appealing benefits compared to the previous works. (1) SED imposes a consistency regularization to handle the large scale variance problem. (2) SED alleviates the noise problem from the False Negative samples and inferior localization precision. (3) A re-weighting strategy can implicitly screen the potential foreground regions of the unlabeled data to reduce the effect of class imbalance. Extensive experiments show that SED consistently outperforms the recent state-of-the-art methods on different datasets with significant margins. For example, it surpasses the supervised counterpart by more than 10 mAP when using 5% and 10% labeled data on MS-COCO.
Clutter Edges Detection Algorithms for Structured Clutter Covariance Matrices
Feb 03, 2022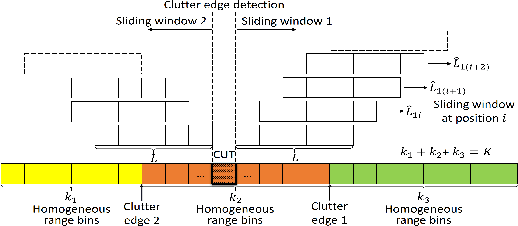
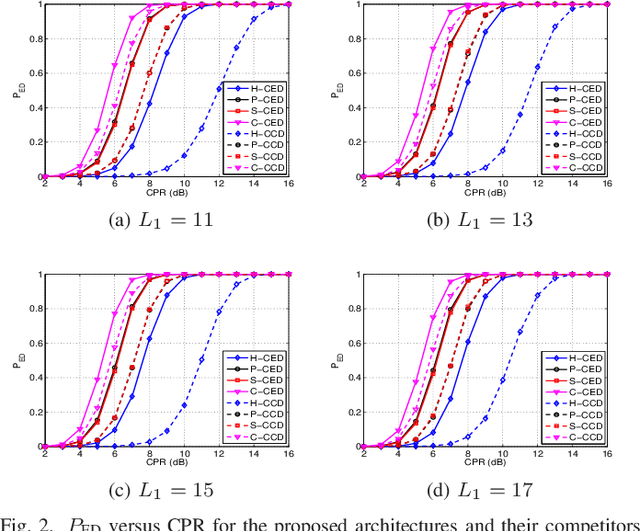
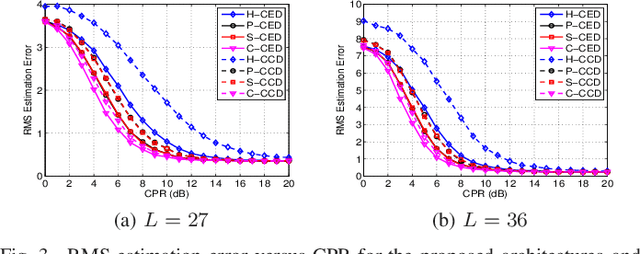
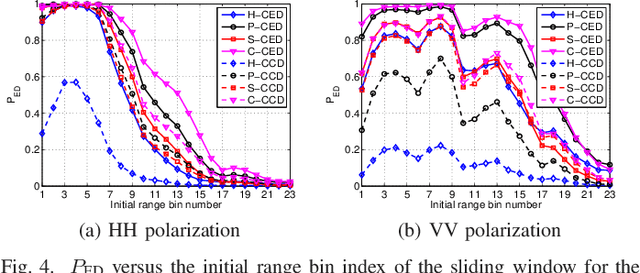
This letter deals with the problem of clutter edge detection and localization in training data. To this end, the problem is formulated as a binary hypothesis test assuming that the ranks of the clutter covariance matrix are known, and adaptive architectures are designed based on the generalized likelihood ratio test to decide whether the training data within a sliding window contains a homogeneous set or two heterogeneous subsets. In the design stage, we utilize four different covariance matrix structures (i.e., Hermitian, persymmetric, symmetric, and centrosymmetric) to exploit the a priori information. Then, for the case of unknown ranks, the architectures are extended by devising a preliminary estimation stage resorting to the model order selection rules. Numerical examples based on both synthetic and real data highlight that the proposed solutions possess superior detection and localization performance with respect to the competitors that do not use any a priori information.
