 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Invariant Projection Learning for Zero-Shot Recognition
Oct 19, 2018
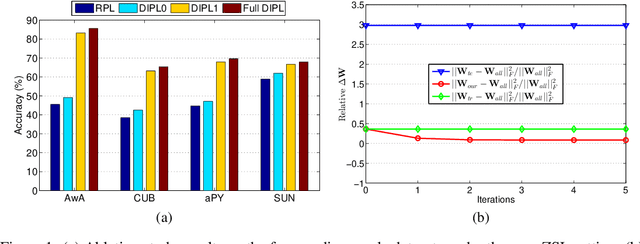
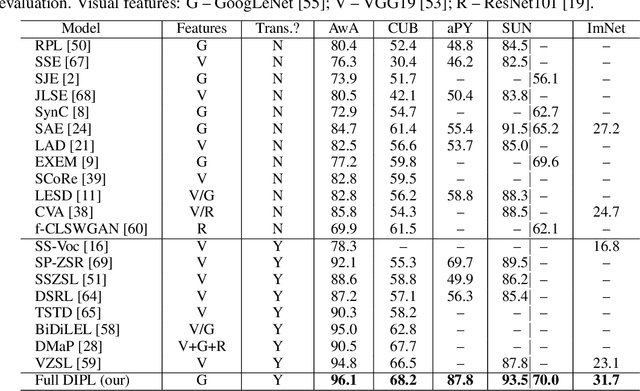
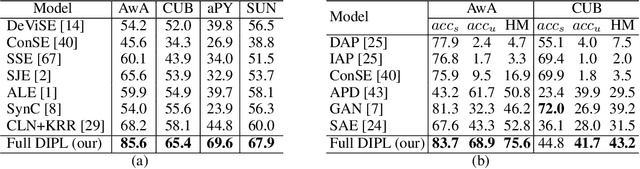
Zero-shot learning (ZSL) aims to recognize unseen object classes without any training samples, which can be regarded as a form of transfer learning from seen classes to unseen ones. This is made possible by learning a projection between a feature space and a semantic space (e.g. attribute space). Key to ZSL is thus to learn a projection function that is robust against the often large domain gap between the seen and unseen classes. In this paper, we propose a novel ZSL model termed domain-invariant projection learning (DIPL). Our model has two novel components: (1) A domain-invariant feature self-reconstruction task is introduced to the seen/unseen class data, resulting in a simple linear formulation that casts ZSL into a min-min optimization problem. Solving the problem is non-trivial, and a novel iterative algorithm is formulated as the solver, with rigorous theoretic algorithm analysis provided. (2) To further align the two domains via the learned projection, shared semantic structure among seen and unseen classes is explored via forming superclasses in the semantic space. Extensive experiments show that our model outperforms the state-of-the-art alternatives by significant margins.
Video Summarisation by Classification with Deep Reinforcement Learning
Sep 03, 2018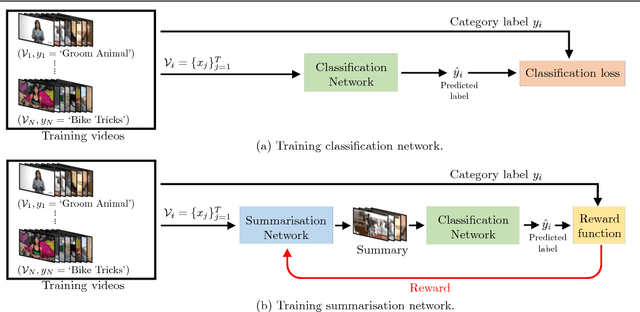
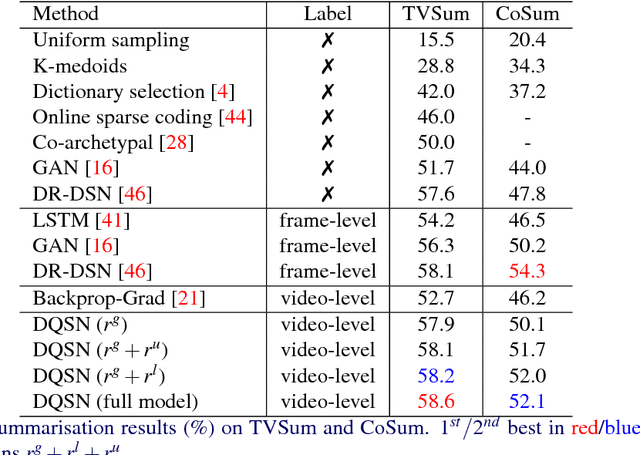
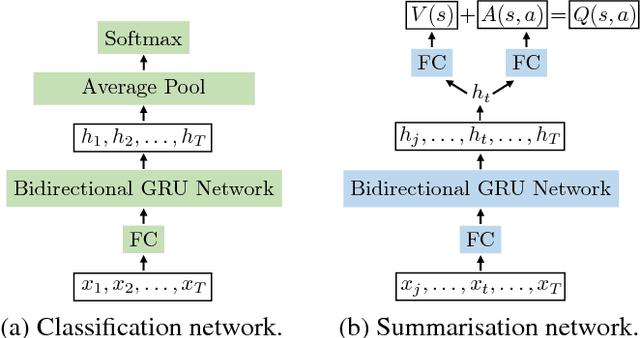

