 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Compositional Deep AUC Maximization
Apr 20, 2023



Federated learning has attracted increasing attention due to the promise of balancing privacy and large-scale learning; numerous approaches have been proposed. However, most existing approaches focus on problems with balanced data, and prediction performance is far from satisfactory for many real-world applications where the number of samples in different classes is highly imbalanced. To address this challenging problem, we developed a novel federated learning method for imbalanced data by directly optimizing the area under curve (AUC) score. In particular, we formulate the AUC maximization problem as a federated compositional minimax optimization problem, develop a local stochastic compositional gradient descent ascent with momentum algorithm, and provide bounds on the computational and communication complexities of our algorithm. To the best of our knowledge, this is the first work to achieve such favorable theoretical results. Finally, extensive experimental results confirm the efficacy of our method.
Generalization Analysis for Contrastive Representation Learning
Feb 28, 2023

Recently, contrastive learning has found impressive success in advancing the state of the art in solving various machine learning tasks. However, the existing generalization analysis is very limited or even not meaningful. In particular, the existing generalization error bounds depend linearly on the number $k$ of negative examples while it was widely shown in practice that choosing a large $k$ is necessary to guarantee good generalization of contrastive learning in downstream tasks. In this paper, we establish novel generalization bounds for contrastive learning which do not depend on $k$, up to logarithmic terms. Our analysis uses structural results on empirical covering numbers and Rademacher complexities to exploit the Lipschitz continuity of loss functions. For self-bounding Lipschitz loss functions, we further improve our results by developing optimistic bounds which imply fast rates in a low noise condition. We apply our results to learning with both linear representation and nonlinear representation by deep neural networks, for both of which we derive Rademacher complexity bounds to get improved generalization bounds.
Stochastic Approximation Approaches to Group Distributionally Robust Optimization
Feb 18, 2023This paper investigates group distributionally robust optimization (GDRO), with the purpose to learn a model that performs well over $m$ different distributions. First, we formulate GDRO as a stochastic convex-concave saddle-point problem, and demonstrate that stochastic mirror descent (SMD), using $m$ samples in each iteration, achieves an $O(m (\log m)/\epsilon^2)$ sample complexity for finding an $\epsilon$-optimal solution, which matches the $\Omega(m/\epsilon^2)$ lower bound up to a logarithmic factor. Then, we make use of techniques from online learning to reduce the number of samples required in each round from $m$ to $1$, keeping the same sample complexity. Specifically, we cast GDRO as a two-players game where one player simply performs SMD and the other executes an online algorithm for non-oblivious multi-armed bandits. Next, we consider a more practical scenario where the number of samples that can be drawn from each distribution is different, and propose a novel formulation of weighted DRO, which allows us to derive distribution-dependent convergence rates. Denote by $n_i$ the sample budget for the $i$-th distribution, and assume $n_1 \geq n_2 \geq \cdots \geq n_m$. In the first approach, we incorporate non-uniform sampling into SMD such that the sample budget is satisfied in expectation, and prove the excess risk of the $i$-th distribution decreases at an $O(\sqrt{n_1 \log m}/n_i)$ rate. In the second approach, we use mini-batches to meet the budget exactly and also reduce the variance in stochastic gradients, and then leverage stochastic mirror-prox algorithm, which can exploit small variances, to optimize a carefully designed weighted DRO problem. Under appropriate conditions, it attains an $O((\log m)/\sqrt{n_i})$ convergence rate, which almost matches the optimal $O(\sqrt{1/n_i})$ rate of only learning from the $i$-th distribution with $n_i$ samples.
Stochastic Methods for AUC Optimization subject to AUC-based Fairness Constraints
Dec 27, 2022



As machine learning being used increasingly in making high-stakes decisions, an arising challenge is to avoid unfair AI systems that lead to discriminatory decisions for protected population. A direct approach for obtaining a fair predictive model is to train the model through optimizing its prediction performance subject to fairness constraints, which achieves Pareto efficiency when trading off performance against fairness. Among various fairness metrics, the ones based on the area under the ROC curve (AUC) are emerging recently because they are threshold-agnostic and effective for unbalanced data. In this work, we formulate the training problem of a fairness-aware machine learning model as an AUC optimization problem subject to a class of AUC-based fairness constraints. This problem can be reformulated as a min-max optimization problem with min-max constraints, which we solve by stochastic first-order methods based on a new Bregman divergence designed for the special structure of the problem. We numerically demonstrate the effectiveness of our approach on real-world data under different fairness metrics.
FedX: Federated Learning for Compositional Pairwise Risk Optimization
Oct 26, 2022