Robust Navigation for Racing Drones based on Imitation Learning and Modularization
May 27, 2021
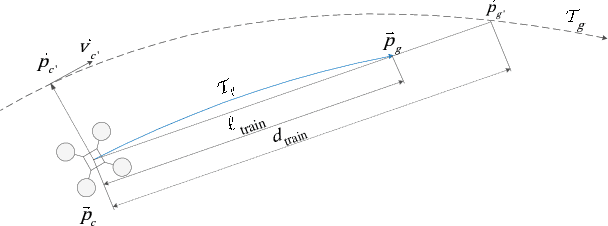
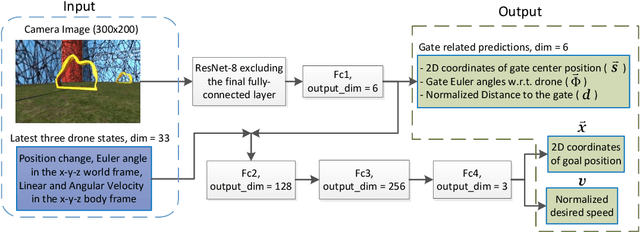

This paper presents a vision-based modularized drone racing navigation system that uses a customized convolutional neural network (CNN) for the perception module to produce high-level navigation commands and then leverages a state-of-the-art planner and controller to generate low-level control commands, thus exploiting the advantages of both data-based and model-based approaches. Unlike the state-of-the-art method which only takes the current camera image as the CNN input, we further add the latest three drone states as part of the inputs. Our method outperforms the state-of-the-art method in various track layouts and offers two switchable navigation behaviors with a single trained network. The CNN-based perception module is trained to imitate an expert policy that automatically generates ground truth navigation commands based on the pre-computed global trajectories. Owing to the extensive randomization and our modified dataset aggregation (DAgger) policy during data collection, our navigation system, which is purely trained in simulation with synthetic textures, successfully operates in environments with randomly-chosen photorealistic textures without further fine-tuning.
BaPipe: Exploration of Balanced Pipeline Parallelism for DNN Training
Jan 14, 2021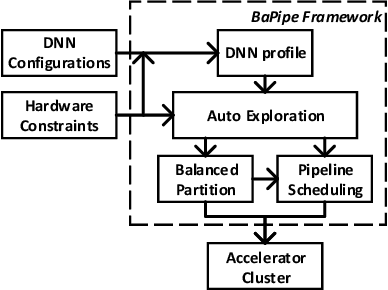
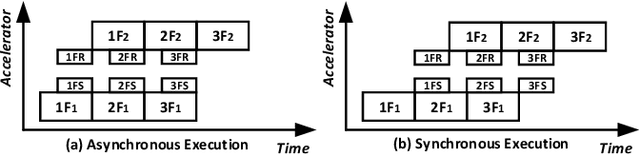
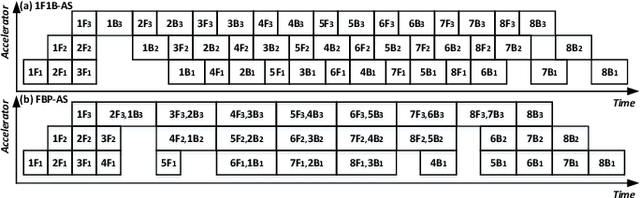
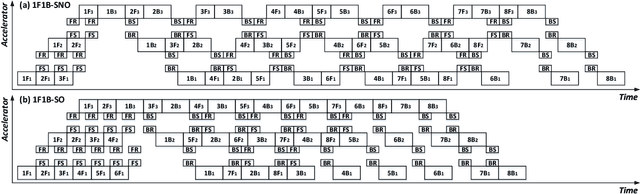
The size of deep neural networks (DNNs) grows rapidly as the complexity of the machine learning algorithm increases. To satisfy the requirement of computation and memory of DNN training, distributed deep learning based on model parallelism has been widely recognized. We propose a new pipeline parallelism training framework, BaPipe, which can automatically explore pipeline parallelism training methods and balanced partition strategies for DNN distributed training. In BaPipe, each accelerator calculates the forward propagation and backward propagation of different parts of networks to implement the intra-batch pipeline parallelism strategy. BaPipe uses a new load balancing automatic exploration strategy that considers the parameters of DNN models and the computation, memory, and communication resources of accelerator clusters. We have trained different DNNs such as VGG-16, ResNet-50, and GNMT on GPU clusters and simulated the performance of different FPGA clusters. Compared with state-of-the-art data parallelism and pipeline parallelism frameworks, BaPipe provides up to 3.2x speedup and 4x memory reduction in various platforms.