Most existing video summarisation methods are based on either supervised or unsupervised learning. In this paper, we propose a reinforcement learning-based weakly supervised method that exploits easy-to-obtain, video-level category labels and encourages summaries to contain category-related information and maintain category recognisability. Specifically, We formulate video summarisation as a sequential decision-making process and train a summarisation network with deep Q-learning (DQSN). A companion classification network is also trained to provide rewards for training the DQSN. With the classification network, we develop a global recognisability reward based on the classification result. Critically, a novel dense ranking-based reward is also proposed in order to cope with the temporally delayed and sparse reward problems for long sequence reinforcement learning. Extensive experiments on two benchmark datasets show that the proposed approach achieves state-of-the-art performance.
SketchyScene: Richly-Annotated Scene Sketches
Aug 07, 2018

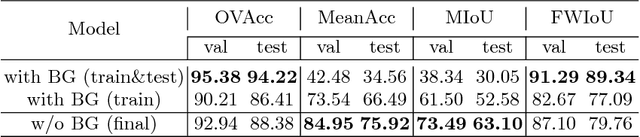
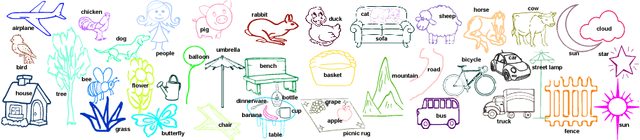
We contribute the first large-scale dataset of scene sketches, SketchyScene, with the goal of advancing research on sketch understanding at both the object and scene level. The dataset is created through a novel and carefully designed crowdsourcing pipeline, enabling users to efficiently generate large quantities of realistic and diverse scene sketches. SketchyScene contains more than 29,000 scene-level sketches, 7,000+ pairs of scene templates and photos, and 11,000+ object sketches. All objects in the scene sketches have ground-truth semantic and instance masks. The dataset is also highly scalable and extensible, easily allowing augmenting and/or changing scene composition. We demonstrate the potential impact of SketchyScene by training new computational models for semantic segmentation of scene sketches and showing how the new dataset enables several applications including image retrieval, sketch colorization, editing, and captioning, etc. The dataset and code can be found at https://github.com/SketchyScene/SketchyScene.