In this paper, we tackle a novel federated learning (FL) problem for optimizing a family of compositional pairwise risks, to which no existing FL algorithms are applicable. In particular, the objective has the form of $\mathbb E_{\mathbf z\sim \mathcal S_1} f(\mathbb E_{\mathbf z'\sim\mathcal S_2} \ell(\mathbf w, \mathbf z, \mathbf z'))$, where two sets of data $\mathcal S_1, \mathcal S_2$ are distributed over multiple machines, $\ell(\cdot; \cdot,\cdot)$ is a pairwise loss that only depends on the prediction outputs of the input data pairs $(\mathbf z, \mathbf z')$, and $f(\cdot)$ is possibly a non-linear non-convex function. This problem has important applications in machine learning, e.g., AUROC maximization with a pairwise loss, and partial AUROC maximization with a compositional loss. The challenges for designing an FL algorithm lie in the non-decomposability of the objective over multiple machines and the interdependency between different machines. We propose two provable FL algorithms (FedX) for handling linear and nonlinear $f$, respectively. To address the challenges, we decouple the gradient's components with two types, namely active parts and lazy parts, where the active parts depend on local data that are computed with the local model and the lazy parts depend on other machines that are communicated/computed based on historical models and samples. We develop a novel theoretical analysis to combat the latency of the lazy parts and the interdependency between the local model parameters and the involved data for computing local gradient estimators. We establish both iteration and communication complexities and show that using the historical samples and models for computing the lazy parts do not degrade the complexities. We conduct empirical studies of FedX for deep AUROC and partial AUROC maximization, and demonstrate their performance compared with several baselines.
Fairness via Adversarial Attribute Neighbourhood Robust Learning
Oct 12, 2022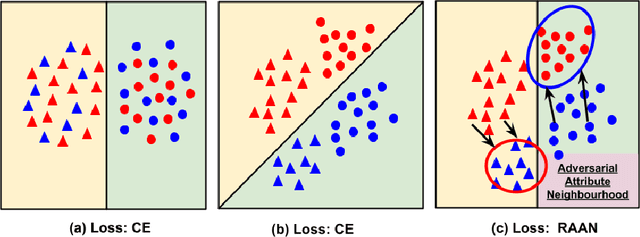

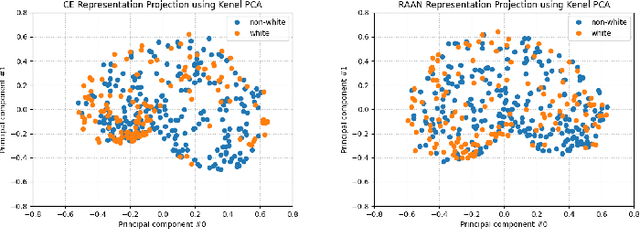
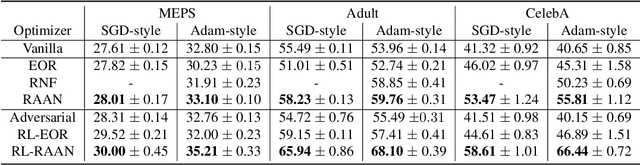
Improving fairness between privileged and less-privileged sensitive attribute groups (e.g, {race, gender}) has attracted lots of attention. To enhance the model performs uniformly well in different sensitive attributes, we propose a principled \underline{R}obust \underline{A}dversarial \underline{A}ttribute \underline{N}eighbourhood (RAAN) loss to debias the classification head and promote a fairer representation distribution across different sensitive attribute groups. The key idea of RAAN is to mitigate the differences of biased representations between different sensitive attribute groups by assigning each sample an adversarial robust weight, which is defined on the representations of adversarial attribute neighbors, i.e, the samples from different protected groups. To provide efficient optimization algorithms, we cast the RAAN into a sum of coupled compositional functions and propose a stochastic adaptive (Adam-style) and non-adaptive (SGD-style) algorithm framework SCRAAN with provable theoretical guarantee. Extensive empirical studies on fairness-related benchmark datasets verify the effectiveness of the proposed method.
Stochastic Constrained DRO with a Complexity Independent of Sample Size
Oct 11, 2022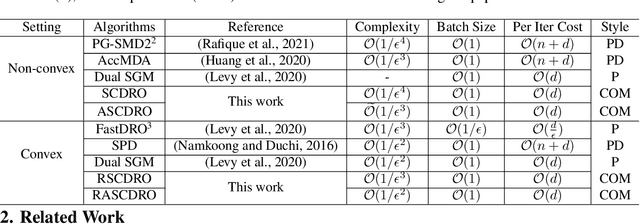



