 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Rates for Generalization of Gradient Descent Methods with Deep Neural Networks
Jun 04, 2026Recent progress has been made in understanding the statistical generalization performance of gradient descent methods for overparameterized neural networks within the neural tangent kernel (NTK) regime. However, most of the existing work on regression problems is limited to shallow network architectures, leaving a notable gap in the theory of deep neural networks. This paper addresses this gap by presenting a comprehensive generalization analysis for deep ReLU networks trained using gradient descent (GD) and stochastic gradient descent (SGD). Specifically, we establish the first known minimax-optimal rates of excess population risk for both GD and SGD with deep ReLU networks, under the assumption that the network width scales polynomially with respect to the network depth and training sample size. Our results demonstrate that with sufficient width, gradient descent methods for deep ReLU networks can achieve optimal generalization rates on par with kernel methods.
Generalization in Deep Neural Networks: Minimax Rates for Gradient Methods
Jun 04, 2026Understanding the generalization performance of over-parameterized neural networks has become a central topic in deep learning theory. While recent advances, particularly works under the Neural Tangent Kernel (NTK) regime, have shed light on the behavior of shallow architectures, the statistical generalization properties of deep neural networks (DNNs), especially in regression tasks, remain far less understood. In this paper, we make significant progress toward closing this gap by providing a comprehensive generalization analysis of DNNs trained using gradient-based methods. First, we establish, for the first time, a crucial connection between the learning dynamics of a DNN with smooth activation functions trained via gradient-based methods and those of kernel methods, showing that gradient-based methods on over-parameterized DNNs can fully inherit the favorable learning dynamics of their kernel counterparts. Building on this connection and the well-established optimality of kernel methods, we derive the first known minimax-optimal rates for the excess population risk of both gradient descent (GD) and stochastic gradient descent (SGD), under the assumption that network width scales polynomially with the sample size. Our results demonstrate that, with sufficient width, DNNs trained by GD or SGD can achieve generalization performance comparable to kernel-based methods.
Learning Theory of the SVRG: Generalization and Convergence Analysis
May 27, 2026Variance reduction (VR) methods employ stochastic gradients with decreasing variance, and they have been widely applied to solve large-scale optimization problems in machine learning because of their efficiency. Existing theoretical studies of VR methods are mainly focused on the convergence analysis, leaving the generalization behavior largely unexplored. In this paper, we bridge this gap by developing the first non-vacuous generalization analysis of the representative VR method: Stochastic Variance Reduced Gradient (SVRG), through the lens of algorithmic stability. In particular, we establish sharp stability bounds of the SVRG in both convex and strongly convex settings by exploiting its algorithmic structure. The obtained bounds are data-dependent, because the training errors are incorporated along the trajectory. Our analysis clarifies the interplay between optimization and generalization, leading to optimal excess population risk bounds in both settings. Our approach differs substantially from existing analyses of stochastic algorithms in the sense that we decompose the SVRG update as an SGD-like step plus a zero-mean correction term and then introduce novel Lyapunov functions to absorb the additional gradient terms induced by the reference points. Our analytical framework can be generalized to other VR methods, and we demonstrate the generalization by the well-known Stochastic Average Gradient Accelerated (SAGA) method.
Stochastic Gradient Descent with Momentum is Algorithmically Stable
May 27, 2026Stochastic gradient descent with momentum (SGDM) is one of the most widely used optimization algorithms in machine learning. While optimization properties of SGDM have been extensively studied in the literature, it remains insufficiently understood whether and when SGDM can generalize well to unseen data. In particular, it has been conjectured that while momentum accelerates training, it may degrade generalization. In this paper, we close this gap by developing a comprehensive generalization analysis of SGDM through the lens of algorithmic stability. More specifically, we introduce a generalized SGDM framework that encompasses both Polyak's and Nesterov's momentum schemes, and establish tight on-average model stability bounds for smooth and convex problems. Notably, the obtained bounds exploit small optimization error bounds along the trajectory, apply to any momentum parameter in the interval $[0, 1)$, and do not require the commonly assumed Lipschitzness of loss functions. We further derive optimization error bounds for the generalized SGDM, and combine them with our generalization analyses to obtain optimal excess population risk bounds for SGDM with both Polyak's and Nesterov's momentum.
Towards Initialization-dependent and Non-vacuous Generalization Bounds for Overparameterized Shallow Neural Networks
Apr 01, 2026Overparameterized neural networks often show a benign overfitting property in the sense of achieving excellent generalization behavior despite the number of parameters exceeding the number of training examples. A promising direction to explain benign overfitting is to relate generalization to the norm of distance from initialization, motivated by the empirical observations that this distance is often significantly smaller than the norm itself. However, the existing initialization-dependent complexity analyses cannot fully exploit the power of initialization since the associated bounds depend on the spectral norm of the initialization matrix, which can scale as a square-root function of the width and are therefore not effective for overparameterized models. In this paper, we develop the first \emph{fully} initialization-dependent complexity bounds for shallow neural networks with general Lipschitz activation functions, which enjoys a logarithmic dependency on the width. Our bounds depend on the path-norm of the distance from initialization, which are derived by introducing a new peeling technique to handle the challenge along with the initialization-dependent constraint. We also develop a lower bound tight up to a constant factor. Finally, we conduct empirical comparisons and show that our generalization analysis implies non-vacuous bounds for overparameterized networks.
Beyond Cross-Validation: Adaptive Parameter Selection for Kernel-Based Gradient Descents
Mar 03, 2026This paper proposes a novel parameter selection strategy for kernel-based gradient descent (KGD) algorithms, integrating bias-variance analysis with the splitting method. We introduce the concept of empirical effective dimension to quantify iteration increments in KGD, deriving an adaptive parameter selection strategy that is implementable. Theoretical verifications are provided within the framework of learning theory. Utilizing the recently developed integral operator approach, we rigorously demonstrate that KGD, equipped with the proposed adaptive parameter selection strategy, achieves the optimal generalization error bound and adapts effectively to different kernels, target functions, and error metrics. Consequently, this strategy showcases significant advantages over existing parameter selection methods for KGD.
Generalization and Optimization of SGD with Lookahead
Sep 19, 2025The Lookahead optimizer enhances deep learning models by employing a dual-weight update mechanism, which has been shown to improve the performance of underlying optimizers such as SGD. However, most theoretical studies focus on its convergence on training data, leaving its generalization capabilities less understood. Existing generalization analyses are often limited by restrictive assumptions, such as requiring the loss function to be globally Lipschitz continuous, and their bounds do not fully capture the relationship between optimization and generalization. In this paper, we address these issues by conducting a rigorous stability and generalization analysis of the Lookahead optimizer with minibatch SGD. We leverage on-average model stability to derive generalization bounds for both convex and strongly convex problems without the restrictive Lipschitzness assumption. Our analysis demonstrates a linear speedup with respect to the batch size in the convex setting.
Stability-based Generalization Analysis of Randomized Coordinate Descent for Pairwise Learning
Mar 03, 2025