Deep Factorised Inverse-Sketching
Aug 07, 2018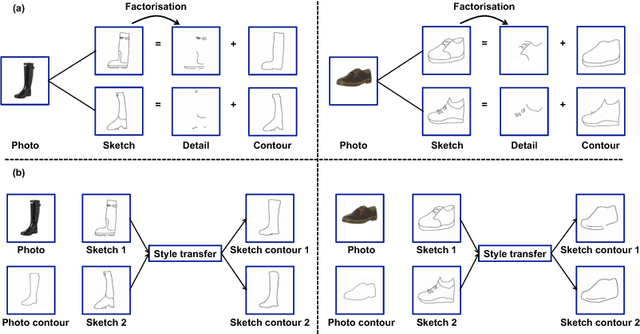
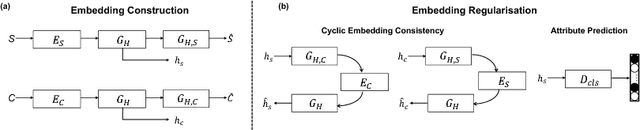
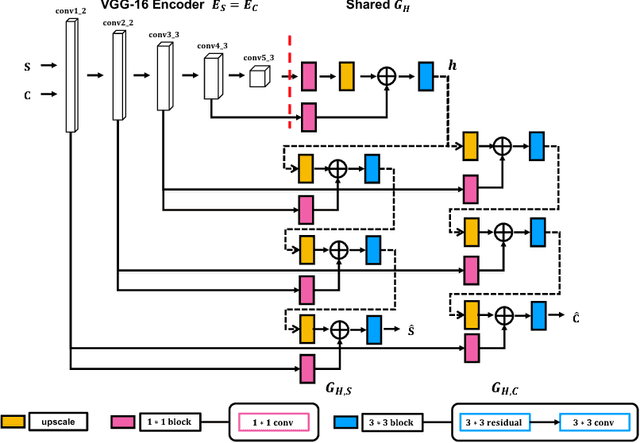
Modelling human free-hand sketches has become topical recently, driven by practical applications such as fine-grained sketch based image retrieval (FG-SBIR). Sketches are clearly related to photo edge-maps, but a human free-hand sketch of a photo is not simply a clean rendering of that photo's edge map. Instead there is a fundamental process of abstraction and iconic rendering, where overall geometry is warped and salient details are selectively included. In this paper we study this sketching process and attempt to invert it. We model this inversion by translating iconic free-hand sketches to contours that resemble more geometrically realistic projections of object boundaries, and separately factorise out the salient added details. This factorised re-representation makes it easier to match a free-hand sketch to a photo instance of an object. Specifically, we propose a novel unsupervised image style transfer model based on enforcing a cyclic embedding consistency constraint. A deep FG-SBIR model is then formulated to accommodate complementary discriminative detail from each factorised sketch for better matching with the corresponding photo. Our method is evaluated both qualitatively and quantitatively to demonstrate its superiority over a number of state-of-the-art alternatives for style transfer and FG-SBIR.
Universal Perceptual Grouping
Aug 07, 2018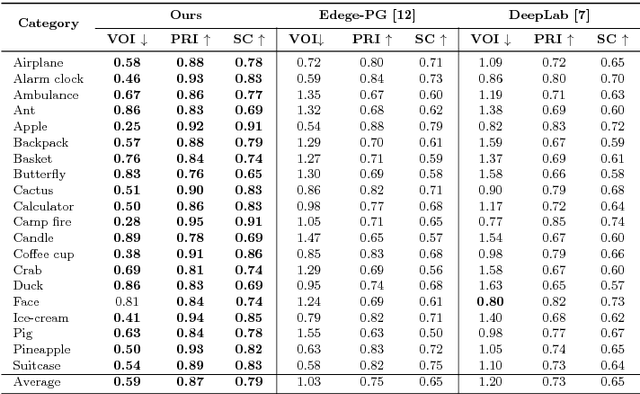
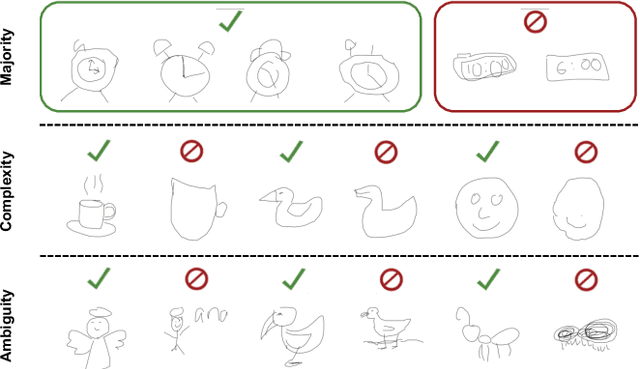
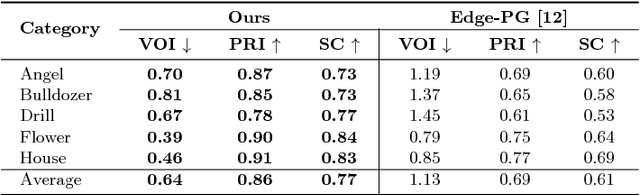
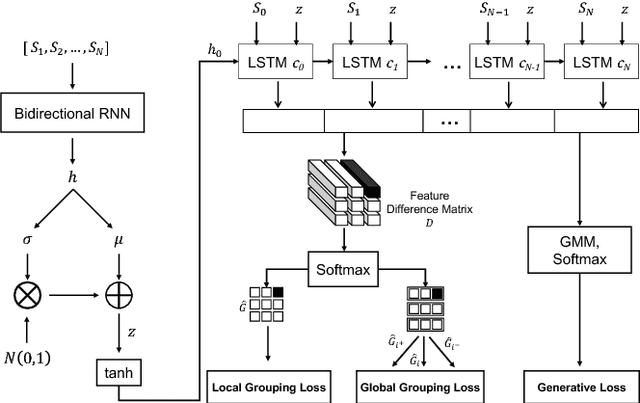
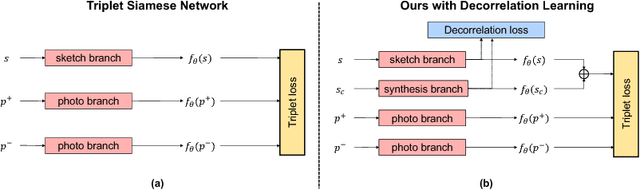