Distributionally Robust Optimization (DRO), as a popular method to train robust models against distribution shift between training and test sets, has received tremendous attention in recent years. In this paper, we propose and analyze stochastic algorithms that apply to both non-convex and convex losses for solving Kullback Leibler divergence constrained DRO problem. Compared with existing methods solving this problem, our stochastic algorithms not only enjoy competitive if not better complexity independent of sample size but also just require a constant batch size at every iteration, which is more practical for broad applications. We establish a nearly optimal complexity bound for finding an $\epsilon$ stationary solution for non-convex losses and an optimal complexity for finding an $\epsilon$ optimal solution for convex losses. Empirical studies demonstrate the effectiveness of the proposed algorithms for solving non-convex and convex constrained DRO problems.
Multi-block-Single-probe Variance Reduced Estimator for Coupled Compositional Optimization
Jul 18, 2022
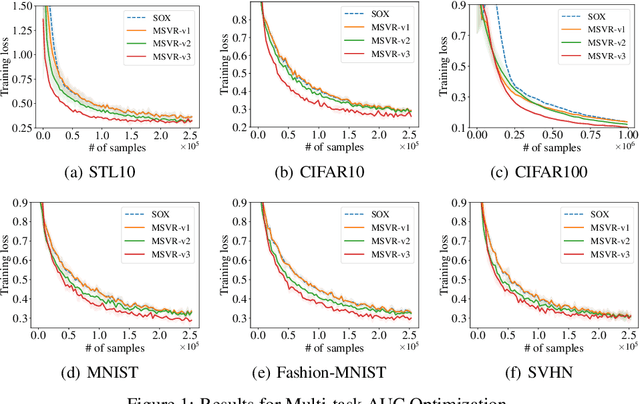
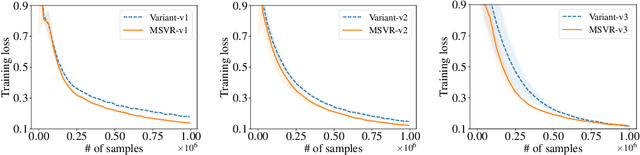
Variance reduction techniques such as SPIDER/SARAH/STORM have been extensively studied to improve the convergence rates of stochastic non-convex optimization, which usually maintain and update a sequence of estimators for a single function across iterations. {\it What if we need to track multiple functional mappings across iterations but only with access to stochastic samples of $\mathcal{O}(1)$ functional mappings at each iteration?} There is an important application in solving an emerging family of coupled compositional optimization problems in the form of $\sum_{i=1}^m f_i(g_i(\mathbf{w}))$, where $g_i$ is accessible through a stochastic oracle. The key issue is to track and estimate a sequence of $\mathbf g(\mathbf{w})=(g_1(\mathbf{w}), \ldots, g_m(\mathbf{w}))$ across iterations, where $\mathbf g(\mathbf{w})$ has $m$ blocks and it is only allowed to probe $\mathcal{O}(1)$ blocks to attain their stochastic values and Jacobians. To improve the complexity for solving these problems, we propose a novel stochastic method named Multi-block-Single-probe Variance Reduced (MSVR) estimator to track the sequence of $\mathbf g(\mathbf{w})$. It is inspired by STORM but introduces a customized error correction term to alleviate the noise not only in stochastic samples for the selected blocks but also in those blocks that are not sampled. With the help of the MSVR estimator, we develop several algorithms for solving the aforementioned compositional problems with improved complexities across a spectrum of settings with non-convex/convex/strongly convex objectives. Our results improve upon prior ones in several aspects, including the order of sample complexities and dependence on the strong convexity parameter. Empirical studies on multi-task deep AUC maximization demonstrate the better performance of using the new estimator.
GraphFM: Improving Large-Scale GNN Training via Feature Momentum
Jun 18, 2022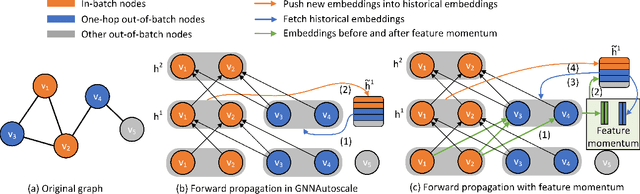
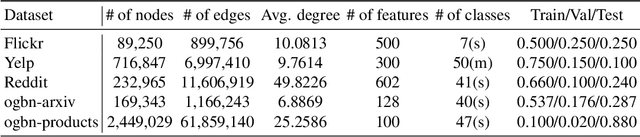
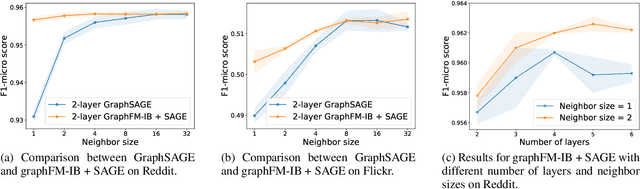
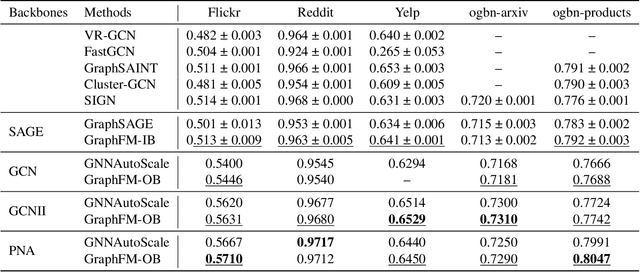
Training of graph neural networks (GNNs) for large-scale node classification is challenging. A key difficulty lies in obtaining accurate hidden node representations while avoiding the neighborhood explosion problem. Here, we propose a new technique, named feature momentum (FM), that uses a momentum step to incorporate historical embeddings when updating feature representations. We develop two specific algorithms, known as GraphFM-IB and GraphFM-OB, that consider in-batch and out-of-batch data, respectively. GraphFM-IB applies FM to in-batch sampled data, while GraphFM-OB applies FM to out-of-batch data that are 1-hop neighborhood of in-batch data. We provide a convergence analysis for GraphFM-IB and some theoretical insight for GraphFM-OB. Empirically, we observe that GraphFM-IB can effectively alleviate the neighborhood explosion problem of existing methods. In addition, GraphFM-OB achieves promising performance on multiple large-scale graph datasets.
Algorithmic Foundation of Deep X-Risk Optimization
Jun 02, 2022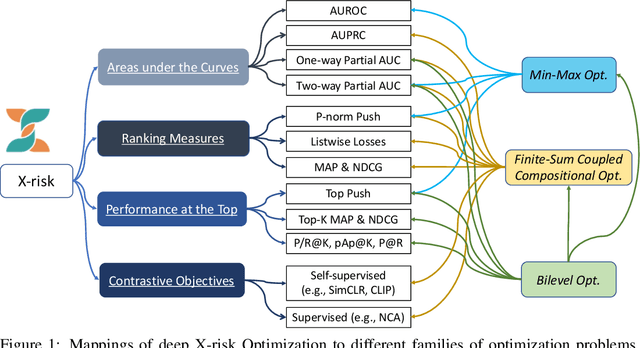