Pairwise learning includes various machine learning tasks, with ranking and metric learning serving as the primary representatives. While randomized coordinate descent (RCD) is popular in various learning problems, there is much less theoretical analysis on the generalization behavior of models trained by RCD, especially under the pairwise learning framework. In this paper, we consider the generalization of RCD for pairwise learning. We measure the on-average argument stability for both convex and strongly convex objective functions, based on which we develop generalization bounds in expectation. The early-stopping strategy is adopted to quantify the balance between estimation and optimization. Our analysis further incorporates the low-noise setting into the excess risk bound to achieve the optimistic bound as $O(1/n)$, where $n$ is the sample size.
Generalization Analysis for Deep Contrastive Representation Learning
Dec 16, 2024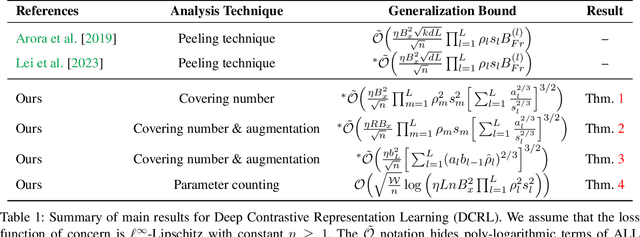
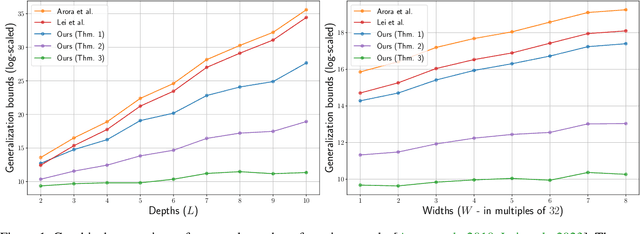


In this paper, we present generalization bounds for the unsupervised risk in the Deep Contrastive Representation Learning framework, which employs deep neural networks as representation functions. We approach this problem from two angles. On the one hand, we derive a parameter-counting bound that scales with the overall size of the neural networks. On the other hand, we provide a norm-based bound that scales with the norms of neural networks' weight matrices. Ignoring logarithmic factors, the bounds are independent of $k$, the size of the tuples provided for contrastive learning. To the best of our knowledge, this property is only shared by one other work, which employed a different proof strategy and suffers from very strong exponential dependence on the depth of the network which is due to a use of the peeling technique. Our results circumvent this by leveraging powerful results on covering numbers with respect to uniform norms over samples. In addition, we utilize loss augmentation techniques to further reduce the dependency on matrix norms and the implicit dependence on network depth. In fact, our techniques allow us to produce many bounds for the contrastive learning setting with similar architectural dependencies as in the study of the sample complexity of ordinary loss functions, thereby bridging the gap between the learning theories of contrastive learning and DNNs.
On Discriminative Probabilistic Modeling for Self-Supervised Representation Learning
Oct 11, 2024



We study the discriminative probabilistic modeling problem on a continuous domain for (multimodal) self-supervised representation learning. To address the challenge of computing the integral in the partition function for each anchor data, we leverage the multiple importance sampling (MIS) technique for robust Monte Carlo integration, which can recover InfoNCE-based contrastive loss as a special case. Within this probabilistic modeling framework, we conduct generalization error analysis to reveal the limitation of current InfoNCE-based contrastive loss for self-supervised representation learning and derive insights for developing better approaches by reducing the error of Monte Carlo integration. To this end, we propose a novel non-parametric method for approximating the sum of conditional densities required by MIS through convex optimization, yielding a new contrastive objective for self-supervised representation learning. Moreover, we design an efficient algorithm for solving the proposed objective. We empirically compare our algorithm to representative baselines on the contrastive image-language pretraining task. Experimental results on the CC3M and CC12M datasets demonstrate the superior overall performance of our algorithm.