In this work we aim to develop a universal sketch grouper. That is, a grouper that can be applied to sketches of any category in any domain to group constituent strokes/segments into semantically meaningful object parts. The first obstacle to this goal is the lack of large-scale datasets with grouping annotation. To overcome this, we contribute the largest sketch perceptual grouping (SPG) dataset to date, consisting of 20,000 unique sketches evenly distributed over 25 object categories. Furthermore, we propose a novel deep universal perceptual grouping model. The model is learned with both generative and discriminative losses. The generative losses improve the generalisation ability of the model to unseen object categories and datasets. The discriminative losses include a local grouping loss and a novel global grouping loss to enforce global grouping consistency. We show that the proposed model significantly outperforms the state-of-the-art groupers. Further, we show that our grouper is useful for a number of sketch analysis tasks including sketch synthesis and fine-grained sketch-based image retrieval (FG-SBIR).
Person Re-Identification in Identity Regression Space
Jun 25, 2018
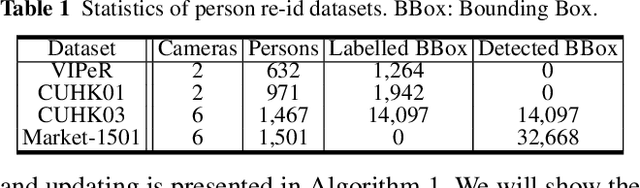
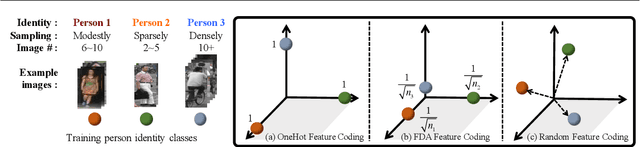
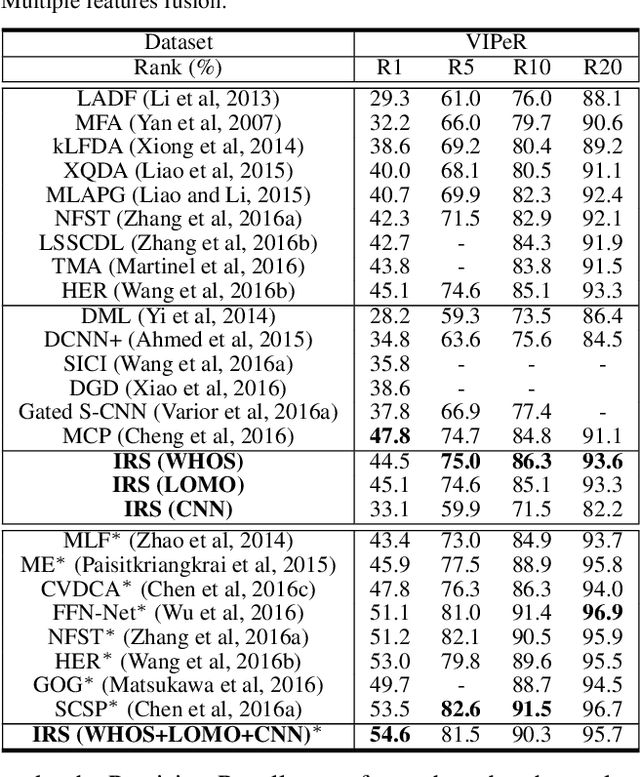
Most existing person re-identification (re-id) methods are unsuitable for real-world deployment due to two reasons: Unscalability to large population size, and Inadaptability over time. In this work, we present a unified solution to address both problems. Specifically, we propose to construct an Identity Regression Space (IRS) based on embedding different training person identities (classes) and formulate re-id as a regression problem solved by identity regression in the IRS. The IRS approach is characterised by a closed-form solution with high learning efficiency and an inherent incremental learning capability with human-in-the-loop. Extensive experiments on four benchmarking datasets(VIPeR, CUHK01, CUHK03 and Market-1501) show that the IRS model not only outperforms state-of-the-art re-id methods, but also is more scalable to large re-id population size by rapidly updating model and actively selecting informative samples with reduced human labelling effort.