UWB-GCN: Hardware Acceleration of Graph-Convolution-Network through Runtime Workload Rebalancing
Aug 23, 2019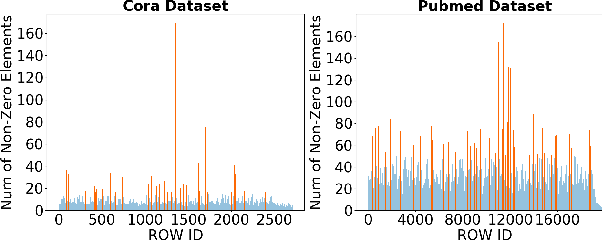
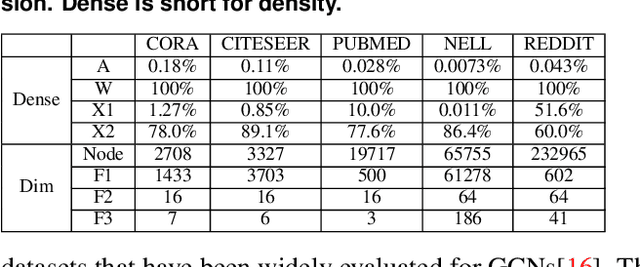
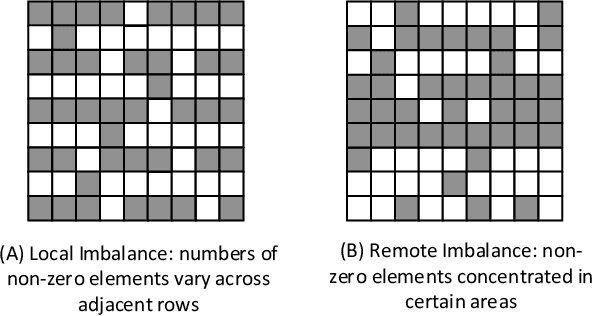
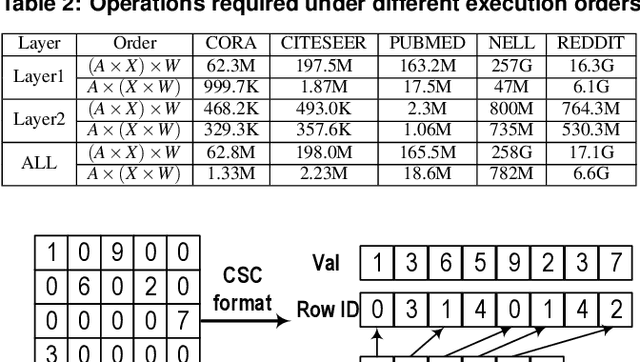
The recent development of deep learning has mostly been focusing on Euclidean data, such as images, videos, and audios. However, most real-world information and relationships are often expressed in graphs. Graph convolutional networks (GCNs) appear as a promising approach to efficiently learn from graph data structures, showing advantages in several practical applications such as social network analysis, knowledge discovery, 3D modeling, and motion capturing. However, practical graphs are often extremely large and unbalanced, posting significant performance demand and design challenges on the hardware dedicated to GCN inference. In this paper, we propose an architecture design called Ultra-Workload-Balanced-GCN (UWB-GCN) to accelerate graph convolutional network inference. To tackle the major performance bottleneck of workload imbalance, we propose two techniques: dynamic local sharing and dynamic remote switching, both of which rely on hardware flexibility to achieve performance auto-tuning with negligible area or delay overhead. Specifically, UWB-GCN is able to effectively profile the sparse graph pattern while continuously adjusting the workload distribution among parallel processing elements (PEs). After converging, the ideal configuration is reused for the remaining iterations. To the best of our knowledge, this is the first accelerator design targeted to GCNs and the first work that auto-tunes workload balance in accelerator at runtime through hardware, rather than software, approaches. Our methods can achieve near-ideal workload balance in processing sparse matrices. Experimental results show that UWB-GCN can finish the inference of the Nell graph (66K vertices, 266K edges) in 8.4ms, corresponding to 192x, 289x, and 7.3x respectively, compared to the CPU, GPU, and the baseline GCN design without workload rebalancing.