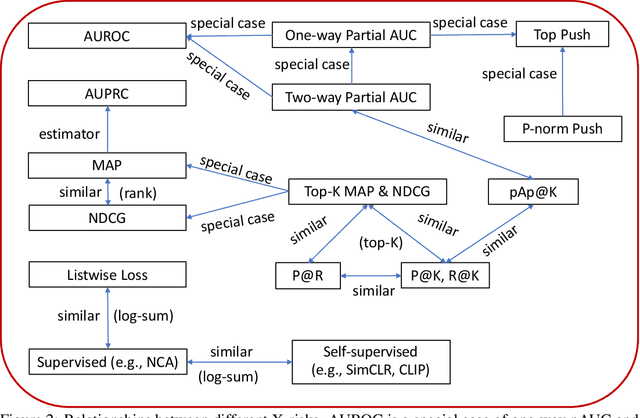
X-risk is a term introduced to represent a family of compositional measures or objectives, in which each data point is compared with a set of data points explicitly or implicitly for defining a risk function. It includes many widely used measures or objectives, e.g., AUROC, AUPRC, partial AUROC, NDCG, MAP, top-$K$ NDCG, top-$K$ MAP, listwise losses, p-norm push, top push, precision/recall at top $K$ positions, precision at a certain recall level, contrastive objectives, etc. While these measures/objectives and their optimization algorithms have been studied in the literature of machine learning, computer vision, information retrieval, and etc, optimizing these measures/objectives has encountered some unique challenges for deep learning. In this technical report, we survey our recent rigorous efforts for deep X-risk optimization (DXO) by focusing on its algorithmic foundation. We introduce a class of techniques for optimizing X-risk for deep learning. We formulate DXO into three special families of non-convex optimization problems belonging to non-convex min-max optimization, non-convex compositional optimization, and non-convex bilevel optimization, respectively. For each family of problems, we present some strong baseline algorithms and their complexities, which will motivate further research for improving the existing results. Discussions about the presented results and future studies are given at the end. Efficient algorithms for optimizing a variety of X-risks are implemented in the LibAUC library at www.libauc.org.