Human-In-The-Loop Person Re-Identification
May 04, 2018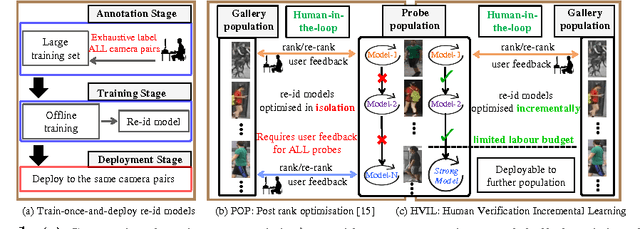
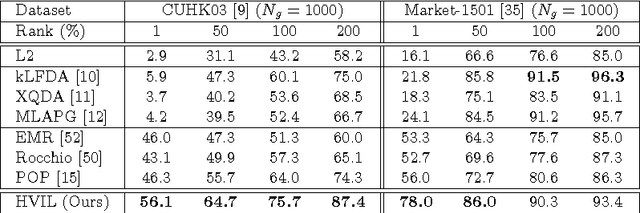

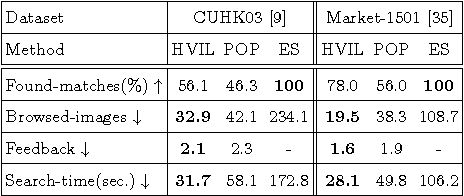
Current person re-identification (re-id) methods assume that (1) pre-labelled training data are available for every camera pair, (2) the gallery size for re-identification is moderate. Both assumptions scale poorly to real-world applications when camera network size increases and gallery size becomes large. Human verification of automatic model ranked re-id results becomes inevitable. In this work, a novel human-in-the-loop re-id model based on Human Verification Incremental Learning (HVIL) is formulated which does not require any pre-labelled training data to learn a model, therefore readily scalable to new camera pairs. This HVIL model learns cumulatively from human feedback to provide instant improvement to re-id ranking of each probe on-the-fly enabling the model scalable to large gallery sizes. We further formulate a Regularised Metric Ensemble Learning (RMEL) model to combine a series of incrementally learned HVIL models into a single ensemble model to be used when human feedback becomes unavailable.
Learning to Sketch with Shortcut Cycle Consistency
May 01, 2018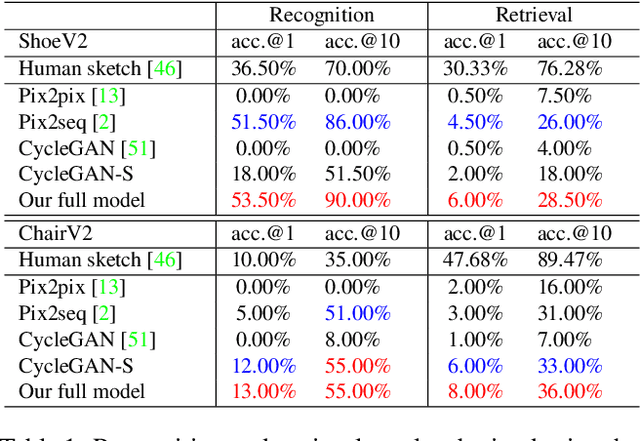
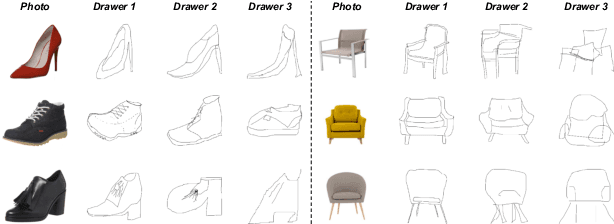

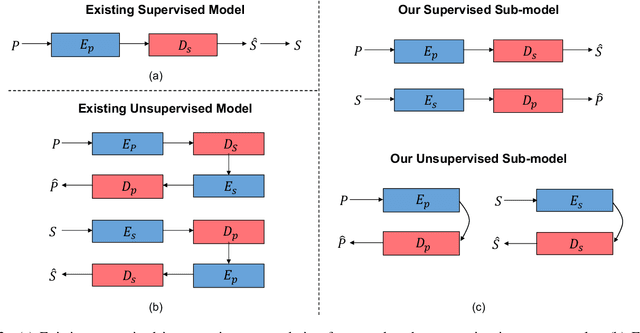
To see is to sketch -- free-hand sketching naturally builds ties between human and machine vision. In this paper, we present a novel approach for translating an object photo to a sketch, mimicking the human sketching process. This is an extremely challenging task because the photo and sketch domains differ significantly. Furthermore, human sketches exhibit various levels of sophistication and abstraction even when depicting the same object instance in a reference photo. This means that even if photo-sketch pairs are available, they only provide weak supervision signal to learn a translation model. Compared with existing supervised approaches that solve the problem of D(E(photo)) -> sketch, where E($\cdot$) and D($\cdot$) denote encoder and decoder respectively, we take