Improved Reinforcement Learning through Imitation Learning Pretraining Towards Image-based Autonomous Driving
Jul 16, 2019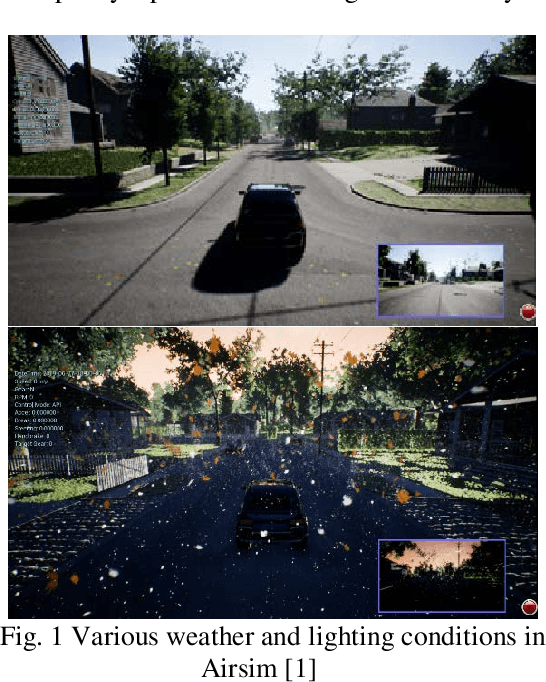
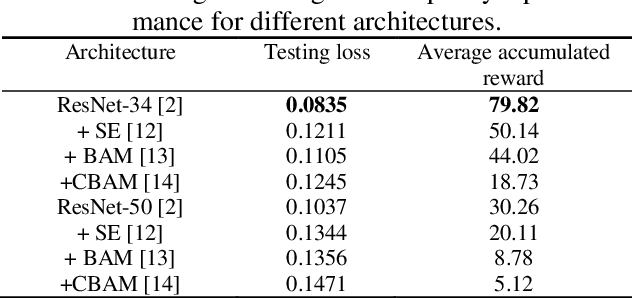
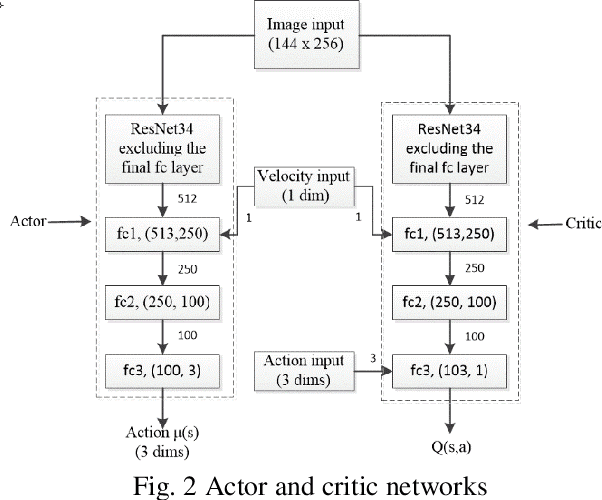

We present a training pipeline for the autonomous driving task given the current camera image and vehicle speed as the input to produce the throttle, brake, and steering control output. The simulator Airsim's convenient weather and lighting API provides a sufficient diversity during training which can be very helpful to increase the trained policy's robustness. In order to not limit the possible policy's performance, we use a continuous and deterministic control policy setting. We utilize ResNet-34 as our actor and critic networks with some slight changes in the fully connected layers. Considering human's mastery of this task and the high-complexity nature of this task, we first use imitation learning to mimic the given human policy and leverage the trained policy and its weights to the reinforcement learning phase for which we use DDPG. This combination shows a considerable performance boost comparing to both pure imitation learning and pure DDPG for the autonomous driving task.