advantage of the inverse problem (e.g., D(E(sketch)) -> photo), and combine with the unsupervised learning tasks of within-domain reconstruction, all within a multi-task learning framework. Compared with existing unsupervised approaches based on cycle consistency (i.e., D(E(D(E(photo)))) -> photo), we introduce a shortcut consistency enforced at the encoder bottleneck (e.g., D(E(photo)) -> photo) to exploit the additional self-supervision. Both qualitative and quantitative results show that the proposed model is superior to a number of state-of-the-art alternatives. We also show that the synthetic sketches can be used to train a better fine-grained sketch-based image retrieval (FG-SBIR) model, effectively alleviating the problem of sketch data scarcity.
Sketch-a-Classifier: Sketch-based Photo Classifier Generation
Apr 30, 2018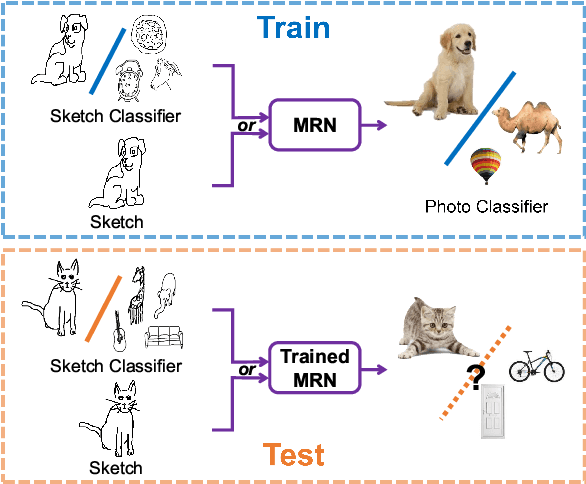

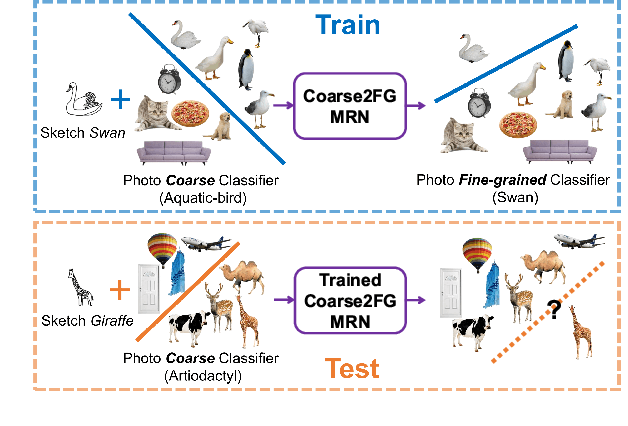
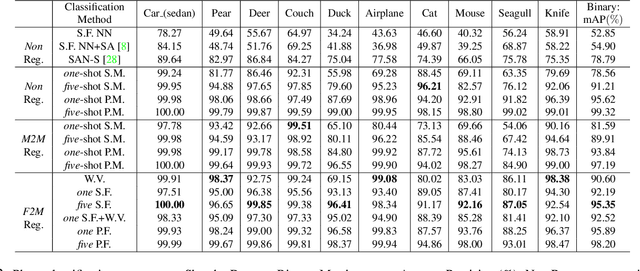
Contemporary deep learning techniques have made image recognition a reasonably reliable technology. However training effective photo classifiers typically takes numerous examples which limits image recognition's scalability and applicability to scenarios where images may not be available. This has motivated investigation into zero-shot learning, which addresses the issue via knowledge transfer from other modalities such as text. In this paper we investigate an alternative approach of synthesizing image classifiers: almost directly from a user's imagination, via free-hand sketch. This approach doesn't require the category to be nameable or describable via attributes as per zero-shot learning. We achieve this via training a {model regression} network to map from {free-hand sketch} space to the space of photo classifiers. It turns out that this mapping can be learned in a category-agnostic way, allowing photo classifiers for new categories to be synthesized by user with no need for annotated training photos. {We also demonstrate that this modality of classifier generation can also be used to enhance the granularity of an existing photo classifier, or as a complement to name-based zero-shot learning.
Pose-Normalized Image Generation for Person Re-identification
Apr 25, 2018
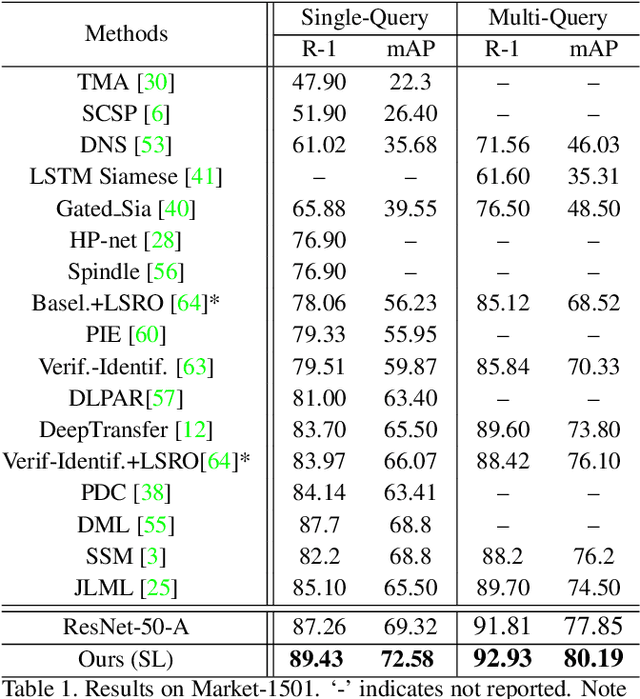
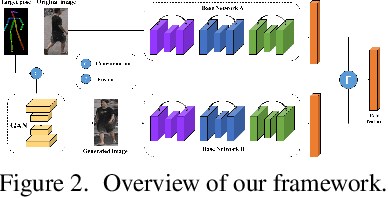
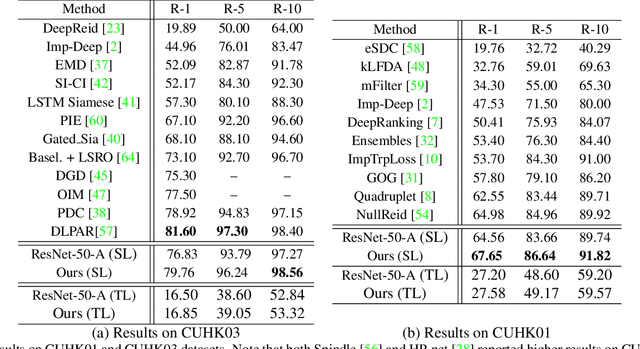
Person Re-identification (re-id) faces two major challenges: the lack of cross-view paired training data and learning discriminative identity-sensitive and view-invariant features in the presence of large pose variations. In this work, we address both problems by proposing a novel deep person image generation model for synthesizing realistic person images conditional on the pose. The model is based on a generative adversarial network (GAN) designed specifically for pose normalization in re-id, thus termed pose-normalization GAN (PN-GAN). With the synthesized images, we can learn a new type of deep re-id feature free of the influence of pose variations. We show that this feature is strong on its own and complementary to features learned with the original images. Importantly, under the transfer learning setting, we show that our model generalizes well to any new re-id dataset without the need for collecting any training data for model fine-tuning. The model thus has the potential to make re-id model truly scalable.